




本文利用KNIME基於Spark決策樹模型算法,通過對泰坦尼克的包含乘客及船員的特徵屬性的訓練數據集進行訓練,得出決策樹倖存模型,並利用測試數據集對模型進行測試。
1、從Kaggle網站下載訓練數據集和測試數據集
2、在KNIME創建新的Workflow,起名:TitanicKNIMESpark

3. 讀取訓練數據集
KNIME支持從Hadoop集羣讀取數據,本文爲了簡化流程直接從本地讀取數據集。
在Node Repository的搜索框裏輸入CSV Reader,找到CSV Reader節點,並將它拖入畫布。

雙擊或右擊CSV Reader對節點進行配置,設置數據集的目錄。

右擊節點,點擊Excute, 然後右擊節點,點擊File table查看結果

4.利用Missing Value節點對缺失值進行處理
類似第三步的操作找到Missing Value節點,並拖入畫布(本文以下操作類似,不再重複),並根據需要設置屬性,這裏採用簡單取平均值的方法處理缺失值。建立CSV Reader節點到Missing Value節點的連接。

右擊節點,點擊Excute, 然後右擊節點,點擊Output Table查看結果

5、添加Create Spark Context節點,設置Spark Context
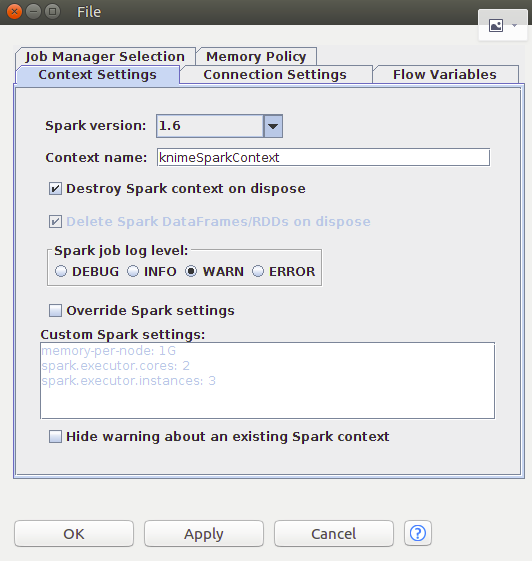
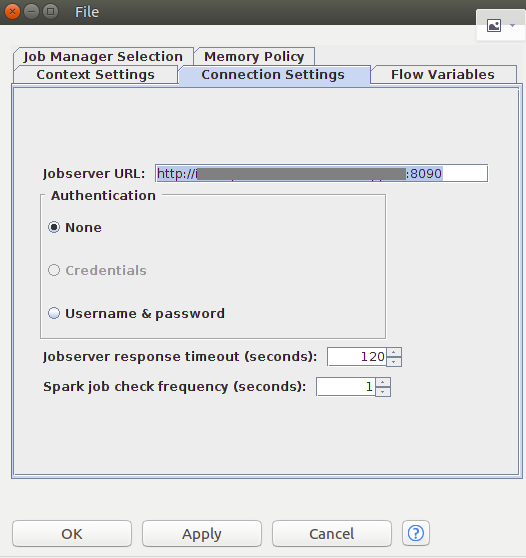
6 .添加Table to Spark節點,將KNIME數據錶轉換成Spark的DataFrame/RDD,配置Table to Spark節點並建立Missing Value節點到Table to Spark節點的連接,建立Create Spark Context節點到Table to Spark節點的連接。
這裏採用默認配置。
7. 添加Spark Normalizer節點,將Survived屬性從數字類型轉換成爲字符類型,配置Spark Normalizer節點並建立Table to Spark節點到Spark Normalizer節點的連接。

右擊節點,點擊Excute, 然後右擊節點,點擊Normalized Spark DataFrame/RDD查看結果.

8. 添加Spark Decision Tree Learner節點,配置決策樹算法參數,並建立Spark Normalizer節點到Spark Decision Tree Learner節點的連接。

右擊節點,點擊Excute, 然後右擊節點,點擊Decision Tree Model查看結果.

9利用測試數據集和Spark Predictor節點對模型進行測試。
複製CSV Reader,Missing Value和Table to Spark節點並參考3,4,6步進行配置讀取測試數據集並對數據進行處理和轉換。添加Spark Predictor節點, 配置 Spark Predictor節點,並將新添加的Table to Spark節點以及Spark Decision Tree Learner節點和Spark Predictor相連接。
CSV Reader配置測試數據集。

Spark Predictor節點配置Prediction column

右擊節點,點擊Excute, 然後右擊節點,點擊Labled Data查看結果.

10.可以添加其他節點對結果進行後續處理,這裏添加只添加Spark Column Filter節點過濾掉不需要的column。
添加Spark Column Filter節點並進行配置。

右擊節點,點擊Excute, 然後右擊節點,點擊Filtered Spark DataFrame/RDD查看結果。

最終整個workflow如下圖所示
