




網站數據分析
通過網站分析與數據分析實現網站優化
標籤歸檔:數據倉庫
網站數據分析的一些問題3


之前看過Inmon的《構建數據倉庫》和《DW 2.0》,而另外一位數據倉庫大師Kimball的《數據倉庫生命週期工具箱》一直沒有時間閱讀,最近纔有時間看完了大部分,就迫不及待想寫點東西了。其實數據倉庫領域普遍認爲Inmon和Kimball的理論是對立的,兩者在構建數據倉庫上方向性的差異一直爭論不休,誰也無法說服誰到底哪種方法更好。我的Evernote的筆記裏面不知什麼時候從哪裏摘錄過來了對兩者觀點的概括性描述,非常簡潔明瞭而一針見血:
Inmon vs Kimball
Kimball – Let everybody build what they want when they want it, we’ll integrate it all when and if we need to. (BOTTOM-UP APPROACH)Pros: fast to build, quick ROI, nimble
Cons: harder to maintain as an enterprise resource, often redundant, often difficult to integrate data marts
Inmon – Don’t do anything until you’ve designed everything. (TOP-DOWN APPROACH)
Pros: easy to maitain, tightly integrated
Cons: takes way too long to deliver first projects, rigid
其實看了《數據倉庫生命週期工具箱》之後,發現兩者的觀點沒有那麼大的本質性差異,可能隨着數據倉庫的不斷髮展,兩者在整體的架構上慢慢趨同。基本上,構建統一的企業級數據倉庫的方向是一致的,而Inmon偏向於從底層的數據集成出發,而Kimball則趨向於從上層的需求角度出發,這可能跟兩者從事的項目和所處的位置有關。
有了上面這段高質量的概括,第一個問題——你更偏向於以何種方式搭建數據倉庫(BOTTOM-UP or TOP-DOWN),分別有什麼優劣勢?——其實就不用問了,所以下面主要提幾個在實際中可能經常遇到或者需要想清楚的問題:
Q1、數據倉庫的技術解決方案有哪些,這些解決方案的優勢在哪,瓶頸在哪?
隨着數據倉庫的不斷髮展和成熟,“大數據”概念的風靡,有越來越多的相關產品出來,最常見的技術解決方案包括hadoop和hive,oracle,mysql的infobright,greenplum及nosql,或者多個結合使用。
其實歸納起來就兩類:一是用傳統RDBMS爲主導的數據庫管理數據,oracle、mysql等都是基於傳統的關係型數據庫,優勢就是有更嚴謹的數據結構,關係型數據庫對數據的管理更加規範,數據處理過程中可能出現的非人爲誤差極小,而且標準的SQL接口使數據獲取的成本較低,數據的查詢和獲取更加靈活和高效;但劣勢也很明顯,對海量數據的處理和存儲的能力不足,當數據量達到一定程度的時候就會出現明顯的瓶頸。而是基於文本的分佈式處理引擎,hadoop、greenplum和nosql都是基於文本數據的處理和存儲,優勢是強大的數據處理能力,分佈式的架構支持並行計算,並且具備超強的擴展延伸能力;劣勢就是上層接口不方便,因此Hadoop上層的hive和greenplum上層的postgreSQL都是爲了解決數據接口的問題,並且數據的查詢和獲取很難做到實時響應,靈活性不足。
Q2、數據倉庫是否就應該保存聚合數據,細節數據不應該放入數據倉庫?
其實這個問題基本已經達成共識,如果是構建企業級的數據倉庫,那麼對細節數據的集成和存儲是必不可少的,但現實中還是存在很多直接從外部數據源計算聚合之後導入數據倉庫的實例。如果對數據倉庫只是輕量級的應用,僅存放聚合數據也無可厚非,畢竟沒人規定數據倉庫一定要是怎麼樣的,最終的目的無非就是滿足對數據的支持和需求。
但對於企業的長期發展來看,數據倉庫中存放細節數據有兩方面的好處:一方面從技術層面,數據倉庫存儲細節數據可以釋放前臺數據庫的查詢壓力,同時對於文本類數據和外部文檔類數據入庫之後管理更加規範,數據倉庫保留歷史和不可變更的特性可以讓信息不被丟失;另一方面就是從數據的使用上,數據倉庫讓數據的獲取和使用更加簡便,集成細節數據讓大量的文本型數據可查詢,可關聯,而面向主題的設計讓數據的展現和分析更有方向性和目的性,而且細節數據是支持數據分析和數據挖掘應用所必不可少的。所以,如果數據倉庫要不斷地催生出更大的價值,細節數據的存儲是必不可少的。
Q3、你會把數據倉庫分爲幾層,每層的數據作用是什麼?
沒有標準答案,根據數據倉庫中數據的複雜性和對數據使用的需求程度,數據倉庫可以有不用的層級劃分。
我一般會把數據倉庫劃成三層:最底層的細節數據,管理策略是優化存儲,一般存儲導入的原始數據,便於進行向上的統計彙總,因爲數據量較大所以需要優化存儲;中間層是多維模型,管理策略是優化結構和查詢,面向主題的多維模型的設計,需要滿足OLAP和數據查詢的多樣需求,同時保證查詢的便捷性,關鍵在與維表的設計和維度的選擇及組合,事實表需要關注存儲和索引的優化;最上層是展現數據,管理策略是優化效率,一般會存放每天需要展現的彙總報表,或者根據多維模型拼裝的視圖,展現層的數據需要以最快的速度展現出來,一般用於BI平臺的Dashboard和報表。
Q4、數據倉庫搭建中最繁雜的事情是什麼,最容易缺失的是哪一塊?
一直覺得數據倉庫的核心不在於數據集成,當然數據集成是數據倉庫實現價值的前提,數據倉庫真正的價值體現在數據的有效應用,數據源於業務反作用於業務。而搭建數據倉庫的核心在於數據倉庫的架構和數據模型的設計,怎麼權衡數據的存儲和數據獲取效率之間的矛盾是數據倉庫管理上的難點,這個難點任何數據倉庫都會存在,而大數據增大了這種權衡中的難度。而數據的集成和數據質量控制是數據倉庫搭建中最繁雜的事情,尤其是數據清洗的過程,我之前也寫過幾篇數據質量控制的文章,但現實中這個過程還要複雜得多,而且爲了上層數據產出的準確性和有效性,這項工作又不得不做,而且要做得儘量細緻。
搭建數據倉庫中最容易缺失的就是對元數據的管理,很少有數據倉庫團隊具備完整的元數據,當然搭建數據倉庫的工程師本身就是活的元數據,但無論是爲了用數據的人還是數據倉庫自身的團隊着想,元數據都不可或缺。一方面元數據爲數據需求方提供了完整的數據倉庫使用文檔,幫助他們能自主地快速獲取數據,另一方面數據倉庫團隊成員可以從日常的數據解釋中解脫出來,無論是對後期的不斷迭代更新和維護還是培訓新的員工,都非常有好處,元數據可以讓數據倉庫的應用和維護更加高效。
寫在最後:以上僅代表個人觀點,歡迎大家踊躍拍磚,更加希望高手們能在評論中給出寶貴的答案,任何角度的觀點和討論都可以,集思廣益。
本條目發佈於 2013 年 5 月 23 日。屬於 未分類 分類,被貼了 數據倉庫 標籤。
分析的前提—數據質量3

數據審覈幫助我們發現數據中存在的問題,而這些問題有時候可以利用一些方法就行修正,從而提升數據的整體質量,數據修正就是爲了完成這個任務,可以從以下幾個方面進行修正:
填補缺失值
對於記錄缺失的問題,最簡單的辦法就是數據回補。一般而言統計指標數據缺失可以從原始數據中重新統計獲取,而原始數據缺失可以從抽取的數據源或者備份數據中回補。如果原始數據完全丟失,基本就回天無力了。
對於字段值的缺失,很多資料都會介紹使用一些統計學的方法進行修補,其實就是對缺失值的預測或者估計,一般會使用平均數、衆數、前後值取平均等方法,或者使用迴歸分析的方法擬合指標的變化趨勢後進行預測。這些方法在缺失值無法使用其他途徑找回或者重新統計計算,並且在缺失值有變化規律可循的前提下都是可取的,當某天的指標值丟失時可以通過這類方法根據前幾天的數據來預估該天的數值。但很多時候網站分析中如果底層的日誌存在缺失值,我們很難預測具體的缺失值,因爲訪問的細節幾乎是無跡可尋的,所以對於訪問記錄存在缺失值並且這些字段的缺失會明顯影響一些統計指標的計算時,最簡單的方法就是捨棄該記錄,但這種直接過濾掉缺失記錄的方法一些只會用於訪問日誌等不需要非常精確的數據上,如果是網站的運營、交易等這些需要保證完全計算準確的數據絕對是不能直接捨棄的,而且對於訪問日誌中缺失或者異常記錄的過濾也需要基於對這類數據的統計基礎上,一般的原則是不太重要的字段如果缺失或者異常的記錄佔比小於1%或者5‰的情況下可以選擇過濾這些記錄,如果佔比比較高,需要進一步排查日誌記錄是否存在問題。
刪除重複記錄
數據集裏面某些字段的值必然是唯一的,比如按天統計的指標值中的日期字段,用戶信息表的用戶ID等,這些需要保證唯一的規則可以對數據庫設置唯一約束,但我們在做ETL處理時,有時爲了保證數據加載全過程可以不因爲違反唯一約束而中斷(有時Load的過程需要較長的時間或處理成本,ETL需要有容錯能力以保證整個過程不被中斷)會先忽略重複記錄,待整個ETL過程結束後再對需要保證唯一的字段進行去重處理。
這些重複記錄可以比對Data Profiling中數據統計信息的唯一值個數和記錄總數是否一致進行審覈,而進行修正的最簡單辦法就是重複記錄僅保留一條,刪除其他記錄。這個需要根據現實情況,有時也可能使用把重複記錄的統計量相加的方法進行去重。
轉化不一致記錄
數據的轉化是數據倉庫抽取數據過程中最常見的處理,因爲數據倉庫“集成性”的特徵,需要把來自多個數據源的數據集中存入數據倉庫,而不同數據源對某些含義相同的字段的編碼規則會存在差異,比如用戶ID,雖然是相同的用戶,但可能A系統的ID是u1001,B系統是1001,C系統是100100,來源於這三套系統的用戶ID就需要統一,比如我們將A數據源的u前綴去除,C系統ID除100後統一成B系統的編碼方式一起導入數據庫;即使是來源於同一套日誌,也可能存在記錄的不一致,比如之前遇到較早發佈的產品版本記錄的日誌中移動操作系統是Android,而版本更新後記錄改成了android,新老版本的日誌打到了一起,於是也會涉及數據的轉化,但這種記錄的不一致性無疑會增加ETL的處理成本。
上面舉例的轉化規則是比較簡單的,在數據倉庫的ETL處理數據轉化時可能會遇到一些很BT的規則,這個時候最關鍵的還是對數據源記錄方式足夠的熟悉,這樣才能保證進入數據倉庫的數據是一致的。最好的做法就是數據倉庫的開發工程師與其他前臺系統的開發人員能事先約定一套統一的數據記錄和編碼的方式,這樣可以減少後期的協調溝通和轉化處理成本。
處理異常數據
異常數據大部分情況是很難修正的,比如字符編碼等問題引起的亂碼,字符被截斷,異常的數值等,這些異常數據如果沒有規律可循幾乎不可能被還原,只能將其直接過濾。
有些數據異常則可以被還原,比如原字符中參雜了一些其他的無用字符,可以使用取子串的方法,用trim函數可以去掉字符串前後的空格等;字符被截斷的情況如果可以使用截斷後字符推導出原完整字符串,那麼也可以被還原,比如移動操作系統的記錄一般包括Symbian、Android、iPhone、BlackBerry等,如果某些記錄的是And,那麼可以被還原成Android,因爲其他的移動操作系統被截斷不可能出現And這種記錄。數值記錄中存在異常大或者異常小的值是可以分析是否數值單位差異引起的,比如克和千克差了1000倍,美元和人民幣存在匯率的差異,時間記錄可能存在時區的差異,百分比用的是小於1的小數還是已經乘了100等等,這些數值的異常可以通過轉化進行處理,數值單位的差異也可以認爲是數據的不一致性,或者是某些數值被錯誤的放大或縮小,比如數值後面被多加了幾個0導致了數據的異常。
最後,總結一下數據可修正的前提:1) 數據質量的問題可以通過Data Auditing的過程被審覈出來;2) 數據的問題必須有跡可循,可以通過趨勢進行預測或者可以通過一些規則進行轉換還原。否者,對於異常數據只能直接進行刪除丟棄,但進行數據過濾之前必須評估異常記錄的比例,當佔比過高時需要重新審覈原始數據的記錄方式是否存在問題。
本條目發佈於 2012 年 11 月 20 日。屬於 數據獲取與預處理 分類,被貼了 數據倉庫 標籤。
分析的前提—數據質量2
前一篇文章介紹了數據質量的一些基本概念,數據質量控制作爲數據倉庫的基礎環節,是保障上層數據應用的基礎。數據質量保證主要包括數據概要分析(Data Profiling)、數據審覈(Data Auditing)和數據修正(Data Correcting)三個部分,前一篇文章介紹了Data Profiling的相關內容,從Data Profiling的過程中獲得了數據的概要統計信息,所以下面就要用這些數據統計信息來審覈數據的質量,檢查數據中是否存在髒數據,所以這一篇主要介紹數據審覈(Data Auditing)的內容。
數據質量的基本要素
首先,如何評估數據的質量,或者說怎麼樣的數據纔是符合要求的數據?可以從4個方面去考慮,這4個方面共同構成了數據質量的4個基本要素。

完整性
數據的記錄和信息是否完整,是否存在缺失的情況。
數據的缺失主要有記錄的缺失和記錄中某個字段信息的缺失,兩者都會造成統計結果的不準確,所以完整性是數據質量最基礎的保障,而對完整性的評估相對比較容易。
一致性
數據的記錄是否符合規範,是否與前後及其他數據集合保持統一。
數據的一致性主要包括數據記錄的規範和數據邏輯的一致性。數據記錄的規範主要是數據編碼和格式的問題,比如網站的用戶ID是15位的數字、商品ID是10位數字,商品包括20個類目、IP地址一定是用”.”分隔的4個0-255的數字組成,及一些定義的數據約束,比如完整性的非空約束、唯一值約束等;數據邏輯性主要是指標統計和計算的一致性,比如PV>=UV,新用戶比例在0-1之間等。數據的一致性審覈是數據質量審覈中比較重要也是比較複雜的一塊。
準確性
數據中記錄的信息和數據是否準確,是否存在異常或者錯誤的信息。
導致一致性問題的原因可能是數據記錄的規則不一,但不一定存在錯誤;而準確性關注的是數據記錄中存在的錯誤,比如字符型數據的亂碼現象也應該歸到準確性的考覈範疇,另外就是異常的數值,異常大或者異常小的數值,不符合有效性要求的數值,如訪問量Visits一定是整數、年齡一般在1-100之間、轉化率一定是介於0到1的值等。對數據準確性的審覈有時會遇到困難,因爲對於沒有明顯異常的錯誤值我們很難發現。
及時性
數據從產生到可以查看的時間間隔,也叫數據的延時時長。
雖然說分析型數據的實時性要求並不是太高,但並不意味了就沒有要求,分析師可以接受當天的數據要第二天才能查看,但如果數據要延時兩三天才能出來,或者每週的數據分析報告要兩週後才能出來,那麼分析的結論可能已經失去時效性,分析師的工作只是徒勞;同時,某些實時分析和決策需要用到小時或者分鐘級的數據,這些需求對數據的時效性要求極高。所以及時性也是數據質量的組成要素之一。
Data Auditing

完整性
我們從Data Profiling得到的數據統計信息裏面看看哪些可以用來審覈數據的完整性。首先是記錄的完整性,一般使用統計的記錄數和唯一值個數。比如網站每天的日誌記錄數是相對恆定的,大概在1000萬上下波動,如果某天的日誌記錄數下降到了只有100萬,那很有可能記錄缺失了;或者網站的訪問記錄應該在一天的24小時均有分佈,如果某個整點完全沒有用戶訪問記錄,那麼很有可能網站在當時出了問題或者那個時刻的日誌記錄傳輸出現了問題;再如統計訪客的地域分佈時,一般會包括全國的32個省份直轄市,如果統計的省份唯一值個數少於32,那麼很有可能數據也存在缺失。
完整性的另一方面,記錄中某個字段的數據缺失,可以使用統計信息中的空值(NULL)的個數進行審覈。如果某個字段的信息理論上必然存在,比如訪問的頁面地址、購買的商品ID等,那麼這些字段的空值個數的統計就應該是0,這些字段我們可以使用非空(NOT NULL)約束來保證數據的完整性;對於某些允許空的字段,比如用戶的cookie信息不一定存在(用戶禁用cookie),但空值的佔比基本恆定,比如cookie爲空的用戶比例通常在2%-3%,我們同樣可以使用統計的空值個數來計算空值佔比,如果空值的佔比明顯增大,很有可能這個字段的記錄出現了問題,信息出現缺失。
一致性
如果數據記錄格式有標準的編碼規則,那麼對數據記錄的一致性檢驗比較簡單,只要驗證所有的記錄是否滿足這個編碼規則就可以,最簡單的就是使用字段的長度、唯一值個數這些統計量。比如對用戶ID的編碼是15位數字,那麼字段的最長和最短字符數都應該是15;或者商品ID是P開始後面跟10位數字,可以用同樣的方法檢驗;如果字段必須保證唯一,那麼字段的唯一值個數跟記錄數應該是一致的,比如用戶的註冊郵箱;再如地域的省份直轄市一定是統一編碼的,記錄的一定是“上海”而不是“上海市”、“浙江”而不是“浙江省”,可以把這些唯一值映射到有效的32個省市的列表,如果無法映射,那麼字段通不過一致性檢驗。
一致性中邏輯規則的驗證相對比較複雜,很多時候指標的統計邏輯的一致性需要底層數據質量的保證,同時也要有非常規範和標準的統計邏輯的定義,所有指標的計算規則必須保證一致。我們經常犯的錯誤就是彙總數據和細分數據加起來的結果對不上,導致這個問題很有可能的原因就是數據在細分的時候把那些無法明確歸到某個細分項的數據給排除了,比如在細分訪問來源的時候,如果我們無法將某些非直接進入的來源明確地歸到外部鏈接、搜索引擎、廣告等這些既定的來源分類,但也不應該直接過濾掉這些數據,而應該給一個“未知來源”的分類,以保證根據來源細分之後的數據加起來還是可以與總體的數據保持一致。如果需要審覈這些數據邏輯的一致性,我們可以建立一些“有效性規則”,比如A>=B,如果C=B/A,那麼C的值應該在[0,1]的範圍內等,數據無法滿足這些規則就無法通過一致性檢驗。
準確性
數據的準確性可能存在於個別記錄,也可能存在於整個數據集。如果整個數據集的某個字段的數據存在錯誤,比如常見的數量級的記錄錯誤,這種錯誤很容易發現,利用Data Profiling的平均數和中位數也可以發現這類問題。當數據集中存在個別的異常值時,可以使用最大值和最小值的統計量去審覈,或者使用箱線圖也可以讓異常記錄一目瞭然。
還有幾個準確性的審覈問題,字符亂碼的問題或者字符被截斷的問題,可以使用分佈來發現這類問題,一般的數據記錄基本符合正態分佈或者類正態分佈,那麼那些佔比異常小的數據項很可能存在問題,比如某個字符記錄佔總體的佔比只有0.1%,而其他的佔比都在3%以上,那麼很有可能這個字符記錄有異常,一些ETL工具的數據質量審覈會標識出這類佔比異常小的記錄值。對於數值範圍既定的數據,也可以有效性的限制,超過數據有效的值域定義數據記錄就是錯誤的。
如果數據並沒有顯著異常,但仍然可能記錄的值是錯誤的,只是這些值與正常的值比較接近而已,這類準確性檢驗最困難,一般只能與其他來源或者統計結果進行比對來發現問題,如果使用超過一套數據收集系統或者網站分析工具,那麼通過不同數據來源的數據比對可以發現一些數據記錄的準確性問題。
上面已經從Data Profiling的統計信息中,通過Data Auditing發現了數據質量上存在的一些問題,那麼接下來就要針對這些問題對數據進行清洗和修正,也就是下一篇文章中要介紹的內容——Data Correcting,數據修正。
本條目發佈於 2012 年 10 月 21 日。屬於 數據獲取與預處理 分類,被貼了 數據倉庫 標籤。
分析的前提—數據質量1

我們通常通過數據清洗(Data cleansing)來過濾髒數據,保證底層數據的有效性和準確性,數據清洗一般是數據進入數據倉庫的前置環節,一般來說數據一旦進入數據倉庫,那麼必須保證這些數據都是有效的,上層的統計聚合都會以這批數據作爲基礎數據集,上層不會再去做任何的校驗和過濾,同時使用穩定的底層基礎數據集也是爲了保證所有上層的彙總和多維聚合的結果是嚴格一致的。但當前我們在構建數據倉庫的時候一般不會把所有的數據清洗步驟放在入庫之前,一般會把部分數據清洗的工作放在入庫以後來執行,主要由於數據倉庫對數據處理方面有自身的優勢,部分的清洗工作在倉庫中進行會更加的簡單高效,而且只要數據清洗髮生在數據的統計和聚合之前,我們仍然可以保證使用的是清洗之後保留在數據倉庫的最終“乾淨”的基礎數據。
前段時間剛好跟同事討論數據質量保證的問題,之前做數據倉庫相關工作的時候也接觸過相關的內容,所以這裏準備系統地整理一下。之前構建數據倉庫基於Oracle,所以選擇的是Oracle提供的數據倉庫構建工具——OWB(Oracle Warehouse Builder),裏面提供了比較完整的保證數據質量的操作流程,主要包括三塊:
- Data Profiling
- Data Auditing
- Data Correcting
Data Profiling
Data Profiling,其實目前還沒找到非常恰當的翻譯,Oracle裏面用的是“數據概要分析”,但其實“Profiling”這個詞用概要分析無法體現它的意境,看過美劇Criminal Minds(犯罪心理)的同學應該都知道FBI的犯罪行爲分析小組(BAU)每集都會對罪犯做一個Criminal Profiling,以分析罪犯的身份背景、行爲模式、心理狀態等,所以Profiling更多的是一個剖析的過程。維基百科對Data Profiling的解釋如下:
Data profiling is the process of examining the data available in an existing data source and collecting statistics and information about that data.
這裏我們看到Data Profiling需要一個收集統計信息的過程(這也是犯罪心理中Garcia乾的活),那麼如何讓獲取數據的統計信息呢?
熟悉數據庫的同學應該知道數據庫會對每張表做Analyze,一方面是爲了讓優化器可以選擇合適的執行計劃,另一方面對於一些查詢可以直接使用分析得到的統計信息返回結果,比如COUNT(*)。這個其實就是簡單的Data Profiling,Oracle數據倉庫構建工具OWB中提供的Data Profiling的統計信息更加全面,針對建立Data Profile的表中的每個字段都有完整的統計信息,包括:
記錄數、最大值、最小值、最大長度、最小長度、唯一值個數、NULL值個數、平均數和中位數,另外OWB還提供了six-sigma值,取值1-6,越高數據質量越好,當six-sigma的值爲7的時候可以認爲數據質量近乎是完美的。同時針對字段的唯一值,統計信息中給出了每個唯一值的分佈頻率,這個對發現一些異常數據是非常有用的,後面會詳細介紹。
看到上面這些Data Profile的統計信息,我們可能會聯想到統計學上面的統計描述,統計學上會使用一些統計量來描述一些數據集或者樣本集的特徵,如果我們沒有類似OWB的這類ETL工具,我們同樣可以藉助統計學的這些知識來對數據進行簡單的Profiling,這裏不得不提一個非常實用的圖表工具——箱形圖(Box plot),也叫箱線圖、盒狀圖。我們可以嘗試用箱形圖來表現數據的分佈特徵:
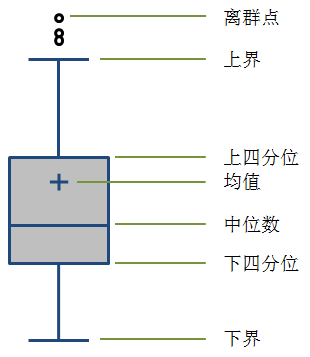
箱線圖有很多種表現形式,上面圖中的是比較常見的一種箱線圖。一般中間矩形箱的上下兩邊分別爲數據集的上四分位數(75%,Q3)和下四分位數(25%,Q1),中間的橫線代表數據集的中位數(50%,Media,Q2),同時有些箱線圖會用“+”來表示數據集的均值。箱形的上下分別延伸出兩條線,這兩條線的末端(也叫“觸鬚”)一般是距離箱形1.5個IQR(Q3-Q1,即箱形的長度),所以上端的觸鬚應該是Q3+1.5IQR,下端的觸鬚是Q1-1.5IQR;如果數據集的最小值大於Q1-1.5IQR,我們就會使用最小值替換Q1-1.5IQR作爲下方延伸線末端,同樣如果最大值小於Q3+1.5IQR,用最大值作爲上方延伸線的末端,如果最大或者最小值超出了Q1-1.5IQR到Q3+1.5IQR這個範圍,我們將這些超出的數據稱爲離羣點(Outlier),在圖中打印出來,即圖中在上方觸鬚之外的點。另外,有時候我們也會使用基於數據集的標準差σ,選擇上下3σ的範圍,或者使用置信水平爲95%的置信區間來確定上下邊界的末端值。
其實箱線圖沒有展現數據集的全貌,但通過對數據集幾個關鍵統計量的圖形化表現,可以讓我們看清數據的整體分佈和離散情況。
既然我們通過Data profiling已經可以得到如上的數據統計信息,那麼如何利用這些統計信息來審覈數據的質量,發現數據可能存在的異常和問題,並對數據進行有效的修正,或者清洗,進而得到“乾淨”的數據,這些內容就放到下一篇文章吧。
本條目發佈於 2012 年 9 月 26 日。屬於 數據獲取與預處理 分類,被貼了 數據倉庫、統計學 標籤。
網站數據分析的一些問題2

BI(Business Intelligence,商業智能),先看一下維基百科上面對BI的定義:
Business intelligence (BI) is defined as the ability for an organization to take all its capabilities and convert them into knowledge.
BI提供大量有價值的信息引導企業尋找新的發展機遇,當企業認識到潛在的機遇併成功地實施相應戰略決策的時候,BI就能幫助企業在市場建立競爭優勢並維持企業持續地發展。BI時常跟決策支持系統(Decision Support System, DSS)聯繫在一起,其實BI最主要的目標就是實現對企業的決策支持。
下面就探討幾個BI方面的問題:
Q1、BI與數據倉庫(DW)之間的關係是怎麼樣的?(知乎)
首先可以明確的是BI的重點在於對數據的應用上,讓數據變成有價值的信息,而所有的基礎數據基本都是來源於數據倉庫。
BI有兩個方向的定義:廣義的BI是包含數據倉庫的,廣義的BI包括數據的獲取、處理、儲存,到之後的分析、挖掘、展現變成有價值信息的整個過程,組成了一套完整的系統,當然在這個系統中數據倉庫擔當着從數據獲取之後的處理和存儲的職責,是基礎組成部分;狹義的BI僅僅包括上層的數據應用,包括數據的展現、分析、挖掘等,所以不包括數據倉庫。
因爲BI的定義更側重於數據應用,而隨着數據量的不大擴大,數據倉庫更多地被作爲一項獨立的技術被抽離出來,所以當前BI和數據倉庫的定義更傾向於分離,整個系統被叫做“DW/BI”的解決方案。
Q2、BI系統主要是爲了幫助企業解決什麼樣的問題?(知乎)
BI最初的目標就是優化企業的決策支持,實現從數據到有價值的信息的轉化,輔助企業商業戰略和決策的制定。所以BI的最終目標是獲取商業的Insight。
BI首先實現的是企業數據的透明化,原始的數據報表就是爲了從數據的角度定量地掌握企業的運營狀態,有了數據的支撐,很多決策的制定就會有了參考依據。隨着商業和信息技術的不斷髮展,BI不再僅僅停留在報表的領域,數據除了展現以外被更多地用於商業分析,而商業分析的基礎組成就是統計、預測和優化,這些對企業的運營決策起到了更加關鍵的作用。但隨着信息膨脹,數據量的劇增,BI也不斷面臨挑戰,我們需要花更多的成本去處理和存儲數據,需要花更多的精力去分析和應用數據。我之前寫過BI應用中的三大矛盾這篇文章,因爲有段時間了,很多地方的看法可能有了變化,但這3個矛盾相信依然還是存在。
所以,最終還是要把握BI的輸出是有價值的信息,無論中間的處理方式是查詢、報表,還是分析、挖掘,最終要得出的是有價值的結論。
Q3、目前BI的應用或組件主要有哪些?(知乎)
這裏簡單地歸納了一下,可能會有遺漏,希望大家能夠在評論中補充。這裏僅僅包括狹義BI中基於數據應用層面的一些功能,數據倉庫的數據處理方面的應用不在這裏羅列。
首先是報表、圖表和Dashboard,目前的報表和圖表除了更加豐富以外,跟傳統報表還有一個關鍵的區別就是可交互性。目前的報表基本都提供簡單的數據篩選、排序等功能,Dashboard的出現實現了按需整合報表和圖表的功能。
再則是OLAP,OLAP一度被當做BI的核心功能,不得不承認OLAP是分析數據最有效的手段,尤其是基於多個維度多個層面的分析,這些是一兩張報表圖表所無法做到的。OLAP一般都是基於已經設計成型的多維模型以及存放多維模型的數據集市(Data Mart),數據集市和OLAP跟業務層面有着很多關聯,這個使數據集市跟底層的數據倉庫有了區分。
然後是數據的查詢和分析,有時基於既定的模型的OLAP無法滿足分析的需求,所以就有了數據查詢的需求,一般直接查詢數據倉庫的細節數據;BI中的Ad-hoc Query則是對既定多維模型的靈活查詢,可以自由組合維度和度量。
最後是報表的發佈和數據預警,這都是屬於BI平臺的推送功能,一般可以通過郵件訂閱的形式定期把組合的報表推送給相關的人員,而通過預警的設定,可以監控數據的變化趨勢,掌握數據可能出現的異常。
另外BI還有很多新奇的功能,如基於GIS的地圖數據、基於Flash實現的動態圖表及對數據挖掘功能的集成等。
Q4、BI中的多維數據模型和OLAP的實用價值在哪?(知乎)
之前有關於多維數據模型和OLAP的介紹,可以參考數據倉庫的多維數據模型和數據立方體與OLAP這兩篇文章中的內容。
其實多維數據模型和OLAP最主要的是解決了如何有效地觀察數據的問題,傳統關係模型很難直接對數據進行觀察分析,而多維模型爲數據觀察者提供了清晰的視角,就如平常我們從多個角度看待事物一樣,多維模型維度的設計就很好地提供了這些角度的選擇。而OLAP的幾個操作形式正是體現了“分析”這個詞本身的含義,從總體到細節,結合多個維度的交叉分析,讓我們具備了對整個數據集進行全景觀測的能力。
OLAP最關鍵的技術除了多維模型設計還有就是預計算(Precomputation),或者叫預聚合,預計算解決了數據快速獲取的問題,基於一定的規則或者算法對數據集進行預計算之後,OLAP的操作性能可能得到有效地提升,從而使對大量數據的快速靈活的分析操作成爲可能。
Q5、目前市場上主流的BI產品主要有哪些?(知乎)
市場上主要的商業BI產品包括IBM的Cognos,另外IBM有自己的DB2可以建立數據倉庫,在2010年收購SPSS之後,讓其在數據分析和數據挖掘的領域也更加具有競爭力、SAP的Business Objects(BO),另外SAP有BW(Business Information Warehouse),作爲傳統的ERP方案提供商在數據集成方面有獨特的優勢、Oracle的BI(企業級的叫BIEE,Oracle Business Intelligence Enterprise Edition),Oracle藉助其強大的關係型數據庫建立數據倉庫有獨特的優勢。這3大商業BI都屬於整合型的BI,再加上微軟藉助Sql Server數據庫提供的SSIS、SSAS和SSRS也是屬於整合型的BI解決方案。另外也有獨立的BI公司,如SAS,傳統優勢在數據挖掘領域、Micro Strategy的BI解決方案、開源強大的BI系統Pentaho(之前幾年還有很多開源的BI系統,但因爲BI在技術上有一定的門檻和成本,所以目前很多開源BI 都會包括開源版本和商業版本,Pentaho也不例外),國內也有用友的BQ軟件也是屬於BI產品。
歸納一下就是目前的BI產品主要以商業產品爲主,而且整套的BI產品一般都是重量級的,在購買、部署和使用上都需要一定的成本投入。
如果對BI方面有自己的見解,歡迎在下面評論,或者到知乎回答相應的問題。
本條目發佈於 2012 年 8 月 12 日。屬於 未分類 分類,被貼了 OLAP、數據倉庫 標籤。
BI應用中的三大矛盾

看到文章標題,相信大家已經知道這篇文章還是關於BI方面的,其實這是我剛進現在所在公司的時候所寫的一篇文章,現在回頭看來即使一直努力地在協調好這些矛盾,但說實話最終沒有一個是真正完完全全的解決了的。我相信如果其他公司也是自己搭建BI系統的話,多多少少也會遇到這些問題,可能其中的一兩個矛盾現在也正困擾着大家,我這裏提供了我的解決方案,至於可行性和效果,有待大家去驗證。
矛盾一:業務部門對數據的理解與數據部門對需求的理解
把它放在第一位是因爲這個直接影響着數據所能發揮的效用,或者說這個矛盾沒協調好的話,數據所能創造的價值將大打折扣。造成這個矛盾的原因就是業務部門無法瞭解數據的獲取、處理、計算整個流程,從而對數據的含義和用處產生了自己的理解;同時數據部門無法真正瞭解業務需求,不清楚數據到底用於何處,爲了監控或評估產品的哪個方面,於是無法提供最優或最有效的數據。
解決方案:建立業務部門與數據部門間的接口。這個接口包括規範的流程、詳細的文檔、合理的數據展現,而最重要的還是能夠銜接起業務和數據之間的人。
首先是數據需求流程的規範化,也就是需求一般由業務部門提起,通過數據部門對數據的獲取和計算將結果返回給業務部門,這個流程中業務部門不僅要提供數據的規則,同時應該對獲取數據的目的、指標的定義、用處和價值做出詳細的描述;而數據部門不僅要給出最終數據,同時需要對指標的獲取途徑、計算方法作出解釋,最終的目的都是爲了使雙方在理解上能夠達成一致。
其次是詳細的文檔。這個其實就是上面所說的流程中必然會產生的兩類文檔:數據需求文檔和數據解釋文檔(在數據倉庫裏面是元數據的重要組成部分,關於數據倉庫的元數據一直想整理一篇文章出來,希望在之後儘快貼上來),文檔的內容基本就是包含上面流程中提到的那些內容。
再者就是合理的數據展現。其實就是一個原則:讓每個人看到自己想看的數據,並能直觀地理解這些數據。無論是報表、Excel還是其他展現方式,每個指標都應該能夠有途徑去直接查看相應的數據解釋文檔,而數據應該以最直觀的方式展現出來以方便理解,藉助各類圖表結合的方式。
最後也是最重要的一點就是業務與數據的銜接者。這類人員應該對產品的戰略目標、業務流程十分熟悉,同時對數據的獲取途徑、計算方法也瞭如指掌,或許不需要涉及高技術難度的數據ETL處理、組織和優化,但必須具備自己去計算和獲取各類數據的能力。
矛盾二:業務需求的不斷變化與生成數據的複雜流程
業務需求是不斷變化的,尤其是身在互聯網這個發展迅速的環境中。所以我們往往會遇到每天業務部門都會有新的需求過來,或者幾天前某個指標的計算邏輯在幾天之後就發生了變化。而數據部門面對這些情況,往往會陷入困境,一方面由於數據獲取上的問題導致某些指標沒法計算得到,另一方面指標計算邏輯的改變可能需要改動到整個複雜的數據處理流程,令人頭疼。
解決方案:集成化的完整的底層數據與快速靈活的數據獲取途徑。
其實在關於數據倉庫架構的文章中就提到過數據倉庫儘量保存所有的底層細節數據,包括原始的日誌點擊流數據和前臺數據庫的ODS數據以及其他來源的數據,其實我不太建議數據倉庫是單純根據需求建立起來的多維模型,因爲需求始終會變,但多維模型在應對變化時有缺失靈活性。而如果保存的底層數據,其實在大部分時間內就能做到以不變應萬變,因爲幾乎所有的指標都是從這些底層數據中計算得到的,擁有了底層數據相當於滿足了大部分數據的需求。
還有一個問題就是對需求改變時的及時應變,一種方法是建立面向不同主題的多維模型(當然是在底層數據的上層建的),因爲多維模型能夠滿足從多個角度多個層面對數據的觀察分析,能夠從一定程度上解決數據的多樣需求;同時基於底層數據集成化的組織管理環境,使用標準化的統計語言,如SQL語句,藉助其強大的對數據的聚合、排序、分組等能力,加速數據的獲取和計算。
矛盾三:數據即時查詢的效率與海量數據的處理和建模
其實這裏又是一個權衡的問題,即如何在提供足夠豐富的指標的前提下保證數據的展現、獲取和查詢的效率能夠滿足數據需求方的要求。如果提供的指標不夠,或者數據的粒度不夠細,就無法滿足日常數據監控和分析需要;相反,如果每天計算和統計的指標過多或者數據分得太細,那麼顯然會增加服務器運算的負荷,同時在數據查詢上的響應能力也會相應的下降。
解決方案:把握核心數據,建立合理的多維模型。
其實數據倉庫中海量數據的處理和查詢效率的問題本身就是一門很深的學問,涉及數據倉庫結構和ETL的優化、OLAP的優化(上一篇文章——OLAP的基本特徵有提到Oracle在這方面所做的優化),這裏不談論這些技術上的實現途徑,還是說應用上的。
核心數據,簡單說就是網站的目標、KPIs等,這些數據是從高層到基層人員都在時刻關注的數據,所以最優先的原則就是保證這些數據的查詢效率和及時響應。最簡單的做法就是這些指標獨立統計,不放入多維模型,只做每天的簡單聚合存入Summary表中直接供報表展現。
另一個就是建立合理的多維模型,說到合理這裏又要抱怨下,數據的需求方起初會漫無邊際地提各種需求,可能會有上百個指標,但一旦統計出來之後很少會有人真正去使用和分析這些指標(估計是因爲看了會眼花),這個我在關於實時數據統計中提到過類似問題。因爲在多維模型中增加一個維或維的層次加深一層,對於立方的數據是以乘積方式遞增的,比如增加一個100條記錄的維相當於立方的數據乘以100,或者時間維的粒度從天到小時,相當於數據量是原先的24倍,這個對於那些本身數據量就非常龐大的多維模型而言本身就是一場災難。所以建立多維模型時的原則是提供實際應用中需要的維和指標,同時把握好各個維的層次粒度。
上面就是我遇到的三大難題了,一下子又寫了這麼多,希望大家有耐心看完。其實之前的工作也較多地涉及了一些技術上面的東西,主要是Oracle和PL/SQL,由於對於那方面不是很擅長,另外博客主要面向網站數據分析方面的主題,所以很多總結的東西也不敢拿出來獻醜,如果大家希望也有這個方面的討論的,我可以分享幾篇上來,大家可以留言給我點建議。
本條目發佈於 2010 年 11 月 22 日。屬於 個人觀點分享 分類,被貼了 OLAP、數據倉庫 標籤。
OLAP的基本特徵

其實我們大部分時間是在模仿,參考書本或者他人的範例,而當我們去實現這些東西的時候,我們又會有自己的體驗,我們需要將這些體驗記錄下來,當我們能夠自己去總結整個實現過程的時候,其實可以認爲我們已經掌握了這個知識或技能。而正是在總結的過程中,我們也許會發現原先的範例可能並不是最優的,我們會產生自己的思考和優化方案,其實到這一步的時候你已經實現了一個超越,而當你自己的方案被實踐所驗證時,那麼可能你已經站在了一些人的前面了。而我今天要做的就是——“總結”。
OLAP的類型和基本操作
先來回顧下一些基礎知識,之前的文章——數據立方體與OLAP中介紹過OLAP的一些基本知識,包括OLAP的類型:ROLAP、MOLAP、HOLAP。
以及OLAP的基本操作:鑽取(Drill-down)、上卷(Roll-up)、切片(Slice)、切塊(Dice)以及旋轉(Pivot)。
因爲這些在之前的文章中都有介紹,這裏不再重複了,有興趣瞭解的同學直接去看我之前的那篇文章即可。
OLAP的優勢
OLAP的優勢包括之前提到的豐富的數據展現方式、高效的數據查詢以及多視角多層次的數據分析。這裏再補充兩點,是Oracle 11g的官方文檔介紹OLAP時提到的在Oracle中使用Cube所具備的優勢(當然Oracle裏面的Cube指的是MOLAP類型的數據組織方式,有點偏技術了):
從細粒度數據到彙總數據的預聚合(fine-grained approach to pre-aggregating summary data):Oracle的Cube提供了基於成本的預聚合(Cost based pre-aggregation),也就是既不會完全不進行預先的聚合,也不會將每個維每個層次的數據都預先聚合起來;而是會去考慮對於每條記錄聚合的成本,並將那些在動態聚合中相對高成本的記錄預先聚合並儲存起來,這樣相當於權衡了立方數據加載時的壓力和數據查詢時的效率(過度的預聚合會使數據加載的時間和空間成本提高,而過少的預聚合則會讓數據查詢的效率降低)。而其最終實現的就是最具性價比的快速查詢(fast query)。
維和立方之間的預關聯(pre-joining of dimensions to cube):當然這個也是基於MOLAP所具有的優勢,MOLAP是基於數組來構建的,所以維和立方之間是預關聯的,也就是相比ROLAP而言,其消除了構建索引以及建立表或物化視圖時所需要的額外的時間開銷,而在聚合數據的時候也避免了維和立方之間的多次關聯。
OLAP的基本特徵
進入主體內容,下面是我自己對OLAP所具備的基本特徵的總結,當然包括一些國外的博客和相關網站的介紹(現在打開某些國外的網站還真累),Oracle的一些文檔資料以及自己在實際使用時的體會。其實每個特徵都從不同層面上體現着OLAP對數據的組織、處理和分析上的優勢。
數據建模(Data Modeling)
我們知道數據倉庫的特徵之一是面向主題的,而數據模型的構建正是爲了將原本基於業務關係的數據整理成更符合人們日常觀察事物的一般方式,多維模型讓人們對數據的觀察更加得心應手,數據建模的優勢就是體現在簡化了複雜的數據組織邏輯和關係。
多維與可視化(Multidimensional and Visual)
多維和可視化體現在對數據多視角多層次的展現上。其實多維模型的OLAP在可視化層面上主要體現在報表上的鑽取、上卷、切片等操作,如果用過Mondrian的開源OLAP引擎就能體驗到其實就是一個類似樹形結構的展開,就像Windows裏面的資源管理器左側列表,這個符合人們日常觀察和使用的習慣。同時大部分的報表工具都支持此類的OLAP展示,MDX(Multi-Dimensional Expression,多維表達式)就是專門爲多維OLAP打造的查詢語法標準。
聚合(Aggregation)
聚合的優勢體現在滿足了從細節數據到高度彙總數據的不同需求。聚合的特徵在多維模型中體現爲預計算(pre-calculated)以及快速查詢(fast query)上面,能夠在不同的數據粒度上對數據進行聚合彙總,滿足數據的多種需求。
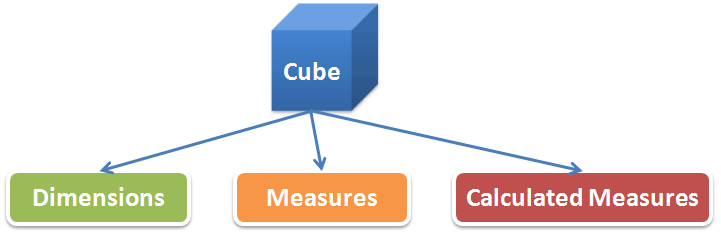
計算度量(Calculated Measures)
計算度量更加豐富地表現了各類指標的延伸、比率及變化趨勢等。最簡單的計算度量就是指標間的加減乘除、排名及比例,常見的例子就是銷售額減成本計算得到利潤,進而根據利潤對不同的產品進行排名,或者計算各類產品類型的利潤所佔的比例等;另外一種就是基於時間序列上計算得到的度量,比如同比增長、環比增長、期初累計、移動平均等。所以計算度量的存在讓我們的分析指標有了更多的選擇。
預測(Forecast)
其實熟悉OLAP,用過相關OLAP工具的朋友都知道,大部分的OLAP都會提供預測的功能,一般是基於時間序列的預測,工具直接提供相應的預測方法,比如加權移動平均法、指數平滑法(歷史數據加權平均的不斷迭代的過程)等。因爲在實踐中沒有用到過,所以這裏也不便討論起具體的意義多大,但這種不需要自己去寫算法,而直接使用工具根據相應的聚合數據預測未來的趨勢,至少能爲我們快捷地展現數據可能的走向,並做出可能調整。
好了,今天的總結就到這裏,不知道對你來說是不是也有些許收穫。
本條目發佈於 2010 年 11 月 16 日。屬於 網站數據倉庫 分類,被貼了 OLAP、數據倉庫、預測 標籤。
維(Dimension)和立方(Cube)
博客之前的兩篇文章:數據倉庫的多維模型和數據立方體與OLAP中分別對多維模型和OLAP的一些基本概念進行了介紹,這篇文章是基於那兩篇文章的深入擴展,主要介紹的是多維OLAP中兩個重要構成元素——維和立方的結構和組成。可能內容會偏向於模型構建方面,對那方面不太感興趣的同學可以直接跳過。
維(Dimension)
維是用於從不同角度描述事物特徵的,一般維都會有多層(Level),每個Level都會包含一些共有的或特有的屬性(Attribute),可以用下圖來展示下維的結構和組成:
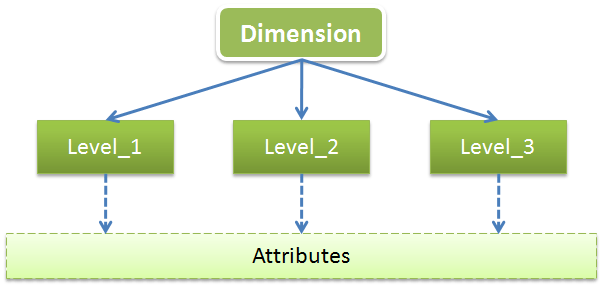
以時間維爲例,時間維一般會包含年、季、月、日這幾個Level,每個Level一般都會有ID、NAME、DESCRIPTION這幾個公共屬性,這幾個公共屬性不僅適用於時間維,也同樣表現在其它各種不同類型的維。其中ID一般被視爲代理主鍵(Agent),它只被用於作爲唯一性標誌,並且是多維模型中關聯關係的代理者,在業務層面並不具有任何意義;NAME一般是業務主鍵(Business),在業務層面限制唯一性,一般作爲數據裝載(Load)時的關聯鍵;而DESCRIPTION則記錄了詳細描述信息,在多維展示和分析時我們都會選擇使用DESCRIPTION來表述具體含義。這3個屬性一般是所有Level都會共用的,而比如用於描述星期幾的屬性weekid可能只會用於“日期”這層,因爲年月都不具備這一信息。所以圖中我將Attributes放到了一個層面上,就如同是不同的Level從底層的多個Attributes中選取自身所需的屬性,Attributes層是包含着各個Level的共有和特有屬性的集合。
Hierarchy
因爲不知道怎麼翻譯好,所以還是用英文吧。Hierarchy(等級、層級的意思),中文的OLAP相關文檔中普遍翻譯爲“層次”,而上面的Level被普遍翻譯爲“級別”,我經常會被這樣的翻譯搞混淆,所以我上面也一直用Level,至少對我來說這樣看起來反而清晰點 
因爲上面這個結構的維是無法直接應用於OLAP的,我前面的文章有介紹,其實OLAP需要基於有層級的自上而下的鑽取,或者自下而上地聚合。所以每一個維必須有Hierarchy,至少有一個默認的,當然可以有多個,見下圖:
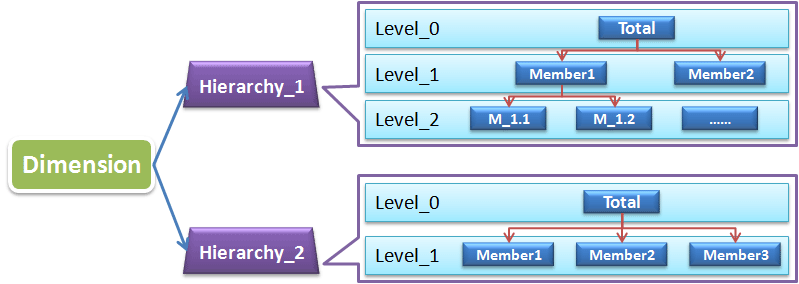
有了Hierarchy,維裏面的Level就有了自上而下的樹形結構關係,也就是上層的每一個成員(Member)都會包含下層的0個或多個成員,也就是樹的分支節點。這裏需要注意的是每個Hierarchy樹的根節點一般都設置成所有成員的彙總(Total),當該維未被OLAP中使用時,默認顯示的就是該維上的彙總節點,也就是該維所有數據的聚合(或者說該維未被用於細分)。Hierarchy中的每一層都會包含若干個成員(Member),還是以時間維,假設我們建的是2006-2015這樣一個時間跨度的時間維,那麼最高層節點僅有一個Total的成員,包含了所有這10年的時間,而年的那層Level中包含2006、2007…2015這10個成員,每一年又包含了4個季度成員,每個季度包含3個月份成員……這樣似乎順理成章多了,我們就可以基於Hierarchy做一些OLAP操作了。
每個Hierarchy都包含了一個樹形結構,但維中也可以包含多個Hierarchy,正如上圖所示,維中的Hierarchy相互獨立地構建了自己的樹形結構。還是以時間維爲例,時間維可以根據日曆(Calendar)時間組建日曆的Hierarchy,也可以根據財務(Fiscal)時間組建財務的Hierarchy,而其中財務季度的劃分可能並不與日曆一致,基於這種多樣的Hierarchy,我們在組建多維模型時可以按需選擇合適的,比如給財務部的數據分析模型選用財務Hierarchy,而其他部門的分析人員顯然希望看到日曆樣式的Hierarchy,這樣就完美地滿足了不同的需求。多種的Hierarchy劃分同樣適用於產品維,根據產品類型、產品規格等劃分 Hierarchy,對於按多種條件的產品篩選和檢索是十分有效的,實例可以參見淘寶搜索商品界面和太平洋電腦中產品報價界面分類篩選模塊,這裏不再截圖了。
立方(Cube)
這裏所說的立方其實就是多維模型中間的事實表(Fact Table),它會引用所有相關維的維主鍵作爲自身的聯合主鍵,加上度量(Measure)和計算度量(Calculated Measure)就組成了立方的結構:
度量是用於描述事件的數字尺度,比如網站的瀏覽量(Pageviews)、訪問量(Visits),再如電子商務的訂單量、銷售額等。度量是實際儲存於物理表中的,而計算度量則沒有,計算度量是通過度量計算得到的,比如同比(如去年同期的月利潤)、環比(如上個月的利潤)、利率(如環比利潤增長率)、份額(如該月中某類產品利潤所佔比例)、累計(如從年初到當前的累加利潤)、移動平均(如最近7天的平均利潤額)等,這些計算度量在Oracle中都可以藉助分析函數直接計算得到,相信大部分的OLAP組件都會提供類似在時間序列上的分析功能。而這些計算度量往往對於分析而言更具意義,立方中藉助與各個維的關聯關係從不同的角度和層面來展現這些度量。
The end,因爲最近在看相關方面的資料,這篇文章就作爲讀書筆記,如果有哪裏表述不準確的,還望指正。
本條目發佈於 2010 年 10 月 27 日。屬於 網站數據倉庫 分類,被貼了 OLAP、數據倉庫 標籤。
數據立方體與OLAP
前面的一篇文章——數據倉庫的多維數據模型中已經簡單介紹過多維模型的定義和結構,以及事實表(Fact Table)和維表(Dimension Table)的概念。多維數據模型作爲一種新的邏輯模型賦予了數據新的組織和存儲形式,而真正體現其在分析上的優勢還需要基於模型的有效的操作和處理,也就是OLAP(On-line Analytical Processing,聯機分析處理)。
數據立方體
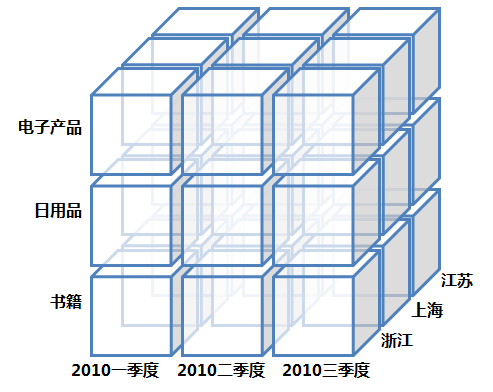
關於數據立方體(Data Cube),這裏必須注意的是數據立方體只是多維模型的一個形象的說法。立方體其本身只有三維,但多維模型不僅限於三維模型,可以組合更多的維度,但一方面是出於更方便地解釋和描述,同時也是給思維成像和想象的空間;另一方面是爲了與傳統關係型數據庫的二維表區別開來,於是就有了數據立方體的叫法。所以本文中也是引用立方體,也就是把多維模型以三維的方式爲代表進行展現和描述,其實上Google圖片搜索“OLAP”會有一大堆的數據立方體圖片,這裏我自己畫了一個:
OLAP
OLAP(On-line Analytical Processing,聯機分析處理)是在基於數據倉庫多維模型的基礎上實現的面向分析的各類操作的集合。可以比較下其與傳統的OLTP(On-line Transaction Processing,聯機事務處理)的區別來看一下它的特點:
OLAP與OLTP
| 數據處理類型 | OLTP | OLAP |
| 面向對象 | 業務開發人員 | 分析決策人員 |
| 功能實現 | 日常事務處理 | 面向分析決策 |
| 數據模型 | 關係模型 | 多維模型 |
| 數據量 | 幾條或幾十條記錄 | 百萬千萬條記錄 |
| 操作類型 | 查詢、插入、更新、刪除 | 查詢爲主 |
OLAP的類型
首先要聲明的是這裏介紹的有關多維數據模型和OLAP的內容基本都是基於ROLAP,因爲其他幾種類型極少接觸,而且相關的資料也不多。
MOLAP(Multidimensional)
即基於多維數組的存儲模型,也是最原始的OLAP,但需要對數據進行預處理才能形成多維結構。
ROLAP(Relational)
比較常見的OLAP類型,這裏介紹和討論的也基本都是ROLAP類型,可以從多維數據模型的那篇文章的圖中看到,其實ROLAP是完全基於關係模型進行存放的,只是它根據分析的需要對模型的結構和組織形式進行的優化,更利於OLAP。
HOLAP(Hybrid)
介於MOLAP和ROLAP的類型,我的理解是細節的數據以ROLAP的形式存放,更加方便靈活,而高度聚合的數據以MOLAP的形式展現,更適合於高效的分析處理。
另外還有WOLAP(Web-based OLAP)、DOLAP(Desktop OLAP)、RTOLAP(Real-Time OLAP),具體可以參開維基百科上的解釋——OLAP。
OLAP的基本操作
我們已經知道OLAP的操作是以查詢——也就是數據庫的SELECT操作爲主,但是查詢可以很複雜,比如基於關係數據庫的查詢可以多表關聯,可以使用COUNT、SUM、AVG等聚合函數。OLAP正是基於多維模型定義了一些常見的面向分析的操作類型是這些操作顯得更加直觀。
OLAP的多維分析操作包括:鑽取(Drill-down)、上卷(Roll-up)、切片(Slice)、切塊(Dice)以及旋轉(Pivot),下面還是以上面的數據立方體爲例來逐一解釋下:
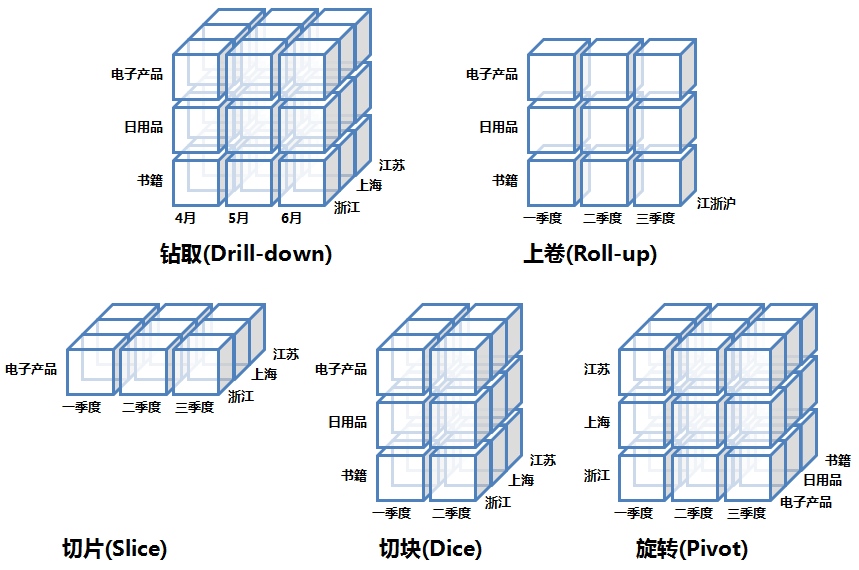
鑽取(Drill-down):在維的不同層次間的變化,從上層降到下一層,或者說是將彙總數據拆分到更細節的數據,比如通過對2010年第二季度的總銷售數據進行鑽取來查看2010年第二季度4、5、6每個月的消費數據,如上圖;當然也可以鑽取浙江省來查看杭州市、寧波市、溫州市……這些城市的銷售數據。
上卷(Roll-up):鑽取的逆操作,即從細粒度數據向高層的聚合,如將江蘇省、上海市和浙江省的銷售數據進行彙總來查看江浙滬地區的銷售數據,如上圖。
切片(Slice):選擇維中特定的值進行分析,比如只選擇電子產品的銷售數據,或者2010年第二季度的數據。
切塊(Dice):選擇維中特定區間的數據或者某批特定值進行分析,比如選擇2010年第一季度到2010年第二季度的銷售數據,或者是電子產品和日用品的銷售數據。
旋轉(Pivot):即維的位置的互換,就像是二維表的行列轉換,如圖中通過旋轉實現產品維和地域維的互換。
OLAP的優勢
首先必須說的是,OLAP的優勢是基於數據倉庫面向主題、集成的、保留歷史及不可變更的數據存儲,以及多維模型多視角多層次的數據組織形式,如果脫離的這兩點,OLAP將不復存在,也就沒有優勢可言。
數據展現方式
基於多維模型的數據組織讓數據的展示更加直觀,它就像是我們平常看待各種事物的方式,可以從多個角度多個層面去發現事物的不同特性,而OLAP正是將這種尋常的思維模型應用到了數據分析上。
查詢效率
多維模型的建立是基於對OLAP操作的優化基礎上的,比如基於各個維的索引、對於一些常用查詢所建的視圖等,這些優化使得對百萬千萬甚至上億數量級的運算變得得心應手。
分析的靈活性
我們知道多維數據模型可以從不同的角度和層面來觀察數據,同時可以用上面介紹的各類OLAP操作對數據進行聚合、細分和選取,這樣提高了分析的靈活性,可以從不同角度不同層面對數據進行細分和彙總,滿足不同分析的需求。
是不是覺得其實OLAP並沒有想象中的那麼複雜,一旦多維數據模型建成後,在上面做OLAP其實是一件很cool的事情。
本條目發佈於 2010 年 8 月 29 日。屬於 網站數據倉庫 分類,被貼了 OLAP、數據倉庫 標籤。
數據倉庫的多維數據模型
多維數據模型的定義和作用
多維數據模型是爲了滿足用戶從多角度多層次進行數據查詢和分析的需要而建立起來的基於事實和維的數據庫模型,其基本的應用是爲了實現OLAP(Online Analytical Processing)。
當然,通過多維數據模型的數據展示、查詢和獲取就是其作用的展現,但其真的作用的實現在於,通過數據倉庫可以根據不同的數據需求建立起各類多維模型,並組成數據集市開放給不同的用戶羣體使用,也就是根據需求定製的各類數據商品擺放在數據集市中供不同的數據消費者進行採購。
多維數據模型實例
在看實例前,這裏需要先了解兩個概念:事實表和維表。事實表是用來記錄具體事件的,包含了每個事件的具體要素,以及具體發生的事情;維表則是對事實表中事件的要素的描述信息。比如一個事件會包含時間、地點、人物、事件,事實表記錄了整個事件的信息,但對時間、地點和人物等要素只記錄了一些關鍵標記,比如事件的主角叫“Michael”,那麼Michael到底“長什麼樣”,就需要到相應的維表裏面去查詢“Michael”的具體描述信息了。基於事實表和維表就可以構建出多種多維模型,包括星形模型、雪花模型和星座模型。這裏不再展開了,解釋概念真的很麻煩,而且基於我的理解的描述不一定所有人都能明白,還是直接上實例吧:
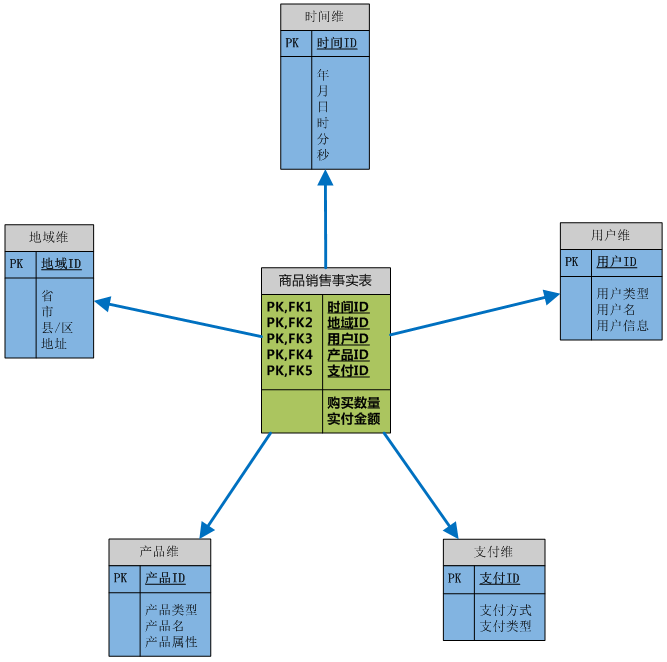
這是一個最簡單的星形模型的實例。事實表裏面主要包含兩方面的信息:維和度量,維的具體描述信息記錄在維表,事實表中的維屬性只是一個關聯到維表的鍵,並不記錄具體信息;度量一般都會記錄事件的相應數值,比如這裏的產品的銷售數量、銷售額等。維表中的信息一般是可以分層的,比如時間維的年月日、地域維的省市縣等,這類分層的信息就是爲了滿足事實表中的度量可以在不同的粒度上完成聚合,比如2010年商品的銷售額,來自上海市的銷售額等。
還有一點需要注意的是,維表的信息更新頻率不高或者保持相對的穩定,例如一個已經建立的十年的時間維在短期是不需要更新的,地域維也是;但是事實表中的數據會不斷地更新或增加,因爲事件一直在不斷地發生,用戶在不斷地購買商品、接受服務。
多維數據模型的優缺點
這裏所說的多維模型是指基於關係數據庫的多維數據模型,其與傳統的關係模型相比有着自身的優缺點。
優點:
多維數據模型最大的優點就是其基於分析優化的數據組織和存儲模式。舉個簡單的例子,電子商務網站的操作數據庫中記錄的可能是某個時間點,某個用戶購買了某個商品,並寄送到某個具體的地址的這種記錄的集合,於是我們無法馬上獲取2010年的7月份到底有多少用戶購買了商品,或者2010年的7月份有多少的浙江省用戶購買了商品?但是在基於多維模型的基礎上,此類查詢就變得簡單了,只要在時間維上將數據聚合到2010年的7月份,同時在地域維上將數據聚合到浙江省的粒度就可以實現,這個就是OLAP的概念,之後會有相關的文章進行介紹。
缺點:
多維模型的缺點就是與關係模型相比其靈活性不夠,一旦模型構建就很難進行更改。比如一個訂單的事實,其中用戶可能購買了多種商品,包括了時間、用戶維和商品數量、總價等度量,對於關係模型而言如果我們進而需要區分訂單中包含了哪些商品,我們只需要另外再建一張表記錄訂單號和商品的對應關係即可,但在多維模型裏面一旦事實表構建起來後,我們無法將事實表中的一條訂單記錄再進行拆分,於是無法建立以一個新的維度——產品維,只能另外再建個以產品爲主題的事實表。
所以,在建立多維模型之前,我們一般會根據需求首先詳細的設計模型,應該包含哪些維和度量,應該讓數據保持在哪個粒度上才能滿足用戶的分析需求。
這裏對數據倉庫的多維模型進行了簡單的介紹,你是不是想到了其實你在分析數據的時候很多的數據就是複合多維模型的結構的,或者你已經用自己的方法構建出了多維模型或者實現的數據的多維化展示,歡迎與我分享。
文章當時發的時候好像有點問題,後面有段沒更新進去,評論也被關了,居然發佈了近兩週才發現,現在補上了,對所有看過這篇文章的朋友說聲抱歉!