




近幾年深度學習在物體檢測方面出現了許多基於不同框架的網絡模型,不同模型需要不同的版本的Python、TensorFlow、Keras、CUDA、cuDNN以及操作系統。不得不說,要把經典物體檢測網絡的源碼都跑通,單配置環境就要浪費很多時間,因爲目前兼容這些經典網絡的框架和環境還很少。新版的TensorFlow在models的objection-detection模塊中包含了fast-rcnn、rfcn、SSD幾種網絡,不過開發環境是基於Ubuntu的,因此我對該環境進行了配置。
1.Ubuntu安裝環境選擇
Ubuntu版本很多,首選LTS版本。現在已經有了18.04LTS,裝上後界面豐富好看了,不過在運行Python和TensorFlow環境下的代碼時出現了一些未知問題,有關排故的信息也比較少,所以我重新安裝了16.04LTS。安裝時可先使用深度U盤啓動工具(我使用的是UEFI版)製作Ubuntu啓動盤,然後在電腦安裝,具體過程百度即可。我以前使用的是雙系統安裝,但時間長了以後Ubuntu系統會出問題,有時需要進入grub模式進行修復,操作不當會導致無法進入Windows系統。所以後來我就把兩個系統安裝在兩個硬盤上,啓動時進入引導菜單選擇要進入的硬盤即可,或者啓動前拔掉其中一個硬盤電源線即可。
2.安裝NVIDIA顯卡驅動
首先安裝顯卡驅動。首先看自己顯卡
lspci | grep -i vga
lspci | grep -i nvidia然後看顯卡驅動
lsmod | grep -i nvidiaUbuntu16.04原來安裝的是開源的nouveau驅動,但是CUDA要使用NVIDIA官方驅動,所以要更換顯卡驅動,可點擊 系統設置->軟件與更新->附加驅動->選擇NVIDIA官方驅動,應用更改並重啓即可。借用下圖,其中NVIDIA驅動版本會因顯卡不同而不同。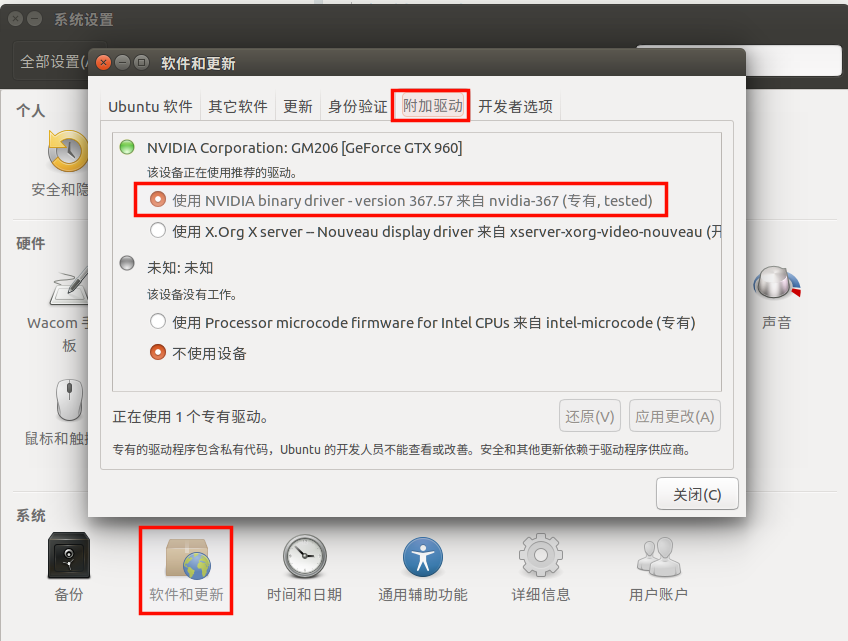
注意:
CUDA官方的安裝指導裏安裝驅動採用是手動禁用nouveau驅動並安裝NVIDIA驅動的方式,需重啓後進入文字界面,並運行bash命令安裝驅動。使用的命令主要有:
sudo apt-get remove --purge nvidia*
sudo gedit /etc/modprobe.d/blacklist.conf
blacklist nouveau
sudo update-initramfs -u
sudo service lightdm stop
sudo sh ./NVIDIA-Linux-x86_64-375.20.run我在安裝過程出現了以下問題。
a. 由於默認驅動禁用、圖形界面無法使用,可能會導致無限重啓、進入登錄界面。
b. 進入文字界面執行命令後出現菱形字符,而命令內容也沒有執行。
所以我採用在Ubuntu系統界面中改變驅動的方法。
c. 在 系統設置->軟件與更新->附加驅動->中顯示空白,沒有出現默認驅動和NVIDIA驅動。這是因爲我的系統由於自動更新導致無法啓動,進入啓動菜單選擇早點的版本,可進入系統但沒有了顯卡驅動信息。重新安裝系統,再查看,出現了顯卡驅動信息,選擇NVIDIA384驅動,然後重啓。
爲避免上述問題,在Ubuntu系統設置中更換顯卡驅動即可。
3.安裝CUDA9.0
Tensorflow1.9以後的版本需要安裝CUDA9.0和cuDNN7.0,否則會出現異常。先下載CUDA9.0安裝文件,借用下圖。安裝步驟可參考官方安裝指導。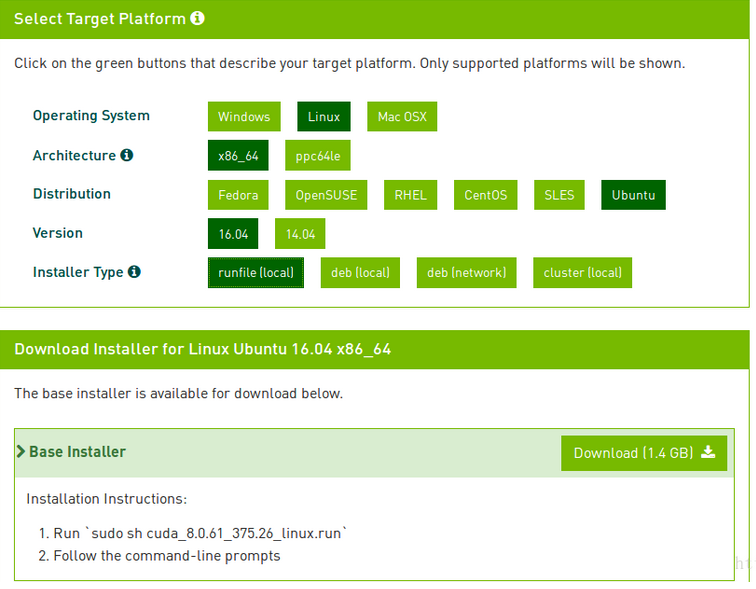
安裝前可做如下準備工作,檢查系統是否可以安裝,Ubuntu16.04可忽略。主要有:
1.驗證自己的電腦是否有一個可以支持CUDA的GPU
在ubuntu的終端中輸入命令:
lspci | grep -i nvidia會顯示出NVIDIA GPU版本信息,然後去CUDA的官網查看自己的GPU版本是否在CUDA的支持列表中。當前GPU基本都支持。
2.驗證自己的Linux版本是否支持 CUDA
輸入命令:
uname -m && cat /etc/*release結果顯示:
x86_64
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=16.04
......
Ubuntu 16.04支持。
3. 驗證系統是否安裝了gcc
在終端中輸入:
gcc –version結果顯示:
gcc (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609
......
若未安裝請使用下列命令進行安裝:
sudo apt-get install build-essential
4. 驗證系統是否安裝了kernel header
a、查看正在運行的系統內核版本:
在終端中輸入:
uname –r結果顯示:
4.10.0-40-generic
Ubuntu16.04不需要安裝
上述檢查完後可運行命令安裝:
sudo dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.deb
sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub
sudo apt-get update
sudo apt-get install cuda在CUDA完成安裝之後,還需要添加環境變量,打開終端,輸入下面的命令:
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}如果是64位系統,輸入:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}如果是32位系統,輸入:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}上述過程完成了整個的CUDA9.0的安裝。
我在安裝過程報錯如下:
下列軟件包有未滿足的依賴關係: cuda : 依賴: cuda-9-0 (>= 9.0.176) 但是它將不會被安裝
經檢查是因爲我關閉了Ubuntu的自動更新,打開後重新運行即可,如下圖。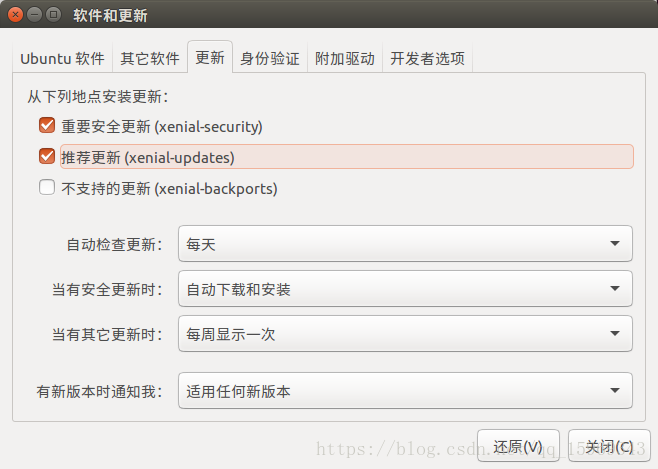
同時將附加驅動中的更新也打開。
4. 安裝cuDNN
cuDNN v7.0,下載地址,可用之前下載CUDA註冊的郵箱登錄。
進入之後點擊Download,之後進入下載界面,選擇上I Agree To the Terms of the cuDNN Software License Agreement的複選框,一次要選擇上正確的版本。
我選擇的是deb文件,下載界面選擇的文件名爲:
cuDNN v7.0.5 Runtime Library for Ubuntu16.04 (Deb)
下載後進入下載目錄,打開終端,之後輸入以下命令:
sudo dpkg -i libcudnn7_7.0.5.15-1+cuda9.0_amd64.deb
注意,上述命令中的可能會由於cudnn版本的細微差異而不同,注意tab鍵補齊就行。之後等待完成cuDNN的安裝。
安裝完成後可測試CUDA的Samples。
cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery如果顯示的是如下圖關於GPU的信息,則說明安裝成功了。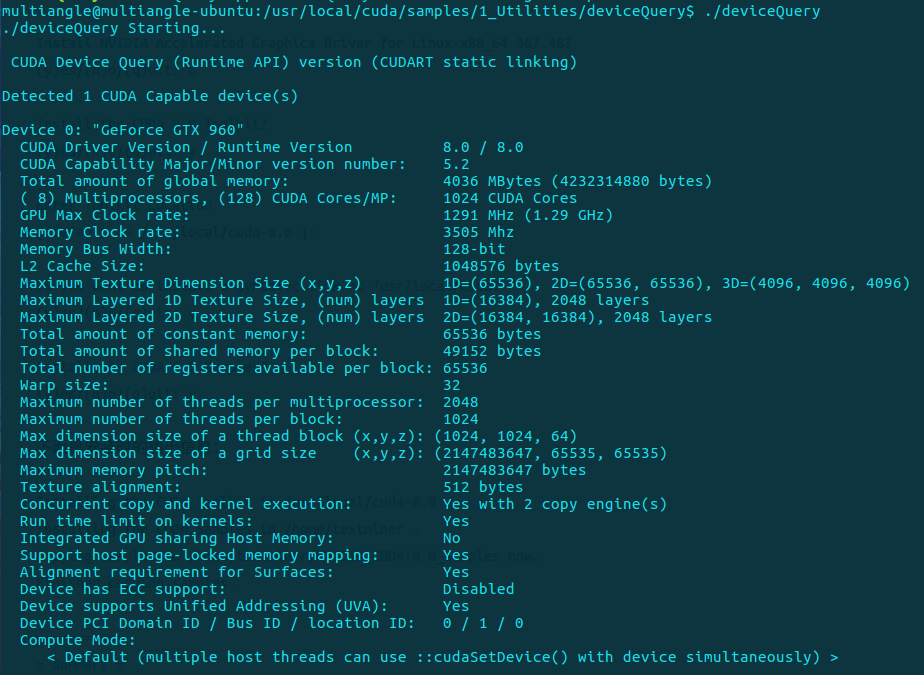
5. 安裝Anaconda
Anaconda版本與對應的Python版本列表如下。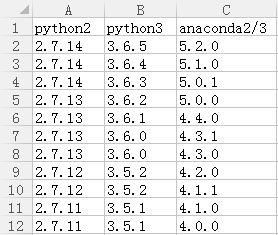
tensorflow1.5~1.10使用cuda9.0和cudnn7.0.5。我安裝的是5.2.0,在官網下載文件,使用bash命令即可安裝。如:
bash anaconda5.2.sh這裏的安裝文件名爲了便於安裝已修改。
6. 安裝tensorflow-gpu
爲便於安裝包導入時不出錯,我在虛擬環境中安裝tensorflow-gpu及其他相關包。使用conda新建虛擬環境。conda常用的命令有:
conda list #查看安裝了哪些包
conda env list 或 conda info -e #查看當前存在哪些虛擬環境
conda update conda #檢查更新當前conda創建Python虛擬環境。
conda create -n env_name python=X.X(2.7、3.6等)該命令 命令創建python版本爲X.X、名字爲env_name的虛擬環境。env_name文件可以在Anaconda安裝目錄envs文件下找到。可以指定python版本爲2.7,也可以不指定,如:
conda create -n tf13也在可創建虛擬環境時同時安裝必要的包,如:
conda create -n env_name numpy matplotlib激活(或切換不同python版本)虛擬環境。
source activate env_name(虛擬環境名稱)Windows下命令爲:
activate env_name(虛擬環境名稱)對虛擬環境中安裝額外的包,可使用命令conda install -n env_name [package],即可安裝package到env_name中
關閉虛擬環境:
source deactivate Windows下爲:
deactivate env_name刪除虛擬環境:
conda remove -n env_name --all刪除環境中的某個包:
conda remove --name env_name package_name創建虛擬環境後,進入該環境目錄,安裝tensorflow-gpu。由於一些源碼要求tensorflow1.9.0以上版本,我安裝該版本:
pip install tensorflow-gpu==1.9.0安裝後,終端輸入python,進入python命令行後輸入:
import tensorflow as tf沒有報錯表示安裝成功。
但在spyder中創建python文件,運行深度網絡代碼時提示:
SymbolAlreadyExposedError: Symbol unittest.mock is already exposed as ('test.mock',).
這是由於tensorflow更新過程結構有變化,不適合所運行的代碼。卸載tensorflow-gpu1.9.0,重新安裝,不指定版本。
pip install tensorflow-gpu重新運行python文件,不報錯。查看版本,發現安裝的是tensorflow-gpu1.3.0。
7.設置國內鏡像
如果需要安裝很多packages,conda下載的速度很慢,因爲Anaconda.org的服務器在國外。清華TUNA鏡像源有Anaconda倉庫的鏡像。可將其加入conda的配置:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes #設置搜索時顯示通道地址pip安裝也可設爲通過修改配置文件,使用國內鏡像。
# 如果不存在此文件夾,則創建之
mkdir ~/.pip
vi ~/.pip/pip.conf添加如下內容
[global]
index-url=http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
如果只需要單次使用鏡像,可在安裝命令後加上鏡像名:
sudo pip install tensorflow-gpu==1.9.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/8. 在虛擬環境下安裝Spyder和Jupyter
安裝Anaconda後,運行Spyder會出現黑屏,Spyder界面沒有出現。排除方法如下:
cd /etc/ld.so.conf.d目錄中有 i386-linux-gnu_GL.conf and x86_64-linux-gnu_GL.conf等文件,打開後者添加驅動,運行如下代碼:
cat x86_64-linux-gnu_GL.conf
/usr/lib/nvidia-340
/usr/lib32/nvidia-340但是文件i386-linux-gnu_GL.conf 是空文件,這時需要把 x86_64-linux-gnu_GL.conf中的內容複製到i386-linux-gnu_GL.conf
sudo gedit i386-linux-gnu_GL.conf 把兩行內容複製,粘貼,保存,關閉。
sudo ldconfig注意:需要root權限,重啓spyder, ok
這時雖然出現了界面,但在運行導入TensorFlow·語句時會報錯,提示無法導入。這是因爲Ubuntu在使用pip安裝時把安裝包安裝在了自帶的Python2.7的默認位置。爲使用方便我在虛擬環境中安裝TensorFlow和spyder、jupyter,安裝spyder和jupyter代碼如下:
sudo pip install jupyter
或conda install jupyter這樣就不會提示導入出錯。使用jupyter是執行
jupyter notebook即可。這時會打開默認位置的文件,如需永久改變打開位置需修改jupyter配置文件,如臨時改變打開位置,在命令後加上文件路徑即可。
9. 在虛擬環境下安裝相關包
Ubuntu默認安裝了Python2.7,如果不切換安裝目錄,即使激活了虛擬環境,安裝時仍然會將包安裝在默認位置。所以最好將將相關的包安裝至虛擬環境所在的目錄。不管是conda 還是pip,都要先切換至虛擬環境所在的目錄,再用命令安裝。例如spyder和jupyter都需要在該目錄下重新安裝,否則會提示無法導入tensoflow等導入的包。
安裝完成後可新建syder文件輸入以下代碼驗證:
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
out = sess.run(hello)
a = tf.constant(10)
b = tf.constant(32)
sess.run(a+b)輸出正常結果即可。
10. 實時查看GPU使用率
在Windows下可使用魯大師的軟件在狀態欄實時顯示GPU狀態信息。Ubuntu下可使用nvidia-smi命令,
輸出結果借用下圖,具體數字會有不同。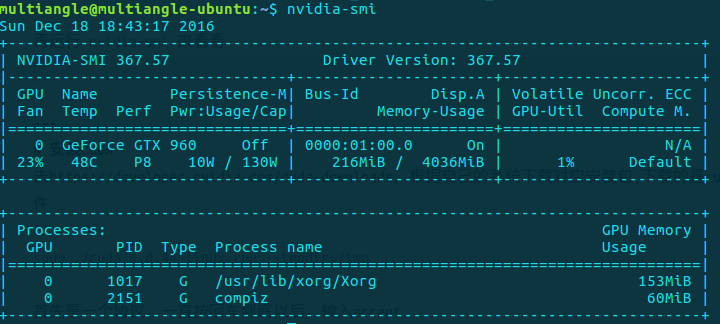
顯示結果含義爲:
第一行Driver Version表示驅動的版本。
第二行表示GPU序號,名字,Persisitence-M(持續模式狀態)。如只有一個GPU,號爲0,名字爲GeForce系列的GTX960,持續模式的狀態,持續模式雖然耗能大,但是在新的GPU應用啓動時,花費的時間更少,這裏顯示的是off的狀態。
第三行字段如下:
Fan:N/A是風扇的轉速,從0到100%之間變動。有的nvidia設備如筆記本,tesla系列不是主動散熱的可能顯示不了轉速。
Temp:溫度,48攝氏度。
Perf:是性能狀態,從P0到P12,P0表示最大性能,P12表示最小性能地;
Pwr表示能耗;
Bus-Id是表示GPU總線類型;
Disp.A是DisPlay Active ,表示GPU是否有初始化
Memory-Usage表示顯存的使用率;
Volatile GPU-Util表示GPU的利用率;
Uncorr.ECC是表示ECC的相關東西,ECC即 Error Correcting Code 錯誤檢查和糾正,在服務器和工作站上的內存中才有的技術。
但是這個命令只能顯示一次,如果要實時顯示,配合watch命令, 讓一秒刷新一次,可輸入:
watch -n 1 nvidia-smi11. 在ubuntu上卸載anaconda的
如果要卸載Anaconda,其步驟爲:
a. 刪除整個anaconda目錄
由於Anaconda的安裝文件都包含在一個目錄中,所以直接將該目錄刪除即可。到包含整個anaconda目錄的文件夾下,刪除整個Anaconda目錄:
sudo rm -rf anaconda文件夾名b. 清理下.bashrc中的Anaconda
1.到根目錄下,打開終端並輸入:
sudo gedit ~/.bashrc2.在.bashrc文件末尾用#號註釋掉之前添加的路徑(或直接刪除):
#export PATH=/home/lq/anaconda3/bin:$PATH
保存並關閉文件
3.使其立即生效,在終端執行:
source ~/.bashrc4.關閉終端,然後再重啓一個新的終端,這一步很重要,不然在原終端上還是綁定有anaconda。