




摘要: 專欄介紹:Paddle Fluid 是用來讓用戶像 PyTorch 和 Tensorflow Eager Execution 一樣執行程序。在這些系統中,不再有模型這個概念,應用也不再包含一個用於描述 Operator 圖或者一系列層的符號描述,而是像通用程序那樣描述訓練或者預測的過程。
專欄介紹:Paddle Fluid 是用來讓用戶像 PyTorch 和 Tensorflow Eager Execution 一樣執行程序。在這些系統中,不再有模型這個概念,應用也不再包含一個用於描述 Operator 圖或者一系列層的符號描述,而是像通用程序那樣描述訓練或者預測的過程。
本專欄將推出一系列技術文章,從框架的概念、使用上對比分析 TensorFlow 和 Paddle Fluid,爲對 PaddlePaddle 感興趣的同學提供一些指導。
在圖像領域,最流行的 building block 大多以卷積網絡爲主。上一篇我們介紹瞭如何在 PaddleFluid 和 TensorFlow 上訓練圖像分類任務。卷積網絡本質上依然是一個前饋網絡,在神經網絡基本單元中循環神經網絡是建模序列問題最有力的工具, 有着非常重要的價值。自然語言天生是一個序列,在自然語言處理領域(Nature Language Processing,NLP)中,許多經典模型都基於循環神經網絡單元。可以說自然語言處理領域是 RNN 的天下。
這一篇以 NLP 領域的 RNN 語言模型(RNN Language Model,RNN LM)爲實驗任務,對比如何使用 PaddleFluid 和 TensorFlow 兩個平臺實現序列模型。 這一篇中我們會看到 PaddleFluid 和 TensorFlow 在處理序列輸入時有着較大的差異:PaddleFluid 默認支持非填充的 RNN 單元,在如何組織 mini-batch 數據提供序列輸入上也簡化很多。
如何使用代碼
本篇文章配套有完整可運行的代碼, 請從隨時從 github [1] 上獲取最新代碼。代碼包括以下幾個文件:
image
注意:在運行模型訓練之前,請首先進入 data 文件夾,在終端運行 sh download.sh 下載訓練數據。
在終端運行以下命令便可以使用默認結構和默認參數運行 PaddleFluid 訓練 RNN LM。
python rnnlm_fluid.py
在終端運行以下命令便可以使用默認結構和默認參數運行 TensorFlow 訓練 RNN LM。
python rnnlm_tensorflow.py
背景介紹
one-hot和詞向量表示法
計算機如何表示語言是處理 NLP 任務的首要問題。這裏介紹將會使用到的 one-hot 和詞向量表示法。
one-hot 表示方法:一個編碼單元表示一個個體,也就是一個詞。於是,一個詞被表示成一個長度爲字典大小的實數向量,每個維度對應字典裏的一個詞,除了該詞對應維度上的值是 1,其餘維度都是 0。
詞向量表示法:與 one-hot 表示相對的是 distributed representation ,也就是常說的詞向量:用一個更低維度的實向量表示詞語,向量的每個維度在實數域 RR 取值。
在自然語言處理任務中,一套好的詞向量能夠提供豐富的領域知識,可以通過預訓練獲取,或者與最終任務端到端學習而來。
循環神經網絡
循環神經網絡(Recurrent Neural Network)是一種對序列數據建模的重要單元,模擬了離散時間(這裏我們只考慮離散時間)動態系統的狀態演化。“循環” 兩字刻畫了模型的核心:上一時刻的輸出作爲下一個時刻的輸入,始終留在系統中如下面的圖 1 所示,這種循環反饋能夠形成複雜的歷史。自然語言是一個天生的序列輸入,RNN 恰好有能力去刻畫詞彙與詞彙之間的前後關聯關係,因此,在自然語言處理任務中佔有重要的地位。
image
▲ 圖1. 最簡單的RNN單元
RNN 形成“循環反饋” 的過程是一個函數不斷複合的過程,可以等價爲一個層數等於輸入序列長度的前饋神經網絡,如果輸入序列有 100 個時間步,相當於一個 100 層的前饋網絡,梯度消失和梯度爆炸的問題對 RNN 尤爲嚴峻。
直覺上大於 1 的數連乘越乘越大,極端時會引起梯度爆炸;小於 1 的數連乘越乘越小,極端時會引起梯度消失。梯度消失也會令在循環神經網絡中,後面時間步的信息總是會”壓過”前面時間步。如果 t 時刻隱層狀態依賴於 t 之前所有時刻,梯度需要通過所有的中間隱層逐時間步回傳,這會形成如圖 2 所示的一個很深的求導鏈。
image
▲ 圖2. t時刻依賴t時刻之前所有時刻
在許多實際問題中時間步之間相互依賴的鏈條並沒有那麼長,t 時刻也許僅僅依賴於它之前有限的若干時刻。很自然會聯想到:如果模型能夠自適應地學習出一些如圖 3 所示的信息傳播捷徑來縮短梯度的傳播路徑,是不是可以一定程度減梯度消失和梯度爆炸呢?答案是肯定的,這也就是 LSTM 和 GRU 這類帶有 “門控”思想的神經網絡單元。
image
▲ 圖3. 自適應地形成一些信息傳播的“捷徑”
關於 LSTM 更詳細的介紹請參考文獻 [2],這裏不再贅述,只需瞭解 LSTM/GUR 這些門控循環神經網絡單元提出的動機即可。
RNN LM
語言模型是 NLP 領域的基礎任務之一。語言模型是計算一個序列的概率,判斷一個序列是否屬於一個語言的模型,描述了這樣一個條件概率,其中是輸入序列中的 T 個詞語,用 one-hot 表示法表示。
言模型顧名思義是建模一種語言的模型,這一過程如圖 4 所示:
image
▲ 圖4. RNN語言模型
RNN LM的工作流程如下:
給定一段 one-hot 表示的輸入序列 {x1,x2,...,xT},將它們嵌入到實向量空間,得到詞向量表示 :{ω1,ω2,...,ωt}。
以詞向量序列爲輸入,使用 RNN 模型(可以選擇LSTM或者GRU),計算輸入序列到 t 時刻的編碼 ht。
softmax 層以 ht 爲輸入,預測下一個最可能的詞的概率。
,根據和計算誤差信號。
PTB數據集介紹
至此,介紹完 RNN LM 模型的原理和基本結構,下面準備開始分別使用 PaddleFluid 和 TensorFlow 來構建我們的 訓練任務。這裏首先介紹這一篇我們使用 Mikolov 與處理過的 PTB 數據,這是語言模型任務中使用最爲廣泛的公開數據之一。 PTB 數據集包含 10000 個不同的詞語(包含句子結束符 ,以及表示 低頻詞的特殊符號 )。
通過運行 data 目錄下的 download.sh 下載數據,我們將使用其中的 ptb.train.txt 文件進行訓練,文件中一行是一句話,文本中的低頻詞已經全部被替換爲 預處理時我們會在 每一行的末尾附加上句子結束符 。
程序結構
這一節我們首先整體總結一下使用 PaddleFluid 平臺和 TensorFlow 運行自己的神經網絡模型都有哪些事情需要完成。
PaddleFluid
調用 PaddleFluid API 描述神經網絡模型。PaddleFluid 中一個神經網絡訓練任務被稱之爲一段 Fluid Program 。
定義 Fluid Program 執行設備: place 。常見的有 fluid.CUDAPlace(0) 和 fluid.CPUPlace()
place = fluid.CUDAPlace(0) if conf.use_gpu else fluid.CPUPlace()
注:PaddleFluid 支持混合設備運行,一些運算(operator)沒有特定設備實現,或者爲了提高全局資源利用率,可以爲他們指定不同的計算設備。
創建 PaddleFluid 執行器(Executor),需要爲執行器指定運行設備。
exe = fluid.Executor(place)
讓執行器執行 fluid.default_startup_program() ,初始化神經網絡中的可學習參數,完成必要的初始化工作。
定義 DataFeeder,編寫 data reader,只需要關注如何返回一條訓練/測試數據。
進入訓練的雙層循環(外層在 epoch 上循環,內層在 mini-batch 上循環),直到訓練結束。
TensorFlow
調用 TensorFlow API 描述神經網絡模型。 TensorFlow 中一個神經網絡模型是一個 Computation Graph。
創建TensorFlow Session用來執行計算圖。
sess = tf.Session()
調用 sess.run(tf.global_variables_initializer()) 初始化神經網絡中的可學習參數。
編寫返回每個 mini-batch 數據的數據讀取腳本。
進入訓練的雙層循環(外層在 epoch 上循環,內層在 mini-batch 上循環),直到訓練結束。
如果不顯示地指定使用何種設備進行訓練,TensorFlow 會對機器硬件進行檢測(是否有 GPU), 選擇能夠儘可能利用機器硬件資源的方式運行。
從以上的總結中可以看到,PaddleFluid 程序和 TensorFlow 程序的整體結構非常相似,使用經驗可以非常容易的遷移。
構建網絡結構及運行訓練
加載訓練數據
PaddleFluid
定義 輸入data layers
PaddleFluid 模型通過 fluid.layers.data 來接收輸入數據。圖像分類網絡以圖片以及圖片對應的類別標籤作爲網絡的輸入:
word = fluid.layers.data(
name="current_word", shape=[1], dtype="int64", lod_level=1)
lbl = fluid.layers.data(
name="next_word", shape=[1], dtype="int64", lod_level=1)
定義 data layer 的核心是指定輸入 Tensor 的形狀( shape )和類型。
RNN LM 使用 one-hot 作爲輸入,一個詞用一個和字典大小相同的向量表示,每一個位置對應了字典中的 一個詞語。one-hot 向量僅有一個維度爲 1, 其餘全部爲 0。因此爲了節約存儲空間,通常都直接用一個整型數表示給出詞語在字典中的 id,而不是真的創建一個和詞典同樣大小的向量 ,因此在上面定義的 data layer 中 word 和 lbl 的形狀都是 1,類型是 int64 。
需要特別說明的是,實際上 word 和 lbl 是兩個 [batch_size x 1] 的向量,這裏的 batch size 是指一個 mini-batch 中序列中的總詞數。對序列學習任務, mini-batch 中每個序列長度 總是在發生變化,因此實際的 batch_size 只有在運行時纔可以確定。 batch size 總是一個輸入 Tensor 的第 0 維,在 PaddleFluid 中指定 data layer 的 shape 時,不需要指定 batch size 的大小,也不需要考慮佔位。框架會自動補充佔位符,並且在運行時 設置正確的維度信息。因此,上面的兩個 data layer 的 shape 都只需要設置第二個維度,也就是 1。
LoD Tensor和Non-Padding的序列輸入
與前兩篇文章中的任務相比,在上面的代碼片段中定義 data layer 時,出現了一個新的 lod_level 字段,並設置爲 1。這裏就要介紹在 Fluid 系統中表示序列輸入的一個重要概念 LoDTensor。
那麼,什麼是 LoD(Level-of-Detail) Tensor 呢?
Tensor 是 nn-dimensional arry 的推廣,LoDTensor 是在 Tensor 基礎上附加了序列信息。
Fluid 中輸入、輸出,網絡中的可學習參數全部統一使用 LoDTensor(n-dimension array)表示,對非序列數據,LoD 信息爲空。一個 mini-batch 輸入數據是一個 LoDTensor。
在 Fluid 中,RNN 處理變長序列無需 padding,得益於 LoDTensor表示。
可以簡單將 LoD 理解爲:std::vector。
下圖是 LoDTensor 示意圖(圖片來自 Paddle 官方文檔):
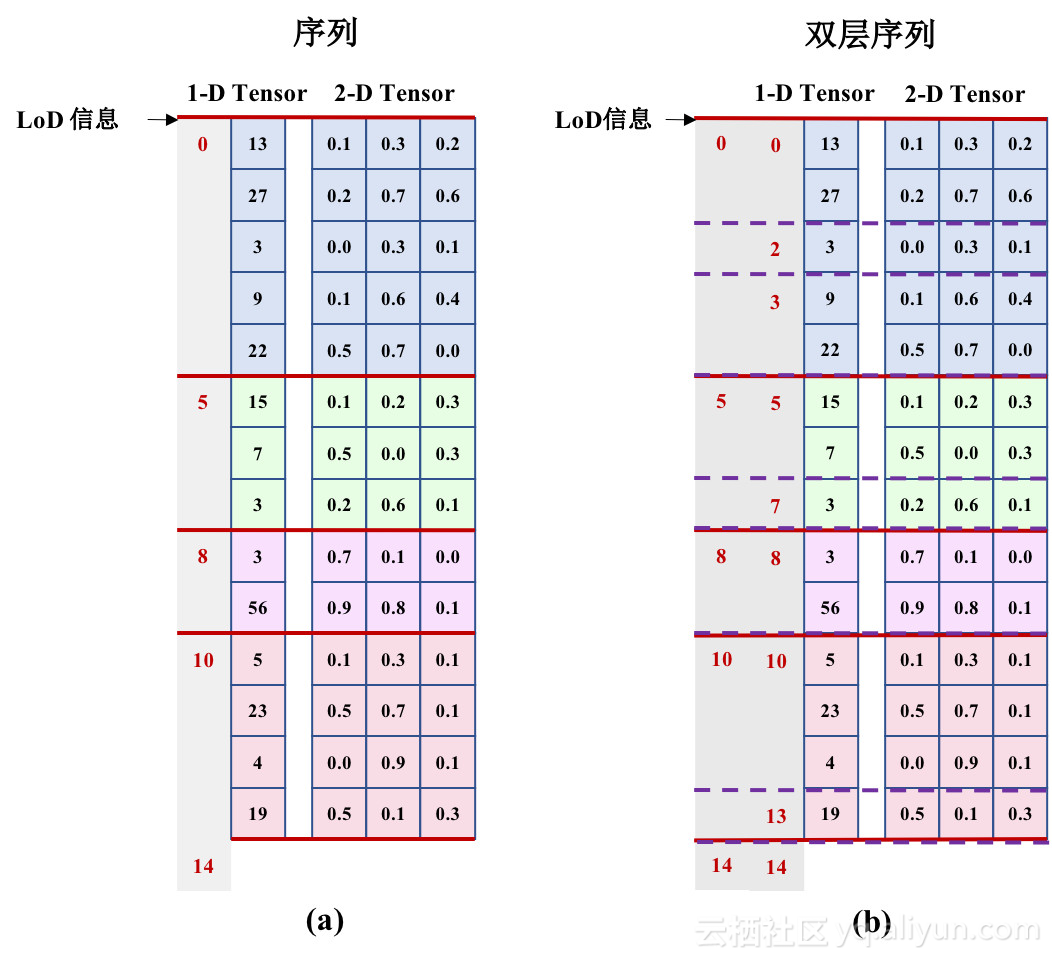
▲ 圖5. LoD Tensor示意圖
LoD 信息是附着在一個 Tensor 的第 0 維(也就是 batch size 對應的維度),來對一個 batch 中的數據進一步進行劃分,表示了一個序列在整個 batch 中的起始位置。
LoD 信息可以嵌套,形成嵌套序列。例如,NLP 領域中的段落是一種天然的嵌套序列,段落是句子的序列,句子是詞語的序列。
LoD 中的 level 就表示了序列信息的嵌套:
圖 (a) 的 LoD 信息 [0, 5, 8, 10, 14] :這個 batch 中共含有 4 條序列。
圖 (b) 的 LoD 信息 [[0, 5, 8, 10, 14] /level=1/, [0, 2, 3, 5, 7, 8, 10, 13, 14] /level=2/] :這個 batch 中含有嵌套的雙層序列。
有了 LoDTensor 這樣的數據表示方式,用戶不需要對輸入序列進行填充,框架會自動完成 RNN 的並行計算處理。
如何構造序列輸入信息
明白了 LoD Tensor 的概念之後,另一個重要的問題是應該如何構造序列輸入。在 PaddleFluid 中,通過 DataFeeder 模塊來爲網絡中的 data layer 提供數據,調用方式如下面的代碼所示:
train_reader = paddle.batch(
paddle.reader.shuffle(train_data, buf_size=51200),
batch_size=conf.batch_size)
place = fluid.CUDAPlace(0) if conf.use_gpu else fluid.CPUPlace()
feeder = fluid.DataFeeder(feed_list=[word, lbl], place=place)
觀察以上代碼,需要用戶完成的僅有:編寫一個實現讀取一條數據的 python 函數: train_data 。 train_data 的代碼非常簡單,我們再來看一下它的具體實現 [3]:
def train_data(data_dir="data"):
data_path = os.path.join(datadir, "ptb.train.txt")
, word_to_id = build_vocab(data_path)
with open(data_path, "r") as ftrain:
for line in ftrain:
words = line.strip().split()
word_ids = [word_to_id[w] for w in words]
yield word_ids[0:-1], word_ids[1:]在上面的代碼中:
train_data 是一個 python generator ,函數名字可以任意指定,無需固定。
train_data 打開原始數據數據文件,讀取一行(一行既是一條數據),返回一個 python list,這個 python list 既是序列中所有時間步。具體的數據組織方式如下表所示(其中,f 代表一個浮點數,i 代表一個整數):
image
paddle.batch() 接口用來構造 mini-batch 輸入,會調用 train_data 將數據讀入一個 pool 中,對 pool 中的數據進行 shuffle,然後依次返回每個 mini-batch 的數據。
TensorFlow
TensorFlow 中使用佔位符 placeholder 接收 訓練數據,可以認爲其概念等價於 PaddleFluid 中的 data layer。同樣的,我們定義瞭如下兩個 placeholder 用於接收當前詞與下一個詞語:
def placeholders(self):
self._inputs = tf.placeholder(tf.int32,
[None, self.max_sequence_length])
self._targets = tf.placeholder(tf.int32, [None, self.vocab_size])
placeholder 只存儲一個 mini-batch 的輸入數據。與 PaddleFluid 中相同, _inputs 這裏接收的是 one-hot 輸入,也就是該詞語在詞典中的 index,one-hot 表示 會進一步通過此詞向量層的作用轉化爲實值的詞向量表示。
需要注意的是,TensorFlow 模型中網絡輸入數據需要進行填充,保證一個 mini-batch 中序列長度 相等。也就是一個 mini-batch 中的數據長度都是 max_seq_length ,這一點與 PaddleFluid 非常不同。
通常做法 是對不等長序列進行填充,在這一篇示例中我們使用一種簡化的做法,每條訓練樣本都按照 max_sequence_length 來切割,保證一個 mini-batch 中的序列是等長的。
於是, _input 的 shape=[batch_size, max_sequence_length] 。 max_sequence_length 即爲 RNN 可以展開長度。
構建網絡結構
PaddleFluid RNN LM
這裏主要關注最核心的 LSTM 單元如何定義:
def __rnn(self, input):
for i in range(self.num_layers):
hidden = fluid.layers.fc(
size=self.hidden_dim 4,
bias_attr=fluid.ParamAttr(
initializer=NormalInitializer(loc=0.0, scale=1.0)),
input=hidden if i else input)
lstm = fluid.layers.dynamic_lstm(
input=hidden,
size=self.hidden_dim 4,
candidate_activation="tanh",
gate_activation="sigmoid",
cell_activation="sigmoid",
bias_attr=fluid.ParamAttr(
initializer=NormalInitializer(loc=0.0, scale=1.0)),
is_reverse=False)
return lstm
PaddleFluid 中的所有 RNN 單元(RNN/LSTM/GRU)都支持非填充序列作爲輸入,框架會自動完成不等長序列的並行處理。當需要堆疊多個 LSTM 作爲輸入時,只需利用 Python 的 for 循環語句,讓一個 LSTM 的輸出成爲下一個 LSTM 的輸入即可。在上面的代碼片段中有一點需要特別注意:PaddleFluid 中的 LSTM 單元是由 fluid.layers.fc+ fluid.layers.dynamic_lstm 共同構成的。
image
▲ 圖6. LSTM計算公式
圖 6 是 LSTM 計算公式,圖中用紅色圈起來的計算是每一時刻輸入矩陣流入三個門和 memory cell 的之前的映射。PaddleFluid 將這個四個矩陣運算合併爲一個大矩陣一次性計算完畢, fluid.layers.dynamic_lstm 不包含這部分運算。因此:
PaddleFluid 中的 LSTM 單元是由 fluid.layers.fc + fluid.layers.dynamic_lstm 。
假設 LSTM 單元的隱層大小是 128 維, fluid.layers.fc 和 fluid.layers.dynamic_lstm 的 size 都應該設置爲 128 * 4,而不是 128。
TensorFlow RNN LM
這裏主要關注最核心的 LSTM 單元如何定義:
def rnn(self):
def lstm_cell():
return tf.contrib.rnn.BasicLSTMCell(
self.hidden_dim, state_is_tuple=True)
cells = [lstm_cell() for _ in range(self.num_layers)]
cell = tf.contrib.rnn.MultiRNNCell(cells, state_is_tuple=True)
_inputs = self.input_embedding()
_outputs, _ = tf.nn.dynamic_rnn(
cell=cell, inputs=_inputs, dtype=tf.float32)
last = _outputs[:, -1, :]
logits = tf.layers.dense(inputs=last, units=self.vocab_size)
prediction = tf.nn.softmax(logits)tf.nn.rnn_cell.BasicLSTMCell(n_hidden, state_is_tuple=True) : 是最基本的 LSTM 單元。 n_hidden 表示 LSTM 單元隱層大小。 state_is_tuple=True 表示返回的狀態用一個元祖表示。
tf.contrib.rnn.MultiRNNCell : 用來 wrap 一組序列調用的 RNN 單元的 wrapper。
tf.nn.dynamic_rnn : 通過指定 mini-batch 中序列的長度,可以跳過 padding 部分的計算,減少計算量。這一篇的例子中由於我們對輸入數據進行了處理,將它們都按照 max_sequence_length 切割。
但是, dynamic_rnn 可以讓不同 mini-batch 的 batch size 長度不同,但同一次迭代一個 batch 內部的所有數據長度仍然是固定的。
運行訓練
運行訓練任務對兩個平臺都是常規流程,可以參考上文在程序結構一節介紹的流程,以及代碼部分:PaddleFluid vs. TensorFlow,這裏不再贅述。
總結
這一篇我們第一次接觸 PaddleFluid 和 TensorFlow 平臺的序列模型。瞭解 PaddleFluid 和 TensorFlow 在接受序列輸入,序列處理策略上的不同。序列模型是神經網絡模型中較爲複雜的一類模型結構,可以衍生出非常複雜的模型結構。
不論是 PaddleFluid 以及 TensorFlow 都實現了多種不同的序列建模單元,如何選擇使用這些不同的序列建模單元有很大的學問。到目前爲止平臺使用的一些其它重要主題:例如多線程多卡,如何利用混合設備計算等我們還尚未涉及。接下來的篇章將會繼續深入 PaddleFluid 和 TensorFlow 平臺的序列模型處理機制,以及更多重要功能如何在兩個平臺之間實現。
參考文獻
[1]. 本文配套代碼
https://github.com/JohnRabbbit/TF2Fluid/tree/master/03_rnnlm
[2]. Understanding LSTM Networks
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[3]. train_data具體實現
https://github.com/JohnRabbbit/TF2Fluid/blob/master/03_rnnlm/load_data_fluid.pyhttps://github.com/JohnRabbbit/TF2Fluid/blob/master/03_rnnlm/load_data_fluid.py