




轉載自:http://xgj2008best.blog.163.com/blog/static/545841572011961751307/
1:內存對齊定義:
現在使用的計算機中內存空間都是按照字節劃分的,從理論上講似乎對任何類型的變量的訪問可以從任何地址開始,但是實際上計算機系統對於基本數據類型在內存中的存放位置都有限制,要求這些數據存儲首地址是某個數K的倍數,這樣各種基本數據類型在內存衝就是按照一定的規則排列的,而不是一個緊挨着一個排放,這就是內存對齊。
對齊模數:
內存對齊中指定的對齊數值K成爲對齊模數(Alignment Modulus)。當一種類型S的對齊模數與另一種類型T的對齊模數的比值是大於1的整數,我們就稱類型S的對齊要求比T強(嚴格),而稱T比S弱(寬鬆)。
2:內存對齊的好處:
內存對齊作爲一種強制的要求,第一簡化了處理器與內存之間傳輸系統的設計,第二可以提升讀取數據的速度。各個硬件平臺對存儲空間的處理上有很大的不同。一些平臺對某些特定類型的數據只能從某些特定地址開始存取。比如有些架構的CPU在訪問一個沒有進行對齊的變量的時候會發生錯誤,那麼在這種架構下編程必須保證字節對齊.其他平臺可能沒有這種情況,但是最常見的是如果不按照適合其平臺要求對數據存放進行對齊,會在存取效率上帶來損失。比如有些平臺每次讀都是從偶地址開始,如果一個int型(假設爲32位系統)如果存放在偶地址開始的地方,那麼一個讀週期就可以讀出這32bit,而如果存放在奇地址開始的地方,就需要2個讀週期,並對兩次讀出的結果的高低字節進行拼湊才能得到該32bit數據。顯然在讀取效率上下降很多。
Intel的IA32架構的處理器則不管數據是否對齊都能正確工作。但是如果想提升性能,應該注意內存對齊方式。
ANSI C標準中並沒有規定相鄰聲明的變量在內存中一定要相鄰。爲了程序的高效性,內存對齊問題由編譯器自行靈活處理,這樣導致相鄰的變量之間可能會有一些填充字節。對於基本數據類型(int char等),他們佔用的內存空間在一個確定硬件系統下有確定的值。ANSI C規定一種結構類型的大小是它所有字段的大小以及字段之間或字段尾部的填充區大小之和。
3:內存對齊策略:
微軟C編譯器(cl.exe for 80×86)的對齊策略:
第一: 結構體變量的首地址能夠被其最寬基本類型成員的大小所整除;
備註:編譯器在給結構體開闢空間時,首先找到結構體中最寬的基本數據類型,然後尋找內存地址能被該基本數據類型所整除的位置,作爲結構體的首地址。將這個最寬的基本數據類型的大小作爲上面介紹的對齊模數。
第二: 結構體每個成員相對於結構體首地址的偏移量(offset)都是成員大小的整數倍,如有需要編譯器會在成員之間加上填充字節(internal adding);
備註:爲結構體的一個成員開闢空間之前,編譯器首先檢查預開闢空間的首地址相對於結構體首地址的偏移是否是本成員的整數倍,若是,則存放本成員,反之,則在本成員和上一個成員之間填充一定的字節,以達到整數倍的要求,也就是將預開闢空間的首地址後移幾個字節。
第三: 結構體的總大小爲結構體最寬基本類型成員大小的整數倍,如有需要,編譯器會在最末一個成員之後加上填充字節(trailing padding)。
備註:結構體總大小是包括填充字節,最後一個成員滿足上面兩條以外,還必須滿足第三條,否則就必須在最後填充幾個字節以達到本條要求。
填充字節就是爲了使結構體字段滿足內存對齊要求而額外分配給結構體的空間。對於結構體本身也存在着對齊要求,ANSI C標準規定結構體類型的對齊要求不能比它所有字段中要求最嚴格的那個寬鬆,但是可以更嚴格(但此非強制要求,VC7.1就僅僅是讓它們一樣嚴格)。C標準保證,任何類型(包括自定義結構類型)的數組所佔空間的大小一定等於一個單獨的該類型數據的大小乘以數組元素的個數。換句話說,數組各元素之間不會有空隙。
總結規則如下:
0: 結構體變量的首地址能夠被其最寬基本類型成員的大小所整除
1: VC6和VC71默認的內存對齊方式是 #pragam pack(8)
2: 結構體中每個成員按其類型的對齊參數(通常是這個類型的大小)和指定對齊參數中較小的一個對齊.
3: 結構體每個成員相對於結構體首地址的偏移量都是成員大小的整數倍.
4: 結構體本身也存在着對齊要求規則,不能比它所有字段中要求最嚴格的那個寬鬆.
5: 結構體的總大小爲結構體最寬基本類型成員大小的整數倍,且應儘量節省內存。
6: 在GCC中,對齊模數的準則是:對齊模數最大隻能是 4,也就是說,即使結構體中有double類型,對齊模數還是4,所以對齊模數只能是1,2,4。
而且在上述的規則中,第3條裏,offset必須是成員大小的整數倍:
(1): 如果這個成員大小小於等於4則按照上述準則是可行的,
(2): 如果成員的大小大於4,則結構體每個成員相對於結構體首地址的偏移量只能按照是4的整數倍來進行判斷是否添加填充。
例子1(VC8):
typedef struct ms1 {
char a;
int b;
} MS1;
typedef struct ms2 {
int a;
char b;
} MS2;
MS1中有最強對齊要求的是b字段(int類型),字段a相對於首地址偏移量爲0(1的倍數),直接存放,此時如果直接存放字段b,則字段b相對於結構體變量首地址的偏移量爲1(不是4的倍數),填充3字節,b由偏移地址爲4開始存放。也就是遵循了第2條與第3條規則,而對於結構體變量本身,根據規則4,對齊參數至少應該爲4。根據規則5,sizeof(MS1) = 8; 同樣MS2分析得到的結果也是如此。
例子2VC8:
typedef struct ms3 {
char a;
short b;
double c;
} MS3;
typedef struct ms4 {
char a;
MS3 b;
} MS4;
MS3中內存要求最嚴格的字段是c(8字節),MS3的對齊參數也是8字節; 那麼MS4類型數據的對齊模數就與MS3中的double一致(爲8),a字段後面應填充7個字節.sizeof(MS3) = 16; sizeof(MS4) = 24;
注意規則5中是說,結構體的總大小爲結構體最寬基本類型成員大小的整數倍。注意是基本類型,這裏的MS3不是基本類型。
對齊模數的選擇只能是根據基本數據類型,所以對於結構體中嵌套結構體,只能考慮其拆分的基本數據類型。
例子3(GCC):
struct T {
char ch;
double d ;
};
在GCC下,sizeof(T)應該等於12個字節。VC8下爲16字節。
ch爲1字節,沒有問題的,之後d的大小大於4,對於d的對齊模數只能是4,相對於結構體變量的首地址偏移量也只能是4,而不能使8的整數倍,由偏移量4開始存放,結構體共佔12字節。
這裏並沒有執行第5條規則。
位域情況:
C99規定int、unsigned int和bool可以作爲位域類型。但編譯器幾乎都對此作了擴展,允許其它類型類型的存在。
如果結構體中含有位域(bit-field),總結規則如下
1) 如果相鄰位域字段的類型相同,且其位寬之和小於類型的sizeof大小,則後面的字段將緊鄰前一個字段存儲,直到不能容納爲止;
2) 如果相鄰位域字段的類型相同,但其位寬之和大於類型的sizeof大小,則後面的字段將從新的存儲單元開始,其偏移量爲其類型大小的整數倍;
3) 如果相鄰的位域字段的類型不同,則各編譯器的具體實現有差異,VC6採取不壓縮方式(不同位域字段存放在不同的位域類型字節中),Dev-C++和GCC都採取壓縮方式;
4)如果位域字段之間穿插着非位域字段,則不進行壓縮;
5) 結構體的總大小爲結構體最寬基本類型成員大小的整數倍,且應儘量節省內存。
備註:當兩字段類型不一樣的時候,對於不壓縮方式,例如:
struct N {
char c:2;
int i:4;
};
依然要滿足不含位域結構體內存對齊準則第3條,i成員相對於結構體首地址的偏移應該是4的整數倍,所以c成員後要填充3個字節,然後再開闢4個字節的空間作爲int型,其中4位用來存放i,所以上面結構體在VC中所佔空間爲8個字節;
而對於採用壓縮方式的編譯器來說,遵循不含位域結構體內存對齊準則第3條,不同的是,如果填充的3個字節能容納後面成員的位,則壓縮到填充字節中,不能容納,則要單獨開闢空間,所以上面結構體N在GCC或者Dev- C++中所佔空間應該是4個字節。
例子4:
typedef struct {
char c:2;
double i;
int c2:4;
}N3;
按照含位域規則4,在GCC下佔據的空間爲16字節,在VC下佔據的空間是24個字節。
結論:
--------
定義結構體的時候,成員最好能從大到小來定義,那樣能相對的省空間。例如如下定義:
struct A {
double d;
int i;
char c;
};
那麼,無論是windows下的vc系列編譯器,還是linux下的gcc,都是16字節。
例子5:
typedef union student{
char name[10];
long sno;
char sex;
float score [4];
} STU;
STU aa[5];
cout<<sizeof(aa)<<endl;
union是可變的以其成員中最大的成員作爲該union的大小16*5=5=80
例子6:
typedef struct student{
char name[10];
long sno;
char sex;
float score [4];
} STU;
STU aa[5];
cout<<sizeof(aa)<<endl;
STU佔空間爲:10字節(char)+空2字節+4字節(long)+1字節(char)+空3字節+16字節(float)=36字節,36*5=180字節
例子7(VC8.0):
typedef struct bitstruct {
int b1:5;
int b2:2;
int b3:3;
}bitstruct;
int _tmain(int argc, _TCHAR* argv[]) {
bitstruct b;
memcpy(&b,"EM",sizeof(b));
cout<<sizeof(b)<<endl;
cout<<b.b1<<endl<<b.b2<<endl<<b.b3;
return 0;
}
對於bitstruct是含有位域的結構體,sizeof(int)爲4字節,按照規則1、2,首先b1佔起始的5個字節, 根據含位域規則1, b2緊跟存放,b3也是緊跟存放的。
根據規則5,得到sizeof(bitstruct) = 4。
現在主流的CPU,intel系列的是採用的little endian的格式存放數據,motorola系列的CPU採用的是big endian.
以主流的little endian分析:
在進行內存分配的時候,首先分配bitstruct的第一個成員類型int(4字節),這四個字節的存放按照低字節存儲在低地址中的原則。
int共4個字節:
第4個字節 - 第3個字節 - 第2個字節 - 第1個字節,
在內存中的存放方式如下所示。
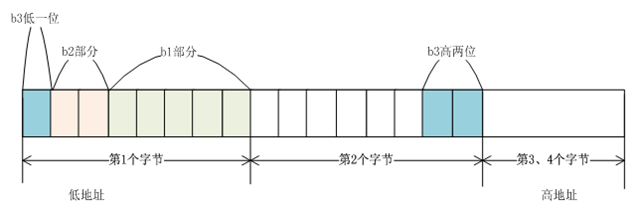
而後爲b1分配5位,這裏優先分配的應該是低5位,也就是第一個字節的低5位。
繼而分配b2的2個字節,也就是第1個字節中緊接着的2位。
最後分配b3的3位,按照規則1、2,b3還是緊接着存放的,b3的最低位是第一個字節的最高位,高兩位爲第2個字節的低兩位。
內存分配圖如下所示:
字符E二進制爲0100 0101,字符M的二進制爲0100 1101,在內存中存放如下所示:
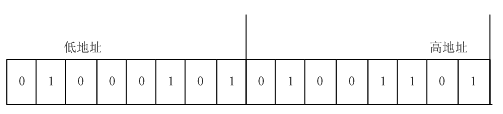
memcpy爲按位拷貝的,所以兩片內存區可以直接對應上,得到
b1的二進制形式爲:00101 ,高位爲0,正數,5
b2的二進制形式爲:10 ,高位爲1,負數,取反加1,添加符號,-2
b3的二進制形式爲:b3的最低一位是0,高位爲01,拼接後爲010,正數,2
內存分配情況感覺蠻奇怪的,按如下修改例7,b1應該爲5,b2爲-2,b3爲-6,VC8.0下驗證正確。
typedef struct bitstruct {
int b1:5;
int b2:2;
int b3:4;
}bitstruct;
int _tmain(int argc, _TCHAR* argv[]) {
bitstruct b;
memcpy(&b,"EM",sizeof(b));
cout<<sizeof(b)<<endl;
cout<<b.b1<<endl<<b.b2<<endl<<b.b3;
return 0;
}
4: 定義數組時的內存佈局及內存字節對齊
int b=10;
int a[3]={1,2,3};
int c=11;
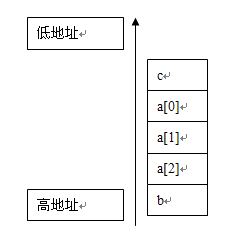
int b=0x01020304;
char ch='a';
對於一個數0x01020304; 對於一個數0x1122
使用Little Endian方式時,低地址存放低字節,由低地址向高地址存放爲:4->3->2->1
而使用Big Endian方式時, 低地址存放高字節,由低地址向高地址存放爲:1->2->3->4
而在Little Endian模式中,b的地址所指的就是 : 低地址(存放的是最低的字節)
1: void __cdecl func_cdcel(int i, char *szTest) {
2: cout << "szTest在棧中的地址:" << &szTest << endl;
3: cout << "szTest本身的值(指向的地址):" << (void*)szTest << endl<<endl;
4:
5: cout << "i在堆棧中地址:" << &i << endl;
6: cout << "i的地址:" << &i << endl;
7:
8: int k,k2;
9: cout << "局部變量k的地址:" << &k << endl;
10: cout << "局部變量k2的地址:" << &k2 << endl;
11: cout << "-------------------------------------------------------" << endl;
12: }
13:
14: void __stdcall func_stdcall(int i, char *szTest){
15: cout << "szTest在棧中的地址:" << &szTest << endl;
16: cout << "szTest本身的值(指向的地址):" << (void*)szTest << endl<<endl;
17:
18: cout << "i在堆棧中地址:" << &i << endl;
19: cout << "i的地址:" << &i << endl;
20:
21: int k,k2;
22: cout << "局部變量k的地址:" << &k << endl;
23: cout << "局部變量k2的地址:" << &k2 << endl;
24: cout << "-------------------------------------------------------" << endl;
25: }
26:
27: int main(){
28: int a[4];
29: cout <<"a[0]地址:"<< &a[0] << endl;
30: cout <<"a[1]地址:"<< &a[1] << endl;
31: cout <<"a[2]地址:"<< &a[2] << endl;
32: cout <<"a[3]地址:"<< &a[3] << endl;
33:
34: int i = 0x22;
35: int j = 8;
36: char szTest[4] = {'a','b', 'c', 'd'};
37: cout <<"i的地址:"<<&i << endl;
38: cout <<"szTest的地址:"<<(void*)szTest << endl;
39: func_cdcel(i, szTest);
40: func_stdcall(i, szTest);
41: }
輸出爲:
a[0]地址:0012FF54
a[1]地址:0012FF58
a[2]地址:0012FF5C
a[3]地址:0012FF60 <— 可見存儲方式如上圖所示,a[3]在高地址,先入棧,而數組地址a爲a[0]的地址(低地址)
i的地址:0012FF48 <— 這裏進行了內存對齊,i的起始地址必定是i所佔內存大小的倍數
szTest的地址:0012FF30
szTest在棧中的地址:0012FE5C
szTest本身的值(指向的地址):0012FF30
i在堆棧中地址:0012FE58 <— i在堆棧中的地址低於szTest,也就是說szTest是先入棧的
i的地址:0012FE58
局部變量k的地址:0012FE48
局部變量k2的地址:0012FE3C
-------------------------------------------------------
szTest在棧中的地址:0012FE5C
szTest本身的值(指向的地址):0012FF30
i在堆棧中地址:0012FE58
i的地址:0012FE58
局部變量k的地址:0012FE48
局部變量k2的地址:0012FE3C
-------------------------------------------------------