




一、聲紋識別簡介
聲紋是指能惟一識別某人或某物的聲音特徵,是用電聲學儀器顯示的攜帶言語信息的聲波頻譜。雖然人的發音器官生理構造總的是相同的,但人的語言產生是人體語言中樞與發音器官之間一個複雜的生理物理過程,人在講話時使用的器官——舌、牙齒、喉頭、肺、鼻腔在尺寸和形態等方面,每兩個人之間的差異會很大(見圖2-1所示)所以任何兩個人的聲紋圖譜都有差異,而對於每個人而言,從十幾歲發育變聲後直到五十多歲,其聲紋基本保持不變。聲紋識別技術正是利用這一特點,將聲音輸入到聲譜儀中,使聲音不同頻率的機械振動變成頻譜圖像,顯示在熒光屏或記錄在紙上,這種圖像就是聲紋。

圖2-1 發音器官
聲紋識別(Voiceprint Recognition,即VPR),通常也被稱爲話者識別(Speaker Recognition),分爲兩類,即話者辨認(Speaker Identification)和話者確認(Speaker Verification)。前者用以判斷某段語音是若干人中的哪一個所說的,是“多選一”問題;而後者用以確認某段語音是否是指定的某個人所說的,是“一對一判別”問題。不同的任務和應用會使用不同的聲紋識別技術,如縮小刑偵範圍時可能需要辨認技術,而銀行交易時則需要確認技術。不管是辨認還是確認,都需要先對說話人的聲紋進行建模,這就是所謂的“訓練”或“學習”過程[7]。聲紋識別過程如圖2-2所示:

圖2-2 聲紋識別過程
聲紋識別可以說有兩個關鍵問題,一是特徵提取,二是模式匹配。特徵提取的任務是提取並選擇對說話人的聲紋具有可分性強、穩定性高等特性的聲學或語言特徵。與語音識別不同,聲紋識別的特徵必須是“個性化”特徵,而說話人識別的特徵對說話人來講必須是“共性特徵”。雖然目前大部分聲紋識別系統用的都是聲學層面的特徵,但是表徵一個人特點的特徵應該是多層面的,包括: (1)與人類的發音機制的解剖學結構有關的聲學特徵(如頻譜、倒頻譜、共振峯、基音、反射係數等等)、鼻音、帶深呼吸音、沙啞音、笑聲等;(2)受社會經濟狀況、受教育水平、出生地等影響的語義、修辭、發音、言語習慣等;(3)個人特點或受父母影響的韻律、節奏、速度、語調、音量等特徵。從利用數學方法可以建模的角度出發,聲紋自動識別模型目前可以使用的特徵包括:(1)聲學特徵(倒頻譜);(2)詞法特徵(說話人相關的詞n-gram,音素n- gram);(3)韻律特徵(利用n-gram描述的基音和能量“姿勢”);(4)語種、方言和口音信息;(5)通道信息(使用何種通道);等等。
對於模式識別,主要有這幾大類方法:(1)模板匹配方法:利用動態時間彎折(DTW)以對準訓練和測試特徵序列,主要用於固定詞組的應用(通常爲文本相關任務);(2)最近鄰方法:訓練時保留所有特徵矢量,識別時對每個矢量都找到訓練矢量中最近的K個,據此進行識別,通常模型存儲和相似計算的量都很大;(3)神經網絡方法:有很多種形式,如多層感知、徑向基函數(RBF)等,可以顯式訓練以區分說話人和其背景說話人,其訓練量很大,且模型的可推廣性不好;(4)隱式馬爾可夫模型(HMM)方法:通常使用單狀態的HMM,或高斯混合模型(GMM),是比較流行的方法,效果比較好;(5)VQ聚類方法(如LBG,K-均值):效果比較好,算法複雜度也不高,和HMM方法配合起來更可以收到更好的效果;(6)多項式分類器方法:有較高的精度,但模型存儲和計算量都比較大。 其中模板匹配法的的要點是,在訓練過程中從每個說話人的訓練語句中提取相應的特徵矢量來描述各個說話人的行爲,在測試階段,從說話人的測試語音信號中用同樣的方法提取測試模板,主要有動態時間規整方法和矢量量化方法。
對說話人確認,還面臨一個兩難選擇問題。通常,表徵說話人確認系統性能的兩個重要參數是錯誤拒絕率和錯誤接受率,前者是拒絕真正說話人而造成的錯誤,後者是接受集外說話人而造成的錯誤,二者與閾值的設定相關。在現有的技術水平下,兩者無法同時達到最小,需要調整閾值來滿足不同應用的需求,比如在需要“易用性”的情況下,可以讓錯誤拒絕率低一些,此時錯誤接受率會增加,從而安全性降低;在對“安全性”要求高的情況下,可以讓錯誤接受率低一些,此時錯誤拒絕率會增加,從而易用性降低。前者可以概括爲“寧錯勿漏”,而後者可以“寧漏勿錯”。我們把真正閾值的調整稱爲“操作點”調整。好的系統應該允許對操作點的自由調整。
聲紋識別有文本相關的(Text-Dependent)和文本無關的(Text-Independent)兩種。與文本有關的聲紋識別系統要求用戶按照規定的內容發音,每個人的聲紋模型逐個被精確地建立,而識別時也必須按規定的內容發音,因此可以達到較好的識別效果,但系統需要用戶配合,如果用戶的發音與規定的內容不符合,則無法正確識別該用戶。而與文本無關的識別系統則不規定說話人的發音內容,模型建立相對困難,但用戶使用方便,可應用範圍較寬。根據特定的任務和應用,兩種是有不同的應用範圍的。比如,在銀行交易時可以使用文本相關的聲紋識別,因爲用戶自己進行交易時是願意配合的;而在刑偵或偵聽應用中則無法使用文本相關的聲紋識別,因爲無法要求犯罪嫌疑人或被偵聽的人配合。
二、MFCC參數(Mel倒譜系統)的提取說明
1、預增強(Pre-Emphasis) :差分語音信號。
2、音框化(Framing) :對語音數據分幀。
3、漢明窗(Hamming Windowing) :對每幀信號加窗,以減小吉布斯效應的影響。
4、快速傅立葉變換(FFT) :將時域信號變換成爲信號的功率譜。
5、三角帶通濾波器(Triangle Filters) :三角濾波器覆蓋的範圍都近似於人耳的一個臨界帶寬,以此來 模擬人耳的掩蔽效應。
6、離散餘弦轉換(DCT) :去除各維信號之間的相關性,將信號映射到低維空間。
三、聲紋提取、識別過程
話者的聲紋提取過程總的分4步:
1、 對輸入的語音數據序列(PCM碼流)進行預處理。
目的:a) 去除非語音信號 和 靜默語音信號;
b) 對語音信號分幀,以供後續處理。
2、 提取每一幀語音信號的MFCC參數 並保存。
3、 用第2步提取的MFCC參數訓練話者的GMM(高斯混合模型),得到專屬某話者的GMM聲紋模型。
4、 聲紋識別。提供輸入話音與GMM聲紋模型的匹配運算函數,以判斷輸入話音是否與聲紋匹配。
一)、 語音數據預處理(去除靜寂聲音)
輸入語音流採用單聲道、8bit、16KHz採樣。
以256個採樣點爲一個音框單位(幀),以128爲音框之間的重迭單位,對輸入語音流進行分幀。
計算各幀語音數據的累積能量E(最大值爲256^3=16777216,用int表示足夠),
![]() ,
,
如果連續語音幀累積能量![]() 大於預設靜音閾值(連續數>100),則採納該段連續語音幀爲訓練語音;
大於預設靜音閾值(連續數>100),則採納該段連續語音幀爲訓練語音;
保留所有可供訓練的語音。
二)、MFCC參數提取
圖1.顯示了MFCC參數提取流程
具體6步:
1) 預增強(Pre-Emphasis)
2) 音框化(Framing)
3) 漢明窗(Hamming Windowing)
4) 快速傅立葉轉換(FFT)
5) 三角帶通濾波器(Triangle Filters)
6) 離散餘弦轉換(DCT)
1) 預增強(Pre-Emphasis)(對原始採樣數據處理,所以N不是256)
以S1(n)(n:0..N-1)表示時域信號,預增強公式爲:
S(n) = S1(n) – a×S1(n-1) (0.9 < a < 1.0)---------------每字節做差分
該過程可以達到在音框化階段對靜音數據的判斷,因爲靜音數據的值是幾乎不變的
所以在做差分以後值會很小,接近於0,而有聲音的數據則會保留較大的值
S(n)=(S1(n)-128)/128
此時還是不分幀的好,這樣就只需要做完幀數據大小一半的差分
差分後必須以short以及比它字節大的有符號類型,因爲差分結果可能爲負,且超過char的範圍,造成溢出
2) 音框化(Framing)
音框化即預處理階段的語音信號分幀。
3) 漢明窗(Hamming Windowing)
假設音框化的信號(M幀共N點)爲S(n),n=0,1,…,N-1。那幺乘上漢明窗後爲:
S′(n) = S(n) ×W(n)
![]() , a = 0.46
, a = 0.46
//即使是重疊處的樣值在漢明窗以後也會不同,因爲n不同

圖1. MFCC參數提取流程
4) 快速傅立葉轉換(FFT)
對S′(n) 的每幀實施基2 FFT時域變換(代碼到網上找)
得到X(n), n = 0..N-1(N=256)
注意X(n)爲複數,所以S′(n) 也要在3)以後轉化爲複數作爲FFT的輸入
5) 三角帶通濾波器(Triangle Filters)
設定16KHz 和 8KHz條件下的濾波器數組 melf16[],melf8[]。
melf[]濾波器數組爲20×129的稀疏矩陣,以結構化數組的方式存儲。
計算每個濾波器輸出的對數能量z[20],計算公式爲:
z[ ] = log ( melf[]*(|X(0:128)|.^2) )--------------------log(m)是以e 爲底m爲真數的對數
同理exp(m)是以e爲底m爲指數的指數
melf[]數組見melf16,melf8
6) 離散餘弦轉換(DCT)
對上一步所獲得的對數能量進行DCT變換,獲得DCT係數數組r[20]
r[] = dct (z[ ]);
dct()變換公式爲
 ,D = 20
,D = 20
r[] 即一幀語音信號的MFCC參數
計算並保存所有各幀語音信號的MFCC參數。
三)、 訓練話者的GMM模型
GMM模型主要公式爲:
(1) ---------------------------------------------------(1-1)
---------------------------------------------------(1-1)
![]() 爲D維隨機矢量,與 r[ ] 對應;
爲D維隨機矢量,與 r[ ] 對應;
![]() 是m組D維高斯概率密度函數;
是m組D維高斯概率密度函數;
![]() 是M組高斯向量的混合數,
是M組高斯向量的混合數,![]() 。
。
(2)D維高斯概率密度函數公式
 ;
;
(3)一個話者的GMM模型由其參數組唯一表示
![]()

圖2. GMM模型圖
GMM模型訓練的目的即得到特定話者的GMM參數組![]() 。
。
步驟爲:
1)、讀入訓練語音的MFCC參數序列,即![]() ;T =訓練語音的總幀數。
;T =訓練語音的總幀數。
2)、設定起始參數值![]()
3)、用期望值最大化算法(簡稱EM),迭代計算![]() ,直至
,直至![]() ,算法停止。得到的
,算法停止。得到的![]() 即爲特定話者GMM參數組。
即爲特定話者GMM參數組。
步驟2)具體算法爲:
![]() ;//這裏表示M個值都取1/M
;//這裏表示M個值都取1/M
![]() 由k-均值算法獲取;用以訓練k-均值的向量數量爲1..T
由k-均值算法獲取;用以訓練k-均值的向量數量爲1..T

圖3. k-均值算法示意圖
 爲協方差矩陣,i = 1,…,M,D是MFCC參數矢量維度=20,爲計算方便,假設其爲對角陣。
爲協方差矩陣,i = 1,…,M,D是MFCC參數矢量維度=20,爲計算方便,假設其爲對角陣。
 ,
,![]() 爲
爲![]() 的一組矢量,共M組。
的一組矢量,共M組。
k-均值算法一次性得到了所有的![]() ,1≤i≤M
,1≤i≤M
步驟3)具體算法爲:
a) 準備好T個訓練向量,記爲![]()
b) 計算事後概率 ,
,![]() 爲上一輪迭代後獲得的GMM參數組。
爲上一輪迭代後獲得的GMM參數組。
公式中![]() 是表示要計算每個訓練向量的事後概率,共計算T個M組的事後概率
是表示要計算每個訓練向量的事後概率,共計算T個M組的事後概率
也就是說每個訓練向量都對應一個M組的事後概率
c) 計算
這裏的pi是M維向量
d) 計算
e) 計算
f) 計算![]() 若是,則迭代訓練結束,得到話者GMM參數組模型,
若是,則迭代訓練結束,得到話者GMM參數組模型,
若否,則令![]() ,返回b)步繼續計算。
,返回b)步繼續計算。
注:
D = 20;
![]()

四)、聲紋識別
假設已訓練了S個(>2)GMM聲紋模型![]() ,現輸入一位話者的語音序列
,現輸入一位話者的語音序列![]() (已經過mfcc參數提取),要求判斷該話者是誰,即語音序列與哪一個聲紋模型匹配。
(已經過mfcc參數提取),要求判斷該話者是誰,即語音序列與哪一個聲紋模型匹配。
用後驗概率計算

由於假定先驗概率相同,故上式可簡化爲求下式:
![]()
該式又近似於下式。。故實際計算中以下式爲準。
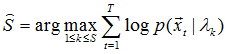
此過程中:![]() 只對大於0的值取log,否則爲0的值將導致最後的累加值可能出現無窮小
只對大於0的值取log,否則爲0的值將導致最後的累加值可能出現無窮小
![]() 即公式(1-1),計算即可。
即公式(1-1),計算即可。
四、驗證實現
採用標準C語言實現:MFCC參數提取,K-means聚類,GMM建模及識別
源碼地址如下:
http://www.openvp.tk
[1] Douglas A. Reynolds, Richard C. Rose. Robust Text-Independent Speaker Identification Using Gaussian
Mixture Speaker Models. IEEE Transactions on Speech and Audio Processing, Vol.3, No.1, January 1993.
[2]郭慧娟.聲紋識別系統研究[D].西華大學碩士學位論文,2006.
[3] 魏凱.聲紋識別中關鍵技術的研究[D].華中科技大學碩士學位論文,2006.
[4] ZhiQiang Wang, Yang Liu, Peng Ding, Xu Bo.Covariance-tied Clustering Method
In Speaker Identification[J].National Laboratory of Pattern Recognition.
Institute of Automation, Chinese Academy of Science Beijing 100080.
[5] 郭皓婷.基於聲紋識別技術的應用難點研究[R].第十四屆全國青年通信學術會議,2009.
[6] 張萬里,劉橋.Mel頻率倒譜系數提取及其在聲紋識別中的作用[J].貴州大學學報,第22卷第2期.
[7] 張廣蘭.聲紋識別的關鍵技術及發展趨勢[J].黑龍江科技學院,黑龍江,哈爾濱,150027.