




相似的判斷
下面兩個句子相同嗎?怎麼判斷?思路呢?
句子A:這隻皮靴號碼大了。那隻號碼合適
句子B:這隻皮靴號碼不小,那隻更合適
1)分詞
句子A:這隻/皮靴/號碼/大了。那隻/號碼/合適。
句子B:這隻/皮靴/號碼/不/小,那隻/更/合適。
列出所有的詞:這隻,皮靴,號碼,大了。那隻,合適,不,小,很
2)計算詞頻(詞出現的次數)
句子A:這隻1,皮靴1,號碼2,大了1。那隻1,合適1,不0,小0,更0
句子B:這隻1,皮靴1,號碼1,大了0。那隻1,合適1,不1,小1,更1
3)寫出詞頻向量。
句子A:(1,1,2,1,1,1,0,0,0),即:x 座標數據
句子B:(1,1,1,0,1,1,1,1,1),即:y 座標數據
4)餘弦公式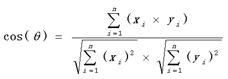
,∑表示求和符號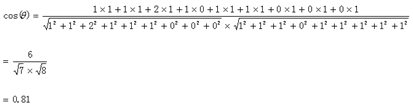
0.81非常接近於1,所以上面的句子A和句子B是基本相似的
雖然上面的例子並無法用於正式場合,但是基本說明了“數學不難”,高中知識就足夠
對數函數的魅力
有一個這樣的場景:某兩個字的頻率分別都是500,另外兩個字的頻率分別爲200和800,如果單純比較頻率和都是相等的,但是取對數後,log500=2.69897, log200=2.30103, log800=2.90308 這時候前者爲2xlog500=5.39794, 後者爲log200+log800=5.20411,這時前者的和更大,取前者。
我們再看另外一個場景:產品A賣500元打完折後賣200元 和 產品B賣800元折後價格500元,同樣是相差300元,但是消費者對哪組數據更加敏感呢? log500-log200>log800-log500
也就是說,數值小的“差異”敏感程度比數值大“差異”敏感程度更高。這也是符合生活常識的,例如對於價格,買個家電,如果價格相差幾百元能夠很大程度影響你決策,但是你買汽車時相差幾百元你會忽略不計了
求導的意義
簡單的介紹:一階導數-求某一時間點的瞬時速度。二階導數-求某一時間點的瞬時加速度。
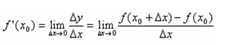
函數求導主要是研究函數值隨自變量的值的變化而變化的趨勢,如果導數小於零,那麼事物發展的趨勢是越來越慢或者是越來越小,相反如果導數大於零,那麼事物發展的趨勢是越來越快或者是越來越大。
特徵值和特徵向量什麼意思
舉例說:去讓你給我接個人,她有很多特徵,我會挑幾個特典型如長髮超級大美女、身材高挑皮膚好...其中特徵值就是多高,多美,特徵向量就是這些分類。
矩陣中的特徵值和特徵向量呢,再舉例:小紅姑娘是個矩陣,在這個矩陣中臉部輪廓是特徵向量,相貌就是特徵值,等比例伸縮就是“眼睛多大,鼻子多高”,最後通過特徵值大小=你能知道這個人到底有多美,體型身材是特徵向量,三圍就是特徵值,等比例伸縮就是“胸部多大,臀部多高”,最後通過特徵值大小=你能知道這個人到身材多好。
給一任意矩陣,該矩陣到底是誰,不容易知道,例如哪一個矩陣代表的是小紅姑娘?但是當你把矩陣附加到某一具體事物(相貌)上觀察,例如反覆運用矩陣相乘(相乘就是多個相同數量的相加,加就是放大,其他事物也放大,但是程度不如特徵向量),矩陣所代表的人的最明顯的特徵,如相貌最大的方向(特徵值是特徵向量的等比伸縮),就由最大特徵值對應的特徵向量展現出來(即運算越來越貼合到最大的特徵值對應的特徵空間,注意也不是無限運算,因爲某次結果後又將遠離特徵空間,即圍繞特徵空間旋轉)
以上內容來自網易雲課堂海暢智慧出品的《機器學習算法》,轉載請註明。