




http://www.dostor.com/p/48121.html
一.NVMe 協議
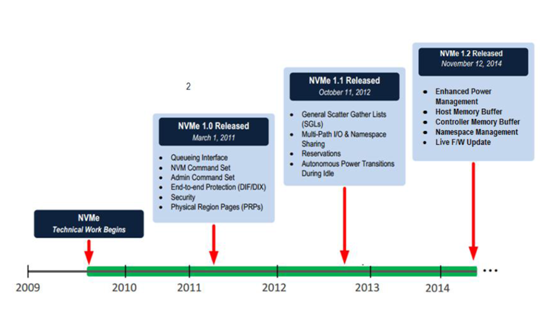
NVMe協議是在PCIe SSD開始大量出現在市場上後,因爲各個廠家的私有協議不具有兼容性,無法和現有操作系統無縫銜接,INTEL爲了統一接口協議建立生態,而在2011年發佈了NVMe協議。
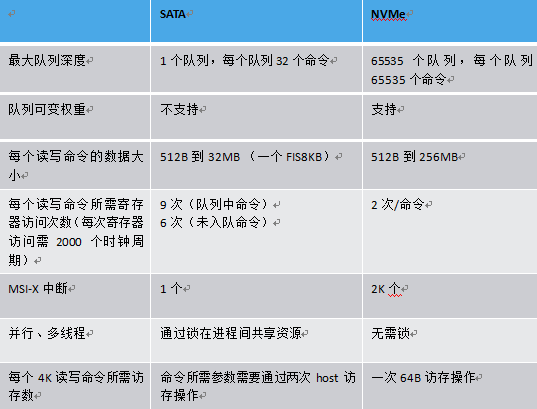
NVMe採用了多命令隊列 (最大65536個命令隊列),每個命令可變數據長度(512B到2MB),同時數據在host端內存支持Physical Region Page和Scatter Gather List。NVMe協議支持命令間的亂序執行,也支持命令內數據塊的亂序傳輸,同時支持命令隊列間的可變權重處理。
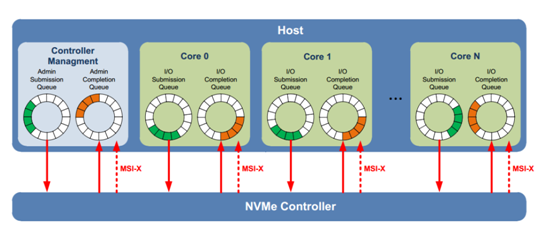
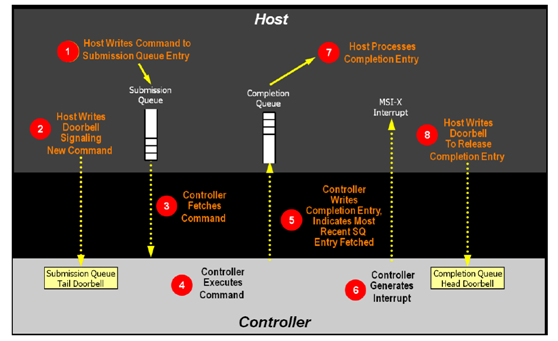
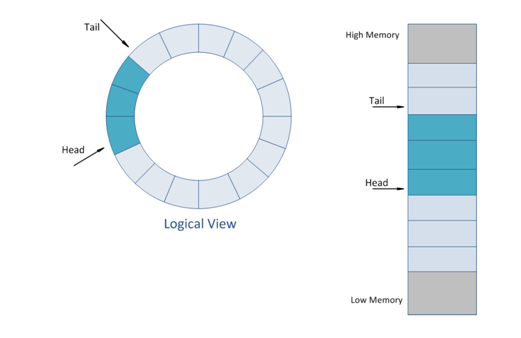
和基於傳統ATA(基於PC時代硬盤的接口協議)的SATA協議相比,NVME協議做了很多針對多核host以及NAND存儲介質的協議優化。
因爲PCIE接口的高帶寬,NVMe協議帶來SSD訪問的高效率,但也同時帶來了SSD控制器端NMVe協議棧實現的難度和挑戰。這個挑戰主要是1)多權重命令隊列的管理和命令抓取,2)命令的解析分解,分發,3)數據的傳輸。
在開始討論解決方法之前,我們先了解一下SSD控制器的基本架構。
二.SSD控制器
典型的SSD控制器架構如下:
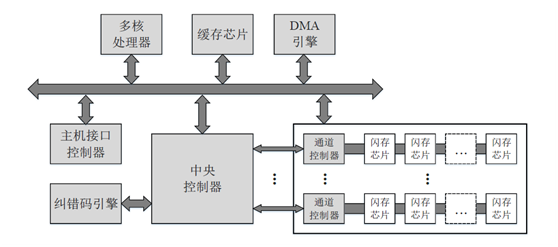
主機接口控制器:
主機接口負責進行主機與固態盤之間的通信和數據傳輸,接受和解析I/O請求,並維護一條或者多條請求隊列。目前主流使用的物理接口包括SATA、SAS、PCIe、M.2等。其中,SATA是低成本的硬盤接口,SATA 3.0的理論帶寬是600MB/s;SAS向下兼容SATA,能提供更高的傳輸速率、可靠性和可用性,SAS3.0的理論帶寬是1.2GB/s;PCIe是連接外圍設備和主機處理器的主要接口,SATA和SAS接口就是通過PCIe接口連接到主機處理器和內存,PCIe SSD既縮短了主機處理器到存儲介質的路徑和響應延時,又能提供更大的帶寬,PCIe 3.0×4和x8的理論帶寬分別是4GB/s和8GB/s;M.2是新一代接口標準,分爲支持PCIe通道和SATA通道兩種,它具有更靈活的物理規範,在傳輸帶寬、容量和輕薄特性等方面優於SATA接口。消費級固態盤主要採用SATA接口和M.2接口,企業級固態盤主要採用SAS接口和PCIe接口。這些物理接口採取的邏輯接口協議一般是AHCI或者NVMe,它們規定了主機與存儲設備之間通信和傳輸數據的方式。AHCI協議主要是針對高延時的SATA接口的機械硬盤而設計的,雖然能夠應用於SATA接口的固態盤,但是成爲了高性能固態盤的瓶頸;NVMe協議是2011年由英特爾等公司領頭,爲閃存存儲和PCIe接口量身定製的非易失性存儲器標準,不僅具有跨平臺的兼容性(目前Windows、Linux和VMware等主流平臺都已經支持),而且相比於AHCI協議,具有更低的延時、更高的IOPS和更低的功耗。比如,AHCI只能支持一條最大深度爲32的命令隊列,而NVMe最多支持64000條最大深度爲64000的命令隊列,能充分利用固態盤內的並行性。因此,NVMe協議能夠更好地發揮出固態盤的高性能優勢,得到了越來越廣泛的應用。
● 多核處理器:
固態盤的管理需要處理諸多複雜的任務,比如主機接口協議、調度算法、FTL算法和緩存算法等,因此需要強有力的多核處理器來提高這些任務的處理效率,從而降低軟件延時。比如,可以使用一個計算核心處理主機接口協議,而使用多個計算核心處理繁重的FTL算法。
● 緩存芯片:
固態盤內置有緩存芯片,一般是DRAM,用於緩存用戶數據和軟件算法的元數據。緩存既能加快數據訪問的速度,提高固態盤的性能,也能夠減少對閃存的寫入,延長固態盤的壽命。緩存用戶數據的部分稱之爲數據緩存,緩存地址映射表的部分稱之爲映射緩存。爲了防止突然掉電導致RAM中的數據丟失,固態盤一般會內置備用電容,並採用適當的數據保護技術,用於保證在突然掉電的情況下,將RAM中關鍵的髒數據刷回閃存。
● 中央控制器:
中央控制器是整個固態盤控制器的核心,負責配置固態盤的工作模式,管理各個模塊之間的通信和數據流。中央控制器內置有小容量的高速SRAM緩存,用於臨時緩存數據。
● 糾錯碼引擎:
糾錯碼引擎對要寫入閃存的數據進行編碼,所增加的糾錯碼冗餘會被寫到閃存頁的額外存儲區中;當需要從閃存中讀取數據時,糾錯碼引擎會對數據和它的糾錯碼冗餘進行解碼。如果發生的比特錯誤數在糾錯能力範圍內,數據中的錯誤就會被糾正,從而得到正確的數據;否則,如果沒有其它的數據恢復手段,存儲的數據就會丟失。編碼和解碼位於訪問閃存的關鍵路徑上,因此糾錯碼引擎通常採用專用的硬件實現,以提高編碼和解碼的效率。爲了降低硬件開銷和解碼延時,糾錯碼引擎會將數據劃分爲固定大小(一般是1KB、2KB或者4KB)的片段,作爲編碼和解碼的單位。一個數據段和它的糾錯碼冗餘稱之爲一個碼字,數據片段的長度與碼字長度的比值稱之爲糾錯碼的碼率。碼率越低,糾錯碼的糾錯能力越強,但是開銷也越大,比如冗餘的存儲開銷和解碼延時都會變大。爲了增加編解碼的並行性,糾錯碼引擎一般包含多個編碼器和解碼器。固態盤常用的糾錯碼算法包括BCH碼和LDPC碼,後者因爲糾錯能力更強而成爲了優先的選擇。
● 通道控制器:
爲了提高性能,固態盤將數量衆多的閃存芯片安置在多個通道上,每個通道上的多個芯片共享一條I/O總線。每個通道包含一個獨立的通道控制器,主要負責與中央控制器和本通道上的閃存芯片進行通信,並維護多條操作閃存的命令隊列(比如爲每個芯片維護一條單獨的隊列,外加一條總的高優先級隊列),將命令發往目標芯片進行執行。所以,固態盤內部具有四個層次的並行結構:通道,芯片,晶圓,分組。高效地利用並行性是保證固態盤高性能的關鍵。
● 閃存芯片:
閃存芯片上既存儲用戶數據,也存儲需要持久化的元數據,比如地址映射表。固態盤提供的物理存儲容量會比用戶可見的容量要多(一般多7% ~ 28%),多餘部分稱之爲過量供應(Over-provisioning, OP)空間,主要用於提高軟件算法(比如垃圾回收操作)的效率和補償因閃存壞塊產生的容量損失。有的固態盤還會在閃存芯片之間組建RAID5,以加強存儲的可靠性。
● DMA引擎:
DMA引擎負責控制在兩個RAM之間進行快速的數據傳輸,比如在中央控制器的SRAM和緩存芯片之間。
不同的固態盤可能在模塊設計上會有所不同,比如在每個通道控制器內配置一對糾錯碼的編碼器和解碼器,而不是配置一個集中的糾錯碼引擎;也可能會包含更多的模塊,比如電源管理模塊、RAID引擎、數據壓縮引擎和加密引擎等等。但是,以上模塊的介紹能夠說明固態盤內部的主要架構。
三. 本文主要針對NVMe主機接口控制器的實現
一般來說NMVe主機接口控制器包括以下幾個部分:
Admin命令和completion隊列處理模塊,IO命令隊列處理模塊,IO completion隊列處理模塊,IO寫數據處理模塊,IO讀數據處理模塊,中斷處理模塊。
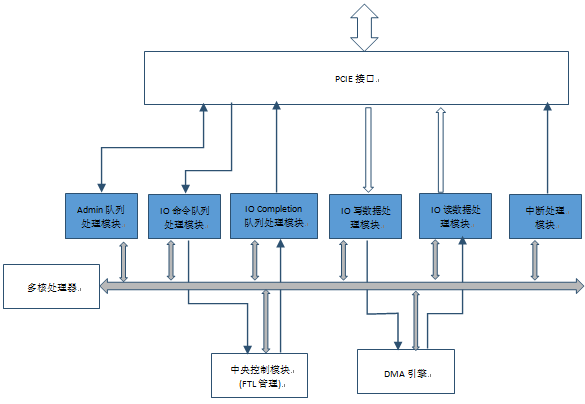
回到NVMe協議棧面臨的挑戰:1)多權重命令隊列的管理和命令抓取,2)命令的解析,分解,分發,3)數據的傳輸。
命令隊列的管理
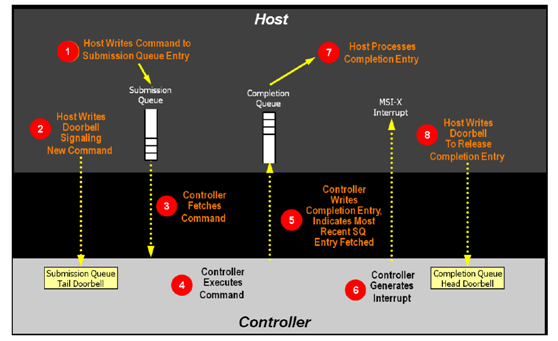
NVMe協議的命令隊列分成兩種,admin命令隊列和IO命令隊列。
Admin命令隊列負責協議的初始化和管理,不負責用戶數據傳輸,對帶寬和響應速度沒有要求,一般可以用負責前端協議處理的CPU固件來處理,即固件來處理admin命令隊列的doorbell,從hostmemory抓取命令,並解析命令;根據命令字段,返回或抓取admin命令的數據段;然後發回completion隊列的completion字段。
IO命令隊列用於數據傳輸,而且支持多達65536個命令隊列(一般根據hostcore的情況命令隊列從16-256不等),數據傳輸對命令隊列的處理要求比較高,SSD控制器的接口控制器需要高效處理命令在各個不同權重的命令隊列的抓取、解析和分發。對主機接口控制器的設計挑戰比較大。對IO命令隊列一般有三種設計思路:1)硬件邏輯處理;2)多核CPU並行固件處理;3)硬件邏輯+CPU固件處理
我們可以比較一下三種思路的優缺點
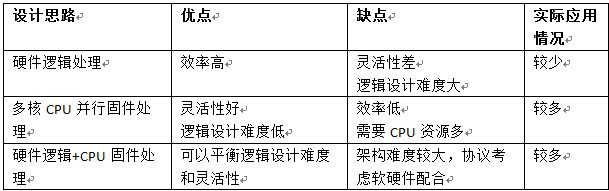
因爲NVMe協議的複雜性,不建議採用純硬件邏輯處理。思路2)和思路3)比較有可行性。
命令隊列的管理要解決幾個難度較大問題,1)是多權重隊列的輪詢次序和優先級問題 2)命令字段的解析分解。3)IO讀寫命令 PRP list處理 4)IO讀寫命令Scatter Gather list處理。
1)是多權重隊列的輪詢次序和優先級問題
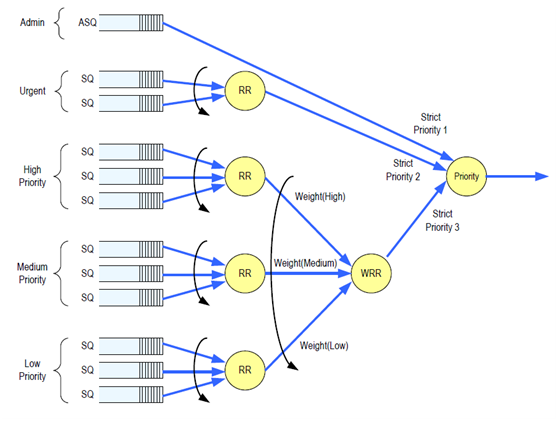
IO命令隊列的輪詢和命令的抓取需要doorbell寄存器的持續輪詢,命令抓取也需要頻繁啓動PCIE IP,不太適合CPU固件完成,會嚴重影響命令的處理效率,每個命令字段固定爲64B,建議由硬件邏輯處理,但要處理不同權重的命令輪詢,需要非常複雜的硬件邏輯,對設計難度考驗極大。
2)命令字段的解析分解
NVMe IO 命令的字段如下。
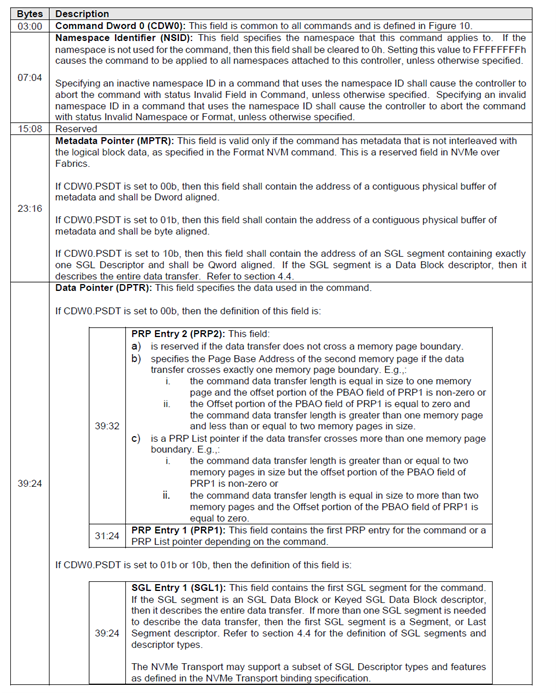

每個IO命令都由64B組成,DWORD0-9字段有固定定義,其他字段根據不同IO命令,有不同意義。而且隨着協議發展,還可能一些新的命令和參數會引入。所以對協議的解析需要CPU固件來完成,這樣可以增加靈活性。
IO命令對應的數據塊在主機側內存中的存放方式有兩種:PRP list 和SGL
PRP list如下圖
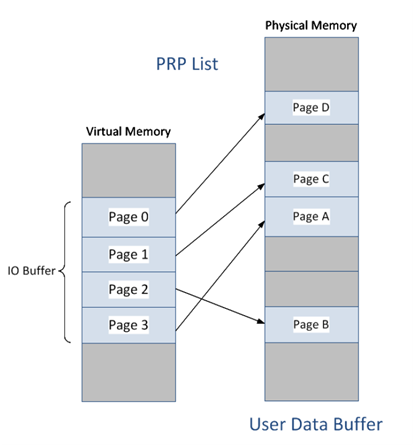
Physical Region Page
SGL 如下圖:
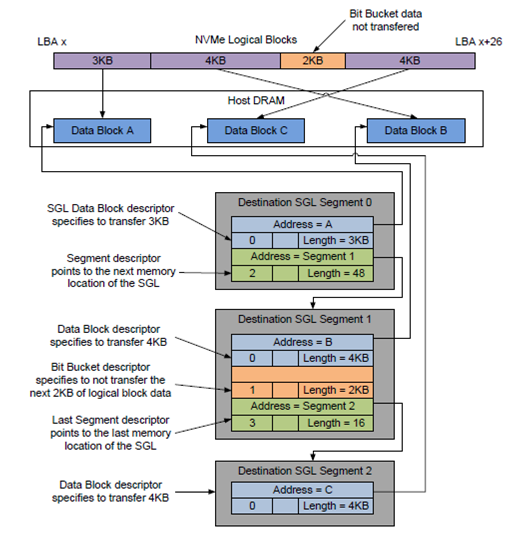
Scatter Gather List
數據在主機側的內存中,一般以4KB爲單位顆粒存放,但顆粒之間物理地址並不連續,而且起始顆粒的offset並不是4KB對齊的。如下圖
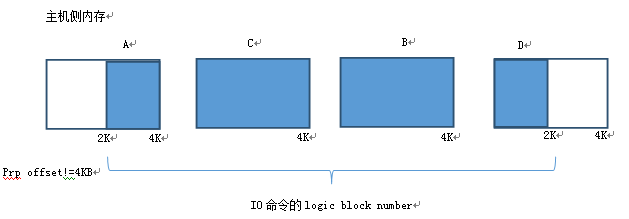
主機控制器在啓動PCIE DMA訪問主機內存時要注意4K不對齊帶來的細節問題,起始塊的非4K對其和塊大小,結尾塊的塊大小,這些塊需要非4K的PCIE DMA傳輸。在處理主機內存訪問時,CPU固件處理能帶來足夠的靈活性,但考慮到主機數據傳輸帶寬性能的高要求,需要硬件做協助或者由硬件處理。比如在PCIE DMA加入PIPE-LINE機制,充分利用PCIE帶寬。
因爲每個IO命令的數據傳輸大小從512B 到256MB不等,對於SSD中央控制器(FTL管理模塊)來說,管理的NAND測數據單元一般是4KB。
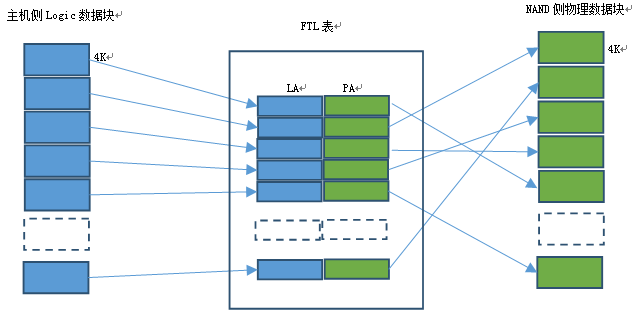
如果主機測IO數據塊大於4KB,每個IO數據塊的傳輸都涉及到數據塊分解的問題,即需要把主機端數據塊分解成FTL管理模塊的4KB顆粒單位。從模塊化分層設計的角度,數據分割功能不太適合放到FTL管理模塊完成,而應該由主機控制模塊完成,NVMe協議部分對FTL控制模塊是透明的。同樣,主機側協議也應該對FTL管理模塊透明。
對於4KB模式LBA,因爲數據的offset是4KB對齊的,主機側數據分解較簡單。
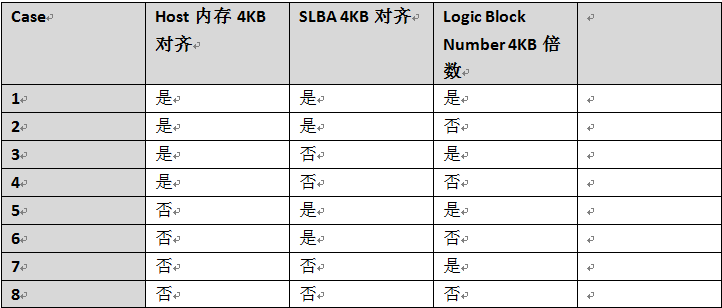
對於LBA非4KB模式(512B,1KB,2KB),主機測數據塊分解爲FTL控制模塊需要的4KB單位情況較爲複雜,case也比較多。每個IO命令的SLBA(Start Logic Address)不一定是4KB對齊的,Logic Block Number也不一定4KB的倍數。所以數據塊分解後的起始第一個塊和最後一個塊有可能不是完整4KB,主機側數據分解後的4K塊數量要同時考慮Logic Block Number 和SLBA不對齊的情況。例如一個12KB(12KB/4KB=3)的主機側數據塊,分解後在FTL NAND側可能會分佈到4個FTL NAND側4KB數據塊。
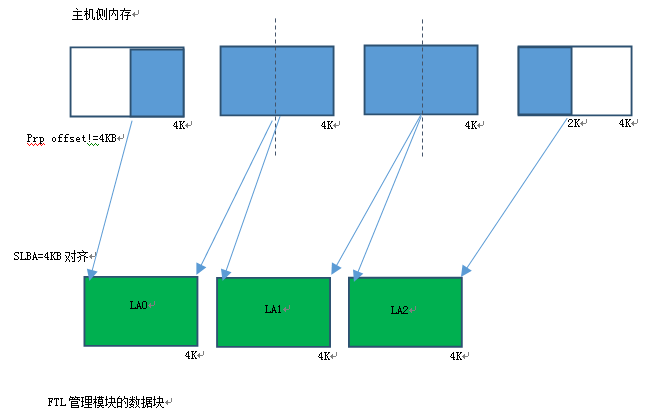
Host內存4KB不對齊,SLBA=4KB對齊,Logic Block Number=4KB整數倍
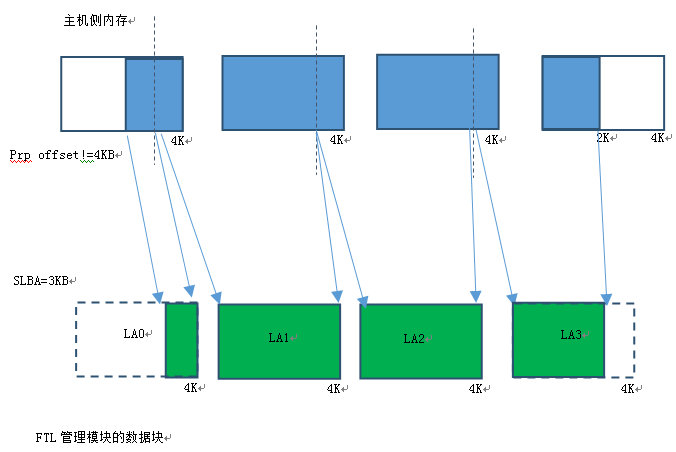
Host內存4KB不對齊,SLBA 4KB不對齊,Logic Block Number=4KB整數倍
從上面兩張圖可以看出,數據塊在主機側內存是否4KB對齊,SLBA是否4KB對齊,Logic Block Number是否是4KB的倍數,會組成很多複雜的情況。比如:數據塊主機側內存4KB不對齊,那麼FTL側看到的4KB在主機側內存會分佈在兩個主機側內存塊裏。
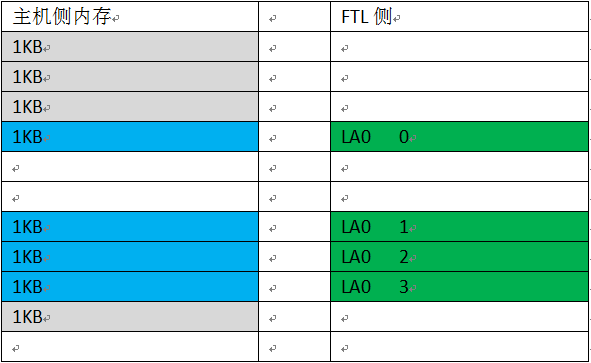
讀者有興趣可以把所有組合整理處來,每種情況數據的分解情況都有不同。
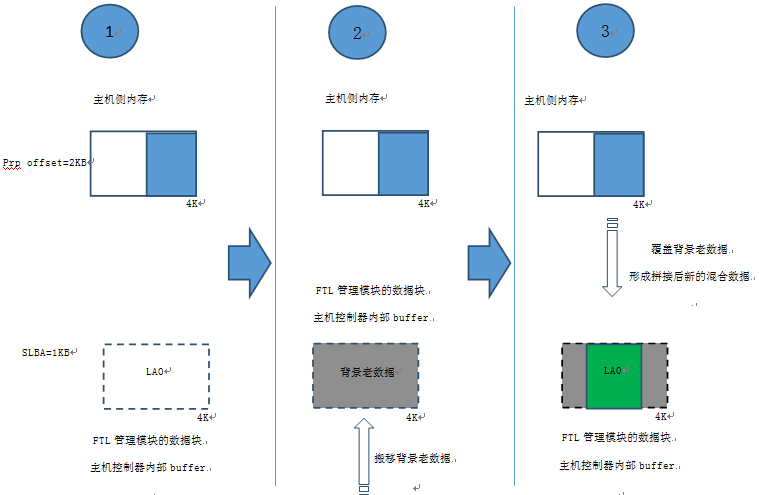
如果分解後的IO數據塊小於4KB(如:512B,1KB,1.5KB,2KB… ….),對寫IO數據,則涉及到不完整部分數據和FTL 4KB數據塊中其他原有背景數據拼接的問題。
NVMe協議是命令控制通路和數據通路分離的,支持多個命令隊列,而且支持命令之間的執行和數據傳輸亂序,命令內分解後的4KB數據塊亂序,所以關於命令之間和命令內控制流數據流的控制也是個很好的話題,技術上也有很多難度,就不在這篇文檔贅述。下一篇重點談這個話題。