




OpenTSDB旨在在查詢執行的過程中有效地組合多個不同的時間序列。原因在於:當用戶查看他們的數據,他們通常會從高層的角度開始提問,例如“數據中心的總吞吐量是多少”或“當前地區用電量是多少”。在查看到這些高層次的值之後,可能會出現一個或多個值,以便用戶深入查看更細化的數據集,例如“我的LAX數據中心每臺主機的吞吐量是多少”。我們希望能夠輕鬆地回答這些高層次的問題,也仍然允許深入瞭解更多的細節。
但是,如何將多個單獨的時間序列合併成一系列的數據?聚合函數提供了將不同時間序列合併成一個的數學方法。過濾器用於按標籤對結果進行分組,然後將聚合應用與每個分組。聚合類似於SQL的Group By子句,其中用戶選擇預定義的聚合函數將多個記錄合併爲單個結果。但是,在TSD中,按照每個時間戳分組聚合一系列記錄爲一組。
每個聚合器都有兩個組件:
- 函數:應用的數學計算方法,如將所有的值累加在一起,計算出平均值或者篩選出最高(大)值。
- 插值:處理缺失值的一種方法。例如將時間序列A在T1有值,但時間序列B沒有值。
本章將重點介紹在group by上下文中如何使用聚合,例如:即合併多個時間序列爲一個時。另外,可以使用聚合器對時間序列進行降採樣(即返回一組分辨率較低的結果)。有關更多信息,請參閱降採樣。聚合
將每個時間序列集合聚合或者分組到一箇中時,每個時間序列中的時間戳都對齊。然後對於每個時間戳,所有時間序列中的值將聚合爲一個新的數值。也就是說,聚合將會在每個時間戳的時間序列上工作。將原始數據視作矩陣或者表,如以下示例所示,該圖說明了sum聚合器在兩個時間序列上的工作原理,A與B合併生成新的Output時間序列。
| 時間序列 | T0 | T0+10s | T0+20s | T0+30s | T0+40s | T0+50s |
|---|---|---|---|---|---|---|
| A | 5 | 5 | 10 | 15 | 20 | 5 |
| B | 10 | 5 | 20 | 15 | 10 | 0 |
| Output | 15 | 15 | 10 | 30 | 30 | 5 |
對於時間戳T0的數據點A和B進行求和,即5+10=15,在SQL中:
select sum(value) from ts_table group by timestamp
插值
在上面的例子中,時間序列A和B每個時間戳都有數據點,他們排列整齊。然而,當兩個序列不會排隊時會發生什麼?同步所有數據源並同時進行寫入可能很困難,有時甚至是不希望的。例如,如果我們有10,000個服務器每5分鐘發送100個系統指標標準,那麼將在一秒鐘內突發10M的數據點。我們需要一個非常強大的網絡和羣集來適應這種流量。更不用說系統會閒置4分59秒。相反,隨着時間的推移張開寫入更有意義,因此我們平均每秒寫入3,333次寫入,以減少對硬件和網絡的要求。
如何彙總聚合或找到一個不存在的數值的平均值?第一步就是返回有效的數據點並完成它。然而,如果像上面那樣處理了數千個簡單未對其的數據點的數據源呢?例如:下圖展示了未對齊寫入的時間序列,引起的鋸齒狀線條令人困惑: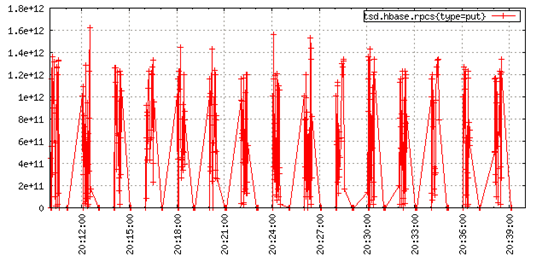
- 缺失數據:
通過“缺失”,只是表示時間序列在給定的時間戳出沒有數據點。通常,數據在請求的時間戳之前或者之後簡單地進行時間移位,但如果源或TSD遇到錯誤並且數據未被記錄,它實際上可能會丟失。一些時間序列數據庫可能允許在時間戳中用NaN存儲一個表示不可記錄的值,但OpenTSDB不允許這樣做。
或者,可以簡單的忽略任意缺少數據的給定時間戳的所有時間序列的數據點。但是,如果有兩個時間序列,並且它們只是簡單的未對齊,即使在存儲中有正常的數據,查詢也會返回一個空的數據集,所以這不一定非常有用。
另外一個選項是定義一個標量值(如0或者Long型的最大值),以便在數據點丟失時使用。OpenTSDB2.0和更高版本提供了一些聚合函數,用於替代丟失數據點的標量值,實際上,上圖是使用zimsum聚合器生成的,該聚合使用0替換未對齊的值。當處理不同值的時間序列時,這種替代可能非常有用,例如在給定時間內的總銷售數量,但在處理平均值或驗證可視化圖表看起來不錯(平緩)時不起作用。
OpenTSDB提供的一個解決方案是使用定義良好的插值數值分析方法來猜測該時間點的值。插值使用現有的時間序列數據點來計算所需時間戳的最佳猜測值。使用OpenTSDB的線性插值,可以平滑未對齊的圖,得到:
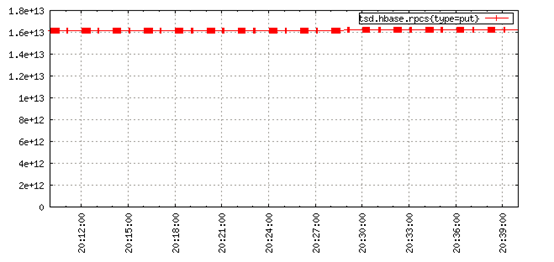
對於一個數值例子,看看這兩個時間序列,其中源沒20秒發出一個值,數據簡單的偏移10秒:
| 時間序列 | T0 | T0+10s | T0+20s | T0+30s | T0+40s | T0+50s | T0+60s |
|---|---|---|---|---|---|---|---|
| A | na | 5 | na | 15 | na | 5 | na |
| B | 10 | na | 20 | na | 10 | na | 20 |
當OpenTSDB計算聚合時,它會從任何序列的第一個數據點開始,在這種情況下,它將是B序列的t0數據點。我們需要時間序列A在t0的值,但此處沒有任何數據。我們知道時間序列A在t0+10秒有數據值。但由於在此之前我們沒有任何值,所以我們不能猜測它會是什麼。因此,我們只能返回時間序列B的值。
接下來我們在時間戳t0+10秒,請求時間序列B在t0+10秒的值,但是沒有。但是時間序列B在t0+20秒有一個值,同時在t0也有一個值,因此我們現在可以計算猜測t0+10秒的值。線性插值的公式是y=y0+(y1-y0)((x-x0)/(x1-x0)),對序列B來說,y0=10, y1=20, x=t0+10(或10), x0=t0(或0), x1=t0+20(或20),因此:y=10+(20-10)((10-0)/(20-0))=15。因此序列B在t0+10秒給我們一個估計值15。
對於作爲查詢的一部分返回的每個序列找到數據點的每個時間戳都會繼續進行迭代。使用sum聚合器生成的結果序列將如下所示:
| 時間序列 | T0 | T0+10s | T0+20s | T0+30s | T0+40s | T0+50s | T0+60s |
|---|---|---|---|---|---|---|---|
| A | na | 5 | na | 15 | na | 5 | na |
| B | 10 | na | 20 | na | 10 | na | 20 |
| 插值A | 10 | 10 | |||||
| 插值B | 15 | 15 | 15 | ||||
| B | 10 | na | 20 | 15 | 10 | na | 20 |
| Summed Result | 10 | 20 | 30 | 20 | 20 | 20 | 20 |
原文表格如下: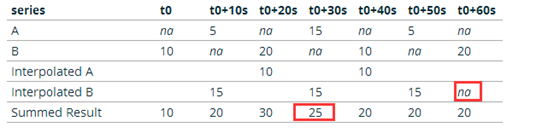
更多示例:
對於圖形傾斜我們有以下示例。在OpenTSDB中記錄了一個虛構的指標m。“sum of m”是由查詢start=1h-ago&m=sum:m產生的頂部的藍線。它是由紅線host=foo和綠線host=bar的和組成的。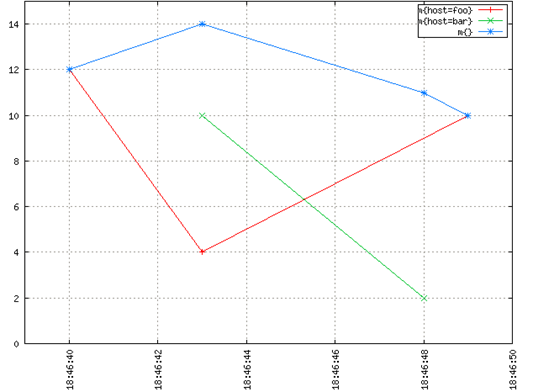
從上面的圖像看起來很直觀,如果“疊加”紅線和綠線,會得到藍線。在任何離散的時間點,藍線的值等於當時紅線值和綠線值的和。如果沒有插值,會得到一些比較不直觀的東西,這樣很難理解,而且它也沒有那麼有意義和有用。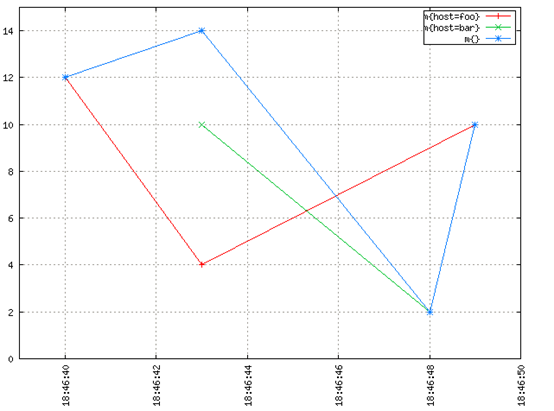
注意18:46:48藍線如何下降到綠色數據點。不需要成爲一名數學家,也不需要高級數學課程才能看到需要進行插值,才能將多個時間序列正確的聚合在一起並獲得有意義的結果。
目前OpenTSDB主要支持線性插值(縮寫”lerp”)以及一些簡單的替換0或最大值或最小值的聚合器。歡迎大家添加其他插值算法來修補程序。
插值僅在查詢時發現多個時間序列與查詢匹配時執行。許多指標採集系統在寫入是進行插值,以便您永遠不會記錄原始值。OpenTSDB存儲原始值,並且可以隨時檢索它。
這是來自郵件列表的另一個稍微複雜的例子,描述了多個時間序列按照平均值聚合的情況: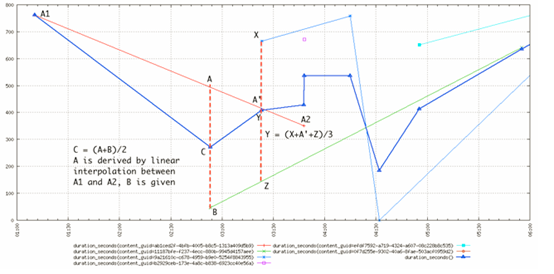
帶有三角形的粗藍線是根據查詢(start=1h-ago&m=avg:duration_seconds)具有多個時間序列avg函數的聚合。正如我們所看到的,由此產生的時間序列在其聚合的所有基礎時間序列的每個時間戳上都有一個數據點,並且該數據點是通過取得該時間戳的所有時間序列值的平均值來計算的。對於紫色方形的孤獨數據點也是如此,這樣將暫時提高平均值知道下個數據點。
注意:
聚合函數根據輸入數據點返回整數或者雙精度值。如果兩個原值在存儲中均爲整數,則計算結果將爲整數。這意味着由計算得到的任何小數值將被刪除,不會發生舍入。如果任一數據點是浮點值,則結果將是浮點數。但是如果啓用降採樣或者Rate,結果將始終爲浮點數。
降採樣
如上所述,插值是處理丟失數據的一種手段。但有些用戶不喜歡線性插值,它是一種產生lie數據的方式,會產生幻像值。相反,處理未對齊值的另一種方法是通過降採用。例如:源每分鐘報告一個值,但是在那一分鐘內他們會發生時間偏移,那麼對於源數據中的每個查詢,在1分鐘內提供一次降採用。這將在每個時間序列有顯著的值,使用與插值相同的時間戳大多是可以避免的。當降採樣的桶丟失一個值時,插值仍然會發生。
有關避免插值的詳細信息和示例,請參見降採樣。
注意:
總體來說,對於包含多個時間序列的每個查詢進行降採樣是一個很好的理想選擇 。
可用聚合器
以下是對OpenTSDB中可用的聚合函數描述。請注意,有些應該只用於分組,其他則用於降採樣。
| 聚合器 | TSD版本 | 描述 | 插值 |
|---|---|---|---|
| avg | 1.0 | 數據點平均值 | 線性插值 |
| count | 2.2 | 集合中原始數據點的數量 | 0替換缺失值 |
| dev | 1.0 | 計算標準差 | 線性插值 |
| Ep50r3 | 2.2 | 使用R-3方法計算估計的50% | 線性插值 |
| Ep50r7 | 2.2 | 使用R-7方法計算估計的50% | 線性插值 |
| Ep75r3 | 2.2 | 使用R-3方法計算估計的75% | 線性插值 |
| Ep75r7 | 2.2 | 使用R-7方法計算估計的75% | 線性插值 |
| Ep90r3 | 2.2 | 使用R-3方法計算估計的90% | 線性插值 |
| Ep90r7 | 2.2 | 使用R-7方法計算估計的90% | 線性插值 |
| Ep95r3 | 2.2 | 使用R-3方法計算估計的95% | 線性插值 |
| Ep95r7 | 2.2 | 使用R-7方法計算估計的95% | 線性插值 |
| Ep99r3 | 2.2 | 使用R-3方法計算估計的99% | 線性插值 |
| Ep99r7 | 2.2 | 使用R-7方法計算估計的99% | 線性插值 |
| Ep999r3 | 2.2 | 使用R-3方法計算估計的999% | 線性插值 |
| Ep999r7 | 2.2 | 使用R-7方法計算估計的999% | 線性插值 |
| first | 2.3 | 返回集合中的第一個數據點。僅僅對降採樣有用,對聚合無用 | 不定 |
| last | 2.3 | 返回集合中的最後一個數據點。僅僅對降採樣有用,對聚合無用 | 不定 |
| mimmin | 2.0 | 篩選最小的數據點 | 線性插值 |
| mimmax | 2.0 | 篩選最大的數據點 | 線性插值 |
| min | 1.0 | 篩選最小的數據點 | 線性插值 |
| max | 1.0 | 篩選最大的數據點 | 線性插值 |
| none | 2.3 | 通過所有時間序列的聚合跳過組 | 0替換缺失值 |
| p50 | 2.3 | 計算50% | 線性插值 |
| p75 | 2.3 | 計算75% | 線性插值 |
| p90 | 2.3 | 計算90% | 線性插值 |
| p95 | 2.3 | 計算95% | 線性插值 |
| p99 | 2.3 | 計算99% | 線性插值 |
| p999 | 2.3 | 計算999% | 線性插值 |
| sum | 1.0 | 將數據點一起求和 | 線性插值 |
| zimsum | 1.0 | 將數據點一起求和 | 0替換缺失值 |
獲取百分比計算,閱讀維基百科文章。對高基數的計算,使用估計百分比性能更好。
Avg
計算降採樣桶或跨多個時間序列所有值的平均值。該函數將在事件序列上執行線性插值。這對於查看gauge指標非常有用。
注意:
即使計算通常會導致浮點值,但如果數據點以整數記錄,則會返回一個整數,從而失去一些精度。
Count
返回存儲在序列或者範圍中的數據點的數量。當用於聚合多個序列是,將使用0替換缺失值。與將採樣一起使用時,它將反映每個降採樣桶中數據點的數量。用於分組聚合時,反映了給定時間的值與時間序列的數量。
Dev
計算一個桶或時間序列的標準差。該函數將在事件序列上執行線性插值。這對於查看gauge指標非常有用。
注意:
即使計算通常會導致浮點值,但如果數據點以整數記錄,則會返回一個整數,從而失去一些精度。
Estimated Percentiles
使用算法選擇計算各種百分比。這些對於有很多數據點的序列很有用,因爲有些數據可能會被踢出計算。用於聚合多個序列時,該函數將執行線性插值。詳情請參閱維基百科。實現是通過Apache Math庫實現的。
First &Last
這兩個聚合器將返回降採樣間隔中的第一個或最後一個數據點。例如,如果降採樣桶由序列2, 6, 1, 7組成,那麼first聚合器將返回2(原文爲1),last聚合器將返回7。注意該聚合器僅僅對降採樣有用。
警告:
當用作group-by聚合器時,結果是不確定的,因爲從存儲中檢索讀取並保存在內存中的時間序列排序從TSD到TSD或從執行到執行不一致。
Min
返回所有時間序列或時間範圍內最小的數據點。該函數將在事件序列上執行線性插值。查看gauge指標的下限很有用處。
Max
與min相反,返回所有時間序列或時間範圍內最大的數據點。該函數將在事件序列上執行線性插值。查看gauge指標的上限很有用處。
MimMin
“缺失最小值時的最大值”函數僅返回所有時間序列或時間範圍內的最小數據點。該函數不會執行插值,而是會返回指定的數據類型的最大值(如果值缺失)。這將返回整數Long.MaxValue或浮點值Double.MaxValue。詳情請參閱原始數據類型。這對於查看gauge指標的下限非常有用。
MimMax
“缺失最大值時的最大值”函數僅返回所有時間序列或時間範圍內的最大數據點。該函數不會執行插值,而是會返回指定的數據類型的最小值(如果值缺失)。這將返回整數Long.MinValue或浮點值Double.MinValue。詳情請參閱原始數據類型。這對於查看gauge指標的上限非常有用。
None
通過聚合跳過組。此聚合器對於從存儲中獲取原始數據非常有用,因爲它將爲每個匹配過濾器的時間序列返回一個結果集。請注意:查詢將在與降採樣器一起使用時引發異常。
Percentiles
計算各種百分比。用於聚合多個序列時,該函數將執行線性插值。實現是通過Apache Math庫實現的。
Sum
如果降採樣,計算所有時間序列或時間範圍內的所有數據點的總和。它是GUI的默認聚合函數,因爲它在組合多個時間序列(例如gauges或count)時通常最有用。當數據點無法排列時,它執行線性插值。如果有不同序列的值,你又想求和時不需要插值,看一下zimsum函數。
ZimSum
根據所有時間序列或時間範圍內指定的時間戳計算所有數據點的總和。此函數不能進行插值,而是一個用0替代缺失的數據點。這在使用離散值時很有用。
聚合器列表
在啓用HTTP API的TSD中調用HTTP接口/api/aggregators,將列出TSD實現的聚合器列表。