




問題描述
有一個應用,偶爾會出現訪問不了的情況。具體表現爲,當其它應用調用它的接口時,可能會出現超時,過一段時間後,再調用它的接口可能又正常了。觀察應用日誌發現,這個被調用的應用會偶發性地連接不上數據庫。因爲該應用沒有辦法及時地查詢到數據庫,應用返回數據時間過長,也就導致調用該應用接口的其它應用超時。這種情況比較偶發,一天大概幾次,沒什麼特別規律。
應用日誌中只能大概看出,出現問題時該應用查詢不了數據庫,與數據庫的連接丟失,沒有太多其它的信息:
2017-06-05 23:23:44,941 INFO (?:?) - Get a connection... 2017-06-05 23:39:11,670 INFO (?:?) - SearchPoList() has a Exception: java.sql.SQLException: ORA-03135: connection lost contact 2017-06-05 23:39:11,670 WARN (HouseKeeper.java:149) - #0001 was active for 324896 milliseconds and has been removed automaticaly. The Thread responsible was named 'http-8086-Processor24', but the last SQL it performed is unknown because the trace property is not enabled. 2017-06-05 23:39:11,671 INFO (?:?) - Connection closed... 2017-06-05 23:39:11,676 WARN (RequestProcessor.java:516) - Unhandled Exception thrown: class java.sql.SQLException 2017-06-05 23:39:11,679 ERROR (StandardWrapperValve.java:253) - Servlet.service() for servlet action threw exception java.sql.SQLException: ORA-03135: connection lost contact
at oracle.jdbc.driver.DatabaseError.throwSqlException(DatabaseError.java:112) at oracle.jdbc.driver.T2CConnection.checkError(T2CConnection.java:672) at oracle.jdbc.driver.T2CConnection.checkError(T2CConnection.java:598) at oracle.jdbc.driver.T2CPreparedStatement.executeForDescribe(T2CPreparedStatement.java:571) at oracle.jdbc.driver.OracleStatement.executeMaybeDescribe(OracleStatement.java:1038) at oracle.jdbc.driver.OracleStatement.doExecuteWithTimeout(OracleStatement.java:1133) at oracle.jdbc.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement.java:3285) at oracle.jdbc.driver.OraclePreparedStatement.executeQuery(OraclePreparedStatement.java:3329) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25) at java.lang.reflect.Method.invoke(Method.java:585) at org.logicalcobwebs.proxool.ProxyStatement.invoke(ProxyStatement.java:100) at org.logicalcobwebs.proxool.ProxyStatement.intercept(ProxyStatement.java:57) at oracle.jdbc.OracleStatement$$EnhancerByProxool$$e42bfc21.executeQuery(<generated>) at com.sssoft.framework.db.DefaultDbManager.executeQuery(Unknown Source) |
雖然說已經確定是應用連接不上數據庫導致的故障,但,爲什麼該應用會連接不上數據庫並且還是偶發性的呢?關於這個問題,開發和DBA等人一同排查了好幾天,竟然沒有任何頭緒,最後找到了我。而我,作爲一個懂網絡、操作系統、數據庫(雖然是MySQL)和略懂程序的,具備全方面知識體系(稍微自誇下,但後面你就會知道,的確涉及到了各方面的知識)的運維工程師,自然不能放過這麼有趣的問題了。好吧,其實是因爲這個應用當初是我部署上線的,我怎麼能允許我自己部署的應用出現問題呢。況且,其它連接同一個數據庫的應用也沒說過有問題啊,然而,事實證明,這個問題涉及到的水比較深。
出現連接不上數據庫的那個應用是Java程序來的,它使用了proxool連接池來連接數據庫。而數據庫本身是Oracle數據庫。
問題初步排查
這個問題排查起來可能不是很容易有思路。當然,作爲一個系統運維工程師,我還是習慣於從操作系統層面開始排查起。由於問題是偶發性的,想要復現並不容易。但既然是應用連接不上數據庫,那麼可以觀察下網絡連接。
經過觀察,我發現,在應用啓動後的一段時間後,在應用服務器上大概有10多個與oracle數據庫服務器的tcp連接:
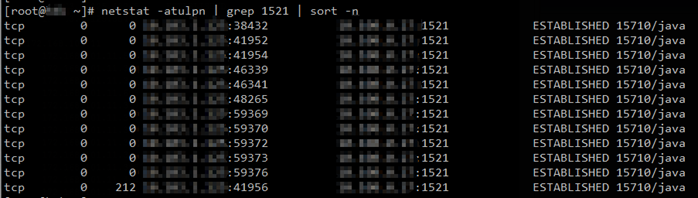
但同一時刻,在Oracle數據庫服務器上,卻只能看到2個與應用服務器的tcp連接:

由於應用採用數據庫連接池來連接Oracle數據庫,也就是說,應用與數據庫之間的連接是tcp長連接。那麼正常情況下,在任一時刻,應用與數據庫服務器兩端的ESTABLISHED狀態的tcp連接數量應該都是一致的。然而,我實際觀察到的情況,正如上面所示,卻不是這樣。經過更加細緻的觀察,可以發現,一開始,在該應用剛剛啓動時,兩端的tcp連接數量是相同的。但是,過了一段時間後,oracle數據庫服務器端與應用服務器的tcp連接數量開始減少,甚至出現爲0的現象。這時就出現了我上面所觀察到的奇異現象了。
兩端的ESTABLISHED狀態的tcp連接數量不一致是不是一定就有問題的呢?答案是肯定的。因爲tcp是面向連接的協議,連接的兩端只有通過"三次握手"正常建立了tcp連接後,它們才能正式通過該tcp連接開始交互數據。如果其中一端不存在該tcp連接的信息,那麼即便另一端通過該tcp連接發送帶應用數據的數據包過來了,不存在tcp連接信息的這一端收到數據包後也會直接將該數據包丟棄,從而導致兩端無法正常交互數據。因此,問題就出在這了,正是因爲應用和數據庫服務器兩端的tcp連接不對稱,才導致了應用無法正常訪問數據庫。
但是,爲什麼會出現這種兩端的tcp連接數不對稱的情況呢?爲了方便排查故障,我另外克隆了一臺應用服務器。這臺新的應用服務器只有我在使用,當我不訪問上面的應用時,上面的應用也就不會訪問數據庫,這樣便於排查。這臺新的應用服務器的IP是x.x.x.125,所連接的數據庫服務器的IP是y.y.y.27。當經過一段時間後,這臺應用服務器與數據庫服務器各自上面的tcp連接數也開始出現不對稱了。在應用服務器和數據庫服務器上使用tcpdump抓包,再下載下來使用wireshark打開,可以發現下面三個比較怪異的現象:
1、 在應用剛啓動時,保持應用空閒(即我不去訪問應用,也就不會觸發應用去訪問數據庫),此時抓包可以發現,雖然應用和數據庫之間已正常建立了連接,但它們之間卻沒有任何數據包交互。

2、 當應用啓動後經過一段時間後,數據庫服務器端查看到的tcp連接數開始下降。如果我不去訪問應用的話,數據庫服務器端的tcp連接數甚至會降爲0。應用服務器端的tcp連接數仍然保持跟應用剛啓動時一樣,有10多個。此時,我通過網頁來訪問應用,從而觸發應用去訪問數據庫,我對這個過程進行抓包:

上面是我在應用服務器上的抓包結果。可以發現,應用服務器125的確有去往數據庫服務器27的數據包,但卻沒有來自數據庫服務器27的回包。所以應用服務器125一直在進行tcp重傳(Retransmission)。此時,在數據庫服務器27上面抓包,也的確沒有抓到來自應用服務器125的數據包。這說明,因爲某種原因,從應用服務器125發出的數據包在網絡中丟失了。具體是什麼原因,現在還無法確定。
3、 當數據庫服務器端的tcp連接數開始下降時,此時在數據庫服務器端抓包:
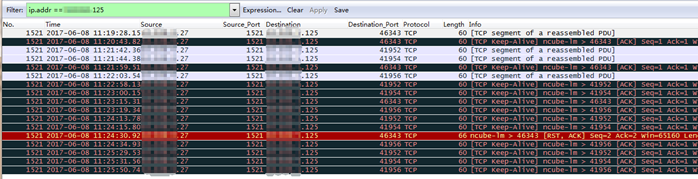
可以發現,數據庫服務器27嘗試發送Keep-Alive包給應用服務器125,但並沒有收到應用服務器125的回包。數據庫服務器27在後面還發送了一個RST包重置了y.y.y.27:1521 x.x.x.125:46343這個tcp連接,這直接導致了數據庫服務器上的這個tcp連接被清理掉。同一時刻,在應用服務器125也沒有抓到來自數據庫服務器27的包。這也說明,因爲某種原因,從數據庫服務器27發出的數據包在網絡中丟失了。
此外,也還有很多疑問尚待解決。比如,那個Keep-Alive包是幹什麼的,爲什麼會有Keep-Alive包?又爲什麼會有RST重置包?
目前還沒有明顯的解決問題的思路,但我想,如果能搞清楚以上三個怪異現象/疑點,搞清楚哪些是正常的哪些是異常的,應該可以定位到出現異常的哪一部分(源端、目標端、網絡還是數據庫),從而幫助解決問題。
應用的網絡架構
既然涉及到了數據包在網絡中丟失,那麼,就有必要介紹一下應用服務器與數據庫服務器之間的網絡架構。
網絡拓撲圖可簡化如下:
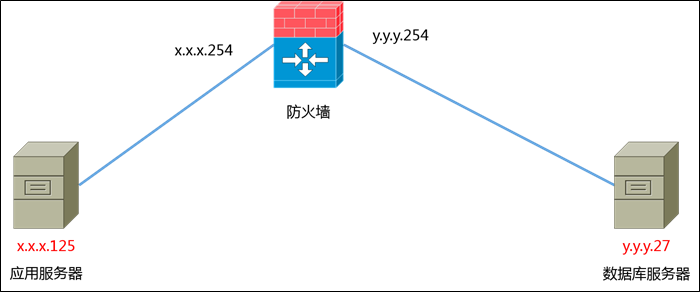
簡單來說,應用服務器(x.x.x.125)與數據庫服務器(y.y.y.27)分屬不同網段,中間有臺防火牆,各個網段的網關(x.x.x.254和y.y.y.254)也位於防火牆上。雖然中間還有很多二層交換機、三層交換機等,但對問題的產生沒什麼影響,所有就省略不表。
按理說,數據包在網絡中丟失了,那麼,就應該找網絡工程師一起排查下是什麼問題。但無奈,我司的網絡工程師水平太低,對網絡底層原理、概念等的掌握還不如我(這並不是我自誇自擂)。簡單來說,我從網絡工程師那裏沒有獲取到任何有價值的信息,他們也不認爲網絡本身有什麼問題,也不願意協助排查,我也沒有權限看不了防火牆,所以我只能自己想辦法排查了。
tcp連接的保持
前面我提到,在抓包時,我發現了3個怪異的現象。其中,第一個現象是,在應用剛啓動,應用空閒時(即應用不主動去訪問數據庫),雖然應用和數據庫之間已正常建立了連接,在應用和數據庫服務器兩端均可看到等量的並對稱的ESTABLISHED狀態的連接,但抓包卻發現它們之間沒有傳遞任何數據包。
關於這個問題,我查閱了<<TCP/IP Illustrated, Volume 1: The Protocols>>。其中,TCP Keepalive這章裏面有提到:
Many newcomers to TCP/IP are surprised to learn that no data whatsoever flows across an idle TCP connection. That is, if neither process at the ends of a TCP connection is sending data to the other, nothing is exchanged between the two TCP endpoints. There is no polling, for example, as you might find with other networking protocols. This means that we can start a client process that establishes a TCP connection with a server and walk away for hours, days, weeks, or months, and the connection should remain up. In theory, intermediate routers can crash and reboot, data lines may go down and back up, but as long as neither host at the ends of the connection reboots (or changes its IP address), the connection remains established. This is how TCP/IP was designed. |
上面這段話的意思是:空閒的TCP連接是沒有數據流動的,也就是說,如果TCP連接的兩端如果都不發送數據給對方,就沒有任何東西在它們之間交互;也不會有定時的數據包輪詢;當一個客戶端和一臺服務器建立TCP連接之後,若服務器離開幾個小時、幾天或幾個月,連接也都還在的,即便中間的路由器和線路掛了、重啓了或斷了,但只要TCP連接兩端的主機都沒有重啓(或更改它的IP地址),連接會一直保持ESTABLISHED狀態;TCP/IP就是這麼設計的。
也就是說,我觀察到的第一個現象(應用空閒時,雖然應用服務器和數據庫服務器之間建立了ESTABLISHED狀態的連接,但卻沒有數據包交互),該現象是正常的。TCP/IP就是這麼設計的。
但是,在該章的其它地方,它說:存在一種TCP keepalive機制,但它是可選的。TCP keepalive特性並不是TCP規範的一部分(因爲可能會有誤判及產生額外的流量等),然而,大多數TCP實現都提供了keepalive能力。即便如此,TCP keepalive功能默認也可能是關閉的。
TCP keepalive功能可以在TCP連接的其中一端,或兩端啓用,或兩端都不啓用。它的運作機制是這樣的:如果TCP連接上有一段時間(叫做keepalive time)沒有活動,那麼,啓用了keepalive的一端就會發送存活探測數據包給它的對端。如果沒有收到任何響應數據包,該探測包就會週期性地(週期間隔爲keepalive interval)重複發送,直到探測次數達到keepalive probes的設置值。當發生這種情況時,對端的系統將被判定爲是不可恢復的並且該TCP連接會被終止。
變量keepalive time、keepalive interval和keepalive probes的值通常是可以修改的。一些系統允許在per-connection的基礎上進行這些修改,另一些系統則只能在全局範圍修改(或可能兩種都支持)。在Linux中,這些值可以通過sysctl系統參數來相應修改:net.ipv4.tcp_keepalive_time、net.ipv4.tcp_keepalive_intvl和net.ipv4.tcp_keepalive_probes。默認值分別是7200 (seconds,或2 hours)、75 (seconds)和9 (probes)。
Linux並未提供一個原生的工具來爲那些未請求啓用TCP keepalive的應用強制開啓TCP keepalive功能。換句話說,雖然Linux支持TCP keepalive特性,也可以調整相關的定時器設置,但某一個TCP連接究竟是否啓用TCP keepalive特性,由上層的應用程序說了算(需要應用程序調用系統的API),Linux本身並沒有工具/設置項來讓你爲所有TCP連接都強制開啓TCP keepalive特性。
1) 回到問題本身,應用服務器是RHEL系統,屬於Linux的一種,自然也支持上面提到的三個屬性:
[root@gw ~]# sysctl -a | grep 'keepalive' net.ipv4.tcp_keepalive_time = 7200 net.ipv4.tcp_keepalive_probes = 9 net.ipv4.tcp_keepalive_intvl = 75 |
各參數含義:
net.ipv4.tcp_keepalive_time:如果TCP連接啓用了TCP keepalive特性,那麼,當TCP連接空閒時間達到該項設定值時,服務器就會發送存活探測數據包給它的對端。默認值是7200 (seconds,或2 hours)。
net.ipv4.tcp_keepalive_probes:發送存活探測數據包後,若未收到來自對端的響應數據包,服務器會嘗試重新發送探測數據包,直到總的探測次數達到該項設定值。默認值是9 (probes)次。若最後一次探測時仍未收到對端的響應數據包,服務器會清除掉自己本端的該TCP連接。
net.ipv4.tcp_keepalive_intvl:每次發送探測數據包的間隔時間。默認值是75 (seconds)。那麼來說,從開始探測到最後清除TCP連接,總共需要經過tcp_keepalive_intvl * tcp_keepalive_probes的時間,若以默認值計算,爲75 * 9 = 675秒,約爲11分鐘多。
即便如此,我又怎麼知道應用服務器去往數據庫服務器的TCP連接是否啓用了TCP keepalive呢?畢竟,我無法知道應用程序是否有要求啓用TCP keepalive。其實,通過netstat命令的 -o 選項可以查看到,在應用服務器上執行以下命令:
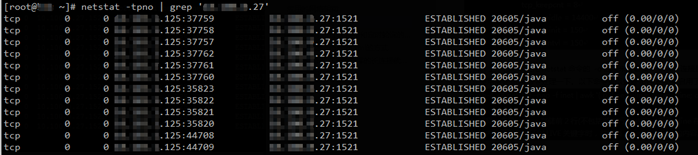
最後一列都是off的,說明在應用服務器125這端,所有與數據庫服務器27的TCP連接都是沒有啓用TCP keepalive特性的。如果有啓用的話,那麼最後一列會顯示keepalive的字樣。
2) 數據庫服務器是AIX系統,它也有一些類似的屬性:
bash-4.2# no -a | grep 'tcp_keep' tcp_keepcnt = 8 tcp_keepidle = 14400 tcp_keepinit = 150 tcp_keepintvl = 150 |
各參數含義:
tcp_keepcnt:等同於Linux的net.ipv4.tcp_keepalive_probes參數。默認值是8次。
tcp_keepidle:等同於Linux的net.ipv4.tcp_keepalive_time參數。單位爲0.5秒,默認值是14400(即7200秒或2小時)。
tcp_keepinit:TCP連接的初始超時時間。AIX的官方文檔中是這麼說的,但沒詳細解釋。單位爲0.5秒,默認值是150(即75秒)。
tcp_keepintvl:等同於Linux的net.ipv4.tcp_keepalive_intvl參數。單位爲0.5秒,默認值是150(即75秒)。那麼來說,從開始探測到最後清除TCP連接,總共需要經過tcp_keepintvl * tcp_keepcnt的時間,若以默認值計算,爲75 * 8 = 600秒,即10分鐘。
在AIX上,也可以使用netstat命令的 -o選項,但需結合awk來處理。想要查看ipv4協議的與某一臺服務器(假設爲x.x.x.x)的TCP連接是否啓用了TCP keepalive特性,可以使用下面的命令,只需要把x.x.x.x替換爲相應的IP就行:
netstat -nao -f inet | awk '{ p2line=pline; pline=cline; cline=$0; if(p2line ~ /x.x.x.x/) {print p2line cline}; }'
# 解釋:變量p2line存儲前2行(不包括前1行)的內容,變量pline存儲前1行的內容,變量cline存儲當前行的內容。當 # p2line的內容匹配到指定IP時,就輸出p2line和cline的內容。 |
命令輸出結果如下:
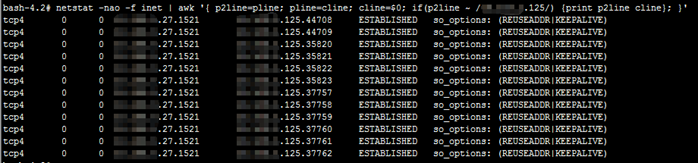
可以看到,在數據庫服務器27這端,所有與應用服務器125的TCP連接都有啓用TCP keepalive特性。可以看到KEEPALIVE字樣。
我並沒有查到有任何AIX官方資料說,AIX會強制爲TCP連接啓用TCP keepalive特性,所以建議還是以實際觀察爲準。
經過上述的分析,現在我們可以解答之前觀測到的一些現象了。爲什麼應用啓動後經過一段時間後,在數據庫服務器端觀察到的TCP連接會逐漸減少了,以及,在抓包觀察到的第3點裏,爲什麼會出現Keep-Alive包和RST包以及它們的作用了:
總的來說,因爲應用服務器與數據庫服務器之間的某些TCP連接在建立後的2個小時內(tcp_keepidle值)都沒有數據包交互,並且在AIX數據庫服務器這端,它與應用服務器125的TCP連接都有啓用TCP keepalive特性,所以AIX服務器會嘗試發送Keep-Alive包以確定這些空閒的TCP連接是否仍然可用,由於它最終都沒有收到對端的回包,所以它就發送了RST包來斷開該TCP連接並清除掉本地系統中的該TCP連接的信息。最終就表現爲,在數據庫服務器端觀察到與應用服務器的TCP連接逐漸減少了。
防火牆的會話特性
經過前面一大堆的分析,我們尚不知道爲什麼數據包會在網絡中丟失呢。根據我的理論知識及過往的經驗,我猜想問題應該出在防火牆。雖然我沒有權限看不了防火牆的配置,但我知道防火牆是有"會話"這一概念的。
(這部分我沒有嚴格的查詢官方文檔,但大體應該是沒錯的)在防火牆中,防火牆會通過五元組來標識一個連接會話,即源IP地址、源端口、目的IP地址、目的端口、協議(tcp或udp)。例如,172.16.1.1 36524 TCP 192.168.1.1 1521就構成了一個五元組,其含義是,IP地址爲172.16.1.1的源主機使用源端口36524,使用TCP協議,訪問IP地址爲192.168.1.1的目標主機的1521端口。但是呢,防火牆中是有會話過期時間的。當一個TCP連接長時間沒有數據包交互,防火牆將會將該TCP連接會話清除。會話信息被清除後,當該TCP連接的源端或目標端再發送數據包過來時,防火牆收到後,會直接將該數據包丟棄。除非重新建立TCP連接(經歷TCP 3次握手),否則,屬於該五元組的TCP連接的數據包將不會被放行。
這就解釋了現象2和3中爲什麼數據包會在網絡中丟失。當應用服務器或數據庫服務器發送數據包時,由於此時防火牆中相應的TCP連接會話已經過期,防火牆收到數據包後就直接把包丟棄了,所以對端就無法收到數據包,它們本身也就無法收到回包。
後來查詢得知,那個防火牆的會話超時時間是1小時。我後來經過實驗證實應該是沒錯的。那麼,整個問題就是這樣的:當應用服務器與數據庫服務器建立TCP連接之後,某些TCP連接由於長時間沒有數據包交互,達到防火牆的會話超時時間1小時,故防火牆清除了這些未活動的TCP連接的會話信息;此時,不管是應用服務器還是數據庫服務器通過這些TCP連接來訪問對端都是不通的,這就導致了最開始應用服務器訪問不了數據庫服務器的現象;又由於數據庫服務器端對這些TCP連接啓用了TCP keepalive特性,那麼當時間達到2小時(即防火牆清除會話信息後又過了1小時)後,數據庫服務器開始發送Keep-Alive包檢測這些空閒的TCP連接是否仍然可用,由於這些連接早在1小時之前就已經不通了,在經過多次嘗試後仍然未收到對端的回包,數據庫服務器便清除了這些不可用的TCP連接,這就出現了最開始觀察到的數據庫服務器上TCP連接不斷減少的現象。
簡單來說就是,由於應用與數據庫長時間沒有流量交互,導致防火牆中的會話超時,就導致了應用訪問不了數據庫。
正確地配置proxool.xml
雖然已經找出了問題的根本原因,但這個問題怎麼解決呢?有幾種解決辦法:調整防火牆會話超時時間大於2小時(AIX數據庫服務器的tcp_keepidle值);調整AIX數據庫服務器的tcp_keepidle值小於1小時(防火牆會話超時時間);調整應用程序。當然,各有優缺啦。
其實,在我剛開始發現應用和數據庫服務器的TCP連接不對等時,我告知了開發人員,開發同事就嘗試修改了應用的數據庫連接池配置。結果誤打誤撞,問題就沒有再發生了。當然,他並不清楚爲什麼會這樣。但是,這引出了我這裏要講的一個問題。
應用程序使用的是proxool連接池,在最開始,它的配置文件proxool.xml的內容類似於:
<?xml version="1.0" encoding="UTF-8"?> <something-else-entirely> <proxool> <alias>defaultDatabase</alias> <driver-url>jdbc:oracle:oci8:@exampledb</driver-url> <driver-class>oracle.jdbc.driver.OracleDriver</driver-class> <driver-properties> <property name="user" value="example_user" /> <property name="password" value="example_password" /> </driver-properties> <prototype-count>3</prototype-count> <maximum-connection-count>50</maximum-connection-count> <minimum-connection-count>4</minimum-connection-count> </proxool> </something-else-entirely> |
然後呢,開發人員加了下面兩條語句(紅色字體的):
<?xml version="1.0" encoding="UTF-8"?> <something-else-entirely> <proxool> . . . . . . <test-before-use>true</test-before-use> <house-keeping-test-sql>SELECT 'x' from dual</house-keeping-test-sql> </proxool> </something-else-entirely> |
這兩條語句呢,其實真正解決了問題的是house-keeping-test-sql這條語句,test-before-use語句則是沒有必要的。加上test-before-use語句除了會增加查詢數據庫所消耗的時間之外,一般來說,真的不會起什麼有效的作用。
網絡上很多文章經常犯的一個錯誤就是,使用了house-keeping-test-sql語句就會同時使用test-before-use語句,認爲前者需要跟後者一同使用才能生效,直觀上也很容易搞錯。實際上,house-keeping-test-sql語句可以單獨使用。使用了test-before-use語句就一定要使用house-keeping-test-sql語句,但反過來就不對了。結合proxool官網中的文檔,這兩條語句的實際作用爲:
house-keeping-test-sql語句:當設置該項時,house keeping thread會找出數據庫連接池中空閒的TCP連接並逐一地通過這些連接來執行該項指定的SQL語句,根據執行成功與否來確定該連接是否仍然可用。該操作每隔一段時間就會重新進行一次,週期爲house keeping thread的睡眠時間間隔(house-keeping-sleep-time屬性的值,默認爲30秒)。爲了減少開銷,該SQL語句應該是執行起來非常快速的。當未設置該項時,該檢測操作會被省略。
house keeping thread的檢測操作本身可以判定TCP連接是否仍然可用。但更重要的是,如果應用與數據庫之間有防火牆,定時的檢測可以產生定時的數據包交互,刷新防火牆中該連接的會話的定時器,保證該會話不會超時而被清除。爲了起到該作用,house-keeping-sleep-time的值需要小於防火牆會話超時時間(我這裏是1小時),但爲了避免產生過多網絡流量,也爲了避免對數據庫產生不必要的壓力,也不建議設置爲太小。可以設置爲10分鐘或20分鐘檢測一次之類的。
另外還需特別說明,這種定時檢測操作是屬於應用層面的實現,跟之前所說的TCP keepalive特性沒有任何關係。
test-before-use語句:當設置該項爲true時,應用在使用數據庫連接池中的某一個連接之前,會先使用house-keeping-test-sql語句中定義的SQL語句來檢測該連接的可用性。如果檢測失敗了,就會選擇另外一個連接。如果所有連接都檢測失敗了,就會創建一個新的連接。如果那個新連接也檢測失敗了,就會返回SQLException信息。
可以看到,該語句是依賴於house-keeping-test-sql語句的,反過來則不對。即便test-before-use語句的值被設爲false(默認值),house-keeping-test-sql語句也仍然生效,house keeping thread仍然會定期執行house-keeping-test-sql語句中定義的SQL語句(如果有設置的話)。使用test-before-use語句雖可以最大限度保證連接可用性,但會產生額外的延遲(至少是應用服務器到數據庫服務器的網絡round trip time),而且,程序需要多久才能判定一個連接是不可用的,這也是一個很重要的問題的。因此,我個人是不推薦使用該語句的。
總的來說,我建議在設置proxool連接池至少加上下面兩條語句(紅色字體的):
<?xml version="1.0" encoding="UTF-8"?> <something-else-entirely> <proxool> <alias>defaultDatabase</alias> <driver-url>jdbc:oracle:oci8:@exampledb</driver-url> <driver-class>oracle.jdbc.driver.OracleDriver</driver-class> <driver-properties> <property name="user" value="example_user" /> <property name="password" value="example_password" /> </driver-properties> <prototype-count>3</prototype-count> <maximum-connection-count>50</maximum-connection-count> <minimum-connection-count>4</minimum-connection-count> <house-keeping-test-sql>SELECT 'x' from dual</house-keeping-test-sql> <house-keeping-sleep-time>600000</house-keeping-sleep-time> </proxool> </something-else-entirely> |
house-keeping-test-sql語句可以讓house keeping thread定期地使用SQL語句檢測連接池中空閒的TCP連接,house-keeping-sleep-time語句則設置這個時間間隔(單位爲毫秒),不設置時默認爲30秒,建議不要設得太大或太小,但要小於硬件防火牆的會話超時時間。
問題總結
到這裏爲止,問題已經很清楚了。這種問題的發生其實並不侷限於訪問Oracle數據庫的情況,只要是長連接,當滿足以下所有條件時,這種問題就會發生:
1、 兩臺服務器之間存在有硬件防火牆。
2、 使用了TCP長連接,比如在使用TCP連接池的場景中。
3、 在TCP連接的兩端均未啓用TCP keeplive特性,或任意一端或兩端啓用了TCP keeplive特性,但空閒檢測時間(如Linux的net.ipv4.tcp_keepalive_time參數,AIX的tcp_keepidle參數)大於硬件防火牆的會話超時時間。是否有啓用TCP keeplive特性通常由上層應用程序決定,但可以通過命令來觀察。
4、 不存在應用層的定時輪詢,或存在應用層的定時輪詢,但輪詢間隔大於硬件防火牆的會話超時時間。是否存在應用層的定時輪詢通常要根據具體的應用程序及配置(如數據庫連接池的配置)而定。
5、 在硬件防火牆的會話超時時間內,長連接中沒有數據包傳輸。通常,如果應用本身沒什麼訪問量,或者是在凌晨等時段訪問量比較低,又或者是長連接數量太多,都有可能使某些長連接一直空閒,長時間沒有數據包傳輸。
其它問題
1、 有時,我們會想,客戶端的數據庫連接池中有很多與數據庫服務器端的連接,假設其中仍然有一部分連接是仍然可以訪問到數據庫的,那麼這時候應用訪問數據庫會不會有問題呢?
仍然是可能有問題的。根據我的觀察,當應用訪問數據庫時,應用可能是從連接池中隨機選取一個連接的(具體的選取規則我不是很確定),但重點是,在沒有做檢測的情況下,應用並不知道連接池中的哪些連接是實際可用的。如果應用選取到的是一個實際不可用的連接,那麼這時,由於數據包發送出去了但沒有回包,(至少在Linux上)操作系統會一直嘗試重傳並超過最大重試次數(正如前面所說),這個過程至少也要10分鐘以上,而應用層通常早就超時報錯了。當確定了連接不可用之後,應用會再從連接池中選取一個連接。若這個連接仍然不可用,應用纔會嘗試創建一個新連接。整個過程下來,可能要20多分鐘,而應用層通常都不會等待這麼久的時間。
當然,如果應用最開始從連接池中選取到的那個連接恰好仍然可用,此時應用訪問數據庫是沒有問題的。因此,總的來說,這種情況就是看概率啦。不過,通常,出問題的概率比較大。
2、 本文講的是與Oracle數據庫之間的問題,如果換成MySQL數據庫,會是什麼情況呢?
MySQL數據庫有一點不同,據我觀察,應用通過MySQL驅動與MySQL數據庫建立長連接時,應用這一端是啓用了TCP keepalive特性的。可能並不是所有MySQL驅動都是這樣的,但假設是這樣的話,那麼,問題的發生會變得更加隱晦。其實原理都是一樣的,套用原理分析一下就行,我就不囉嗦了。