



原创 xgb lgb 自定義評價函數差別
關於xgb lgb自定義評價函數,其實是區別的, 但步驟都是一樣的 XGB: #自定義評價函數---適用於XGBClassifier #preds是預測結果概率-但是需要轉換成label #dtrain是xgb的矩陣,使用get_
 2020-06-02 12:31:58
2020-06-02 12:31:58
原创 NLP實踐三-----特徵選擇
通過對句子的預處理,拿 中文來說,去標點,去停用詞,分詞後,我們可以表示出文本的特徵了,當然這裏還需要截取句子的長度,因爲文本有長有短,機器學習需要輸入相同長度的向量特徵,然後基礎的就是將文本向量化,比如每個單詞出現的頻數,這個
2020-06-02 12:31:58
 1
1
原创 python 時間操作--數據分析
記錄python 對時間的操作整理,數據分析使用 #pd.to_datatime() 可以將str類型的直接轉換成datatime 類型的數據,便於數據分析,format根據str的格式自己調整就好了 action['actio
2020-06-02 12:31:58
2
原创 NLP實踐五-----nn基礎(fasttext實踐)
文章目錄簡要原理代碼實踐 簡要原理 fastText的兩個任務是分類和訓練詞向量,傳統的word2vec把語料庫的每個單詞當作原子的,爲每個單詞生成一個詞向量,而fastText是對每個字符進行處理的,也就是字符級別的n_gram
2020-06-02 12:31:58
原创 NLP實踐七-----卷積神經網絡
文章目錄卷積原理卷積一維卷積二維卷積卷積核的步長padding池化textcnn原理介紹:https://www.cnblogs.com/bymo/p/9675654.html代碼實踐 卷積原理 卷積神經網絡是受生物學上感受野的機
2020-06-02 12:31:58
原创 NLP實踐一----數據探索
nlp實踐(一)----數據探索 對IMDB數據集 : 首先就是對序列進行補全,然後利用embedding(隨機初始化詞向量) 喂入網絡,平均池化,16維的全連接和1維的輸出層 import keras imdb = keras.
2020-06-02 12:31:58
原创 NLP實踐二----語言處理技術
基本文本處理技能:中英文字符串處理(刪除不相關的字符、去停用詞);分詞(結巴分詞);詞、字符頻率統計。 語言模型;unigram、bigram、trigram頻率統計。 結巴分詞介紹和使用 1.中英文字符串處理 #直接使用app
2020-06-02 12:31:58
1
原创 python 安裝.whl文件怎麼選格式
whl文件地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/ 怎麼看自己支持的格式: 在終端輸入python: 文件後綴cp表示版本python,win64就是64位的,fasttext
2019-06-11 06:37:34
原创 NLP實踐五-----nn基礎
文章目錄激活函數深度學習中的正則化深度模型中的優化1.權重初始化2.自適應學習率算法fastText1. 原理2.代碼實踐 激活函數 概念:激活函數是對某一個隱藏層的結點進行非線性激活操作,分爲以下步驟: (1)輸入該節點的值爲
2019-06-11 06:37:34
原创 分位數和箱線圖
1.什麼是分位數? 簡單說就是指將一個隨機變量的概率分佈範圍分爲幾個等份的數值點,常用的有中位數(即二分位數)、四分位數、百分位數等。 Q1-數據中有25%個數據都比它小,第一分位數 Q2-中位數 Q3-數據中有75%個數據都比它
2019-06-11 06:37:34
6
原创 NLP實踐八-----RNN
文章目錄RNN的結構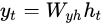 這篇文章詳細介紹了流程: https://zhuanlan.zhihu.com/p
2019-06-11 06:37:34
原创 NLP實踐五-----樸素貝葉斯,SVM,LDA主題模型
樸素貝葉斯 1. 原理 樸素貝葉斯的原理是基於貝葉斯定理的,我們要求的就是後驗概率P(Cj|x),這裏x就是特徵向量,Cj就是類別j,後驗概率最大的P(Cj|x)對於的類j就是樣本特徵爲x對於的類別,其中我認爲它的假設是最影響它
2019-06-11 06:37:34
原创 NLP實踐四-----詞袋模型 + 詞向量 + word2vec
Task4 文本表示:從one-hot到word2vec (2 days) 詞袋模型:離散、高維、稀疏。 分佈式表示:連續、低維、稠密。word2vec詞向量原理並實踐,用來表示文本。 參考: word2vec 中的數學原理詳解
2019-06-11 06:37:34
原创 numpy 操作記錄
記錄平時使用的numpy的一些操作 參考文章:numpy 生成ndarray np.arange(start,end,step) ------前閉後開,與range類似,但是支持小數。 np.linespace((start, s
2019-04-12 01:21:09