在CDH5.14.2 中啓用kudu的配置
標籤(空格分隔): 大數據平臺構建
- 一: 系統平臺介紹
- 二: 安裝kudu的集成
一: 系統平臺介紹
1.1. 關於kudu的介紹
Kudu是Cloudera開源的新型列式存儲系統,是Apache Hadoop生態圈的新成員之一(incubating),專門爲了對快速變化的數據進行快速的分析,填補了以往Hadoop存儲層的空缺。
Hadoop生態系統有很多組件,每一個組件有不同的功能。在現實場景中,用戶往往需要同時部署很多Hadoop工具來解決同一個問題,這種架構稱爲混合架構 (hybrid architecture)。比如,用戶需要利用Hbase的快速插入、快讀random access的特性來導入數據,HBase也允許用戶對數據進行修改,HBase對於大量小規模查詢也非常迅速。同時,用戶使用HDFS/Parquet + Impala/Hive來對超大的數據集進行查詢分析,對於這類場景, Parquet這種列式存儲文件格式具有極大的優勢。
很多公司都成功地部署了HDFS/Parquet + HBase混合架構,然而這種架構較爲複雜,而且在維護上也十分困難。首先,用戶用Flume或Kafka等數據Ingest工具將數據導入HBase,用戶可能在HBase上對數據做一些修改。然後每隔一段時間(每天或每週)將數據從Hbase中導入到Parquet文件,作爲一個新的partition放在HDFS上,最後使用Impala等計算引擎進行查詢,生成最終報表。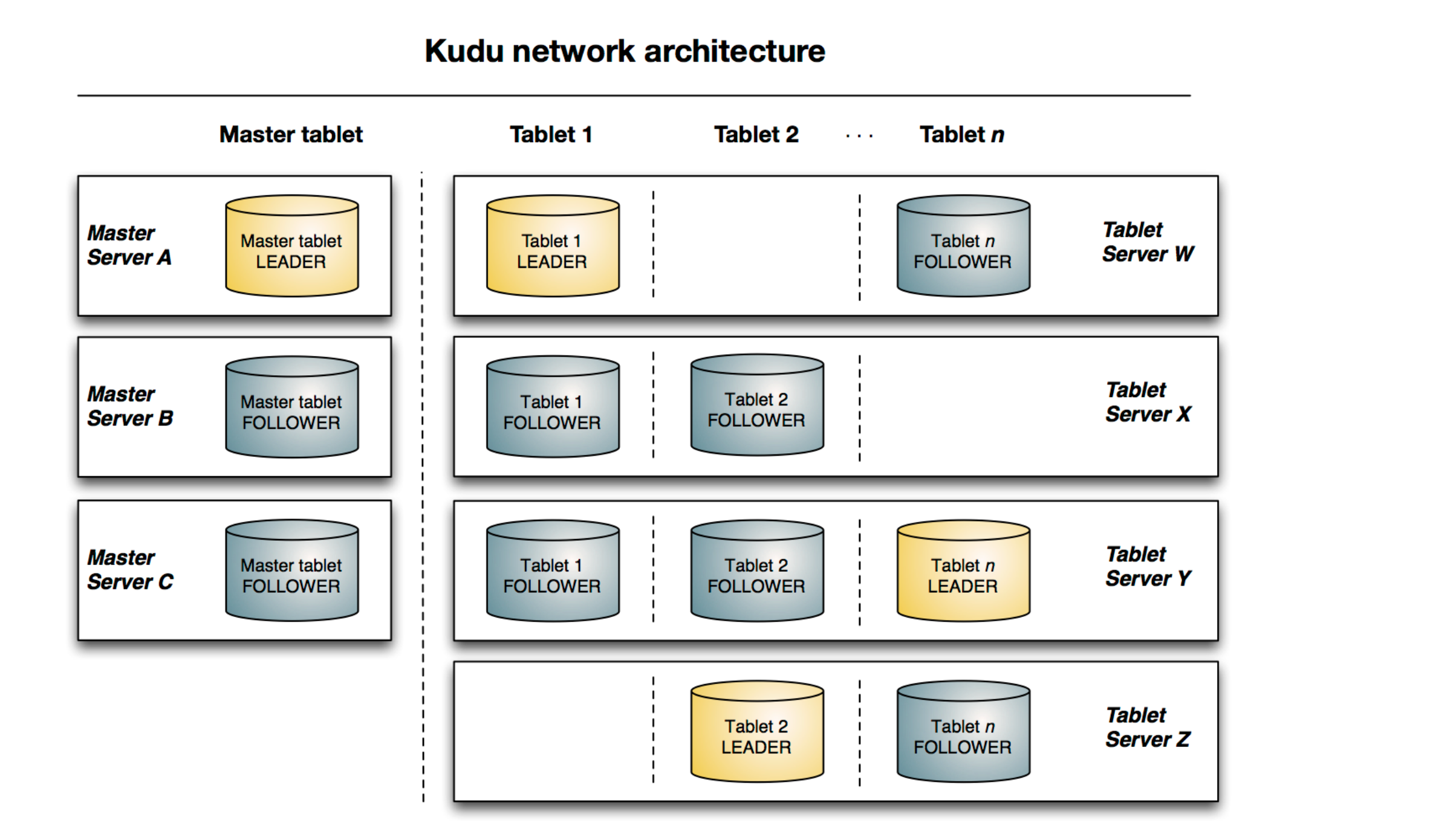
二: 安裝kudu的集成
2.1 kudu 準備與下載
CDH從5.10開始,打包集成Kudu1.2,並且Cloudera正式提供支持。這個版本開始Kudu的安裝較之前要簡單很多,省去了Impala_Kudu,安裝完Kudu,Impala即可直接操作Kudu。
CSD 包下載
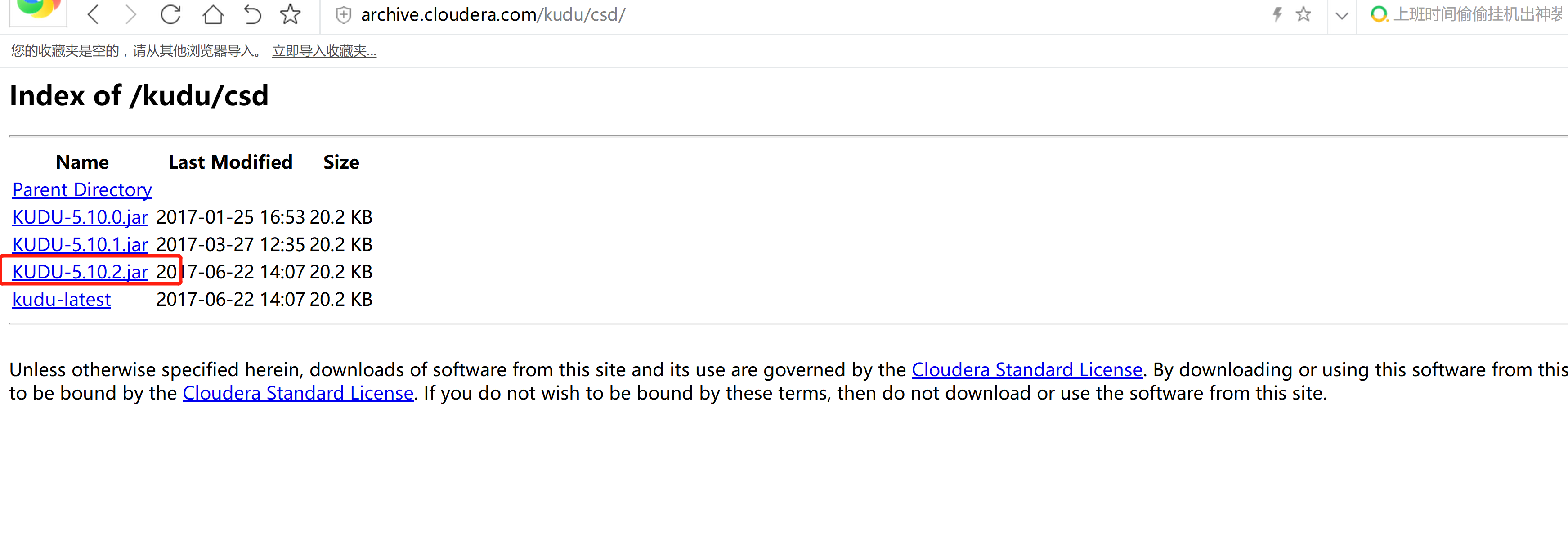
軟件下載:
http://archive.cloudera.com/kudu/csd/
KUDU-5.10.2.jar
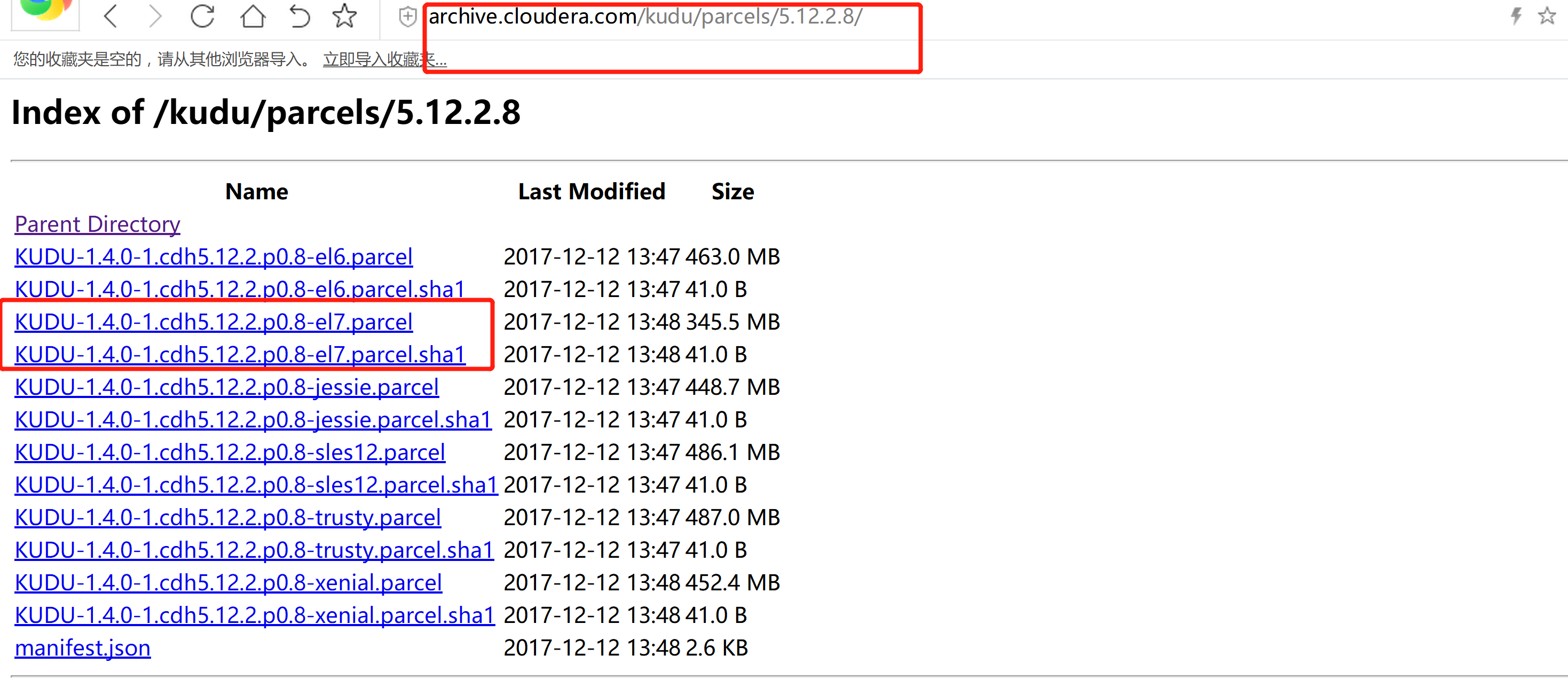
parcel 包:
http://archive.cloudera.com/kudu/parcels/5.12.2.8/
KUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcel
KUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcel.sha1
manifest.json
2.2 開始安裝kudu
mv KUDU-5.10.2.jar /opt/cloudera/csd/
chown cloudera-scm:cloudera-scm /opt/cloudera/csd/KUDU-5.10.2.jar
cd /opt/cloudera/csd/
chmod 644 KUDU-5.10.2.jar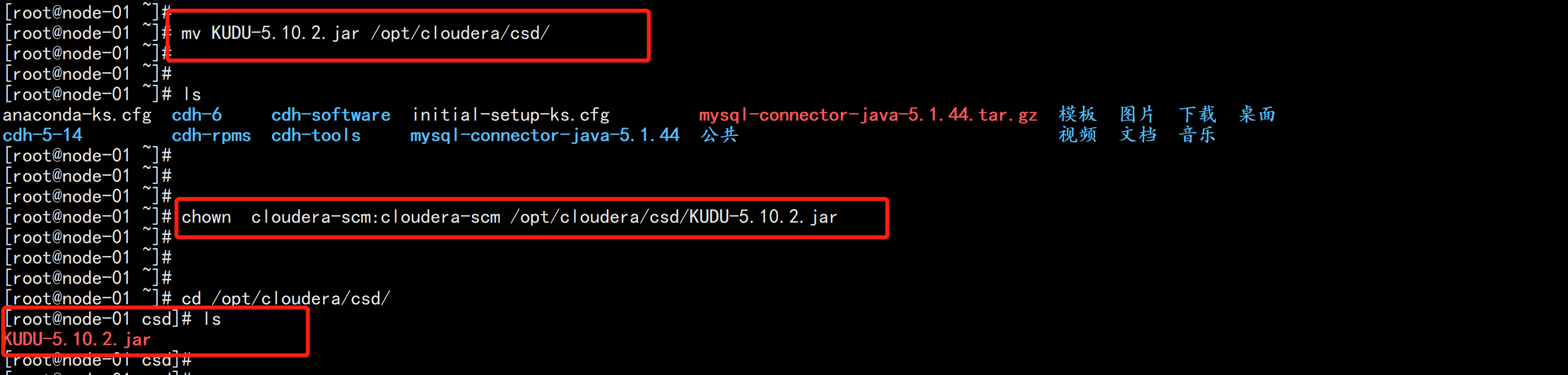

配置httpd-server
yum install -y httpd*
service httpd start
chkconfig httpd on
mv KUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcel* /var/www/html/kudu
mv manifest.json /var/www/html/kudu/
cd /var/www/html/kudu/
mv KUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcel.sha1 KUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcel.sha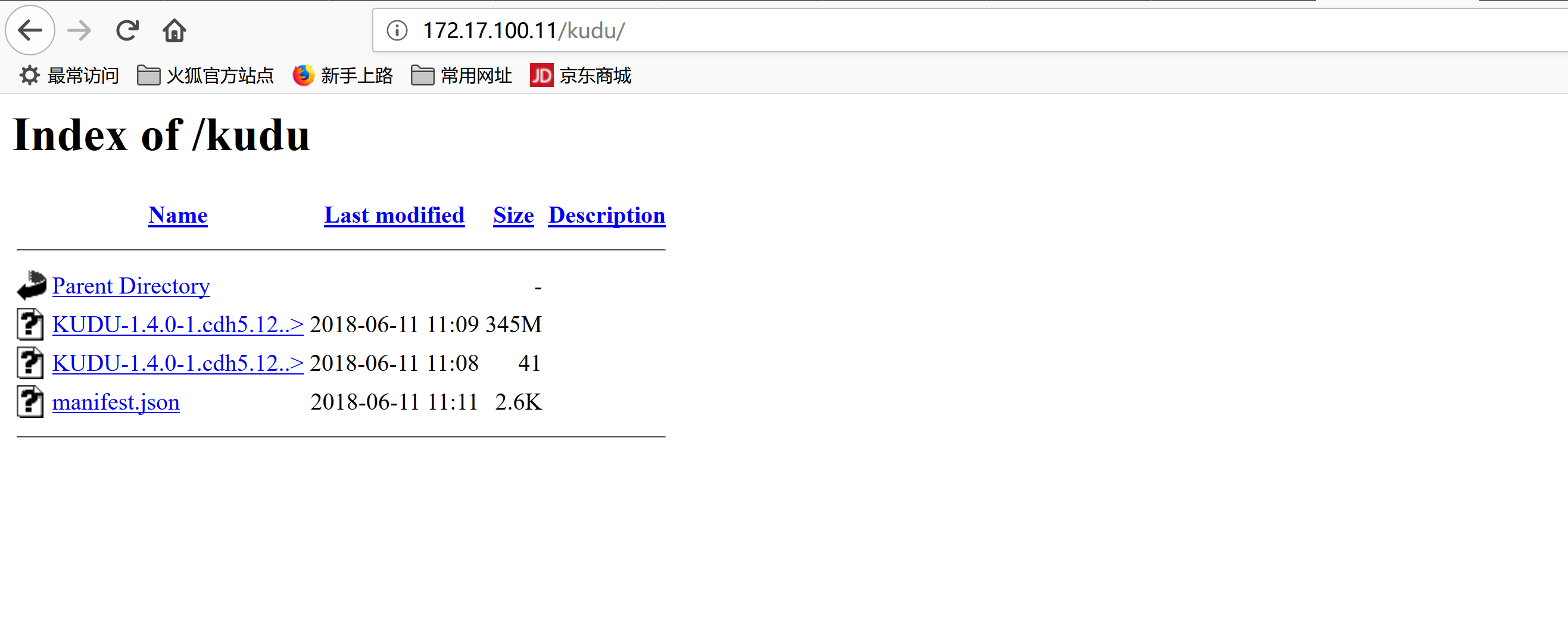
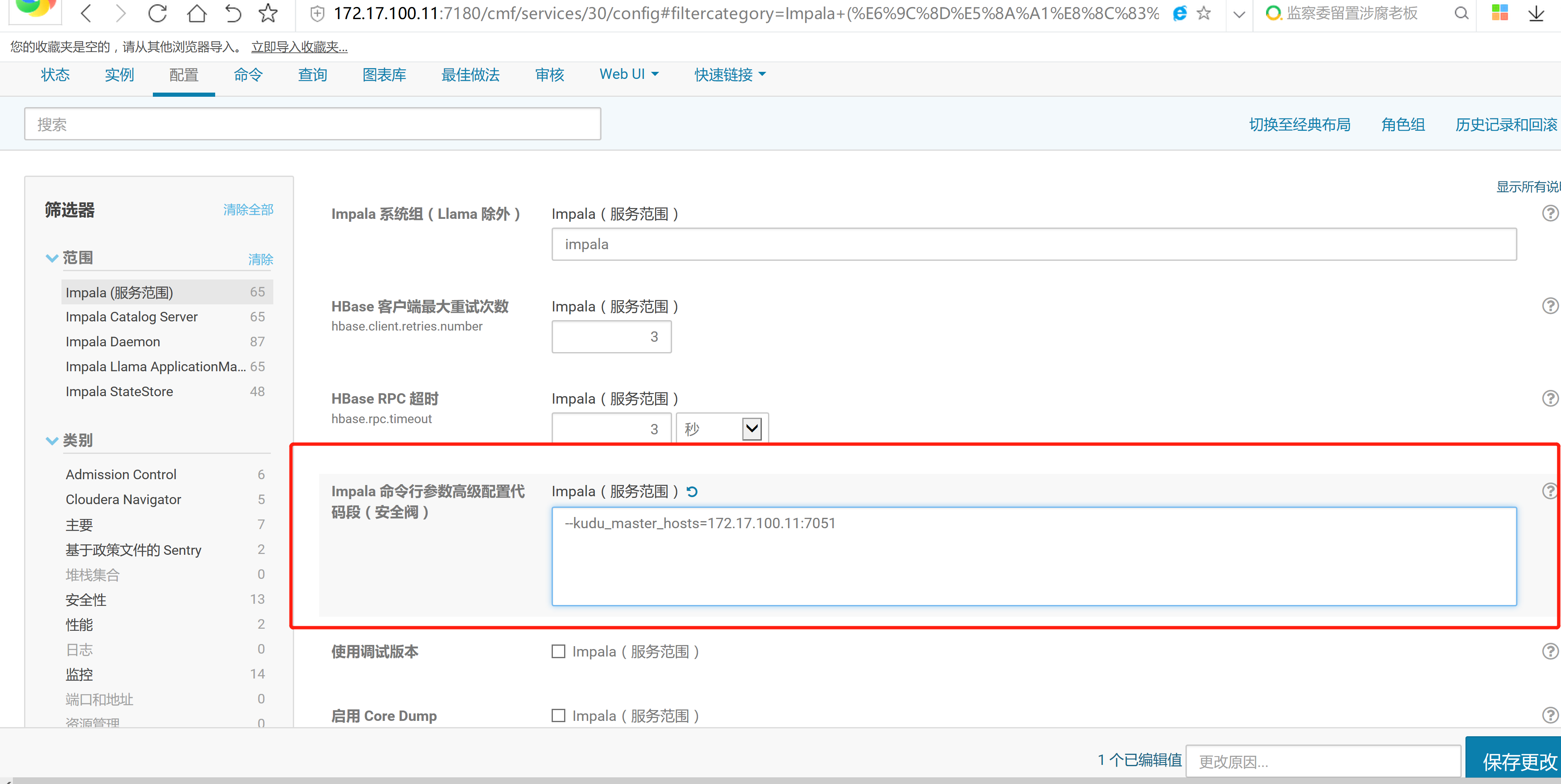
2.3 通過CM界面配置Kudu的Parcel地址,並下載,分發,激活Kudu
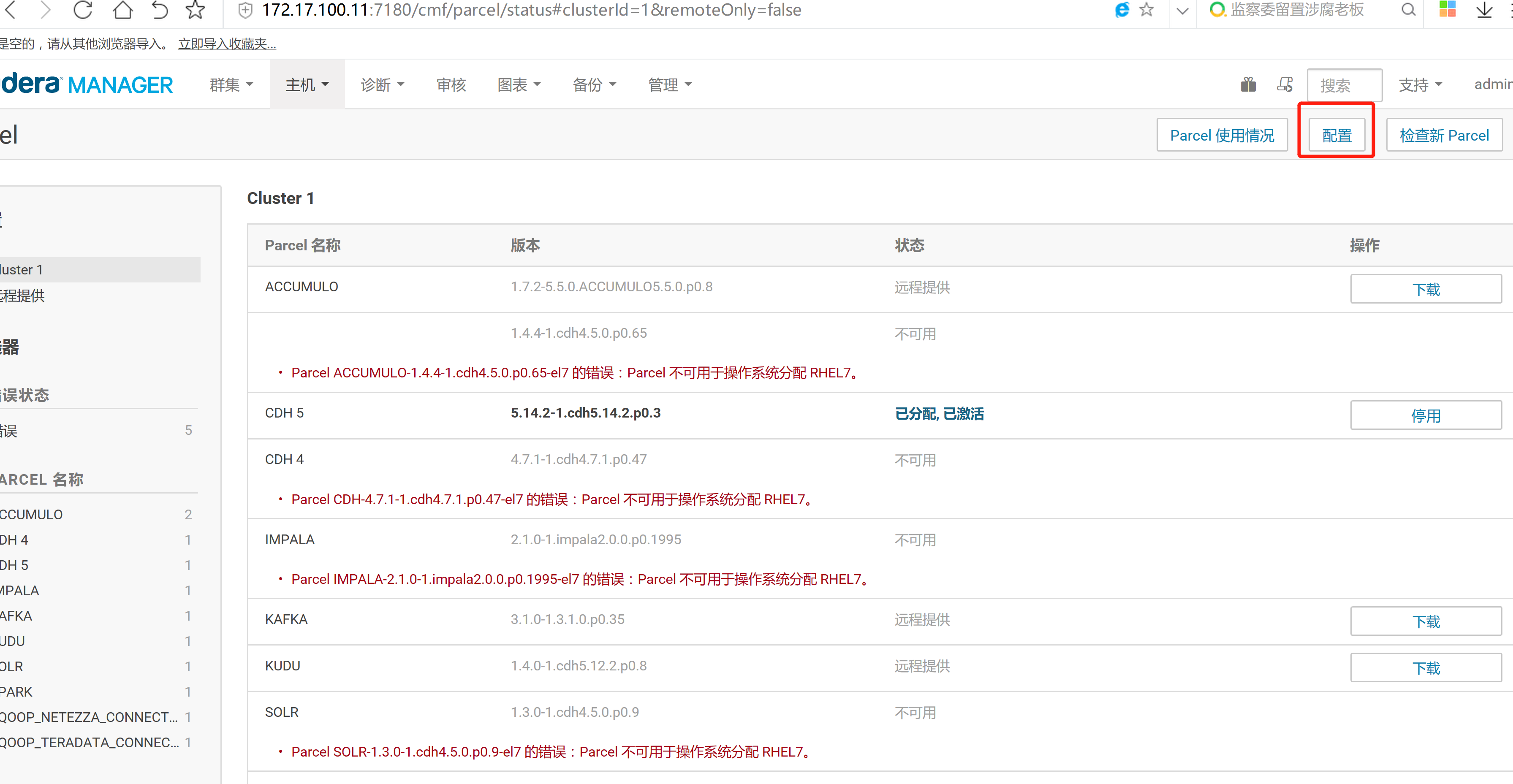
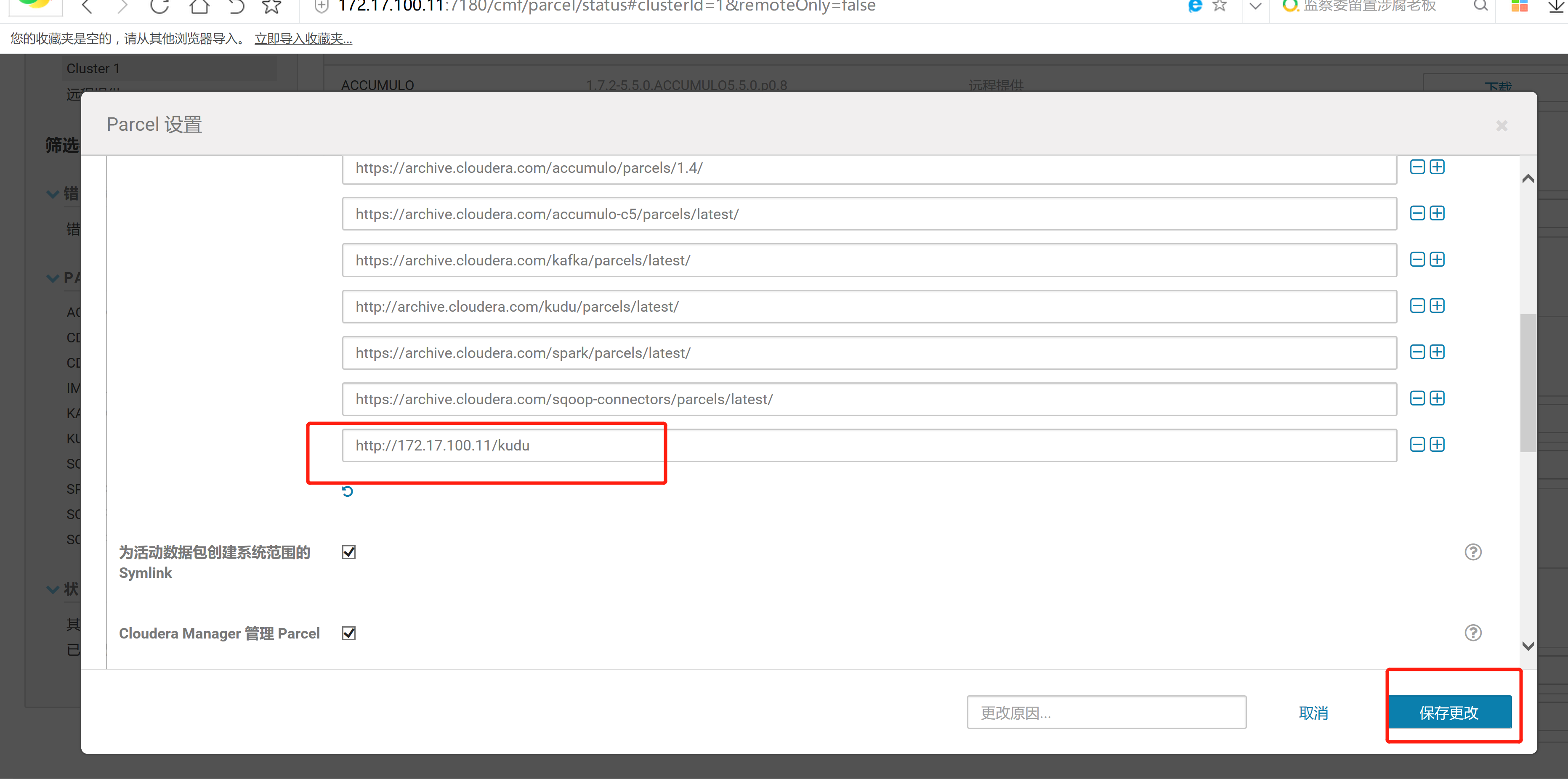
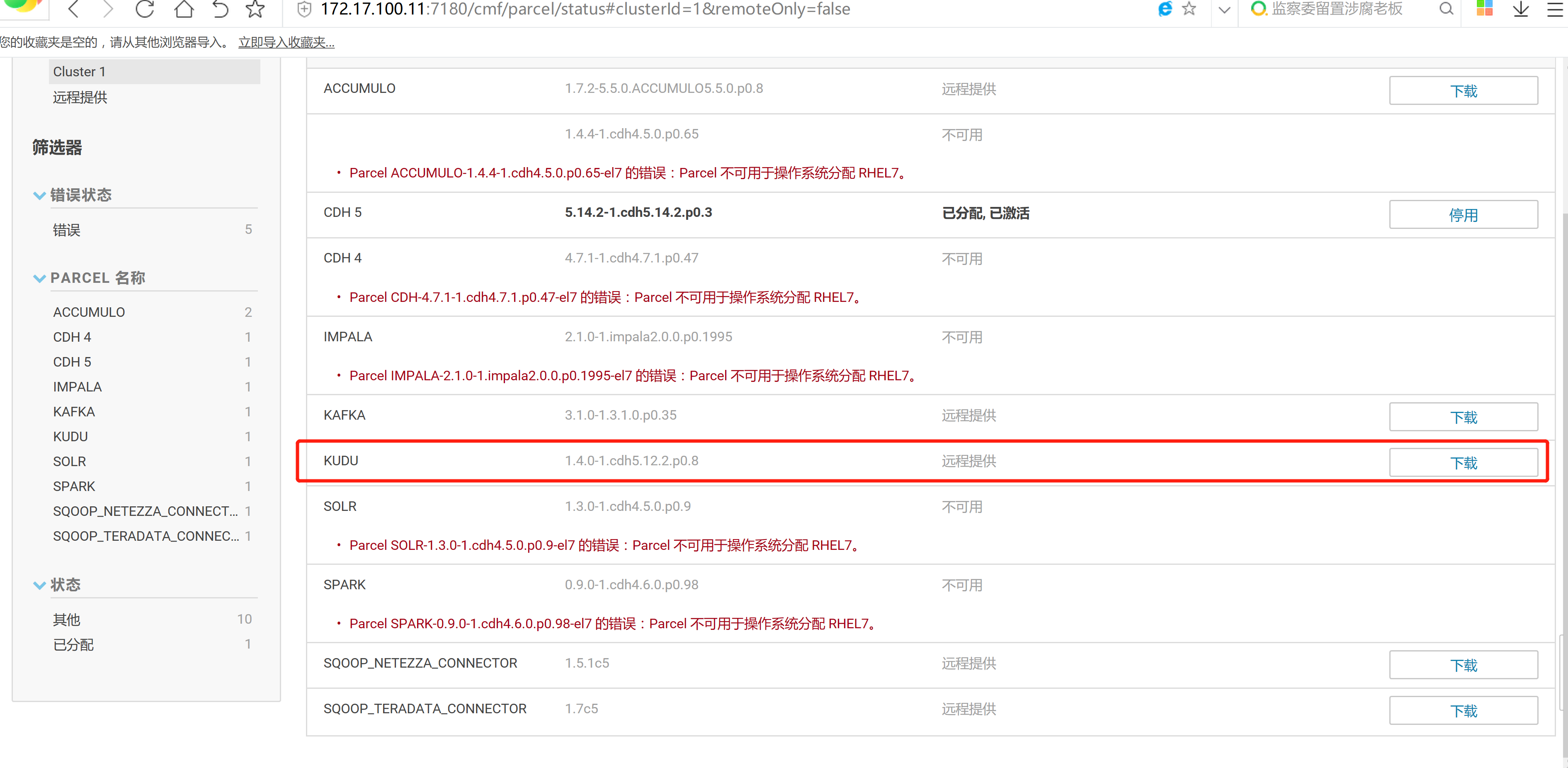
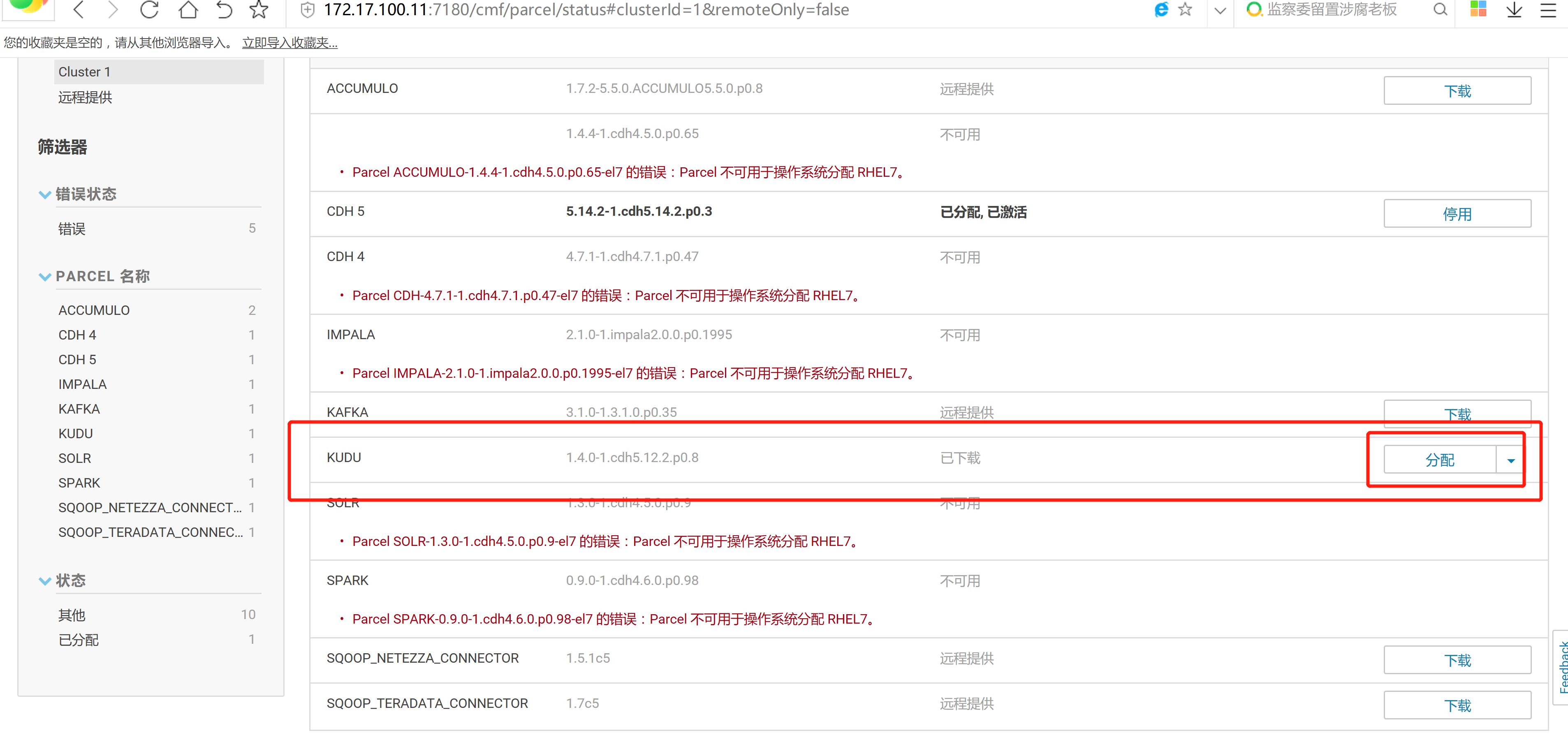

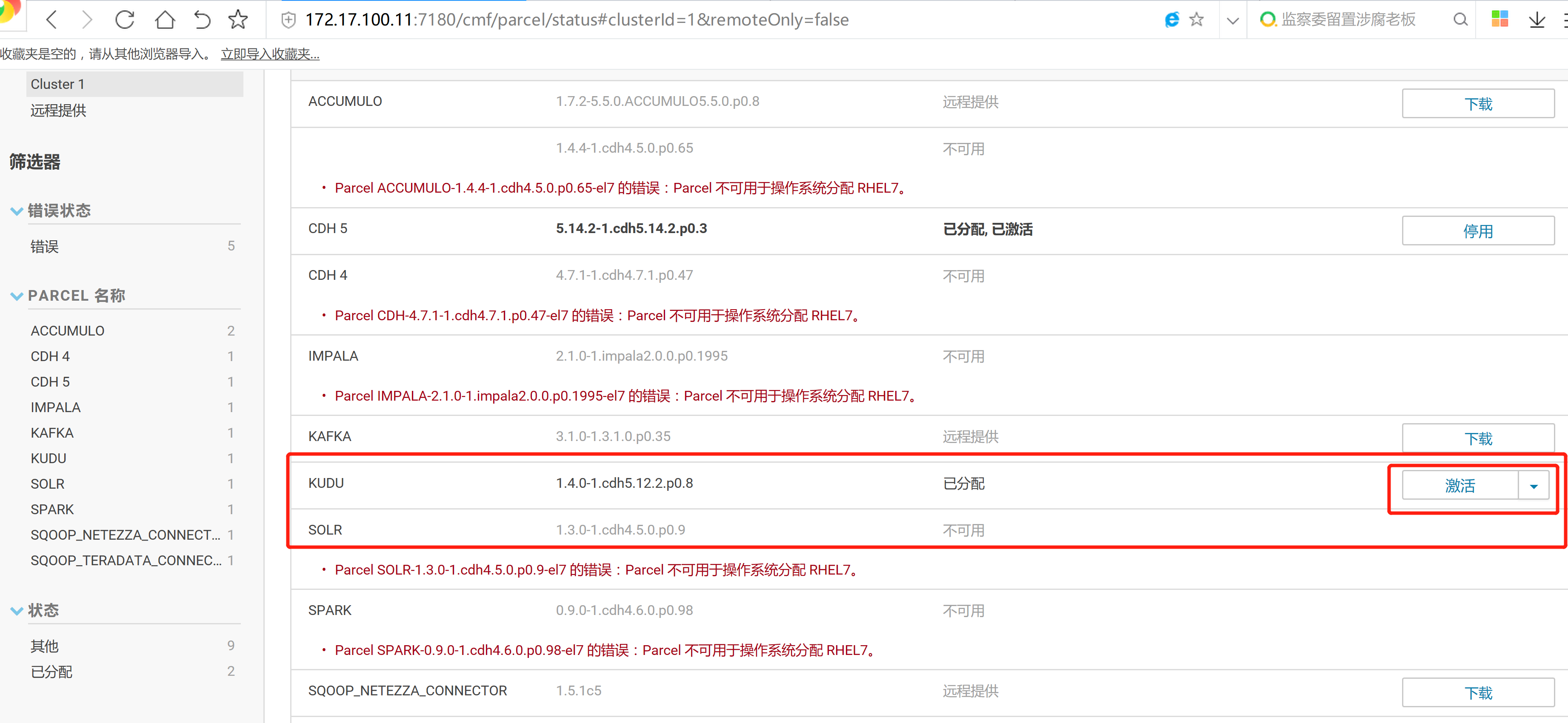
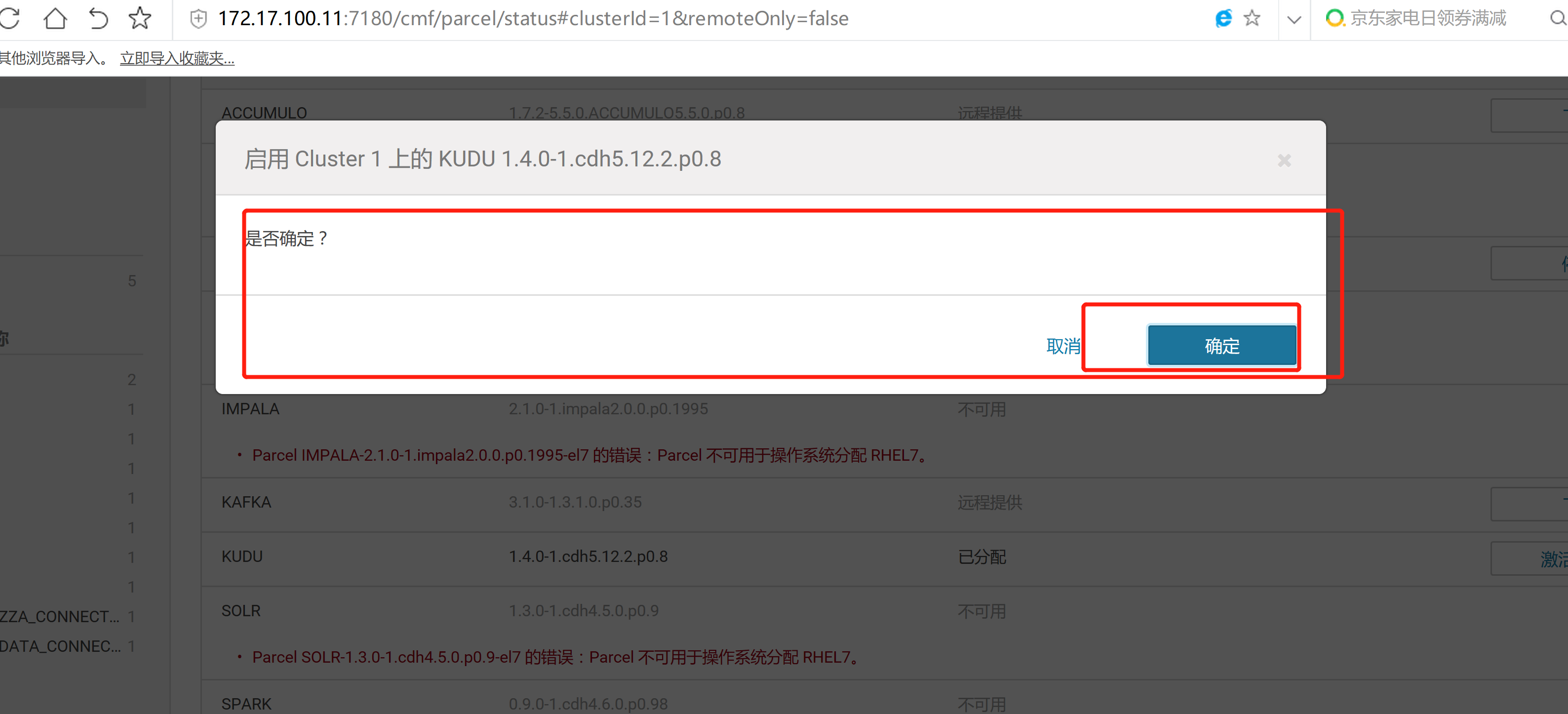
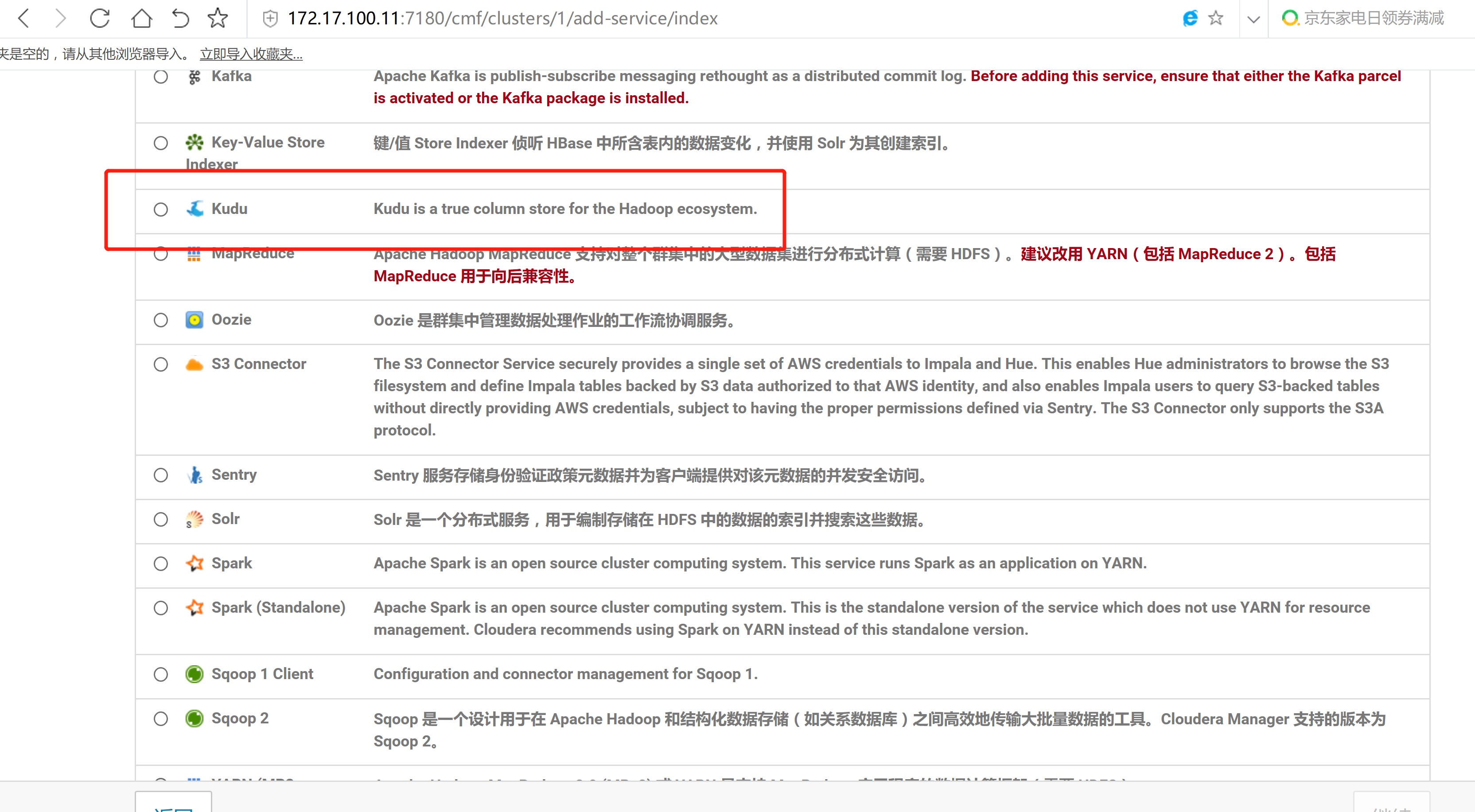
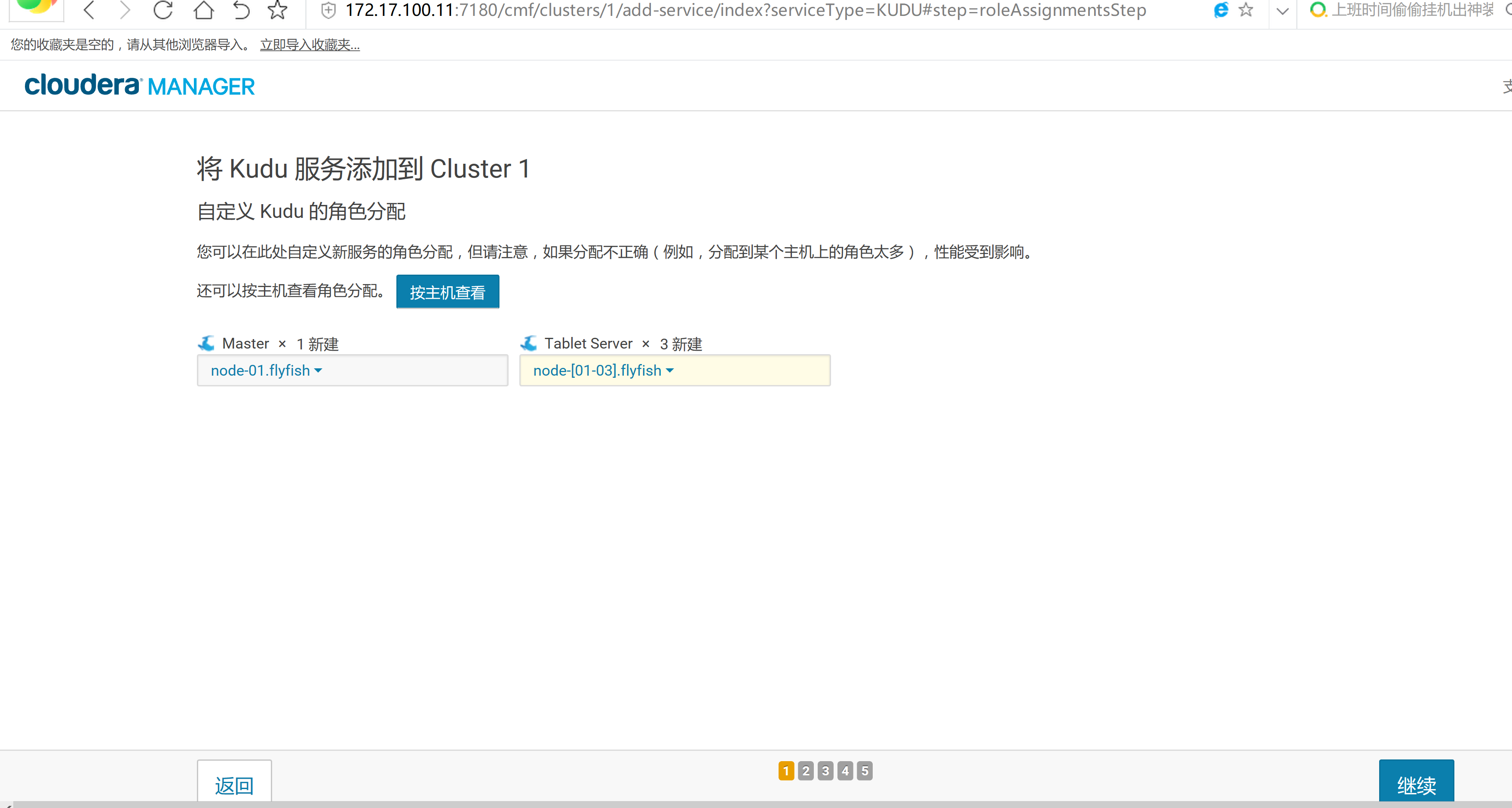
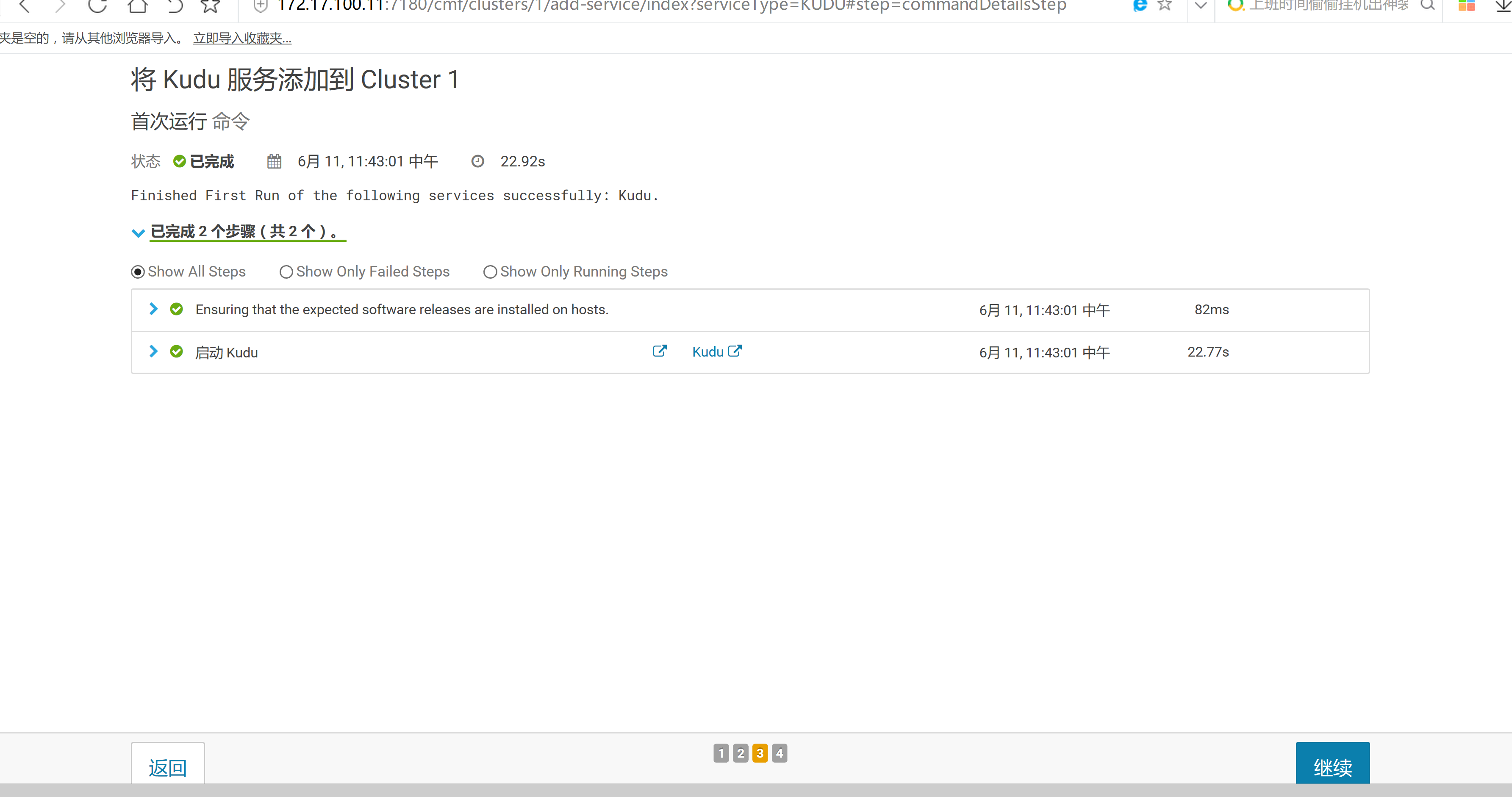
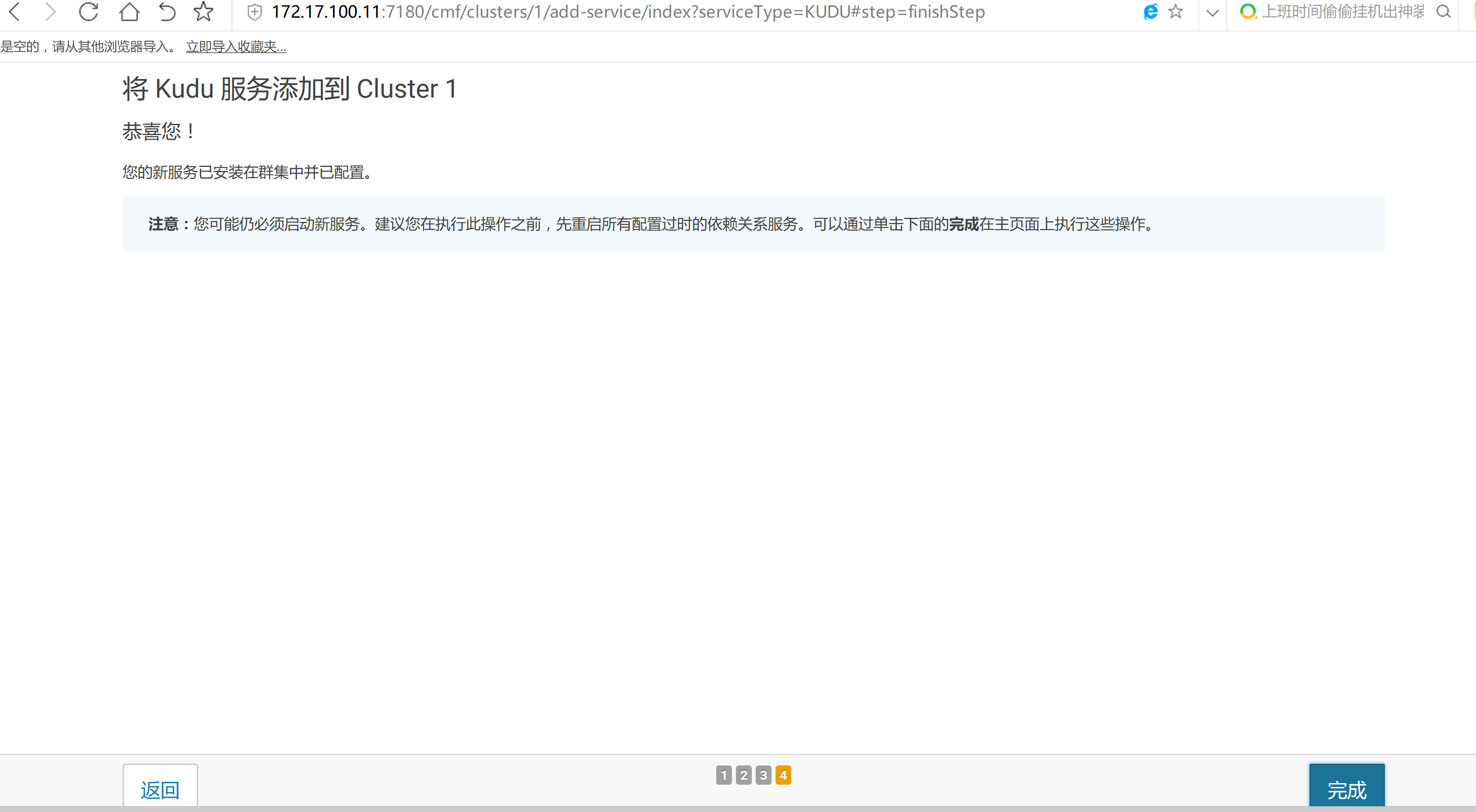
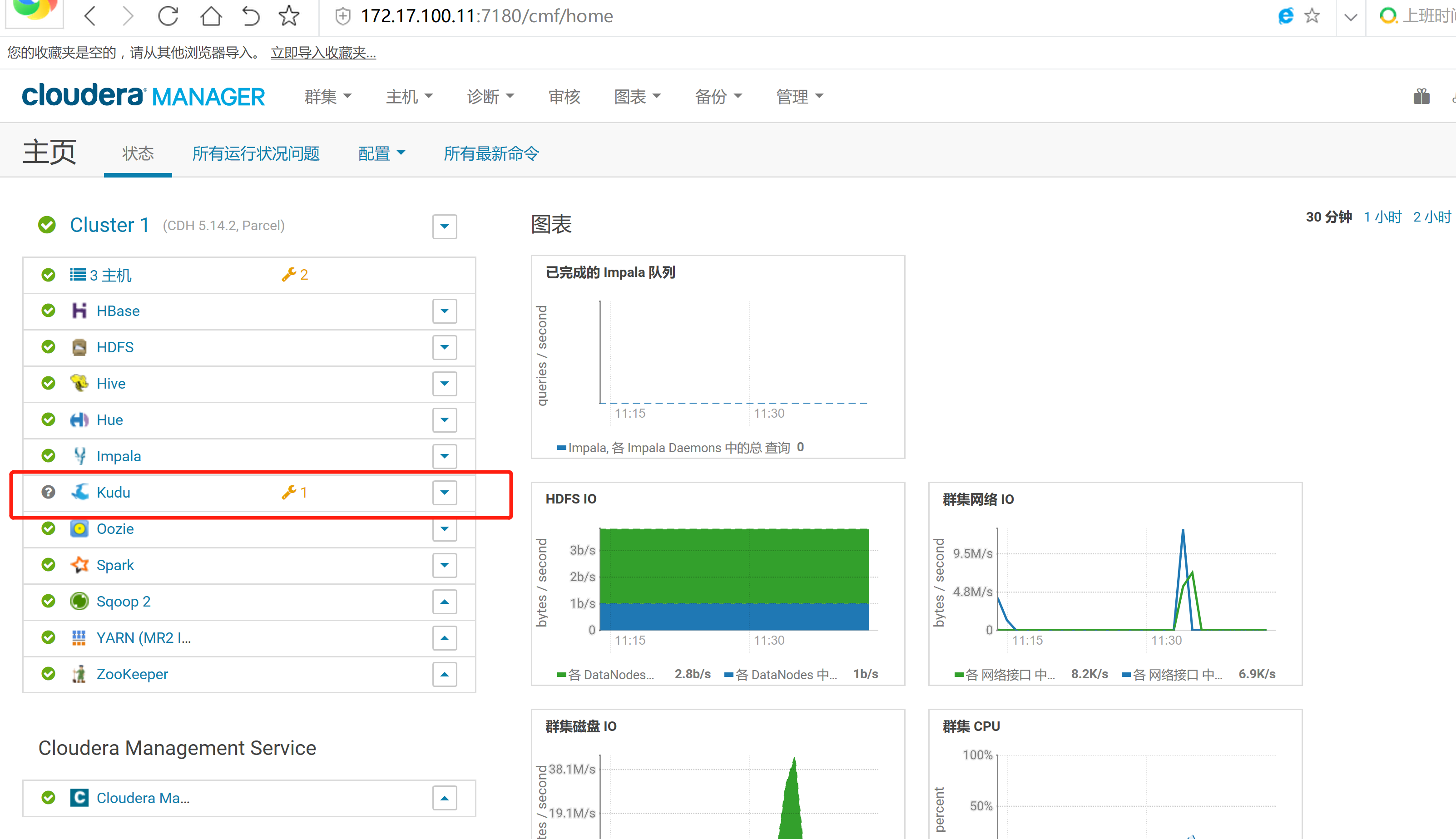
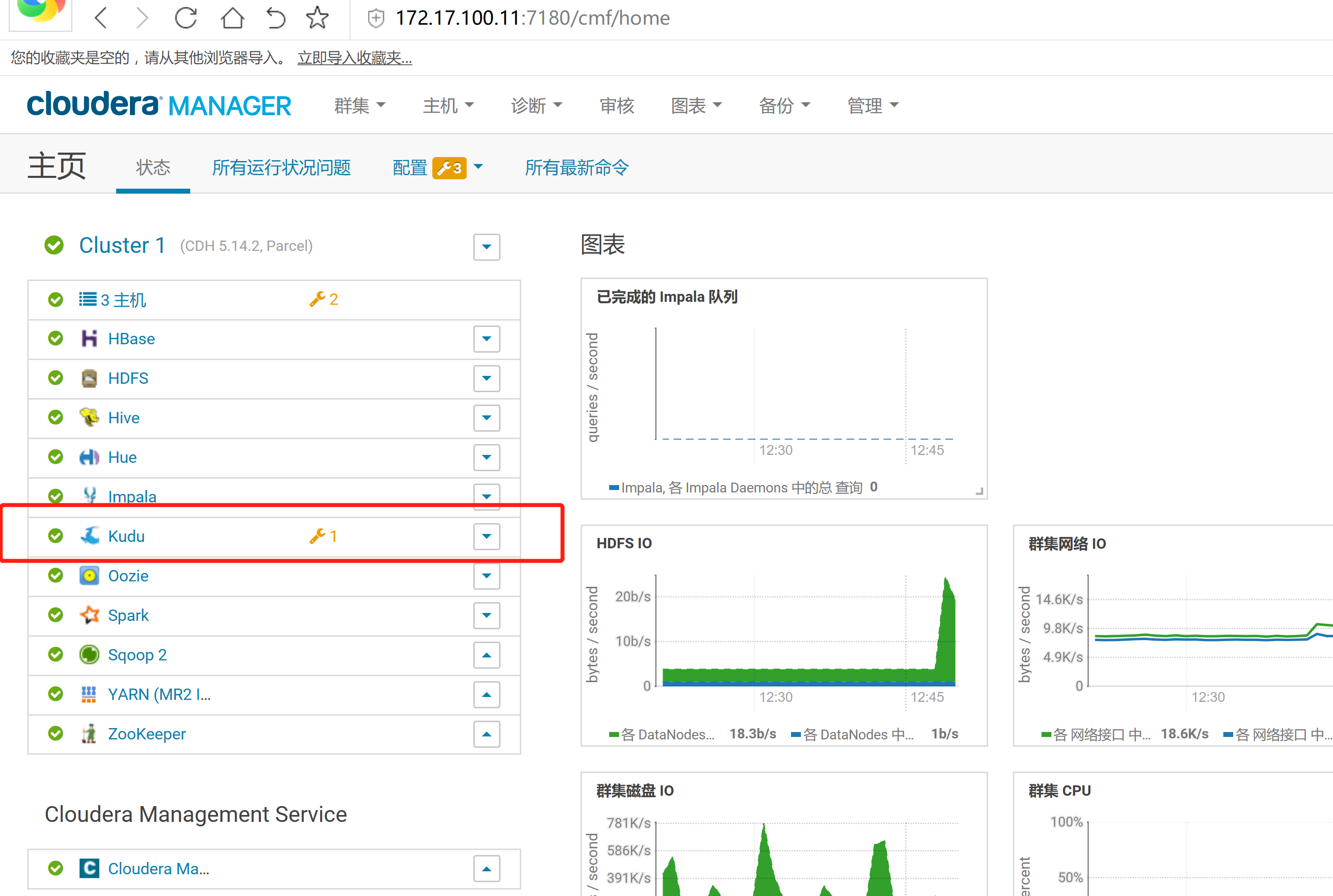
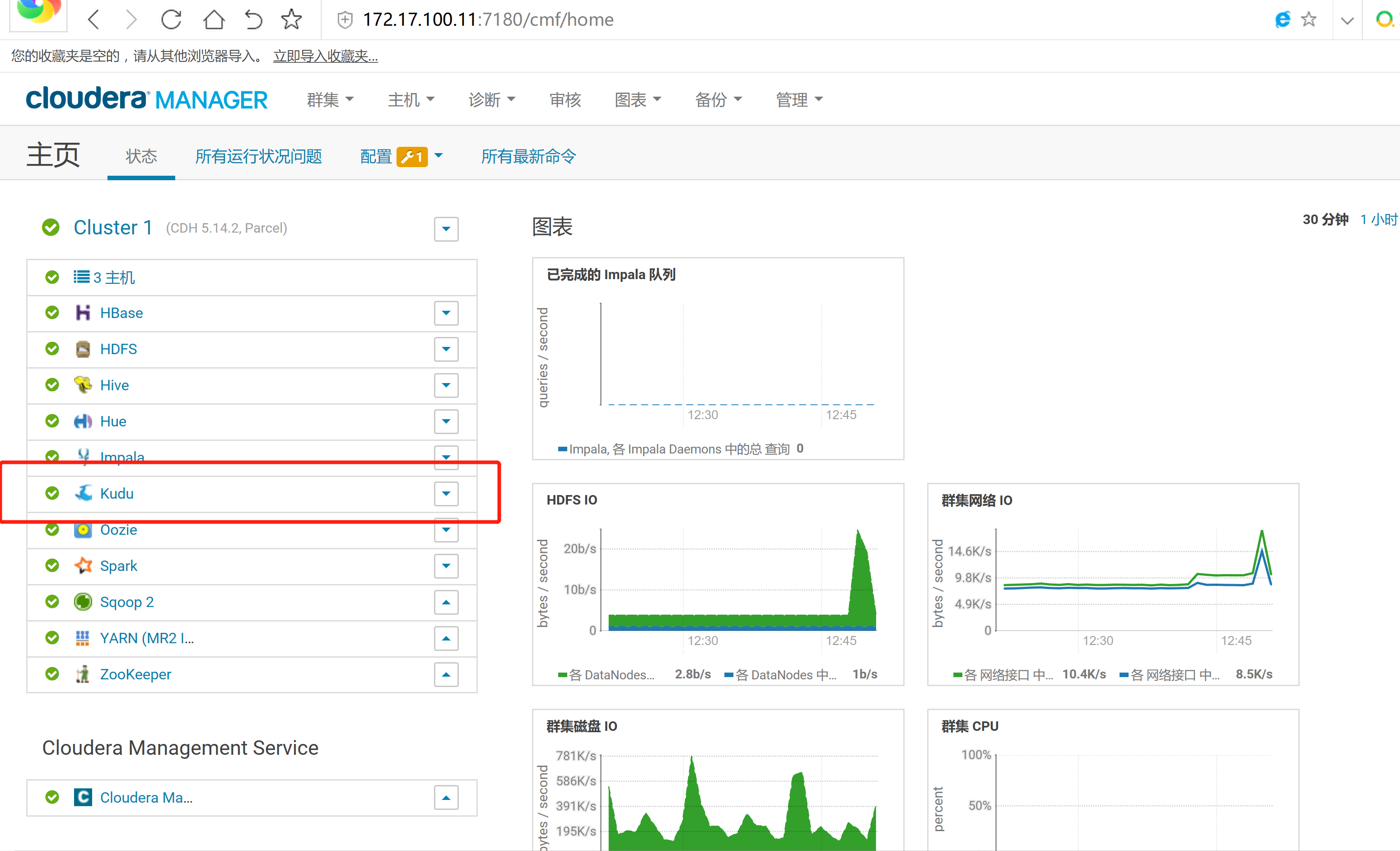
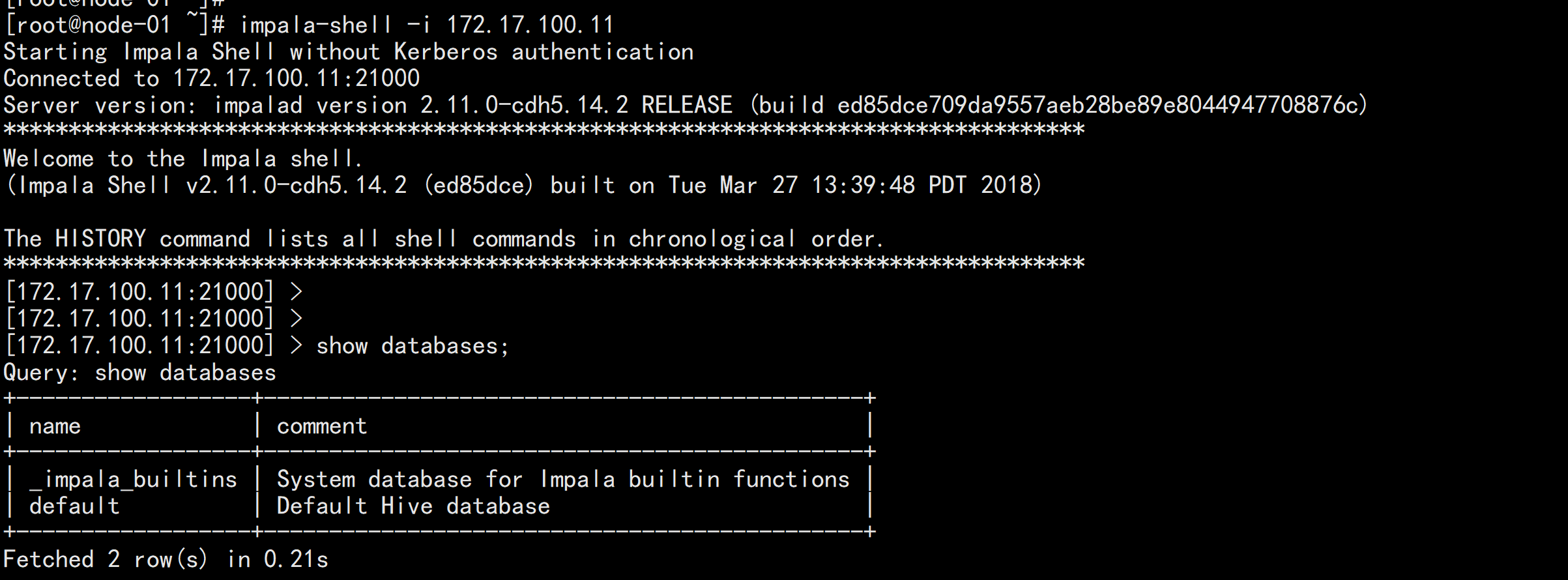
2.4 kudu的驗證: 使用impala 直接創建讀取kudu上面的數據
impala-shell -i 172.17.100.11
create database kudu_test;

use kudu_test;
CREATE TABLE my_first_table
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU;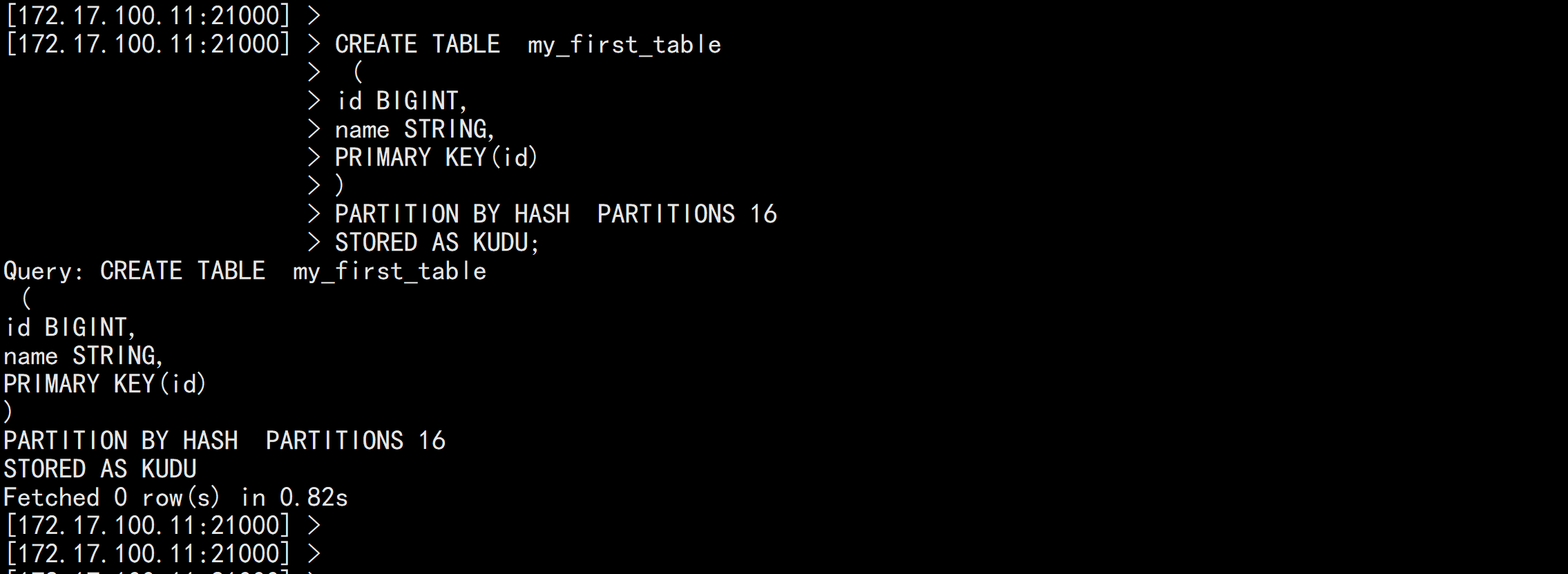
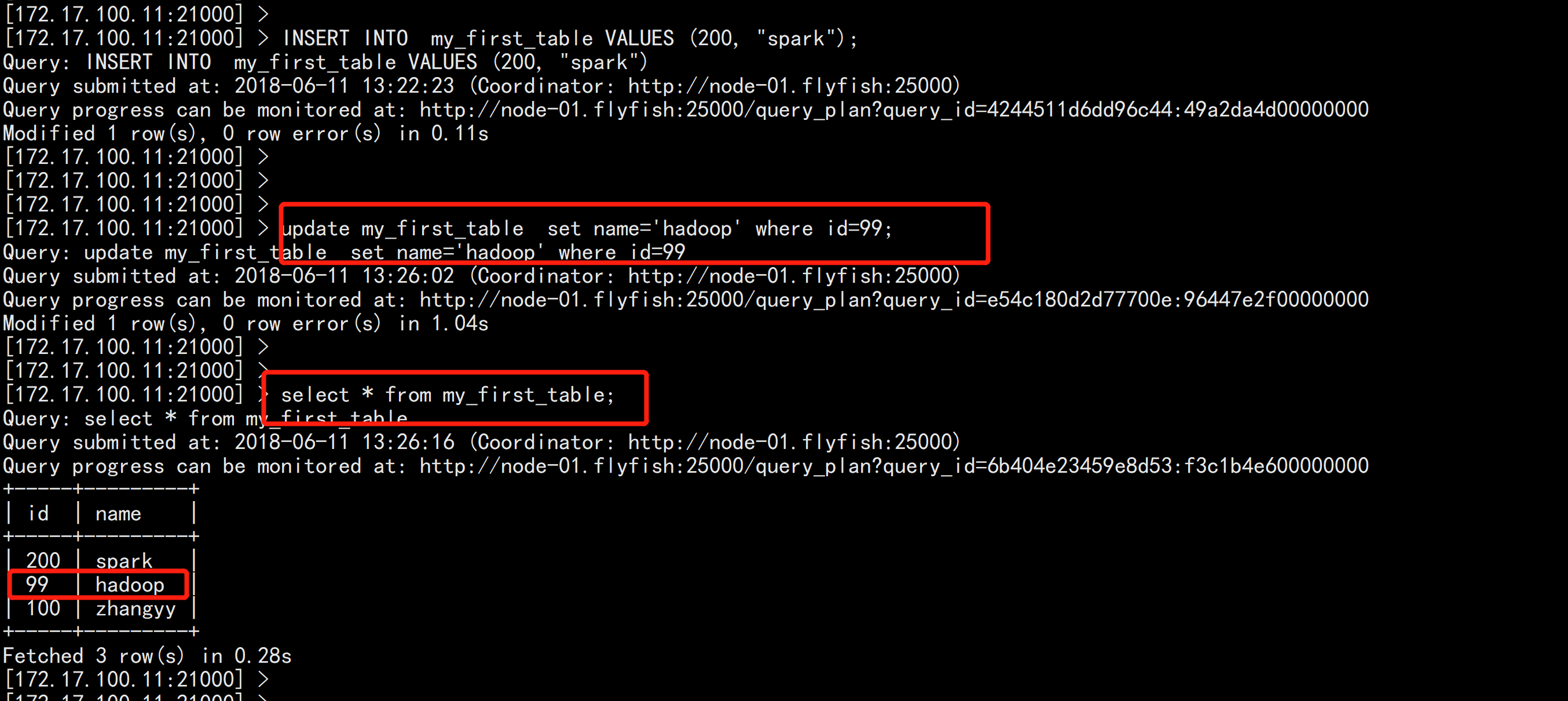
INSERT INTO my_first_table VALUES (99, "sarah");
INSERT INTO my_first_table VALUES (100, "zhangyy");
INSERT INTO my_first_table VALUES (200, "spark");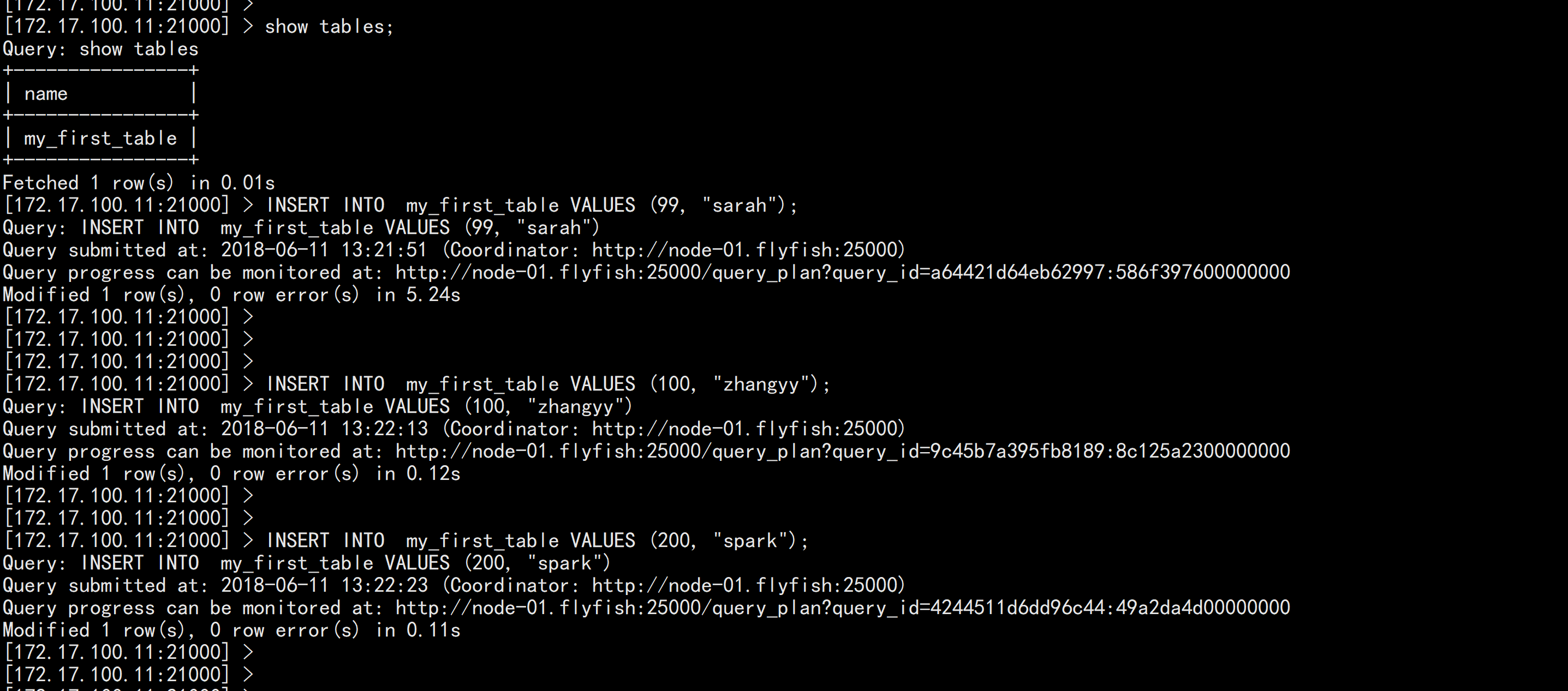
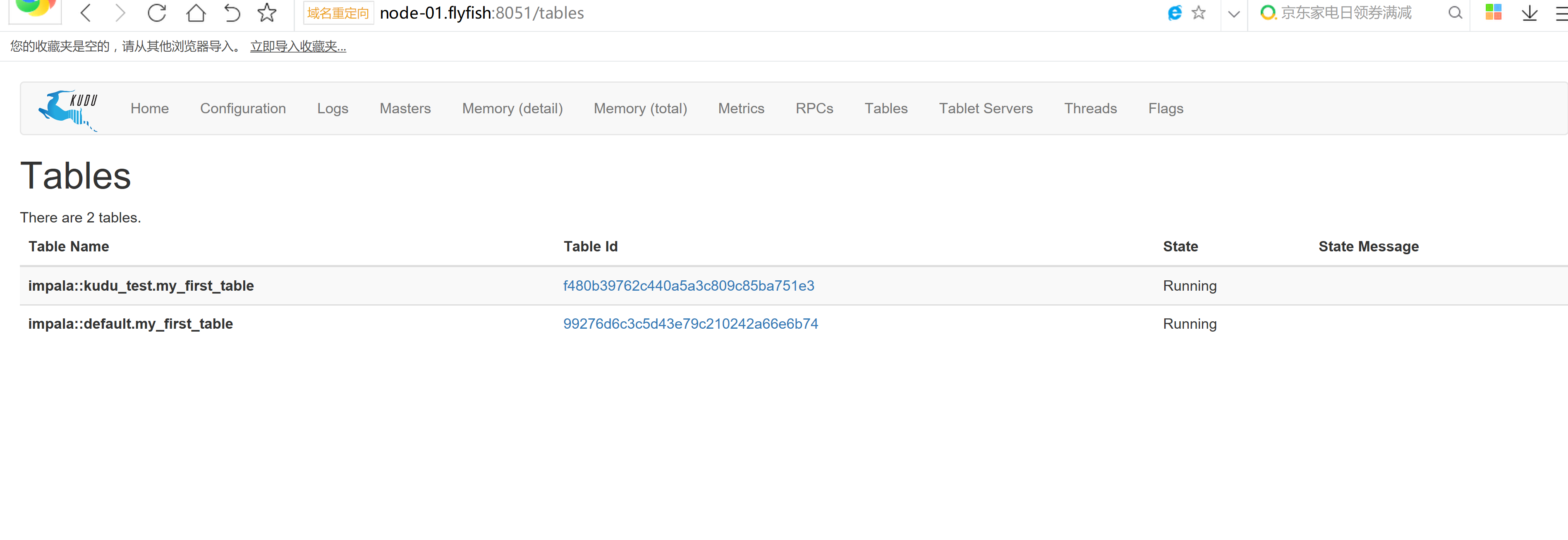
update my_first_table set name='hadoop' where id=99;