




WorkerMan介紹
官方項目地址:https://www.workerman.net/features
workerman是一個高性能的PHP socket 服務器框架,workerman基於PHP多進程以及libevent事件輪詢庫,
PHP開發者只要實現一兩個接口,便可以開發出自己的網絡應用,例如Rpc服務、聊天室服務器、手機遊戲服務器等。
workerman的目標是讓PHP開發者更容易的開發出基於socket的高性能的應用服務,
而不用去了解PHP socket以及PHP多進程細節。
workerman本身是一個PHP多進程服務器框架,具有PHP進程管理以及socket通信的模塊,
所以不依賴php-fpm、nginx或者apache等這些容器便可以獨立運行。業務場景
終端機通過互聯網走TCP協議通過NGinx反向代理服務器與線上PHP服務器中的WorkerMan進程通訊,屬於長連接,對實時性要求較高。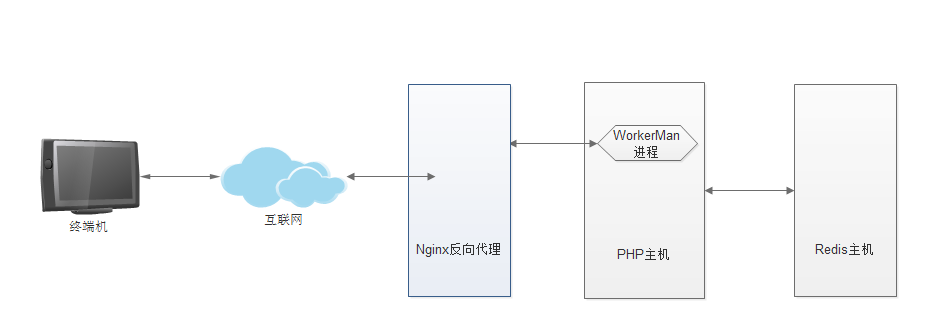
系統與應用環境
# uname -r
3.10.0-693.11.1.el7.x86_64
# cat /etc/centos-release
CentOS Linux release 7.4
Workerman version:3.5.5
PHP version:5.6.36
# php -m
[PHP Modules]
event
phpiredis
這裏只列出了高併發相關的已經加載的模塊現象
終端機通過掃碼形式進行打開,發現在掃碼後會有大約5-10秒的延時纔開始下一流程工作。體驗變得很糟糕。
排查過程
因爲終端機是與Workerman通訊的,因此,直接查看此應用的情況
Workerman 實時連接情況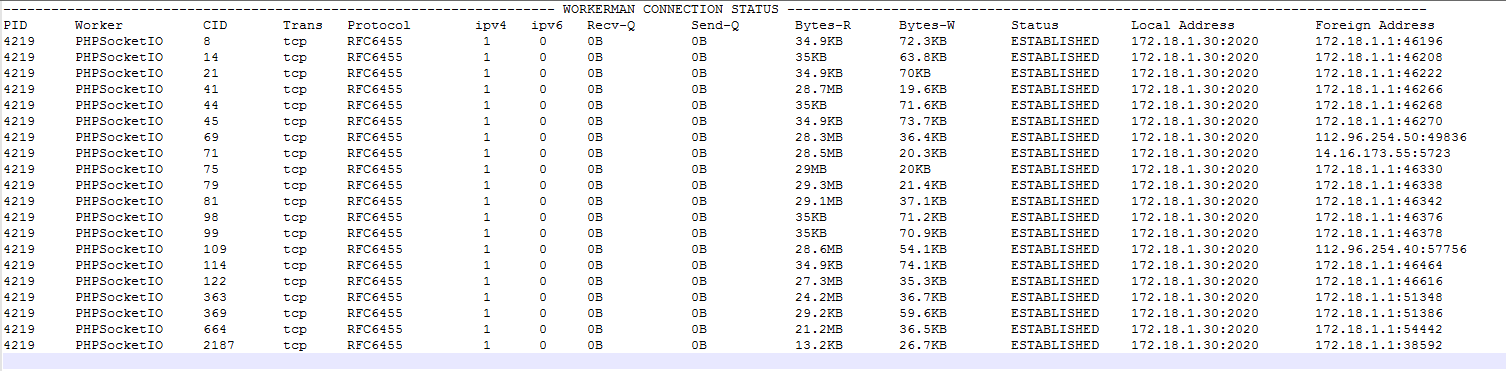
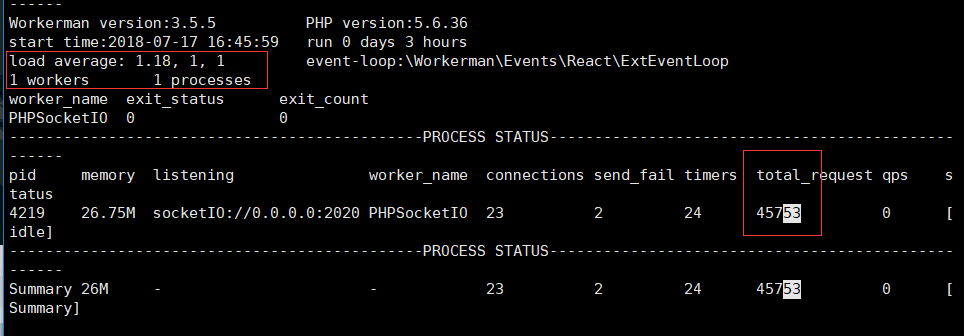
通過htop指令,發現Workerman佔用的CPU核心(CPU 1)還是特別高的。
按理說,剛增加的CPU核數,應該可以改善CPU高的問題啊。不過呢,仔細觀察,本機的業務分爲傳統PHP類和Workerman,按照官方的手冊講到的,Workerman並不跟php-fpm有太多的影響。實際中確實也反映出來了,跟Workerman連接的終端會延時,同一時刻,相關的PHP訪問卻不受影響,除非整個服務器的CPU都超高。
開始把問題瞄向了磁盤IO和網絡IO瓶頸上面,不過當我調出相關的性能監控的時候,發現並不是這個原因。雖然說有寫日誌的行爲,在SSD磁盤的上面還是沒有壓力的。
隨即尋求Workman官方技術羣主幫助,通過狀態頁和相關監控系統指令,產生了疑問:
業務有啥耗費cpu的操作麼?請求量不大怎麼cpu這麼高?
通過mpstat查看每個核的CPU狀況,發現運行Workerman的CPU核心確實存在CPU高的現象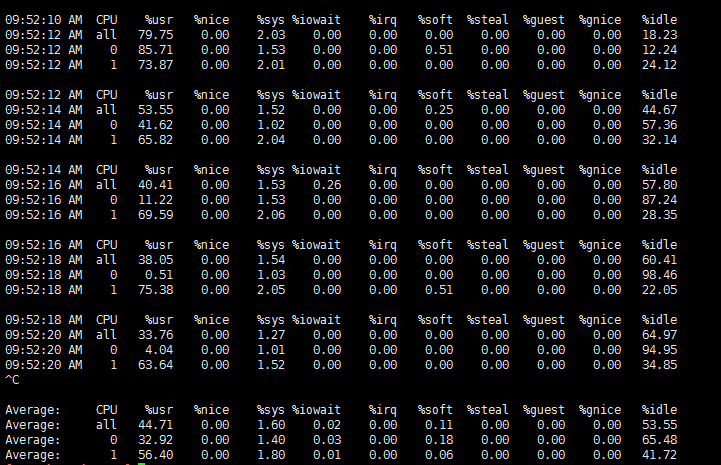
於是,立即使用strace命令跟蹤下情況
strace命令是一個集診斷、調試、統計與一體的工具,我們可以使用strace對應用的系統調用和信號傳遞的跟蹤結果來對應用進行分析,以達到解決問題或者是瞭解應用工作過程的目的。
strace -ttp 進程號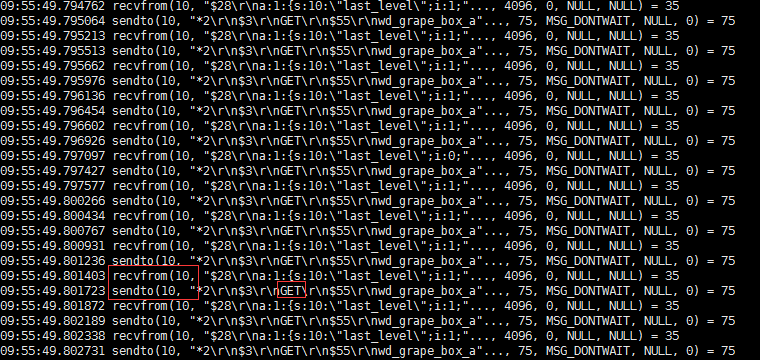
其中每一行是一個系統調用,從這個信息中我們很容易看到進程在做一些什麼事情,可以定位到進程卡在哪裏,卡在連接還是讀取網絡數據等
在與終端機發送消息是一去一回,有一個FD=10的操作相當的頻繁,刷新的非常快。
使用lsof跟蹤此進程
# lsof -p 24373 | grep 10
可以看出,這個就是本機向redis主機通訊(沒有采用默認的6379端口號)
會不會是redis的瓶頸引發的?
再次確認了所連接的Redis配置如下
內網每秒發包數不到2000 pps,遠遠沒達到極限的5萬pps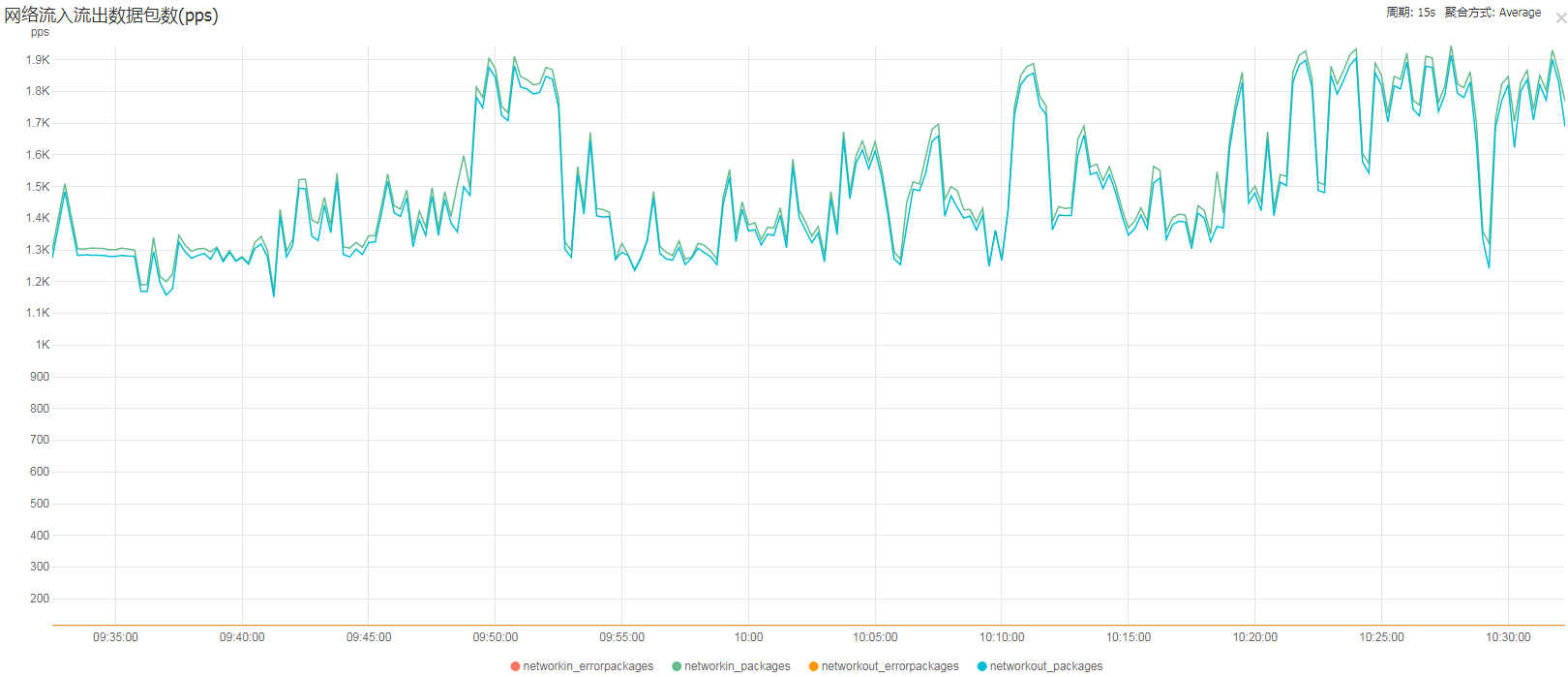
事實證明,並不是因爲Redis服務的瓶頸。
定位問題
與開發人員進行溝通,得知這是終端設備查詢的操作。而且訪問的數據都相同,這樣瘋狂訪問redis,導致了cpu利用率過高,就容易延遲了。
至此,基本定位出問題了,剩下的就交給開發進行優化了。
解決方案
1.減少查詢返回的量
2.將每次一種狀態生成的redis操作的頻繁指令合併到多個指令數據集合操作一條redis操作。
3.將遍歷方法變成校對產生變化的值,從而減少量級。
取值時間 9:00-21:00
WorkerMan主機平均負載
優化前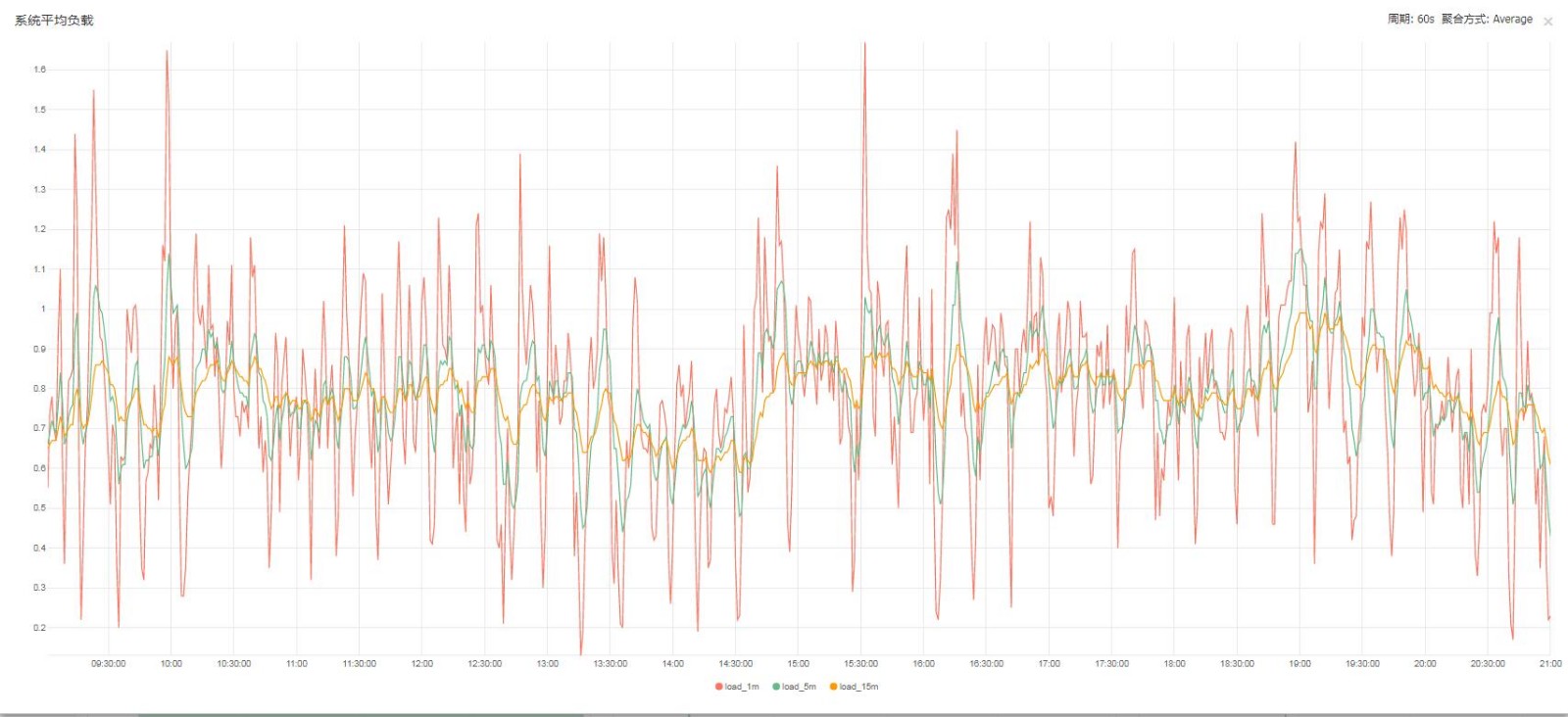
優化後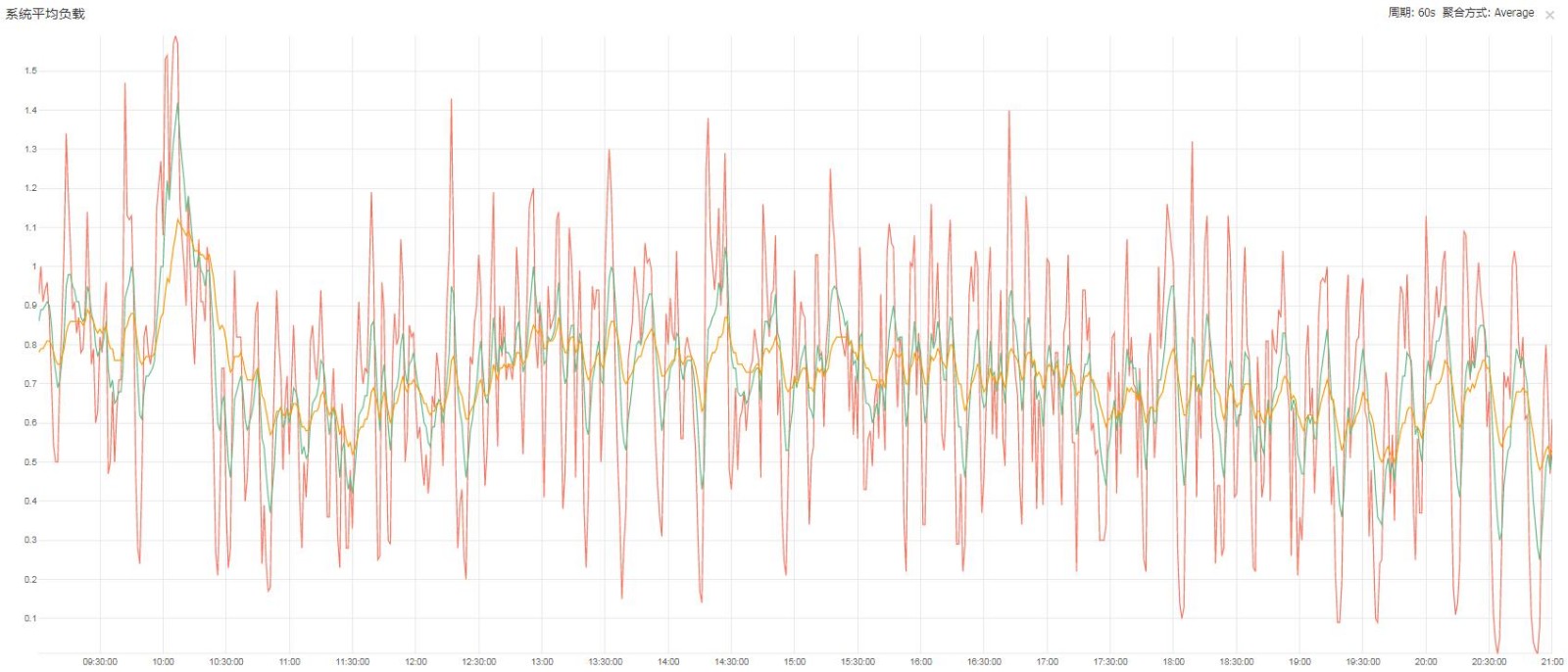
WorkerMan進程CPU使用率
優化前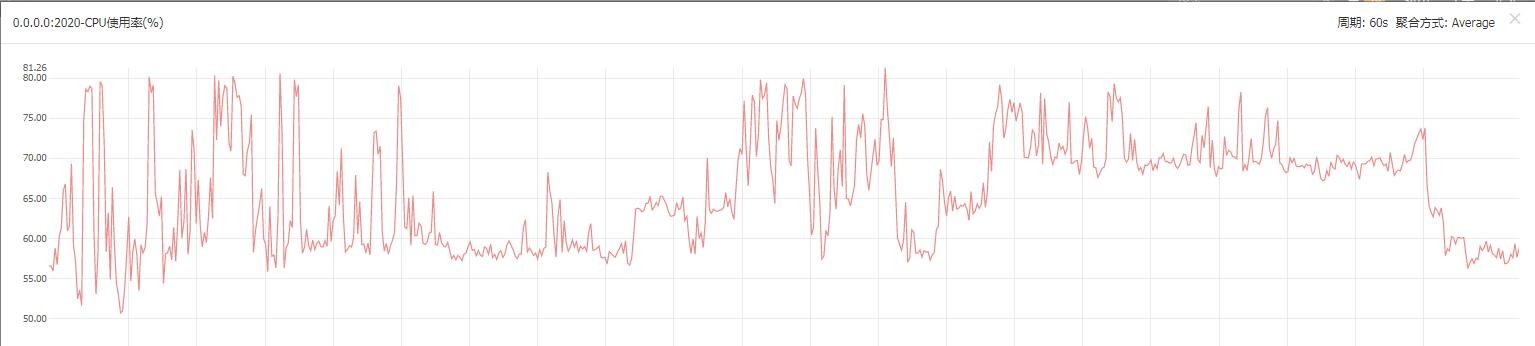
優化後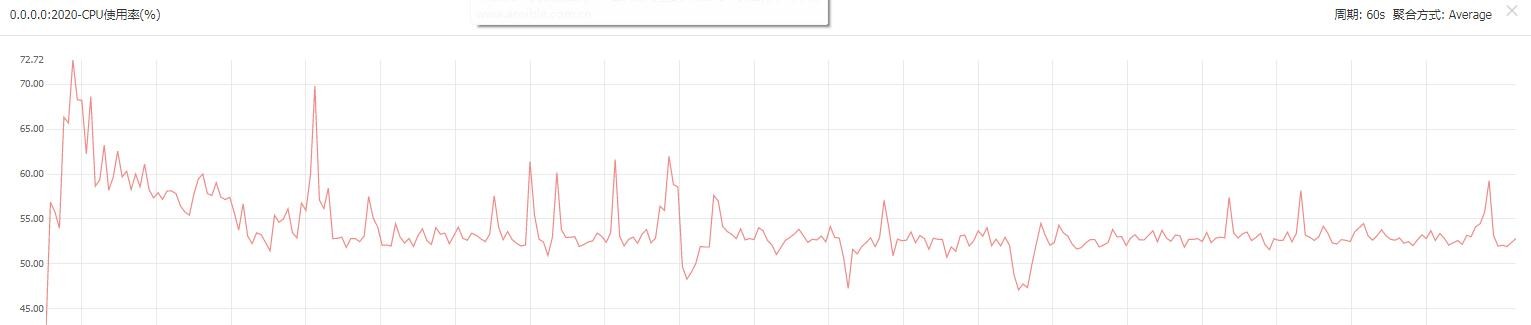
redis主機網絡流入流出數據包數(pps)
優化前
優化後 ,因爲是通過2次優化處理,所以這張圖能很明顯的看出對比變化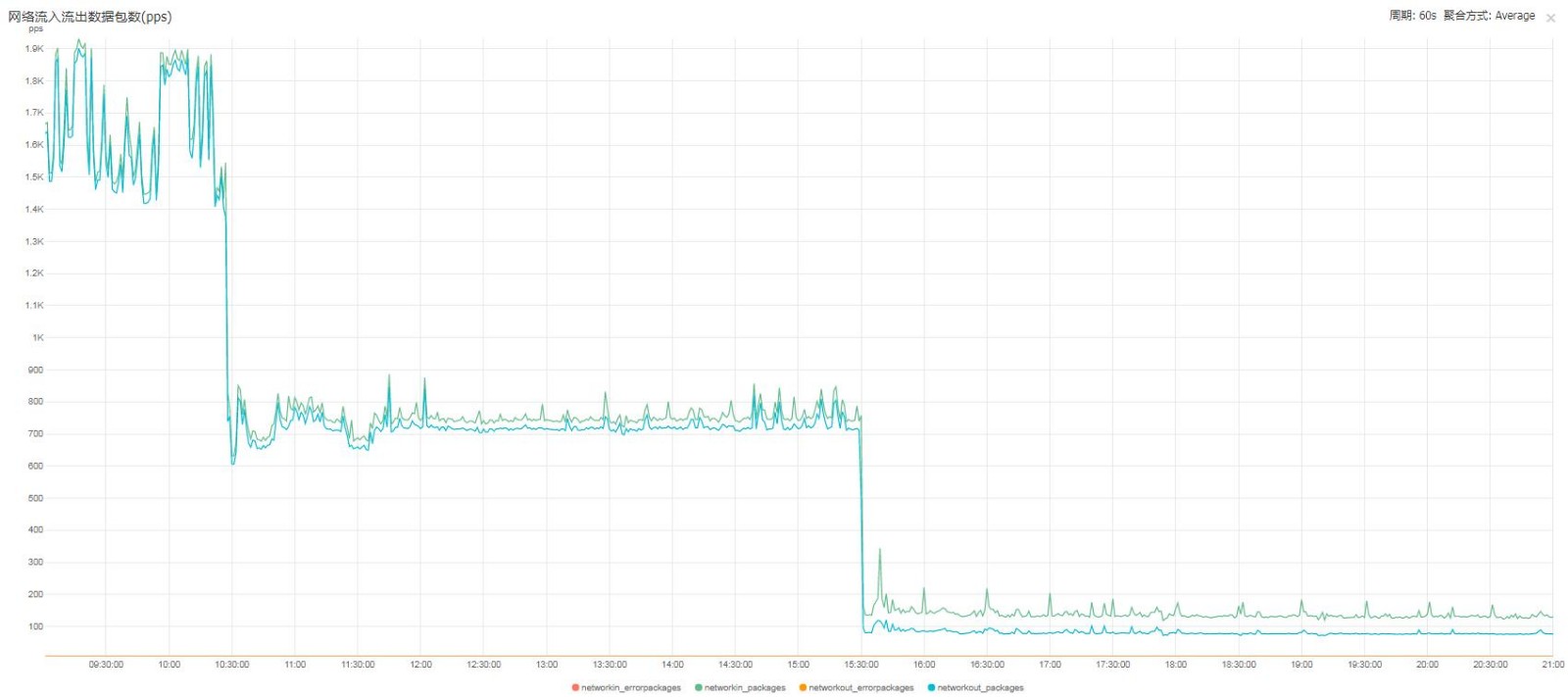
目前線上業務延時已經恢復正常,優化還在進行中,重點將會是WorkerMan進程的CPU優化,不知各位看官有什麼多進程處理的好方案呢?