




一致性哈希算法的起源和介紹就不說了,一般這個是用於分佈式緩存,用於處理緩存的數據和多個緩存服務器之間的對應關係。
個人的理解是如果能夠從緩存服務器中get到數據就是緩存命中,直接從緩存服務器中獲取數據,如果沒命中就從基礎服務器中獲取數據(這種效率相對很差),使用緩存服務器既能提升後端的返回速度,也大大的減輕了數據服務器的壓力。
- 一般算法
說到一致性哈希算法總會以一般的哈希算法爲開頭,這裏也同樣這樣介紹。
按照網上大多數的範例,假設有3臺緩存服務器A、B、C。對每條要緩存的數據進行哈希計算,然後對服務器數求餘,得到的數字就是該數據要存的緩存服務器的位置。
計算公式:
hash(object) % N這裏N爲3,計算的結果肯定是0、1、2中的一個,0對應A,1對應B,2對應C。
正常情況下這種方式是可行的。但是,如果業務量增大要增加緩存服務器,這時候緩存數據庫上多數的緩存數據就會失效,減少服務器也會出現這種情況,而且如果緩存服務器中緩存數據失效過多也有可能引起數據服務器的訪問量突然增大,造成數據服務器的服務癱瘓。
- 一致性哈希算法
意識到了上面的方法的不足,現在再來看下一致性哈希算法。
一致性哈希算法有些地方說是對象的hash值對2的32次方進行取模,也有的地方說是拿對象的hash值對2的32次方進行映射。
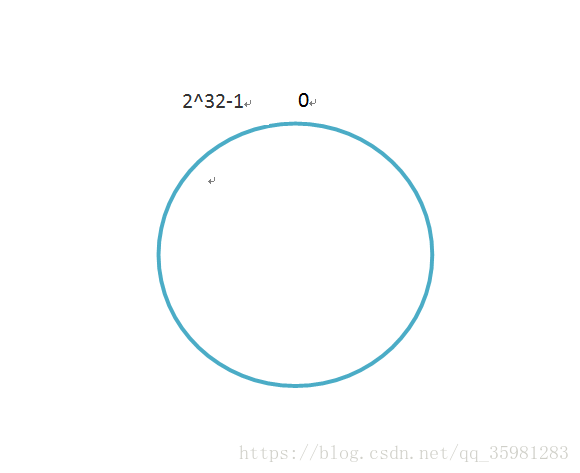
一致性哈希算法涉及到一個很重要的概念——哈希環,這和環上有2^32個點,這些點形成了一個閉環,如下:
0爲起始點,0的左邊第一個點是2^32-1。
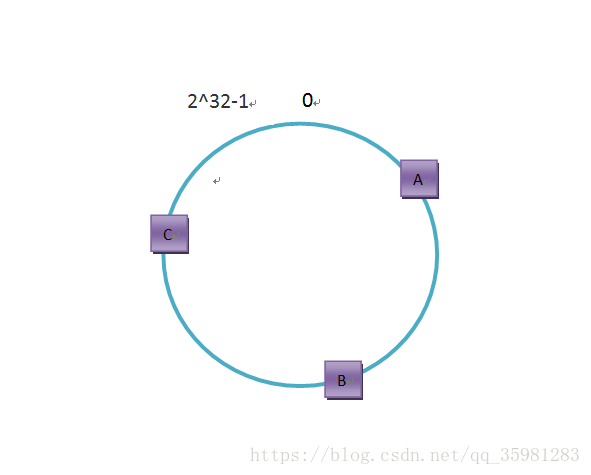
先求出A、B、C三臺服務器的hash值,一般是對服務器的ip或者服務器的名稱求hash值。
假設A、B、C三臺服務器對應的位置如下:
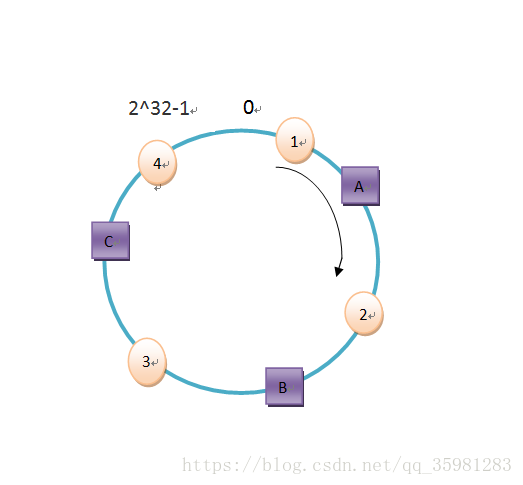
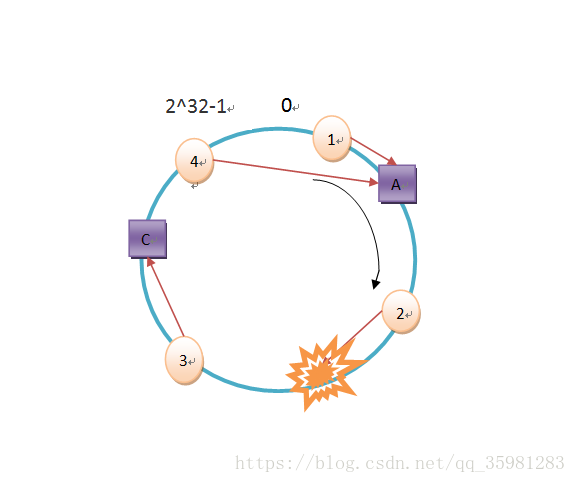
現在以4個數據爲例來存儲:object1、object2、object3、object4。
計算hash值:
hash(object1) = key1
hash(object2) = key2
hash(object3) = key3
hash(object4) = key4這四個值在hash環上的對應爲從0開始,按照順時針,離這個hash值最近的那個節點作爲存儲服務器。
其對應存儲如下:
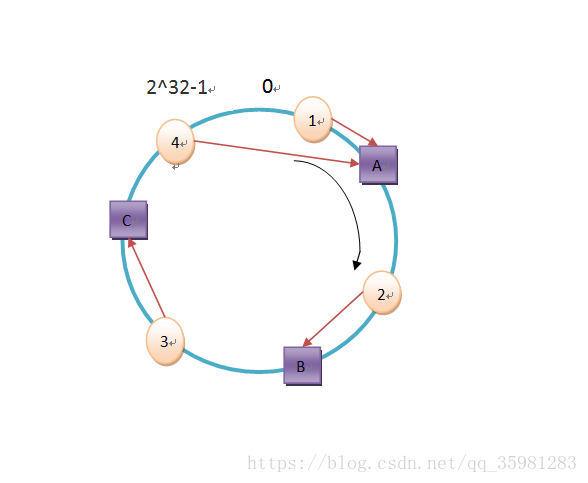
其中object4之後沒有節點,會從0開始尋找緩存服務器,所以存到A上。
現在如果去掉節點B,可以看出object2的緩存就找到C上了,這時候是找不到的,但是object1、object3和object4依然是有效的。
如果新增節點也是類似情況,相對來說對原有服務器的影響很小很小。
但是,現實中A、B、C節點在哈希環上的分佈很多時候都會是下面這種情況:
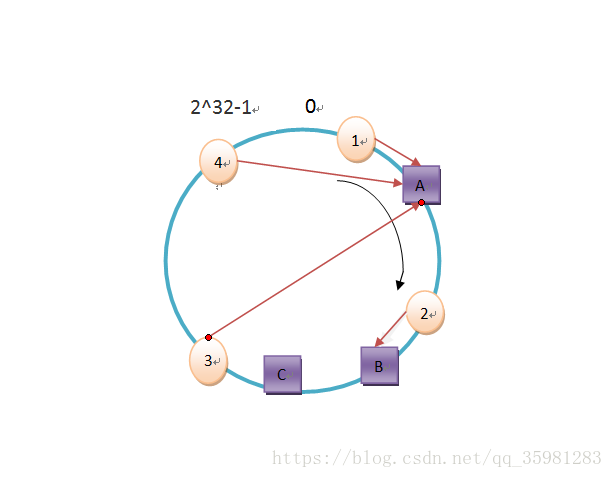
這時候C節點是沒用的,負載都集中到了A上。針對這種情況引入了虛擬節點。
- 虛擬節點
所謂的虛擬節點就是一臺主機在哈希環上分配多個節點,一般哈希環上節點越多分配的越均勻,才能更大的體現出一致性哈希算法的優勢。
這裏我們對A、B、C都映射兩個虛擬節點,虛擬節點的映射可以通過類似如下方式來生成:
hash(ipA#A1) = key1
hash(ipA#A2) = key2
hash(ipB#B1) = key3
hash(ipB#B2) = key4
hash(ipC#C1) = key5
hash(ipC#C2) = key6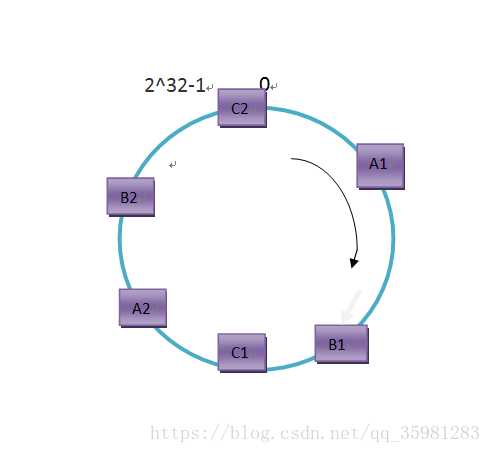
這個時候緩存主機分配的相對來說比較均勻,同樣數據緩存的時候對應的主機也會相對均勻。