




1.List列表
list是處理一組有序項目的數據結構,即你可以在一個列表中存儲一個序列的項目。列表中的項目。列表中的項目應該包括在方括號中,這樣python就知道你是在指明一個列表。一旦你創建了一個列表,你就可以添加,刪除,或者是搜索列表中的項目。由於你可以增加或刪除項目,我們說列表是可變的數據類型,即這種類型是可以被改變的,並且列表是可以嵌套的。
這個是python裏面用的最多最常用的數據類型,可以通過下標來訪問,可以理解爲java或者c裏面的數組.但是功能比數組強大n倍,list可以放任意數量的python對象,可以是字符串,字符,整數,浮點等等都可以,而且創建,添加,刪除也很方便.
1)創建list //list內部的對象可以是字符串,字符,數字,支持混搭
aList = ['apple', 100, 0.01, 'banana','A','B','C']
2)訪問list //直接通過下標去訪問
>>>print(aList[0])
'apple'
3)列表的切片 //通過切片來取列表中的一部分
>>>print(aList[4:6])
['A', 'B']
4)列表的嵌套 //列表支持嵌套,就是列表裏面可以套列表,甚至套字典,元組等
bList=[100,200,['aaa','bbb','ccc']]
>>>print(bList[2][0])
aaa
5)列表的插入//內置函數append,insert
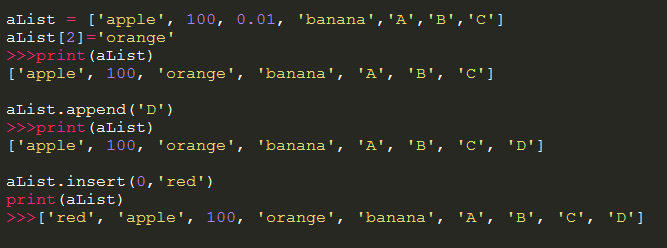
6)列表的刪除//內置remove,pop函數
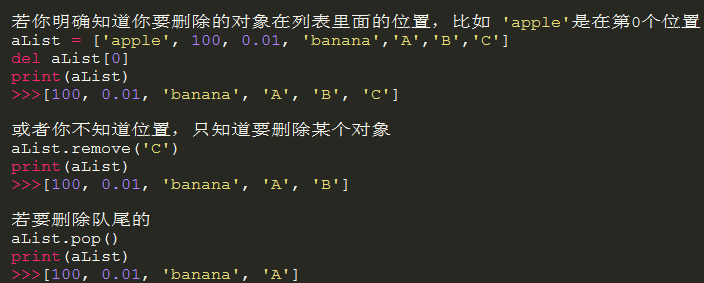
7)列表支持*,+
list1=[1,2,3]
list2=[100,200,300]
list3=list1+list2
print(list3)
>>>[1, 2, 3, 100, 200, 300]
list4=['a','b','c']
list5=list4*3
print(list5)
>>>['a', 'b', 'c', 'a', 'b', 'c', 'a', 'b', 'c']
8)列表的排序//內置了sort函數非常方便,通過傳入reverse爲True或者False來升序或者降序排列
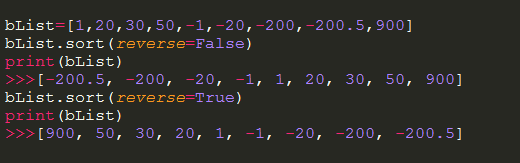
9)計算列表的長度 //利用內置函數len()
aList=[1,2,3,4,5]
print(len(aList))
>>>5
10)計算列表裏面的最大值,最小值
aList=[1,2,3,4,5]
print(min(aList))
>>>1
print(max(aList))
>>>5
當然你若要想知道,最大的前2個數,或者最小的2個數,需要用heapq模塊,以後在python黑魔法裏面會詳細講.
11)列表的擴展 //用內置extend函數,看起來和+差不多,其實區別在於+是返回一個新的列表,而extend是直接修改了列表
aList=[1,2,3]
b=[4,5,6]
aList.extend(b)
print(aList)
>>>[1, 2, 3, 4, 5, 6]
12)查找列表中某一個元素的索引//內置函數index
aList=['This','is','a','very','good','idea']
print(alist.index('very'))
>>>3
13)統計某個元組在列表裏面的次數,內置函數count
aList=['to','do','or','not','to','do']
print(aList.count('to'))
>>>2
以上就是常見的list的用法,注意list是支持重複元素的,就是list裏面可以有2個同樣的元素
比如:
cList=[100,200,'apple','peach','apple']
print(cList)
>>>[100, 200, 'apple', 'peach', 'apple']
後面的教程會講如何一行代碼去掉重複的元素
2.元組
元祖和列表十分相似,不過元組是不可變的。即你不能修改元組。元組通過圓括號中用逗號分隔的項目定義。元組通常用在使語句或用戶定義的函數能夠安全的採用一組值的時候,即被使用的元組的值不會改變。元組可以嵌套。
元組和列表一樣,也是一種序列,唯一的不同在於不能修改
1)元祖的創建
aTuple=(1,2,3)
print(aTuple)
>>>(1, 2, 3)
有一點要注意,當元組裏面只有一個元素的時候,一定要加, 比如(100,)
2)元組的用法和列表一模一樣
很多初學者會問,既然用法和列表一樣,爲啥還要發明元組,原因在於
有一些特殊的場合需要不可變序列,比如後面會講道的數據結構字典,必須要用不可變序列作爲鍵值,而列表不行。
有一些內建的函數的返回值,也必須是元組.
3 字典
字典類似於你通過聯繫人名稱查找地址和聯繫人詳細情況的地址簿,即,我們把鍵(名字)和值(詳細情況)聯繫在一起。注意,鍵必須是唯一的,就像如果有兩個人恰巧同名的話,你無法找到正確的信息。
鍵值對在字典中以這樣的方式標記:d = {key1 : value1, key2 : value2 }。注意它們的鍵/值對用冒號分割,而各個對用逗號分割,所有這些都包括在花括號中。另外,記住字典中的鍵/值對是沒有順序的。如果你想要一個特定的順 序,那麼你應該在使用前自己對它們排序。
基本語法:
dict = {'ob1':'computer', 'ob2':'mouse', 'ob3':'printer'}
技巧:
字典中包含列表:dict={'yangrong':['23','IT'],"xiaohei":['22','dota']}
字典中包含字典:dict={'yangrong':{"age":"23","job":"IT"},"xiaohei":{"'age':'22','job':'dota'"}}
增加字典元素
>>> nameinfo={}
>>> nameinfo['a1']='yangrong' #若字典裏有a1主鍵,則覆蓋原來的值,沒有,則添加
>>> nameinfo
{'a1': 'yangrong'}
遍歷字典主鍵與鍵值
>>> for k, value innameinfo.items():
... print k,value
...
a1 yangrong
查看字典所有主鍵
>>> dict = {'ob1':'computer','ob2':'mouse', 'ob3':'printer'}
>>>
>>>
>>> dict.keys()
['ob2', 'ob3', 'ob1']
判斷字典中是否有該主鍵
>>> dict.keys()
['ob2', 'ob3', 'ob1']
>>> dict.has_key('ob2') #或'ob2' in dict
True
>>> dict.has_key('ob4')
False
也有人用循環方法來判斷
for key in dict.keys():
但是這種方法畢竟不夠簡潔,
查看字典所有鍵值內容
>>> dict = {'ob1':'computer','ob2':'mouse', 'ob3':'printer'}
>>> dict.values()
['mouse', 'printer', 'computer']
列出所有項目
>>> dict.items()
[('ob2', 'mouse'), ('ob3', 'printer'),('ob1', 'computer')]
清空字典
>>> dict.clear()
>>> dict
{}
拷貝字典
>>> dict
{'ob2': 'mouse', 'ob3': 'printer', 'ob1':'computer'}
>>> a=dict
>>> a
{'ob2': 'mouse', 'ob3': 'printer', 'ob1':'computer'}
>>> b=dict.copy()
>>> b
{'ob2': 'mouse', 'ob3': 'printer', 'ob1': 'computer'}
比較字典
>>> cmp(a,b)
首先比較主鍵長度,然後比較鍵大小,然後比較鍵值大小,(第一個大返回1,小返回-1,一樣返回0)
更新字典
>>>dict={'yangrong':{"age":"23","job":"IT"},"xiaohei":{"'age':'22','job':'dota'"}}
>>> dict
{'xiaohei':set(["'age':'22','job':'dota'"]), 'yangrong': {'age': '23', 'job':'IT'}}
>>> dict['xiaohei']=111 #修改一級字典
>>> dict
{'xiaohei': 111, 'yangrong': {'age': '23','job': 'IT'}}
>>> dict['yangrong']['age']=25 #修改二級字典
>>> dict
{'xiaohei': 111, 'yangrong': {'age': 25,'job': 'IT'}}
>>> dict={'yangrong':['23','IT'],"xiaohei":['22','dota']}
>>>dict['xiaohei'][1]="dota2" #修改字典中列表某項,1是代表列表中第2個字符串。
>>> dict
{'xiaohei': ['22', 'dota2'], 'yangrong':['23', 'IT']}
刪除字典元素
>>> dict
{'xiaohei': ['22', 'dota2'], 'yangrong':['23', 'IT']}
>>> del dict['xiaohei'] #刪除xiaohei鍵值
>>> dict
{'yangrong': ['23', 'IT']}
>>> dict
{'yangrong': ['23', 'IT']}
>>>
>>> del dict['yangrong'][1] #刪除yangrong主鍵的每2字值
>>> dict
{'yangrong': ['23']}
刪除整個字典
>>> dict
{'yangrong': ['23']}
>>> dict.clear() #同del dict
>>> dict
{}
將字符串切分爲列表
>>> s="hello world bye"
>>> s.split() #用於把有規律的文本,讀取出來後,使用列表進行修改,再寫入文件。
['hello', 'world', 'bye']
將列表轉換爲字符串
S.split(str, ' ') #將string轉list,以空格切分
存儲字典(pickle序列化)
#需導入pickle模塊 import pickle
把字典內容存入文件
f=file('data.txt','wb') #新建文件data.txt,'wb',b是打開塊文件,對於設備文件有用
pickle.dump(a,f) #把a序列化存入文件
f.close()
把內容讀入字典(反序列化)
a=open('data.txt','rb') #打開文件
print pickle.load(a) #把內容全部反序列化