




本文選擇了4個light weight CNN模型,並對它們的設計思路和性能進行了分析與總結,目的在於爲在完成圖像識別任務時模型的選擇與設計方面提供相關的參考資料。
1 簡介
自AlexNet[1]在LSVRC-2010 ImageNet[22]圖像分類任務上取得突破性進展之後,構建更深更大的convolutional neural networks(CNN)幾乎成了一種主要的趨勢[2-9]。通常,獲得state-of-the-art準確率的模型都有成百上千的網路層以及成千上萬的中間特徵通道,這便導致了一些complex CNN模型[7-9]需要上十億的FLOPs(每秒浮點計算次數),也就限制了他們在移動手機平臺或移動機器人平臺的應用。爲了解決這一問題,構建light weight CNN模型[10-19]成爲了一個非常活躍的研究方向。近年來在light weight CNN模型構建方面的一些成果已經表明,一些經過精心設計的小模型,也能夠在圖像分類問題如ImageNet上取得state-of-the-art的性能,而在模型參數以及計算效率方面都有大幅度的減少與提高。爲了能夠在完成圖像識別任務(如菜品識別等)時模型的選擇與設計方面提供相關的參考資料,本文首先簡單的對構建light weight CNN模型的方法進行了介紹,繼而選擇了4個模型並對它們的設計思路和性能進行了分析與總結。
2 Light Weight CNN模型
在構建light weight CNN模型方面主要有兩個大的方向:
(1) 基於不同的卷積計算方式構造新的網絡結構
如All Convolution Net[10],SqueezeNet[11],MobileNet[12]以及ShuffleNet[13]等。
(2)在已訓練好的模型上做裁剪[14-19]
Pruning:從權重(weight)層面或從(kernel & channel)層面對模型進行修剪;Compressing:如權重共享(clustering based weight sharing)或對權重採用Huffman編碼等;Low-bit representing :如權重量化(quantization)將浮點型轉換到[0~255],或者將網絡二值(binary)化等。
我們這裏選擇,從基於不同的卷積計算方式構造新的網絡結構這個方向下,挑選一些就近的成果來進行分析與總結。這樣選擇的理由是因爲,上述1這個方向是解決問題的一種更爲本真的方式。它是一種更爲靠近底層的解決問題的思路,而上述2這種方式是可以被認爲是以1爲基礎而進行的相關拓展。
3 基於不同的卷積計算方式構造的Light Weight CNN模型
對於Light Weight CNN模型的評估除準確率之外,我們還比較關注模型參數壓縮的比率以及模型的計算效率。因此,在選擇模型時需要注意一下,一些方法在模型參數壓縮方面的比率和模型計算方面的效率之間的權衡。
(1) All Convolution Net [10]
大量的卷積神經網絡均採用了相似的設計方式,即使用可變的卷積層、池化層、再加一些小數量的全連接層。在如何增強這種設計方式下的網絡模型的性能上,很多人進行了不同的探索:1)使用更復雜的激活函數,使用改善的正則化(regularization),以及利用標籤信息進行layer-wise的預訓練 ;2)使用不同的CNN架構 。All Convolution Net的作者通過在不同的數據集上進行實驗後,發現僅僅使用卷積層的網絡結構並不會對物體檢測的性能產生影響,池化層的存在並非必要,可以使用步長較大的卷積層進行替代。因此,All Convolution Net拋棄了以往CNN網絡中的池化層和全連接層,通過使用步長更大的卷積層來代替池化以及使用卷積核爲1的卷積層來代替全連接層。
對於池化層的作用現在還很難給出比較完整的解釋,一般假定池化層可以通過如下三個方面來對CNN的性能產生幫助:1)p-norm(p範數)使CNN的表示更具不變性(invariance);2)降維使高層能夠覆蓋輸入層的更多部分(receptive field);3)池化的feature-wise特性能夠使得優化更爲容易。假設第2)點,即降維對與CNN的性能提升至關重要,那麼我們可以通過使用如下兩種方法,來代替池化層取得相似的降維效果:1)直接移除池化層並增大卷積層的步長;2)使用步長大於1的卷積層來代替池化層。第1)種方法等價於池化操作但僅考慮了頂部左側的特徵響應,因而可能會降低檢測的準確率。第二種則沒有這種缺陷。
最終All Convolution Net模型相較於以往CNN模型的不同之處有:1)使用stride大於1的卷積層代替以往CNN中的池化層(下采樣層);2)使用filter大小爲1*1的卷積層代替全連接層(減少參數和計算量)。其在cifar-10和cifar-100上取得了很好的效果,見下圖。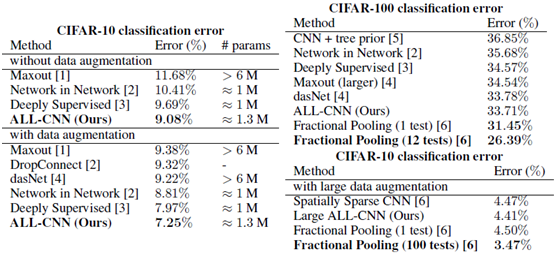
這裏有一個值得注意的地方是,All Convolution Net和 Fully Convolution Net [20]它們的中文翻譯都叫做“全卷積網絡”,但是他們是有區別的,區別在於前者拋棄了池化層和全連接層,而後者保留了池化層而丟棄了全連接層。
(2) SqueezeNet[11]
SqueezeNet遵循了三個設計原則:1)使用更小的11的卷積核來代替33的卷積核。類似於GoogleNet[5]以及ResNet[6]設計中的33卷積來代替AlexNet中的77卷積的思路,SqueezeNet進一步用11卷積代替了33卷積。爲了保證不影響識別的精度,因此在SqueezeNet中並不是完全的代替,而是進行了部分的替換。2)減少輸入33卷積的特徵圖數量。如果是conv1到conv2這樣的直接連接,實際上是不太好減少輸入到conv2的特徵圖的數量的,在SqueezeNet中通過利用11卷積的升維或降維的作用,採用11卷積生成新的數量的特徵圖,然後將他們接入到33的卷積,進而達到目標。在SqueezeNet中將這種思路封裝成了一個Fire Modeule, 見下圖。3)減少pooling。在(1)中的All Convolution Net,GoogleNet以及ResNet中都發現,適當的減少pooling操作能夠得到比較好的效果,因此在SqueezeNet中只是進行了3次max pooling和1次global pooling。
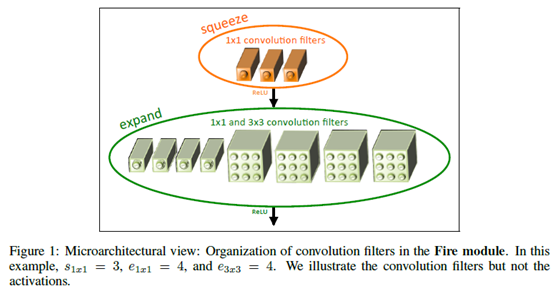
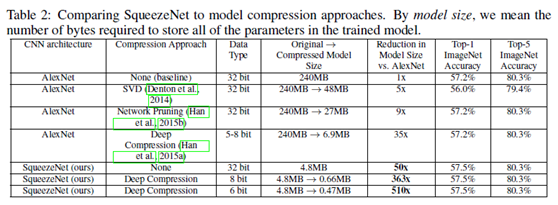
基於上述的三個設計原則,SqueezeNet在ImageNet上與AlexNet以及其他的一些模型壓縮方法進行了對比,在準確率差不多的情況下,SqueezeNet模型參數數量顯著降低了,如下圖所示。
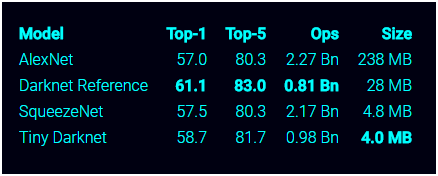
但是,Squeeze Net並沒有在模型參數數量與模型計算效率之間做很好的trade-off,見下圖,瞭解更多可訪問https://pjreddie.com/darknet/tiny-darknet/ 。接下來,我們將分析兩個在參數數量與計算效率間有比較好的trade-off的模型MobileNet[12]和ShuffleNet[13]。
(3) MobileNet[12]
MobileNet提出了一種depth-wise separable convolution卷積的方式來代替傳統卷積的方式, depth-wise separable convolution包含兩種操作:1)depth-wise convolution;2)point-wise convolution。首先提出depth-wise convolution這種卷積方式的是論文[21],這種卷積方式的好處是減少參數數量的同時也提升了計算效率。不同於傳統的卷積計算,將一個卷積核在所有的輸入通道上做卷積操作,在depth-wise convolution中一個卷積核只在一個輸入通道上進行卷積。但是depth-wise convolution只是對輸入通道進行單獨的特徵計算,並沒有將他們結合起來計算特徵。因此,爲了產生一些聯合特徵,增加了一層網絡採用1*1卷積來對depth-wise convolution生成的特徵之間進行一個線性組合,這就是poit-wise convolution。
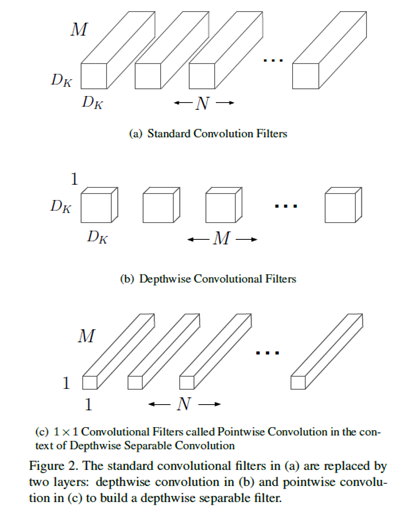

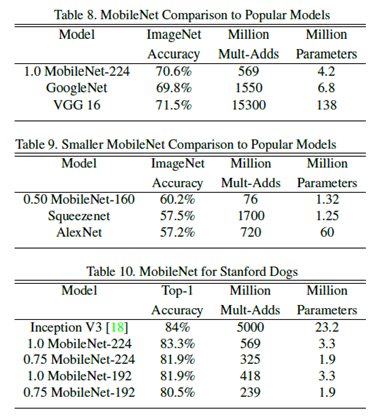
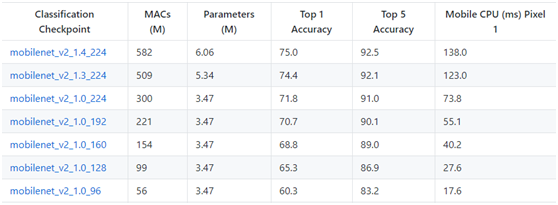
MobileNet 的網絡結構共 28 層,沒有采用池化的方式進行下采樣,而是利用 depth-wise convolution 的時候將步長設置爲 2,達到下采樣的目的。相較於 GoogLeNet,在同一個量級的參數情況下,但是在運算量上卻小於 GoogLeNet 一個量級,同時也保證了較高的準確率,見下圖。這些都是得益於包含depth-wise convolution以及point-wise convolution的depth-wise separable convolution。
(4) ShuffleNet[13]
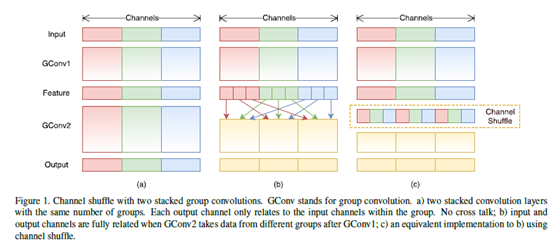
ShuffleNet可以被看作是從MobileNet發展而來的。首先,ShuffleNet的作者發現point-wise convolution這種操作實際上是非常耗時的,爲了能夠高效的在輸入特徵圖間建立信息流通,他們基於group convolution 提出了一種channel shuffle的操作。通過利用group convolution和channel shuffle這兩個操作來設計卷積神經網絡模型,在減少了參數的同時也能夠有效提高計算效率。
Group convolution 是一組卷積核負責一組輸入通道,也就是每組通道只被一組卷積核卷積。那depth-wise convolution 其實是可以看成是一個特殊的 group convolution,即每一個通道是一組。Group convolution早在AlexNet中就已經出現了,當時是因爲硬件限制而採用分組卷積的。之後在 2016 年的 ResNeXt [9] 中,也表明採用 group convolution 可以獲得高效的網絡。由於基於不同組計算出來的特徵圖之間是沒有信息流通的,這會影響網絡的表達,爲了建立組間的信息流通,channel shuffle操作就被引入進來。Channel shuffle操作實際上是對group convolution操作計算出來的特徵圖組進行一個重組,也就是從各個特徵圖組中隨機的選擇一個特徵圖,進而構成新的特徵圖組。每一組這種新的特徵圖組中都包含了舊的特徵圖組中的信息的,也就是在舊的特徵圖組間建立了信息流通。同時,channel shuffle操作也避免了MobileNet中的point-wise convolution的計算量。Channel shuffle操作的略縮圖如下所示。
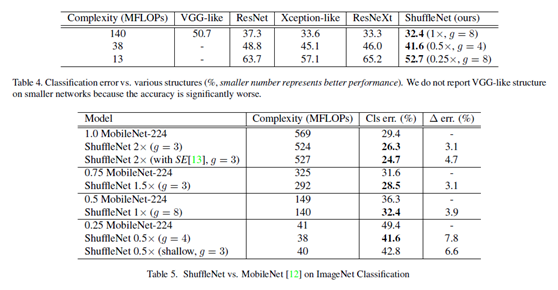
ShuffleNet論文中採用了 Complexity (MFLOPs) 指標,在相同的 Complexity (MFLOPs) 下,對ShuffleNet 和各個網絡以及特別的與 MobileNet 進行了對比,由於 ShuffleNet 相較於 MobileNet 少了point-wise convolution,所以效率大大的提高了,同時也取得state-of-the-art的準確率,見下圖。
4 總結
從上述4種輕量級的網絡模型的實驗比較種可以看出,基於不同的卷積計算方式構造新的網絡結構這個方向是非常有潛力的,而且現階段已有的一些方法與一些complex CNN模型相比,也基本能夠達到state-of-the-art的性能。此外,從上述4種網絡結構的設計中,我們也可以得到如下的一些設計Light Weight CNN模型的經驗:
1) 減少池化操作;
2) 使用較小尺度的卷積核;
3) 採用depth-wise convolution是設計輕量化模型的非常重要的技術,但是要注意解決信息不流通的問題。
最後,由於水平有限,出錯之處,還請多多指教!
備註: 瞭解更多請訪問:http://edu.51cto.com/course/14030.html 。
Reference
[1] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” in Advances in Neural Information Processing Systems (NIPS), pages 1097–1105, 2012
[2] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman, “Return of the Devil in the Details: Delving Deep into Convolutional Nets,” in British Machine Vision Conference (BMVC), 2014.
[3] Karen Simonyan and Andrew Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” in CoRR, 2014. URL http://arxiv.org/abs/1409.1556.
[4] Artem Babenko, Anton Slesarev, Alexandr Chigorin, and Victor Lempitsky, “Neural Codes for Image Retrieval,” in European Conference on Computer Vision (ECCV), volume 8689, pages 584–599, 2014.
[5] Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A, “Going deeper with convolutions,” in CVPR, 7-12 June 2015, doi: 10.1109/CVPR.2015.7298594.
[6] He K, Zhang X, Ren S, Sun J, “Deep residual learning for image recognition,” in Computer Vision and Pattern Recognition, 2016.
[7] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. Alemi, “Inceptionv4, inception-resnet and the impact of residual connections on learning,” arXiv preprint arXiv:1602.07261, 2016.
[8] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2818–2826, 2016.
[9] S. Xie, R. Girshick, P. Doll´ar, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” arXiv preprint arXiv:1611.05431, 2016.
[10] J. T. Springenberg, A. Dosovitskiy, T. Brox, and M. A. Riedmiller, “Striving for simplicity: The all convolutional net,” in CoRR, vol. abs/1412.6806, 2014.
[11] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “Squeezenet: Alexnet-level accuracy with 50x fewer parameters and< 0.5 mb model size,” in ICLR, 2017.
[12] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” in CVPR, 2017.
[13] Zhang X, Zhou X, Lin M, and Sun J, “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” in CVPR 2017. arXiv preprint arXiv:1707.01083
[14] M. Jaderberg, A. Vedaldi, and A. Zisserman, “Speeding up convolutional neural networks with low rank expansions,” arXiv preprint arXiv:1405.3866, 2014.
[15] X. Zhang, J. Zou, X. Ming, K. He, and J. Sun, “Efficient and accurate approximations of nonlinear convolutional networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1984–1992, 2015.
[16] J. Wu, C. Leng, Y. Wang, Q. Hu, and J. Cheng, “Quantized convolutional neural networks for mobile devices,” arXiv preprint arXiv:1512.06473, 2015.
[17] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding,” in CoRR, abs/1510.00149, 2, 2015.
[18] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi, “Xnornet: Imagenet classification using binary convolutional neural networks,” in European Conference on Computer Vision, pages 525–542. Springer, 2016.
[19] Luo JH, Wu J, and Lin W, “Thinet: A filter level pruning method for deep neural network compression,” in ICCV 2017.
[20] Evan Shelhamer, Jonathan Long, Trevor Darrell, “Fully Convolutional Networks for Semantic Segmentation,” in CVPR, 2015.
[21] L. Sifre, “Rigid-motion scattering for image classification,” hD thesis, Ph. D. thesis, 2014.
[22] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in Proc. CVPR, 2009.