




https://plantegg.github.io/2019/12/24/Linux%E5%86%85%E6%A0%B8%E7%89%88%E6%9C%AC%E5%8D%87%E7%BA%A7%EF%BC%8C%E6%80%A7%E8%83%BD%E5%88%B0%E5%BA%95%E6%8F%90%E5%8D%87%E5%A4%9A%E5%B0%91%EF%BC%9F%E6%8B%BF%E6%95%B0%E6%8D%AE%E8%AF%B4%E8%AF%9D/
背景
X 產品在公有云售賣一直使用的2.6.32的內核,有點老並且有些內核配套工具不能用,於是想升級一下內核版本。預期新內核的性能不能比2.6.32差
以下不作特殊說明的話都是在相同核數的Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz下得到的數據,最後還會比較相同內核下不同機型/CPU型號的性能差異。
場景都是用sysbench 100個併發跑點查。
結論
先說大家關心的數據,最終4.19內核性能比2.6.32好將近30%,建議大家升級新內核,不需要做任何改動,尤其是Java應用(不同場景會有差異)
本次比較的場景是Java應用的Proxy類服務,主要瓶頸是網絡消耗,類似於MaxScale。後面有一個簡單的MySQL Server場景下2.6.32和4.19的比較,性能也有33%的提升。
2.6.32性能數據
升級前先看看目前的性能數據好對比(以下各個場景都是CPU基本跑到85%)
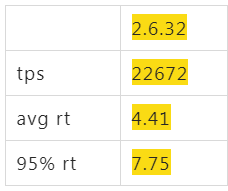
一波N折的4.19
阿里雲上默認買到的ALinux2 OS(4.19),同樣配置跑起來後,tps只有16000,比2.6.32的22000差了不少,心裏只能暗暗罵幾句坑爹的貨,看了下各項指標,看不出來什麼問題,就像是CPU能力不行一樣。如果這個時候直接找內核同學,估計他們心裏會說 X 是個什麼東西?是不是你們測試有問題,是不是你們配置的問題,不要來坑我,內核性能我們每次發佈都在實驗室裏跑過了,肯定是你們的應用問題。
所以要找到一個公認的場景下的性能差異。幸好通過qperf發現了一些性能差異。
通過qperf來比較差異
大包的情況下性能基本差不多,小包上差別還是很明顯
qperf -t 40 -oo msg_size:1 4.19 tcp_bw tcp_lat
tcp_bw:
bw = 2.13 MB/sec
tcp_lat:
latency = 224 us
tcp_bw:
bw = 2.15 MB/sec
tcp_lat:
latency = 226 us
qperf -t 40 -oo msg_size:1 2.6.32 tcp_bw tcp_lat
tcp_bw:
bw = 82 MB/sec
tcp_lat:
latency = 188 us
tcp_bw:
bw = 90.4 MB/sec
tcp_lat:
latency = 229 us
這下不用擔心內核同學懟回來了,拿着這個數據直接找他們,可以穩定重現。
經過內核同學排查後,發現默認鏡像做了一些安全加固,簡而言之就是CPU拿出一部分資源做了其它事情,比如旁路攻擊的補丁之類的,需要關掉(因爲 X 的OS只給我們自己用,上面部署的代碼都是X 產品自己的代碼,沒有客戶代碼,客戶也不能夠ssh連上X 產品節點)
去掉 melt、spec 能到20000, 去掉sonypatch能到21000
關閉的辦法在grub配置中增加這些參數:
nopti nospectre_v2 nospectre_v1 l1tf=off nospec_store_bypass_disable no_stf_barrier mds=off mitigations=off
關掉之後的狀態看起來是這樣的:
$sudo cat /sys/devices/system/cpu/vulnerabilities/*
Mitigation: PTE Inversion
Vulnerable; SMT Host state unknown
Vulnerable
Vulnerable
Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerable, STIBP: disabled
4.9版本的內核性能
但是性能還是不符合預期,總是比2.6.32差點。在中間經過幾個星期排查不能解決問題,陷入僵局的過程中,嘗試了一下4.9內核,果然有驚喜。
下圖中對4.9的內核版本驗證發現,tps能到24000,明顯比2.6.32要好,所以傳說中的新內核版本性能要好看來是真的,這下堅定了升級的念頭,同時也看到了兜底的方案–最差就升級到4.9
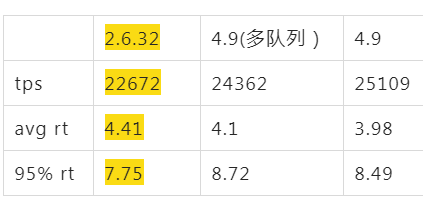
多隊列是指網卡多隊列功能,也是這次升級的一個動力。看起來在沒達到單核瓶頸前,網卡多隊列性能反而差點,這也符合預期
繼續分析爲什麼4.19比4.9差了這麼多
4.9和4.19這兩個內核版本隔的近,比較好對比分析內核參數差異,4.19跟2.6.32差太多,比較起來很困難。
最終仔細對比了兩者配置的差異,發現ALinux的4.19中 transparent_hugepage 是 madvise ,這對Java應用來說可不是太友好:
$cat /sys/kernel/mm/transparent_hugepage/enabled
always [madvise] never
將其改到 always 後4.19的tps終於穩定在了28300
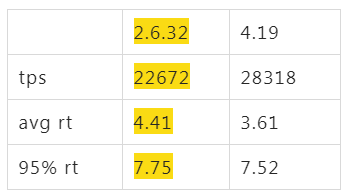
這個過程中花了兩個月的一些其他折騰就不多說了,主要是內核補丁和transparent_hugepage導致了性能差異。
transparent_hugepage,在redis、mongodb、memcache等場景(很多小內存分配)是推薦關閉的,所以要根據不同的業務場景來選擇開關。
透明大頁打開後在內存緊張的時候會觸發sys飆高對業務會導致不可預期的抖動,同時存在已知內存泄漏的問題,我們建議是關掉的,如果需要使用,建議使用madvise方式或者hugetlbpage
一些內核版本、機型和CPU的總結
到此終於看到不需要應用做什麼改變,整體性能將近有30%的提升。 在這個測試過程中發現不同CPU對性能影響很明顯,相同機型也有不同的CPU型號(性能差異在20%以上–這個太坑了)
性能方面 4.19>4.9>2.6.32
沒有做3.10內核版本的比較
以下僅作爲大家選擇ECS的時候做參考。
不同機型/CPU對性能的影響
還是先說結論:
- CPU:內存爲1:2機型的性能排序:c6->c5->sn1ne->hfc5->s1
- CPU:內存爲1:4機型的性能排序:g6->g5->sn2ne->hfg5->sn2
性能差異主要來源於CPU型號的不同
c6/g6: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
c5/g5/sn1ne/sn2ne: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
8269比8163大概好5-10%,價格便宜一點點,8163比E5-2682好20%以上,價格便宜10%(該買什麼機型你懂了吧,價格是指整個ECS,而不是單指CPU)
要特別注意sn1ne/sn2ne 是8163和E5-2682 兩種CPU型號隨機的,如果買到的是E5-2682就自認倒黴吧
C5的CPU都是8163,相比sn1ne價格便宜10%,網卡性能也一樣。但是8核以上的sn1ne機型就把網絡性能拉開了(價格還是維持c5便宜10%),從點查場景的測試來看網絡不會成爲瓶頸,到16核機型網卡多隊列纔會需要打開。
順便給一下部分機型的包月價格比較:
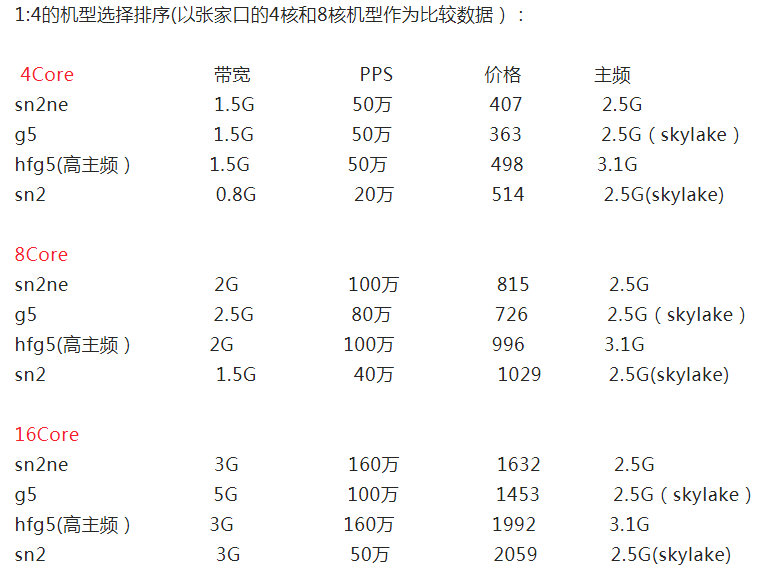
官方給出的CPU數據:
4.19內核在MySQL Server場景下的性能比較
這只是sysbench點查場景粗略比較,因爲本次的目標是對X 產品性能的改進
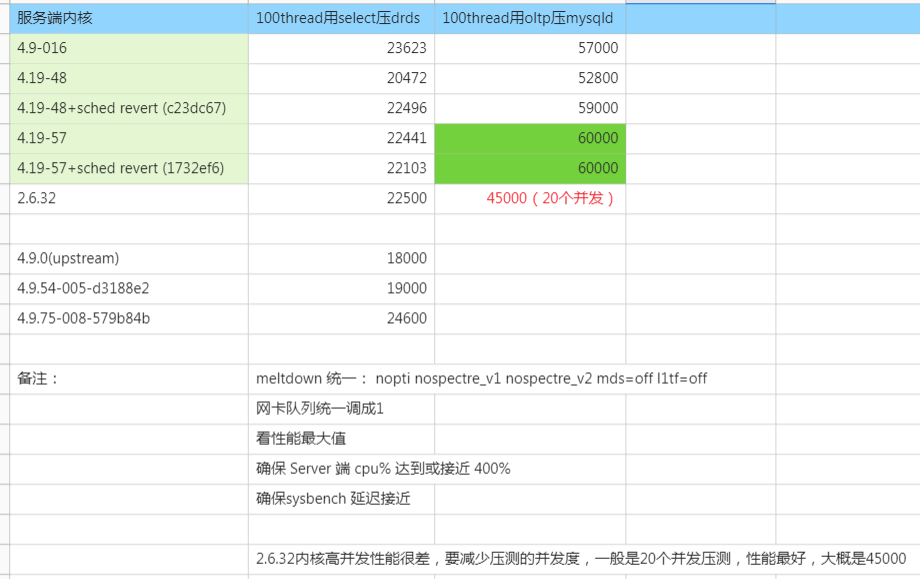
(以上表格數據主要由 內核團隊和我一起測試得到)
重點注意2.6.32不但tps差30%,併發能力也差的比較多,如果同樣用100個併發壓2.6.32上的MySQL,TPS在30000左右。只有在減少併發到20個的時候壓測才能達到圖中最好的tps峯值:45000.
新內核除了性能提升外帶來的便利性
升級內核帶來的性能提升只是在極端場景下才會需要,大部分時候我們希望節省開發人員的時間,提升工作效率。於是X 產品在新內核的基礎上定製如下一些便利的工具。
麻煩的網絡重傳率
通過tsar或者其它方式發現網絡重傳率有點高,有可能是別的管理端口重傳率高,有可能是往外連其它服務端口重傳率高等,尤其是在整體流量小的情況下一點點管理端口的重傳包拉昇了整個機器的重傳率,嚴重干擾了問題排查,所以需要進一步確認重傳發生在哪個進程的哪個端口上,是否真正影響了我們的業務。
在2.6.32內核下的排查過程是:抓包,然後寫腳本分析(或者下載到本地通過wireshark分析),整個過程比較麻煩,需要的時間也比較長。那麼在新鏡像中我們可以利用內核自帶的bcc來快速得到這些信息
sudo /usr/share/bcc/tools/tcpretrans -l
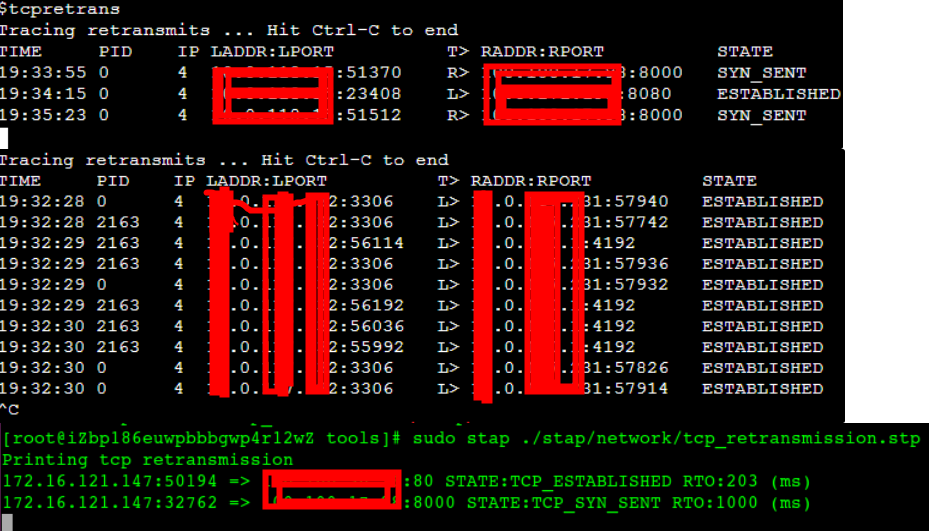
從截圖可以看到重傳時間、pid、tcp四元組、狀態,針對重傳發生的端口和階段(SYN_SENT握手、ESTABLISHED)可以快速推斷導致重傳的不同原因。
再也不需要像以前一樣抓包、下載、寫腳本分析了。
通過perf top直接看Java函數的CPU消耗
這個大家都比較瞭解,不多說,主要是top的時候能夠把java函數給關聯上,直接看截圖:
sh ~/tools/perf-map-agent/bin/create-java-perf-map.sh pid
sudo perf top
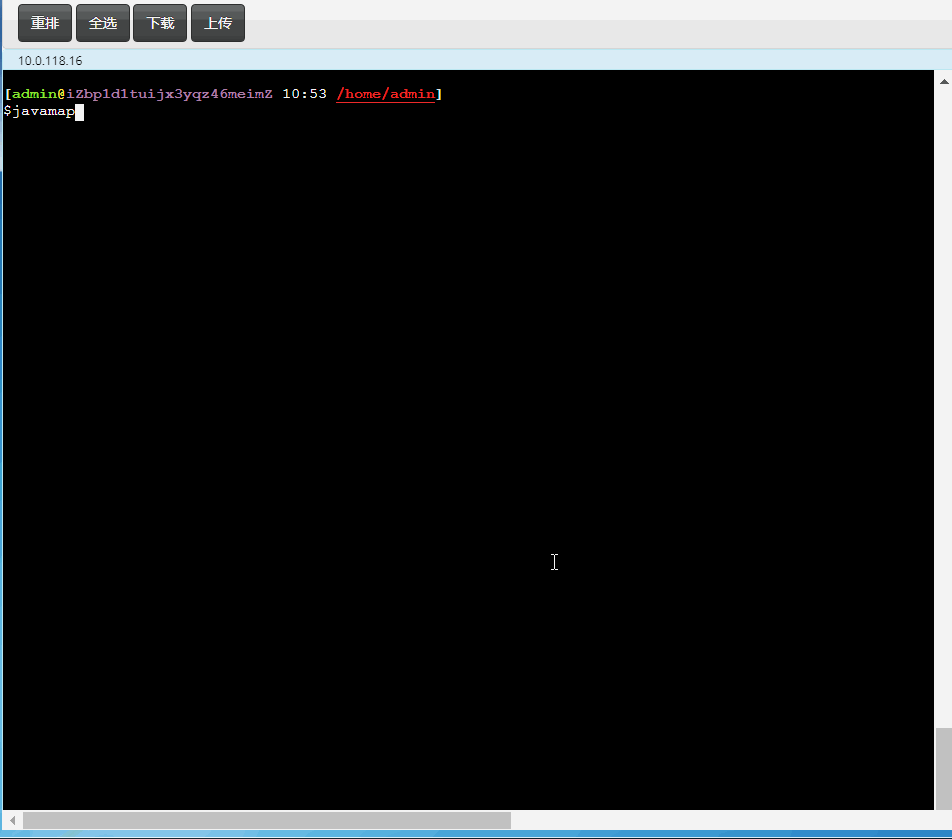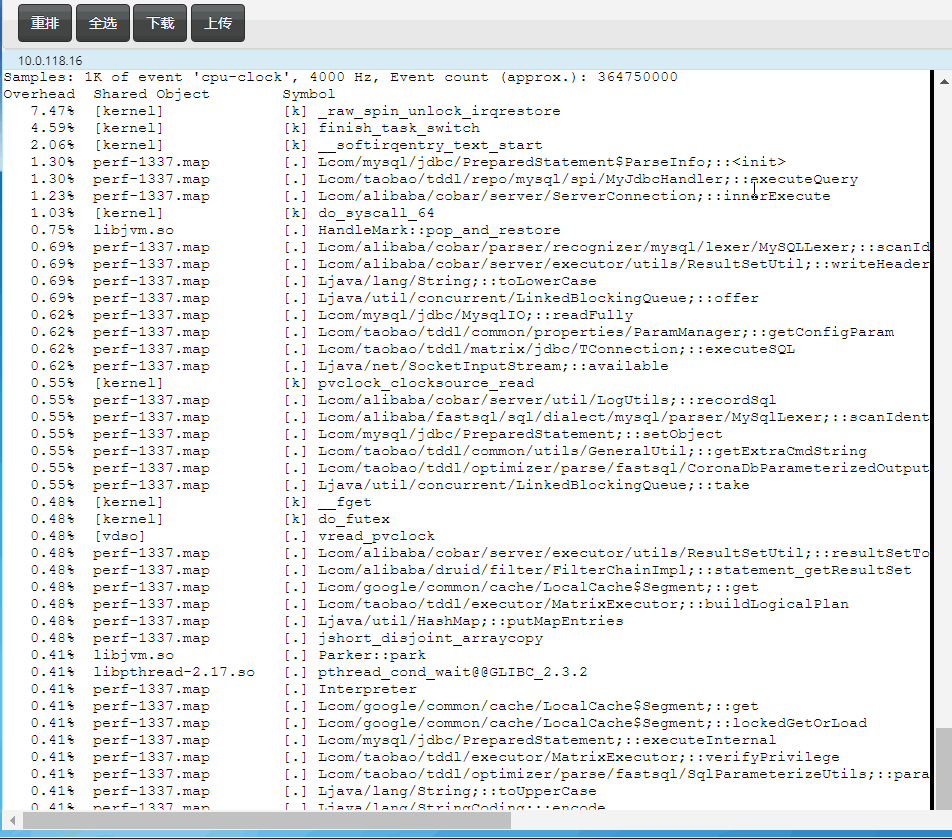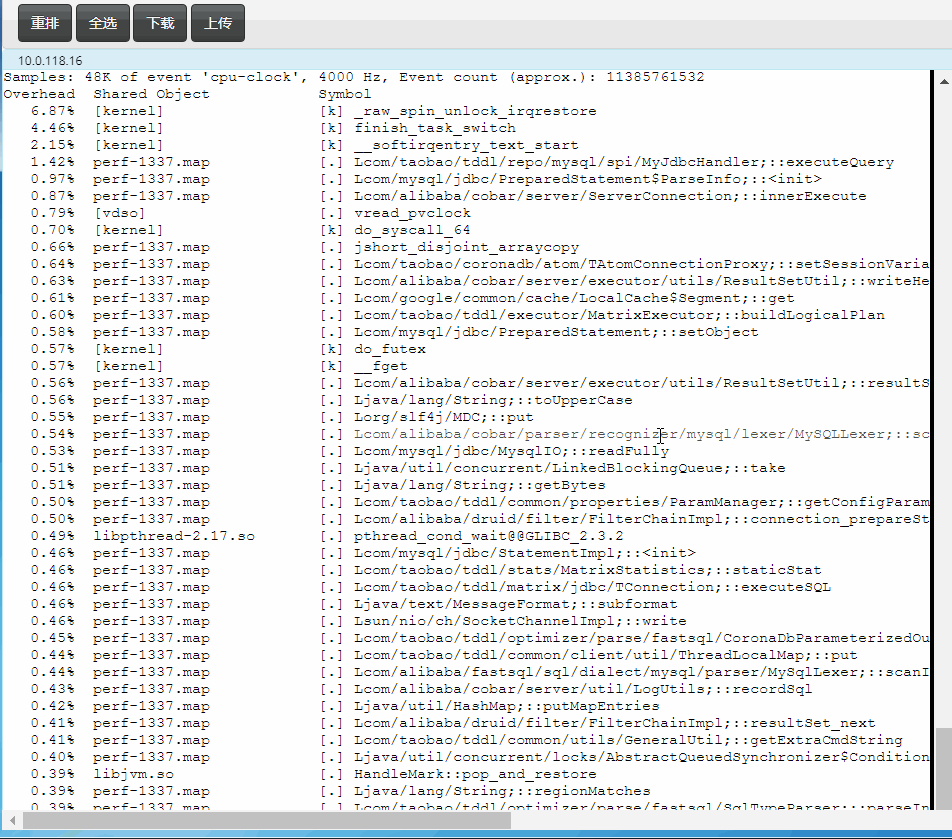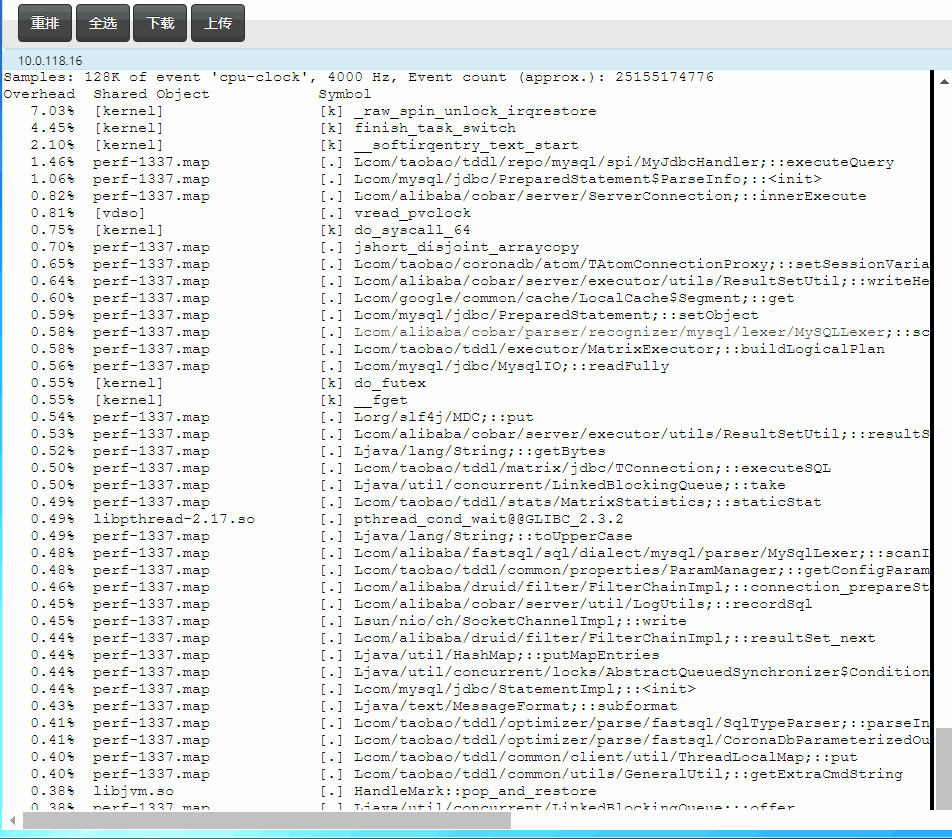
快速定位Java中的鎖等待
如果CPU跑不起來,可能會存在鎖瓶頸,需要快速找到它們
如下測試中上面的11萬tps是解決掉鎖後得到的,下面的4萬tps是沒解決鎖等待前的tps:
#[ 210s] threads: 400, tps: 0.00, reads/s: 115845.43, writes/s: 0.00, response time: 7.57ms (95%)
#[ 220s] threads: 400, tps: 0.00, reads/s: 116453.12, writes/s: 0.00, response time: 7.28ms (95%)
#[ 230s] threads: 400, tps: 0.00, reads/s: 116400.31, writes/s: 0.00, response time: 7.33ms (95%)
#[ 240s] threads: 400, tps: 0.00, reads/s: 116025.35, writes/s: 0.00, response time: 7.48ms (95%)
#[ 250s] threads: 400, tps: 0.00, reads/s: 45260.97, writes/s: 0.00, response time: 29.57ms (95%)
#[ 260s] threads: 400, tps: 0.00, reads/s: 41598.41, writes/s: 0.00, response time: 29.07ms (95%)
#[ 270s] threads: 400, tps: 0.00, reads/s: 41939.98, writes/s: 0.00, response time: 28.96ms (95%)
#[ 280s] threads: 400, tps: 0.00, reads/s: 40875.48, writes/s: 0.00, response time: 29.16ms (95%)
#[ 290s] threads: 400, tps: 0.00, reads/s: 41053.73, writes/s: 0.00, response time: 29.07ms (95%)
下面這行命令得到如下等鎖的top 10堆棧(async-profiler):
$~/tools/async-profiler/profiler.sh -e lock -d 5 1560
--- 1687260767618 ns (100.00%), 91083 samples
[ 0] ch.qos.logback.classic.sift.SiftingAppender
[ 1] ch.qos.logback.core.AppenderBase.doAppend
[ 2] ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders
[ 3] ch.qos.logback.classic.Logger.appendLoopOnAppenders
[ 4] ch.qos.logback.classic.Logger.callAppenders
[ 5] ch.qos.logback.classic.Logger.buildLoggingEventAndAppend
[ 6] ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus
[ 7] ch.qos.logback.classic.Logger.info
[ 8] com.*****.logger.slf4j.Slf4jLogger.info
[ 9] com.*****.utils.logger.support.FailsafeLogger.info
[10] com.*****.util.LogUtils.recordSql
"ServerExecutor-3-thread-480" #753 daemon prio=5 os_prio=0 tid=0x00007f8265842000 nid=0x26f1 waiting for monitor entry [0x00007f82270bf000]
java.lang.Thread.State: BLOCKED (on object monitor)
at ch.qos.logback.core.AppenderBase.doAppend(AppenderBase.java:64)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
at ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:48)
at ch.qos.logback.classic.Logger.appendLoopOnAppenders(Logger.java:282)
at ch.qos.logback.classic.Logger.callAppenders(Logger.java:269)
at ch.qos.logback.classic.Logger.buildLoggingEventAndAppend(Logger.java:470)
at ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus(Logger.java:424)
at ch.qos.logback.classic.Logger.info(Logger.java:628)
at com.****.utils.logger.slf4j.Slf4jLogger.info(Slf4jLogger.java:42)
at com.****.utils.logger.support.FailsafeLogger.info(FailsafeLogger.java:102)
at com.****.util.LogUtils.recordSql(LogUtils.java:115)
ns percent samples top
---------- ------- ------- ---
160442633302 99.99% 38366 ch.qos.logback.classic.sift.SiftingAppender
12480081 0.01% 19 java.util.Properties
3059572 0.00% 9 com.***.$$$.common.IdGenerator
244394 0.00% 1 java.lang.Object
堆棧中也可以看到大量的:
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- locked <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
當然還有很多其他爽得要死的命令,比如一鍵生成火焰圖等,不再一一列舉,可以從業務層面的需要從這次鏡像升級的便利中將他們固化到鏡像中,以後排查問題不再需要繁瑣的安裝、配置、調試過程了。
跟內核無關的應用層的優化
到此我們基本不用任何改動得到了30%的性能提升,但是對整個應用來說,通過以上工具讓我們看到了一些明顯的問題,還可以從應用層面繼續提升性能。
如上描述通過鎖排序定位到logback確實會出現鎖瓶頸,同時在一些客戶場景中,因爲網盤的抖動也帶來了災難性的影響,所以日誌需要異步處理,經過異步化後tps 達到了32000,關鍵的是rt 95線下降明顯,這個rt下降對X 產品這種Proxy類型的應用是非常重要的(經常被客戶指責多了一層轉發,rt增加了)。
日誌異步化和使用協程後的性能數據:
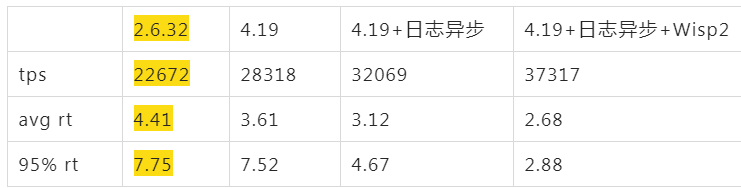
Wisp2 協程帶來的紅利
在整個測試過程中都很順利,只是發現Wisp2在阻塞不明顯的場景下,抖的厲害。簡單來說就是壓力比較大的話Wisp2表現很穩定,一旦壓力一般(這是大部分應用場景),Wisp2表現像是一會是協程狀態,一會是沒開攜程狀態,系統的CS也變化很大。
比如同一測試過程中tps抖動明顯,從15000到50000:
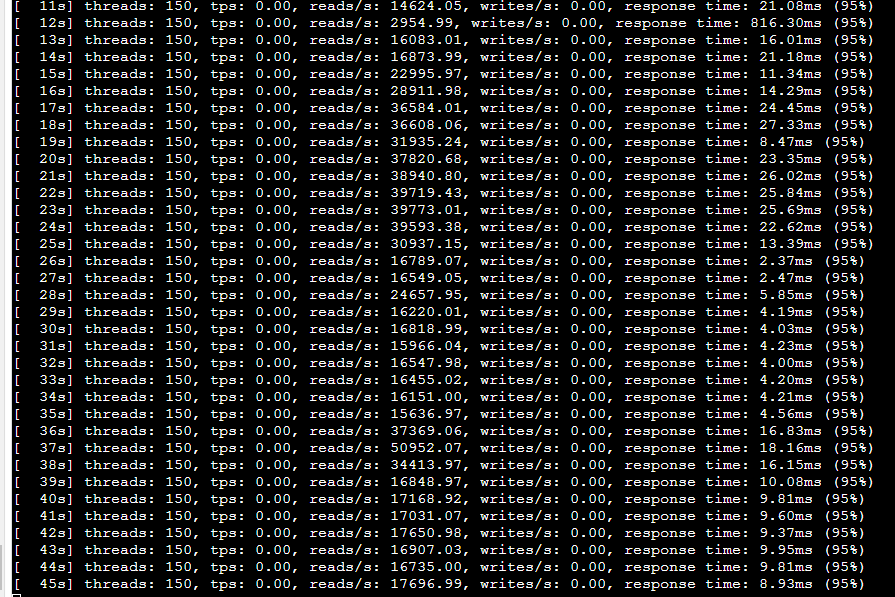
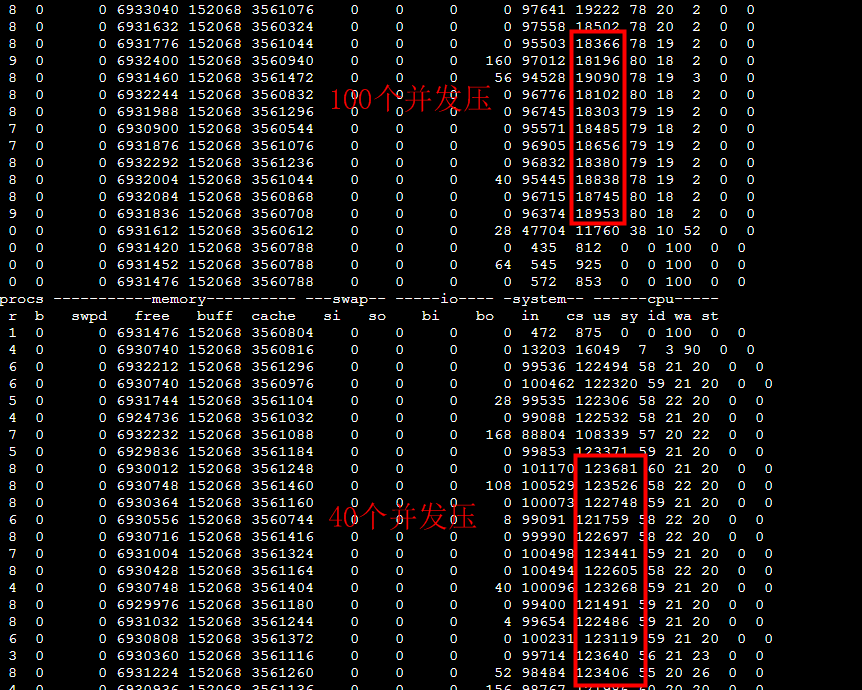
100個併發的時候cs很小,40個併發的時候cs反而要大很多:
最終在 @梁希 同學的攻關下發布了新的jdk版本,問題基本都解決了。不但tps提升明顯,rt也有很大的下降。
致謝
感謝 @夷則 團隊對這次內核版本升級的支持,感謝 @雛雁 @飛緒 @李靖軒(無牙) @齊江(窅默) @梁希 等大佬的支持。
最終應用不需要任何改動可以得到 30%的性能提升,經過開啓協程等優化後應用有將近80%的性能提升,同時平均rt下降了到原來的60%,rt 95線下降到原來的40%。
快點升級你們的內核,用上協程吧。同時考慮下在你們的應用中用上X 產品。