Prometheus作爲專業的監控體系,有自己專門的報警插件Alertmanager;Alertmanager是一個獨立的告警模塊,接收Prometheus等客戶端發來的警報,之後通過分組、刪除重複等處理,並將它們通過路由發送給正確的接收器;告警方式可以按照不同的規則發送給不同的模塊負責人,Alertmanager支持Email, Slack,等告警方式, 也可以通過webhook接入釘釘等國內IM工具。
先上一張基本基本的示意圖: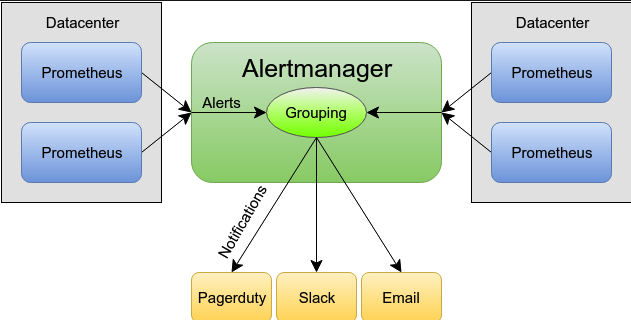
由於換了新的工作環境,報警方面公司有統一報警平臺,這裏自己寫了一個webhook來進行對接,把alertmanager收到的警報流發送到報警平臺,之後其他人可以在報警平臺進行警報訂閱。實踐過程中對Alertmanager配置有了更深的理解。這裏總結分享一下。
首先警報的激活是由Prometheus Server的Alert Rule引起的,Alert Rule可以設置閥值,當達到rule設置的閥值時發送警報給Alertmanager。所以警報具體的發送時間跟Prometheus和Alertmanager的配置密切相關。這裏有幾個關鍵的配置。
Prometheus相關:
1. scrape_interval: How frequently to scrape targets default=1m。Server端抓取數據的時間間隔
2. scrape_timeout: How long until a scrape request times out. default = 10s 數據抓取的超時時間
3. evaluation_interval: How frequently to evaluate rules. default = 1m 評估報警規則的時間間隔Alertmanger相關:
1. group_wait: How long to initially wait to send a notification for a group of alerts. Allows to wait for an inhibiting alert to arrive or collect more initial alerts for the same group. (Usually ~0s to few minutes. default = 30s)發送一組新的警報的初始等待時間,也就是初次發警報的延時
2. group_interval:How long to wait before sending a notification about new alerts that are added to a group of alerts for which an initial notification has already been sent. (Usually ~5m or more. default = 5m)初始警報組如果已經發送,需要等待多長時間再發送同組新產生的其他報警
3. repeat_interval: How long to wait before sending a notification again if it has already been sent successfully for an alert (Usually ~3h or more. default = 4h ) 如果警報已經成功發送,間隔多長時間再重複發送另外說下Alert的三種狀態:
1. pending:警報被激活,但是低於配置的持續時間。這裏的持續時間即rule裏的FOR字段設置的時間。改狀態下不發送報警。
2. firing:警報已被激活,而且超出設置的持續時間。該狀態下發送報警。
3. inactive:既不是pending也不是firing的時候狀態變爲inactive需要注意一點:只有在評估週期期間,警報纔會從當前狀態轉移到另一個狀態。
介紹完上面幾個概念,下面詳細講解下prometheus的報警流程。
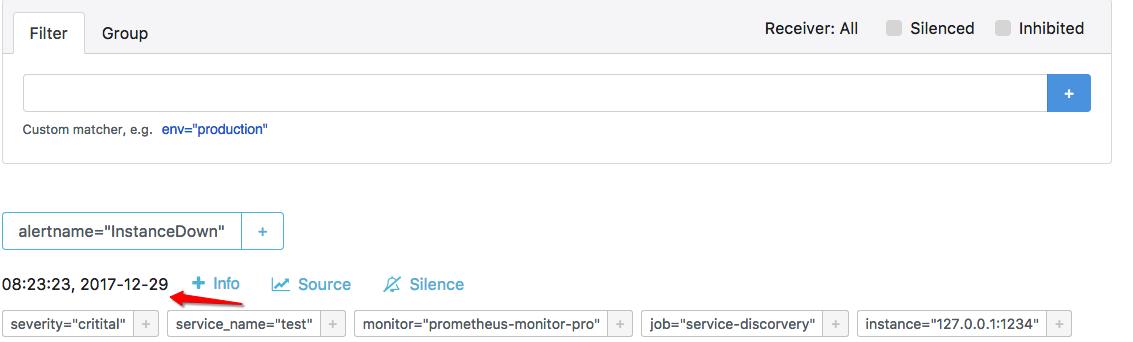
我這裏先定義一個名爲"InstanceDown"的報警規則(Alert Rule):
alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critital
annotations:
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for
more than 1 minutes.'
summary: Instance {{ $labels.instance }} down該規則會檢測後端實例的存活狀態,當後端實例接口down的時候,“UP”的值會變爲0;並設置FOR的持續時間爲1min。
現在添加一個不存在的接口A:<“http://127.0.0.1:1234”>,作爲測試。
那麼報警處理流程如下:
- Prometheus Server監控目標主機上暴露的http接口(這裏假設接口A),通過上述Promethes配置的'scrape_interval'定義的時間間隔,定期採集目標主機上監控數據。
- 當接口A不可用的時候,Server端會持續的嘗試從接口中取數據,直到"scrape_timeout"時間後停止嘗試。這時候把接口的狀態變爲“DOWN”。
![Prometheus智能化報警流程避免郵件轟炸]()
- Prometheus同時根據配置的"evaluation_interval"的時間間隔,定期(默認1min)的對Alert Rule進行評估;當到達評估週期的時候,發現接口A爲DOWN,即UP=0爲真,激活Alert,進入“PENDING”狀態,並記錄當前active的時間;
![Prometheus智能化報警流程避免郵件轟炸]()
- 當下一個alert rule的評估週期到來的時候,發現UP=0繼續爲真,然後判斷警報Active的時間是否已經超出rule裏的‘for’ 持續時間,如果未超出,則進入下一個評估週期;如果時間超出,則alert的狀態變爲“FIRING”;同時調用Alertmanager接口,發送相關報警數據。
![Prometheus智能化報警流程避免郵件轟炸]()
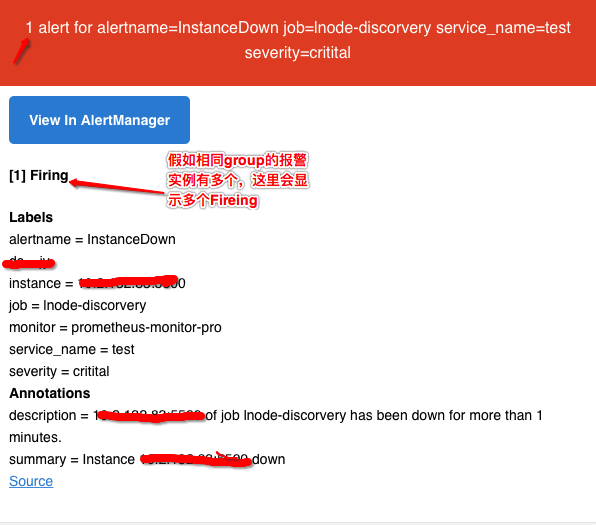
- AlertManager收到報警數據後,會將警報信息進行分組,然後根據alertmanager配置的“group_wait”時間先進行等待。等wait時間過後再發送報警信息。注意對比這裏的上下兩張圖,上圖Prometheus Active的時間是“08:22:23”,下圖Alertmanager收到警報信息的時間是"08:23:23",正好是一個'evaluation_interval’評估週期。
![Prometheus智能化報警流程避免郵件轟炸]()
- 屬於同一個Alert Group的警報,在等待的過程中可能進入新的alert,如果之前的報警已經成功發出,那麼間隔“group_interval”的時間間隔後再重新發送報警信息。比如配置的是郵件報警,那麼同屬一個group的報警信息會彙總在一個郵件裏進行發送。
![Prometheus智能化報警流程避免郵件轟炸]()
- 如果Alert Group裏的警報一直沒發生變化並且已經成功發送,等待‘repeat_interval’時間間隔之後再重複發送相同的報警郵件;如果之前的警報沒有成功發送,則相當於觸發第6條條件,則需要等待group_interval時間間隔後重復發送。
-
同時最後至於警報信息具體發給誰,滿足什麼樣的條件下指定警報接收人,設置不同報警發送頻率,這裏有alertmanager的route路由規則進行配置。同時也可以使用自定義的webhook。這裏暫時先不做具體詳解。
![Prometheus智能化報警流程避免郵件轟炸]()
理解了以上的報警處理流程,我們可以把報警信息進行分組彙總,同組的報警只發送一封報警郵件。可以根據route規則,不同警報的報警級別進行自定義的頻率發送設置,指定接收人等,避免了現在的郵件轟炸報警模式。
當然在沒有理解這種報警處理流程之前,也踩了不少坑,這裏也一起分享一下。 - Alert Rule "FOR"字段設置:如果有配置‘FOR‘’字段的話,alert狀態會先變爲peding,那麼報警信息從server發出的最短時間間隔是一個evaluation_interval評估週期。假如不配置for或for設爲0,則alert被激活後會立即變爲firing狀態,同時發送相關報警信息給alertmanager。
- group_wait的時間設置:如果設置時間過長,會導致報警發出有延遲;配置時間過短,同時會導致大量的郵件轟炸。這裏建議根據不同警報重要性進行配置。