




from--http://www.cnblogs.com/yueyebigdata/p/5893454.html
基於大數據的銀行反欺詐的分析報告
(備註,本人主要是整理,學習他人的博客。由於大量的資料,所以,無法一一附上參考鏈接,所以,各位看我博客的同學們就不要外傳了。)
0,大數據知識背景。
在我第一次接觸大數據的時候,那個故事便是“啤酒和尿布”。
那麼,銀行的反欺詐也是一個預測行爲。現在利用大數據來做欺詐的預測也是一個很好地思路。當然,據我的調查數據,目前不少公司都已經開始了這樣的業務。
1,銀行反欺詐的機器學習方面知識整理。
無監督算法主要是針對交易模式進行的離羣點挖掘,各種技術都有,基於距離、基於密度、基於深度、基於概率、……,但萬變不離其宗,都需要通過距離計算來確定點與點之間的相似性,以此判斷哪些點屬於相對孤立的點。離羣點挖掘優點是對任何異常模式都較爲靈敏,缺點是噪聲大,誤判率高,無法確定是何種欺詐類型。
目前國內支付寶的風險策略引擎做得不錯,前段時間他們還發過一篇吹噓他們所謂“6維度綜合智能判斷”風險策略引擎的文章,居然在微信朋友圈裏也傳的很火,足見其影響力。國際上較爲領先的是paypal,據說已經初步具備人工智能判斷了,風險判斷策略開發得較爲完備。
所有算法從開發主體看都可分爲工程師算法和科學家算法,對於工程師而言,算法都有現成的,關鍵在於如何與公司業務流程緊密結合,結合得越好,即便最簡單的聚類算法也能產生巨大威力,結合不好,光是深入鑽研算法裏邊的奇技淫巧其實是徒勞無功的;對於科學家而言,需要充分藉助數學不斷拓展算法效率的可能性邊界,講求特定算法普適意義上的性能提升,對於特定公司的具體情況一般不予考慮,這類典型例子是hinton,他幾乎是重新發明了ann。
我們大多數人都只能做到工程師算法設計,比如特徵調參、已有算法並行與串行組合、數據預處理、…等,少數天賦較高、科研條件優裕且耐得住寂寞的高手,可以從事科學家算法研發,不過這是一條極爲枯燥且充滿風險的道路。
最後但並非不重要的是,對於工程師而言:反欺詐算法要真正發揮作用,你的業務直覺至關重要,只有具備良好的業務洞察力——僅基於對數據簡單的描述統計就能粗略預估出合適的檢測流程與步驟——你才能在各類複雜模型中準確選擇最合適的模型。沒有良好的業務洞察力與直覺,沒有對數據形狀天然的敏感,你對算法的選擇很可能要麼只停留在很粗糙的層面(既做不好特徵調參,也做不好算法組合),要麼迷失在汗牛充棟長篇累牘的算法文獻中無所適從。總之,業務洞察力與數據敏感性是數據科學家最重要的品質,需要經過一萬小時不懈的刻意練習才能修煉成。
交易欺詐:Falcon、PRM等系統,規則通常是短時間頻繁交易,大額交易,補卡盜刷等。
從前些年爆炒大數據,到目前提到大數據許多業內的朋友都會報以不屑的表情,這源於數據,特別是原來的數理統計被過分的渲染,金融行業的發展,本質也是信息技術的發展,我始終相信科技進步的力量,也相信科技是可以不斷改進金融的
目前比較火的互金領域,簡單的說,我認爲互聯網金融的本質在於金融,特別是P2P網站的資產端,究其實質仍然是小額信貸,傳統的信貸風險管理一定程度上是適用於互金的。最近幾十年隨着計算機技術的發展,也隨着數據挖掘和機器學習的不斷的發展,新的反欺詐和信用評分技術一直在不斷進步,本文我會簡單介紹一下目前投入生產環境的技術和手段,也算是對近期的工作學習做一個簡單的總結。
事實上小額信貸風險管理,本質上是事前對風險的主動把控,儘可能預測和防範可能出現的風險。爲了滿足業務的需求,我們會使用大量數據,建立相應模型,衡量風險並儘可能避免逾期,一般通過對授信人個人狀況、收入能力、負債情況進行數據挖掘,進行模型化綜合度量,進而確定授信對象的額度,並確定一個合理的風險定價,使風險和盈利達到一個平衡的狀態。
很明顯,一般互金公司做的信貸業務(一般p2p公司都無法獲得類似銀行的優質債權)隨着信貸業務不斷髮展,高端客戶無法獲取,必然面臨授信羣體向着普通人羣甚至是高風險人羣的滲透,必然導致客戶質量的參差不齊。信用風險、欺詐風險等都隨之迅速上升
如果依託傳統的信貸技術,事實上只能對存量市場做精耕,但是如果能結合一些新的數據源(特別是一個人的網上記錄包括社交、交易行爲、消費習慣等),一來可以有效的降低風險,其次對新客的拓客有着意想不到的效果(啤酒和尿布)。所以數據挖掘在當前數據大爆炸的時代就具有舉足輕重的作用,也成了業內競爭的強力武器,降低壞賬逾期的重要手段。
說起來很簡單,但任何的技術進步,無一不是通過一次次的試錯完成的。一般而言,不管是任何一種欺詐,歸根到底,都是通過欺詐性地申請實現的。反欺詐策略實質就是探討挖掘和模型技術來預測欺詐的概率。爲企業發現和拒絕欺詐性交易提供科學依據
一個優秀的評分模型一定是基於統計分析技術的,可以準確和實時的進行風險評估,通過內部的模型更新增強對新的詐模式的適應能力,並通過分析各類人羣的行爲特徵模式,利用先進的數理統計技術,進行深度的數據挖掘,不斷修正風險決策模型,對審批、還款管理、催款等各個流程進行科學有效的管理,將風險控制在合理範圍內。
據我所知,目前銀行業對於信貸風險的常見評級方法之一是通過打分法來進行的。即基於業內長期經驗,從衆多風險的指標中選擇若干指標,並對各個指標給予適當的權重水平,設定各個指標具體數值。進而將授信對象的具體數據代入評級體系中,分析各個指標的打分情況。
事實上,指標體系的設計本身是一個十分複雜的系統。在打分時,對於設定各指標權重大小以及每一項指標的分數並沒有十分標準的依據,依靠經驗確定指標的權重,參雜人爲的經驗,主觀因素較突出,這種主觀意見確定權重形成的評級辦法在科學性與客觀性方面都存在問題,影響了評級結果的準確性,在主觀因素的引導下,加重了風險,也會造成不必要的損失
這裏有要介紹另一種基於機器學習和算法的反欺詐評分模型,既神經網絡模型。基於神經網絡的評分模型在當前的數據挖掘過程中具有特殊的地位,它能夠使模型在不斷的學習中逐步成長。本文會大致介紹將神經網絡的數據挖掘方法應用於小額信貸數據的過程,探索適用於互金的信用風險評判的模型。
神經網絡是一種通過模仿人腦信息,類似於大腦神經突觸聯接的結構加工過程的智能化信息處理技術及進行信息處理的數學模型,與博弈論中的動態博弈很相似,具有自適應性、自組織性以及較強勁的穩健性,在應用過程中具有很強的魯棒性和容錯性,能夠並行處理方法,具有自學習性。擁有自組織、自適應性和很強的信息綜合能力等良好性能,能同時處理定量和定性的信息,能很好的協調多種輸入信息關係,適用於處理複雜非線性和不確定對象,能成功的應用於多種不同的信息處理。
這裏引用一張信用評分模型中的圖說明。

一個神經元可以有任意n個輸入
我們將輸入參數記作:x1, x2, x3, x4, x5, ..., xn
同樣n個權重可表達爲:w1, w2, w3, w4, w5 ..., wn
簡單的說,激勵值就是所有輸入與它們對應權重的之乘積之總和
因此,現在就可以寫爲: y = w1x1 + w2x2 + w3x3 + w4x4 + w5x5 +...+ wnxn
神經網絡經過一系列的輸入及加權計算,得到輸出數據,即欺詐風險評分。
網絡可以在真實的數據集環境中學習,通過不斷地學習過程提高效率,交互式的調整其連接權重,每增加一次學習過程,網絡對真實數據集的環境就更加了解一些,學習是一個過程,在此過程中,神經網絡的參數會隨着所處環境的變化自動進行調整
當所有用於估計模型的訓練集樣本誤差達到最小時,模型就建立了,即擬合成了神經網絡模型,隱含的神經網絡模型決定屬性的分類規則。根據需求把新的屬性轉換爲相應的數據代入模型,便可以得到所屬的分類以及相應的概率
最初神經網絡具有結構較複雜、訓練時間長、可解釋性比較差等缺陷,所以在數據挖掘的分類技術應用中不是很被看好,但神經網絡技術具有低錯誤率,能夠承受噪聲數據的能力,以及經過不斷優化神經網絡訓練算法,尤其是不斷完善很多網絡剪枝算法和規則提取算法,使得神經網絡算法在數據挖掘分類技術中的應用越來越被接受及認可。
當然,神經網絡的信用評級模型是對現存的評級方法的一種改良,而非現存評級方法的完全替代,一個完備的評級體系既要避免主觀的陷阱,也要避免統計的陷阱,因而神經網絡模型本身是希望通過定量分析,爲認爲審覈判斷提供一定依據,而不僅僅依靠個人經驗
事實上我認爲,由於神經網絡的黑盒性質,從一定程度上犧牲了模型的可解釋性,比之邏輯迴歸、決策樹,解釋性顯得並不是特別的強等一些缺陷。
4,先進的銀行反欺詐的設計。
最近發生很多起網絡資金賬戶被盜事件,絕大多數集中在互聯網金融公司,我在某爺理財APP上的四萬多理財資金也全部被盜,痛心棘手(當事人無參與),並明顯感覺到了互聯網金融產品的安全性缺失,大衆也紛紛要求提現,導致多家互聯網金融公司被擠兌處在死亡邊緣。
但是反觀銀行業,如果自己不參與(不簽字、不泄漏密碼、不同意複製手機卡),沒有人的銀行賬戶能被盜,即使銀行內部員工內外勾結也不能動客戶一分錢,就像最近發生的40億同業欺詐案,內外行家小心配合也依然無法通過銀行的反欺詐攔截。爲了你的錢和我的錢,爲了讓那些優秀的互聯網金融公司活下去,我們今天就來探討一下銀行的反欺詐是如何設計的。
十年前我在黑客防線和黑客X檔案陸續發表《徒手搞定整個機房》、《徒手對抗驅動級病毒》等安全類文章的那段時間,是國內個人電腦安全最動盪的日子,隨便一個會點鼠標的網民隨便下載幾個工具就可以號稱黑客乾點惡作劇,後來殺出個周鴻禕採用流氓衛士輔以收編各路紅黑高手的手段,才讓網絡安全的話題逐漸的迴歸了平淡。
隨後幾年,平靜的網絡環境給了人們足夠的安全感,接着網絡實行實名制,各大網站紛紛實名社交,之前遊離在編制外的各路黑神逐漸將注意力轉移到各大網站,並將脫褲(下載用戶數據庫)獲得的用戶數據轉爲經濟利益,由於這些數據包含大量真實個人信息,它可以作爲社工猜解的輸入條件對用戶其它信息一一破解,對於不能直接轉爲經濟效益的用戶信息便通過黑市直接轉手賣給各路電信詐騙分子,詐騙分子通過逐一分析用戶信息有針對性的制定詐騙方案,並輔以完整配套設施“官方網站”、“官方400電話”等,略施小計如“您兒子出車禍了”、“恭喜您中獎了”、“到我辦公室來一趟”等即可拿下很多人,因爲對方知道你所有的信息,包括姓名、住址、身份證號碼、在哪裏讀過書、在哪裏工作、領導是誰、買過什麼東西、去過那裏、和誰開過房、甚至包括你家人和朋友的這些信息,當你去網絡求證對方是不是在詐騙時,百度會告訴你對方說的是真的(騙子預先在百度付費推廣詐騙信息,比如公司的電話等)。
詐騙分子實施這一系列的動作有兩個目的,一是直接拿到你的錢,二是退而求其次拿到存錢的賬戶,實現的手段有四類:要求轉賬、櫃檯簽字、獲取密碼、手機號複製。詐騙分子使用以上手段達到這兩個目的過程稱爲社會工程學詐騙,這種詐騙的存在是互聯網金融安全薄弱的根本原因,各大銀行在過去許多年與騙子的較量中已經總結出了一套識別真正用戶以及真實交易的一整套方案,這是現在各大互聯網公司最缺少的,尤其是互聯網金融公司,因爲很多互聯網金融公司還停留在使用用戶外在信息識別用戶身份的低級方案,甚至對交易真實性根本沒有做任何檢查,詐騙分子閉着眼睛隨便捏一個公司出來也能獲得豐厚的回報,這也導致現在詐騙分子非常氾濫還活的十分滋潤的一個原因。而這一切,不是用戶的智商讓我們措手不及,是我們系統設計的讓用戶措手不及。
先舉兩個真實案例,第一個就是發生在我身上的,我存在某互聯網金融公司某爺的四萬多理財資金在一個週五晚上十點的一個小時內全部被盜,我的賬戶被別人在異地使用新手機登錄並修改了登錄密碼、支付密碼、更換了我綁定的銀行卡、並額外綁定了三張別人的銀行卡,這期間我無法重置支付密碼、無法解綁銀行卡、無法凍結賬戶、打客服提示已下班,束手無策,只有絕望。這個過程中發生了多少敏感操作,而我的手機沒有收到一條變更確認的短信和變更成功後的通知,只有最後收到一條我的賬戶被提現到某某卡的通知(完整的詳細過程可以翻看我公衆號裏的那篇《財神爺爺資金被盜是內鬼還是外患》),從這個過程就可以看出這家公司居然沒有用戶身份真僞識別的機制,更別說交易真實性識別了,完全就是拿着用戶的錢在網上裸奔,誰能在旁邊說出錢是誰的錢就給誰,作爲一家金融公司這樣實在是讓人震驚。
第二個案例是發生在銀行間市場,有個人通過向A銀行購買十萬理財產品的方式獲取了A銀行的理財產品說明書、協議書、稅務登記證、營業執照、組織機構代碼證、客戶權益須知等文件,並以個人名義存入2000萬以取得A銀行貴賓室的使用權,然後冒充A銀行工作人員利用A銀行的貴賓室,向B銀行高息兜售該理財產品,連續多天在A銀行的表演和略施小計騙過了B銀行的審覈人員,從而賣出了一份40億的理財資金,但是這筆交易被B銀行的反欺詐偵測列入了風險監控列表,經過人工審覈確認後堵截了這起詐騙事件(詳細過程可查看銀監會安徽監管局發的2016第55號文件)。對比B銀行該案例中表現出來的反欺詐偵測能力,某互聯網金融公司的做法就是在作死,互聯網金融公司安全能力的提升迫在眉睫也任重道遠。
互聯網金融公司想要提升自己的安全能力,最好的學習榜樣就是銀行,而全球範圍內率先實現企業級反欺詐管控體系的是美國銀行和富國銀行,他們在這方面有些非常優秀的設計經驗值得學習,現在我們就開始探討他們在企業級架構下的反欺詐是如何設計的。一般概念下的欺詐分內部欺詐和外部欺詐,它屬於風險管控中操作風險管理的一部分。在操作風險管理中除了欺詐外還管理就業制度和工作場所安全事件、客戶/產品和業務活動事件、實物資產損壞事件、信息科技系統事件、執行/交割和流程管理事件,今天我們主要探討欺詐這部分。在外部欺詐中主要有三類欺詐:當事人欺詐、第三方欺詐以及人行要求檢查的洗錢欺詐,內部欺詐主要有未經授權的行爲與盜竊。對於欺詐的防控分事前防控、事中防控與事後防控,並在以下層面進行防控:
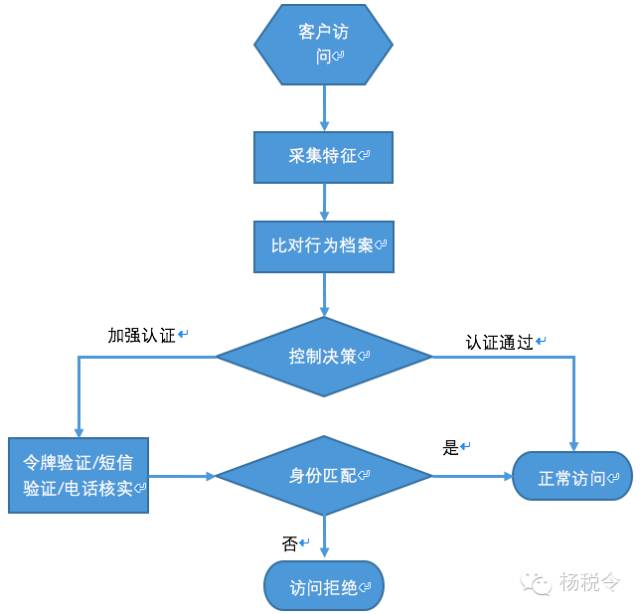
外部渠道層:重點偵測交易發生前的客戶接入、會話可疑行爲;交易發生中的交易對手是否在可疑欺詐名單。
內部渠道層:重點偵測業務違規與可疑操作。
產品服務層:重點偵測產品服務內的欺詐交易,跨產品的欺詐交易。
數據集成層:重點偵測跨產品、渠道的組合/複雜欺詐交易。
這些不同的層側重防控的欺詐行爲不一樣,其偵測邏輯也不一樣,渠道層可能偵測以下行爲:
異地更換網銀盾後首次進行大額轉賬,這可能是客戶的信息已泄露,這種交易需要掛起,並需要打電話給客戶進行覈實。
客戶通過手機或網銀渠道向黑名單收款賬戶轉賬,被阻斷交易後,當天該賬戶又向其它賬戶進行大額轉賬,這可能是客戶賬戶被盜或被電信詐騙分子利用社會工程學的手段實施了詐騙,這種交易需要掛起,並需要打電話給客戶進行覈實。
異地升級網銀盾後首次進行大額轉賬,這可能是客戶身份被盜用,身份證、登錄密碼等已泄露,這種交易需要掛起,並需要打電話給客戶進行覈實。
新開通的網銀客戶進行大額轉賬,這可能是客戶被電信詐騙分子利用社會工程學的手段實施了詐騙,這種交易需要掛起,並需要打電話給客戶進行覈實。
用戶登錄所使用的設備指紋(MAC地址、IP、主板序列號、硬盤序列號)、登錄時間、設備所在地,與其常用的對應信息不一致,這可能是客戶賬戶已被盜用,這種情況需要進行人工覈實。
產品層可能偵測以下行爲:
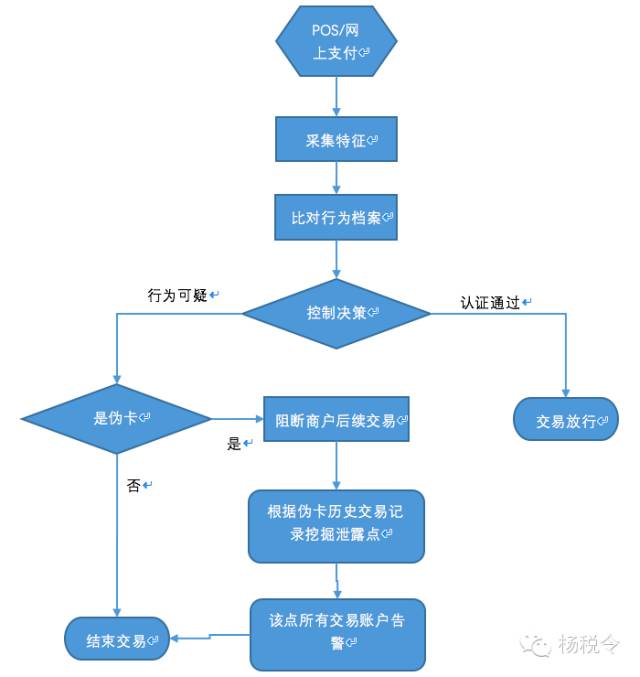
1、 進入黑名單商戶的交易,對於已支付未確認付款的交易需要實施凍結,防止資金流入該商戶。
2、 根據客戶的投訴確認商戶是否存在虛假交易,如果是也需要實施凍結。
3、 如果同卡同天當筆交易爲上一筆的倍數,這可能是客戶賬戶被盜用,這種交易需要掛起,並人工進行覈實。
4、 如果同卡同商戶同金額,這可能是商戶正在配合客戶套現,這種交易需要人工覈實。
5、 如果同卡同商戶五分鐘內交易超限,這可能是在進行虛假交易,這種交易需要人工覈實。
6、 如果對公客戶的交易額不在其合理的範圍內(通過其註冊資本、代發代付的累計額等評估的範圍),這種交易可能需要拒絕並人工進行調查。
7、 如果使用僞卡進行交易,此後該商戶發生的交易可能都需要阻斷或告警。
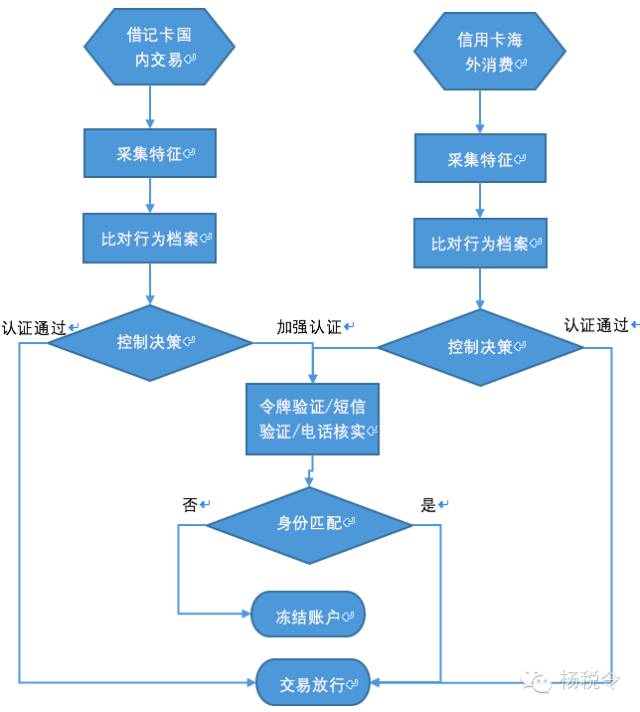
客戶層可能偵測以下行爲:
1、 特定年齡段客戶以往習慣在非櫃面進行小額交易,突然第一筆發生大額轉賬,這可能是賬戶被盜,需要進行人工調查。
2、 客戶賬戶多日連續多筆密碼驗證錯誤,嘗試成功後就進行轉賬操作,這可能是賬戶被盜,其發起的交易可能需要被阻斷,該客戶使用的其他產品可能均需要掛起,並進行人工覈實處理。
3、 同一個客戶的一個或多個產品短時間內在不同地區/國家使用,這可能是客戶的卡被複制存在僞卡,這種交易需要人工覈實處理。
4、 在一定時間內,同一個客戶在特定高風險國家發生多筆或進行大額交易,這可能是僞卡,這種交易需要人工覈實處理。
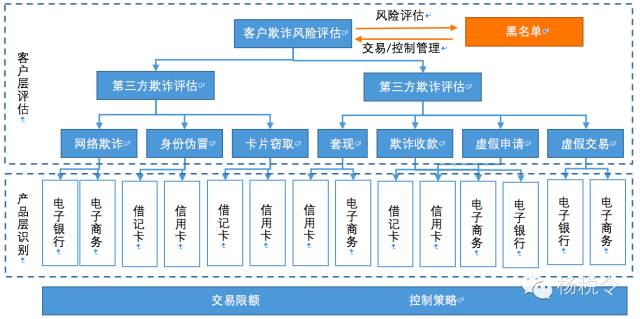
可能需要通過對客戶和員工的不同緯度外部欺詐、內部欺詐風險及黑名單信息的分類評估,實現對客戶欺詐風險的聯合防控,它們之間的風險關係梳理如下:

如果我們要在防控的前、中、後三個階段都要對各個產品的多個緯度進行統一欺詐防控與處理,那麼我們需要基於他們整體建立一套防控體系,通過整理並抽象總結前面提出的偵測行爲,我們將它需要實現的目標梳理如下:
1、 應該具有統一的數據集市。
2、 應該具有統一的數據採集、加工過程。
3、 應該具有統一的偵測策略定義過程。
4、 應該具有統一的基於流程引擎的偵測問題流轉管理。
5、 應該具有統一的基於流程引擎的案件管理,記錄、跟蹤、評估、回顧相關的處理過程。
6、 應該具有統一的基於規則引擎的實時、準實時、批量風險偵測。
7、 應該具有統一的信息外送處理。
通過這些目標,我們將它需要具備的功能梳理如下:
1、 反欺詐業務處理:告警管理、案件調查、交易控制、偵測處理。
2、 反欺詐運營管理:運營管控、流程管理、策略管理。
3、 反欺詐數據報表:數據整合、數據報告。
4、 反欺詐模型研究:規劃研究、變量加工、貼源數據。
5、 反欺詐行爲分析:行爲分析、關聯分析、評級計算、批量處理。
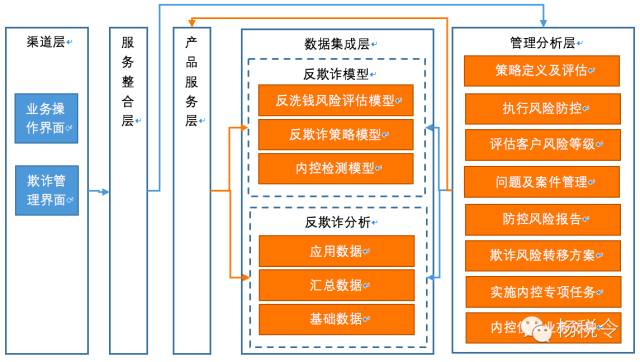
基於前面的要求,我們來梳理一下與反欺詐有關的上下文關係,如下圖:

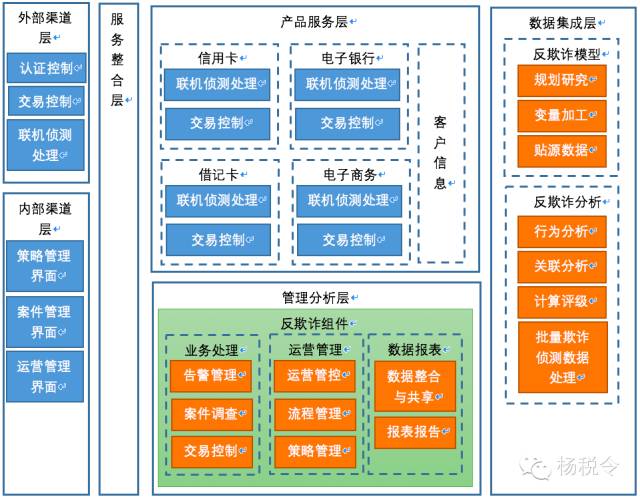
圖中藍色線是交易訪問關係,橙色線是批量數據訪問關係,通過這些關係,我們再來細化梳理一下它們在應用架構中的位置:

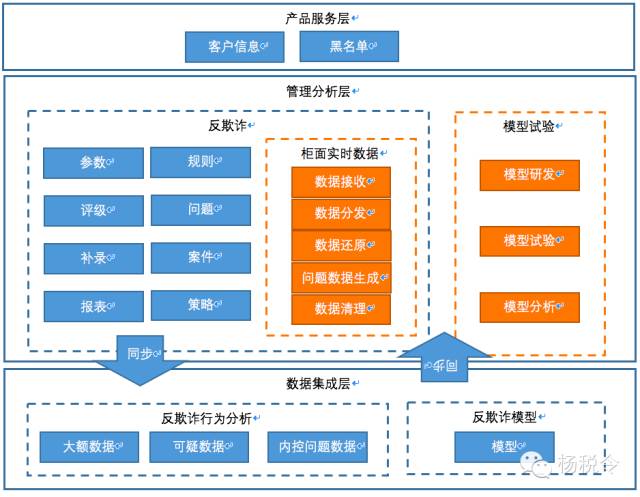
再把它們在數據架構中的位置也梳理出來:

現在,我們可以梳理一下反欺詐的具體處理流程了。渠道層的處理流程梳理如下:

產品層的處理流程梳理如下:

客戶層的處理流程梳理如下:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
在這些處理流程中,對於需要加強認證的行爲,需要將該次交易列入風險監控列表中,經事後人工確認確實存在欺詐行爲的,將此類行爲列入風險行爲模型中,完成欺詐偵測隨着欺詐行爲的變異而不斷進化。
好了,到這裏我們反欺詐設計的主體部分就算設計完成了,這是在企業級架構中邏輯各層已解耦的前提下進行的設計,分階段分層各司其職分而治之,通過建立行爲模型靈活應對用戶的各種行爲,適應現在與未來,對於那些新出現的欺詐手段,主動學習並生成欺詐行爲模型,將可有效杜絕現在與未來可能發生的欺詐。
通過反欺詐設計的這個過程,我們可以總結幾招識別一家互聯網金融公司是否具備反欺詐能力的小技巧:
1、 將您的帳戶在其它手機上登陸,測試渠道層反欺詐能力;
2、 將您的帳戶在異地登陸,測試渠道層反欺詐能力;
3、 修改您的登陸密碼,測試產品層反欺詐能力;
4、 修改您的支付密碼,測試產品層反欺詐能力:
5、 修改身份信息,測試客戶層反欺詐能力;
6、 綁定新的銀行卡,測試產品層反欺詐能力;
7、 用新卡提現,測試交易反欺詐能力;
8、 用他人手機提現,測試交易反欺詐能力;
9、 異地全額提現,測試交易反欺詐能力;
進行以上任意一步操作,如果有收到短信提醒,說明有帳戶異常行爲識別機制;如果有收到短信驗證碼,說明有帳戶行爲控制機制;如果收到電話確認,說明有用戶身份真僞識別。如果只有短信提醒,請謹慎使用,如果都沒有,立刻馬上提現並卸載。