




OpenCV -5 -GoogLeNet模型使用及CNN理論
使用語言:Java 1.8
操作系統:windows x64
OpenCV:4.1.1
PS:玩這個的怎麼都是C++啊,用Java玩的真少 ε=(´ο`*)))唉
關於GoogLeNet的介紹
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-tD2wkRmI-1573039315640)(https://static.oschina.net/uploads/space/2018/0317/141419_uDBe_876354.png)]
2014年,GoogLeNet和VGG是當年ImageNet挑戰賽(ILSVRC14)的雙雄,GoogLeNet獲得了第一名、VGG獲得了第二名,這兩類模型結構的共同特點是層次更深了。VGG繼承了LeNet以及AlexNet的一些框架結構。而GoogLeNet則做了更加大膽的網絡結構嘗試,雖然深度只有22層,但大小卻比AlexNet和VGG小很多,GoogleNet參數爲500萬個,AlexNet參數個數是GoogleNet的12倍,VGGNet參數又是AlexNet的3倍,因此在內存或計算資源有限時,GoogleNet是比較好的選擇;從模型結果來看,GoogLeNet的性能卻更加優越。
關於名字:GoogLeNet是谷歌(Google)研究出來的深度網絡結構,爲什麼不叫“GoogleNet”,而叫“GoogLeNet”,據說是爲了向“LeNet”致敬,因此取名爲“GoogLeNet”
神經網絡,深度學習等等的東西的理論真的是灰常的複雜。看着頭皮發麻。w(゚Д゚)w
請自行查看:理論參考資料:
- https://my.oschina.net/u/876354/blog/1637819 【這一篇灰常的好】
- https://dreamocean.github.io/2017/07/01/net-models/
- https://www.jianshu.com/p/cd73bc979ba9 [LeNet神經網絡]
- https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/ [LeNet神經網絡英文原版]
整理的理論小抄
各種理論體系結構
-
**LeNet(1990年代):**最早的卷積神經網絡之一,LeNet主要用來進行手寫字符的識別與分類,並在美國的銀行中投入了使用。LeNet的實現確立了CNN的結構,現在神經網絡中的許多內容在LeNet的網絡結構中都能看到,例如卷積層,Pooling層,ReLU層。雖然LeNet網絡結構比較簡單,但是剛好適合神經網絡的入門學習。
-
**1990年代至2012年:**在1990年代末至2010年代初,卷積神經網絡得到了發展。隨着越來越多的數據和計算能力變得可用,卷積神經網絡可以解決的任務變得越來越有趣。
-
AlexNet(2012)– 2012年,Alex Krizhevsky(及其他人)發佈了AlexNet,它是LeNet的更深,更廣泛的版本,並在2012年以較大的優勢贏得了艱難的ImageNet大規模視覺識別挑戰賽(ILSVRC)。相對於以前的方法和CNN的當前廣泛應用而言,這是一項重大突破,可以歸功於這項工作。
-
ZF Net(2013)– 2013年 ILSVRC冠軍是Matthew Zeiler和Rob Fergus的卷積網絡。它後來被稱爲ZFNet(以下簡稱蔡勒與宏泰網)。通過調整體系結構超參數,這是對AlexNet的改進。
-
GoogLeNet(2014)– 2014年 ILSVRC獲獎者是Szegedy等人的卷積網絡。來自Google。它的主要貢獻是開發了一個Inception模塊,該模塊大大減少了網絡中的參數數量(4M,而AlexNet爲60M)。
-
VGGNet(2014)– ILSVRC 2014 的亞軍是被稱爲VGGNet的網絡。它的主要貢獻在於表明網絡深度(層數)是獲得良好性能的關鍵因素。
-
ResNets(2015)–由Kaiming He(及其他人)開發的殘差網絡贏得了ILSVRC 2015的冠軍。ResNets目前是最先進的卷積神經網絡模型,並且是在實踐中使用ConvNets的默認選擇(截至2016年5月) )。
-
**DenseNet(2016年8月)–**最近由Gao Huang(及其他作者)發表的 Densely Connected卷積網絡 使每一層都以前饋方式直接連接到其他每一層。事實證明,DenseNet在五個高度競爭的對象識別基準測試任務上比以前的最新體系結構有了顯着改進。在此處檢查Torch的實現。
厲害了,原來這種東東90年代就已經有在搞了,還商用了的。
接下來看看LeNet的理論就差不多了,近些年這些高級的,別說算法了,結構可能都看不懂。︿( ̄︶ ̄)︿
LeNet理論
[黑白]圖像本身是一個二維數組,然後卷積核爲n*n的矩陣,然後兩個相乘就是卷積處理了。
在參考的文章裏面有一些圖片灰常簡明的表示了這種算法:




好的,這裏4張圖【侵刪】,表示的分別是:圖像本身數據,卷積示意圖,同一幅圖像用不同卷積核處理的效果,pooling池化運算。
在LeNet網絡除去輸入輸出層總共有六層網絡。就是:卷積,池化,卷積,池化,全連接層,全連接層,對應輸出層。
大概就是這個樣子了,具體的算法我是看不懂的╮(╯_╰)╭:
這裏需要一個實例圖片:LeNet網絡的執行流程圖【侵刪】

{kind=link}
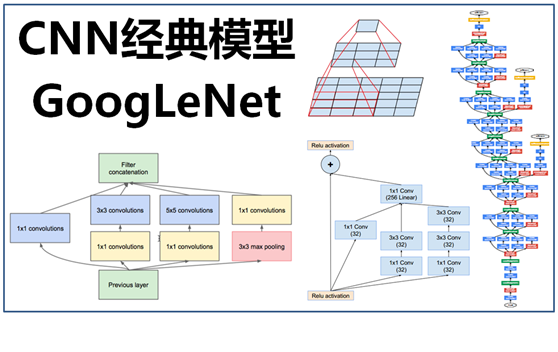
GoogLeNet理論
GoogLeNet用的其實是與LeNet類似的東東,區別在與做了深度,寬度,以及算法的各種加深與優化。
GoogLeNet團隊提出了Inception網絡結構,就是構造一種“基礎神經元”結構,來搭建一個稀疏性、高計算性能的網絡結構。
基於Inception構建了GoogLeNet的網絡結構如下(共22層):
我是不知道這些層具體是幹啥用的 ╮(╯_╰)╭
反正就是很牛逼的感覺:

對上圖說明如下::
牛逼啊!o( ̄▽ ̄)d,666666,簡直神了,wow~ ⊙o⊙
實際使用GoogLeNet
好了,可以忽略那些理論了,實際使用訓練好的模型還是灰常的簡單的。
直接調用加載模型,然後調用一個方法就可以了。╮(╯_╰)╭
理論的東西,只是爲了更好的理解預測方法的結果,只有在自己訓練模型的時候會涉及到的,這個在下一篇要試着弄一下的。
直接代碼說明吧:
代碼中的模型會上傳的資源,也可以去參考文章中找到鏈接地址。
(資源鏈接地址就不太好意思直接copy過來 )
public class GoogleNetToolsTest {
public static void main(String[] args) {
System.load("D:\\OpenCV\\opencv\\build\\java\\x64\\opencv_java411.dll");
imgTest();
}
private static void imgTest() {
/**
* 加載 GoogleNet模型
*/
String bvlc_googlenet = "D:/OpenCV/opencv/sources/samples/data/dnn/google_net/bvlc_googlenet.caffemodel";
String deploy_prototxt = "D:/OpenCV/opencv/sources/samples/data/dnn/google_net/deploy.prototxt";
String labels_txt_file ="D:/OpenCV/opencv/sources/samples/data/dnn/google_net/synset_words.txt";
Net googleNet = readNetFromCaffe(deploy_prototxt, bvlc_googlenet);
// 測試
Mat testImage = Imgcodecs.imread("D:/ijworkspace/meaen_test/data/test1.png");
//GoogLeNet accepts only 224x224 RGB-images
Mat inputBlob = blobFromImage(testImage, 1, new Size(224, 224), new Scalar(104, 117, 123));
googleNet.setInput(inputBlob,"data");
Mat prob = googleNet.forward("prob");
//維度變成1*1000
Mat probMat = prob.reshape(1, 1);
//最大相似度
Core.MinMaxLocResult MMR = Core.minMaxLoc(probMat);
org.opencv.core.Point matchLoc = MMR.maxLoc;
//最大相似度對應的索引
double Nameindex = matchLoc.x;
System.out.println("匹配標籤:"+Nameindex);
//映射訓練標籤集
String lableName = readGoogleNetLabels(labels_txt_file).get((int)Nameindex);
System.out.println("結果:"+matchLoc+"置信度"+MMR.maxVal*100+"%");
System.out.println("匹配標籤:"+lableName);
}
/**
* 加載GoogleNet對應額標籤文件 可以識別的1000個標籤
* @return
*/
private static List<String> readGoogleNetLabels(String lablesTxt) {
List lables = new ArrayList<String>();
File file = new File(lablesTxt);
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
String tempString = null;
// 一次讀入一行,直到讀入null爲文件結束
while ((tempString = reader.readLine()) != null) {
// 顯示行號
lables.add(tempString.substring(10));
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
return lables;
}
}
結果
使用的方式還是和之前的年齡性別預測一樣樣的。
這裏說明一下,測試了一些圖片,對任務識別不了,物體識別中對於主體比較突出的識別率還是很高的。如果識別的物體很小的話,識別率就偏低了。
以下是比較好的測試圖片識別結果:

實際使用參考文章:
- https://blog.csdn.net/qq_30815237/article/details/87916157【模型文件在此參考文章給出了】
- https://blog.csdn.net/Daker_Huang/article/details/86736072
小結一下
寫到這裏使用這個模型,果然還是覺得現在查的資料,用java來玩的真少 ε=(´ο`*)))唉
相對於使用來說,想要理解CNN之類的這種算法,對於我這種普通人來說,頭疼。。都看不怎麼懂!
計劃一下,接下來就是試試自己來訓練個模型玩一下了。(想想都暈 (¦3」∠)
2019-11-06 小杭 ୧(๑•̀◡•́๑)૭