




相比 Spark Stream、Kafka Stream、Storm 等,爲什麼阿里會選擇 Flink 作爲新一代流式計算引擎?前期經過了哪些調研和對比?
大沙:我們是 2015 年開始調研新一代流計算引擎的。我們當時的目標就是要設計一款低延遲、exactly once、流和批統一的,能夠支撐足夠大體量的複雜計算的引擎。Spark streaming 的本質還是一款基於 microbatch 計算的引擎。這種引擎一個天生的缺點就是每個 microbatch 的調度開銷比較大,當我們要求越低的延遲時,額外的開銷就越大。這就導致了 spark streaming 實際上不是特別適合於做秒級甚至亞秒級的計算。
Kafka streaming 是從一個日誌系統做起來的,它的設計目標是足夠輕量,足夠簡潔易用。這一點很難滿足我們對大體量的複雜計算的需求。
Storm 是一個沒有批處理能力的數據流處理器,除此之外 Storm 只提供了非常底層的 API,用戶需要自己實現很多複雜的邏輯。另外,Storm 在當時不支持 exactly once。種種原因,Storm 也無法滿足我們的需求。
最後,我們發現了 Flink,並且驚喜地發現它幾乎完美滿足了我們所有的需求:
a) 不同於 Spark,Flink 是一個真正意義上的流計算引擎,和 Storm 類似,Flink 是通過流水線數據傳輸實現低延遲的流處理;
b) Flink 使用了經典的 Chandy-Lamport 算法,能夠在滿足低延遲和低 failover 開銷的基礎之上,完美地解決 exactly once 的目標;
c)如果要用一套引擎來統一流處理和批處理,那就必須以流處理引擎爲基礎。Flink 還提供了 SQL/tableAPI 這兩個 API,爲批和流在 query 層的統一又鋪平了道路。因此 Flink 是最合適的批和流統一的引擎;
d) 最後,Flink 在設計之初就非常在意性能相關的任務狀態 state 和流控等關鍵技術的設計,這些都使得用 Flink 執行復雜的大規模任務時性能更勝一籌。
Apache Flink(下簡稱Flink)項目是大數據處理領域最近冉冉升起的一顆新星,其不同於其他大數據項目的諸多特性吸引了越來越多人的關注。本文將深入分析Flink的一些關鍵技術與特性,希望能夠幫助讀者對Flink有更加深入的瞭解,對其他大數據系統開發者也能有所裨益。本文假設讀者已對MapReduce、Spark及Storm等大數據處理框架有所瞭解,同時熟悉流處理與批處理的基本概念。
Flink簡介
Flink核心是一個流式的數據流執行引擎,其針對數據流的分佈式計算提供了數據分佈、數據通信以及容錯機制等功能。基於流執行引擎,Flink提供了諸多更高抽象層的API以便用戶編寫分佈式任務:
DataSet API, 對靜態數據進行批處理操作,將靜態數據抽象成分佈式的數據集,用戶可以方便地使用Flink提供的各種操作符對分佈式數據集進行處理,支持Java、Scala和Python。 DataStream API,對數據流進行流處理操作,將流式的數據抽象成分佈式的數據流,用戶可以方便地對分佈式數據流進行各種操作,支持Java和Scala。 Table API,對結構化數據進行查詢操作,將結構化數據抽象成關係表,並通過類SQL的DSL對關係表進行各種查詢操作,支持Java和Scala。
此外,Flink還針對特定的應用領域提供了領域庫,例如:
Flink ML,Flink的機器學習庫,提供了機器學習Pipelines API並實現了多種機器學習算法。 Gelly,Flink的圖計算庫,提供了圖計算的相關API及多種圖計算算法實現。
Flink的技術棧如圖1所示:
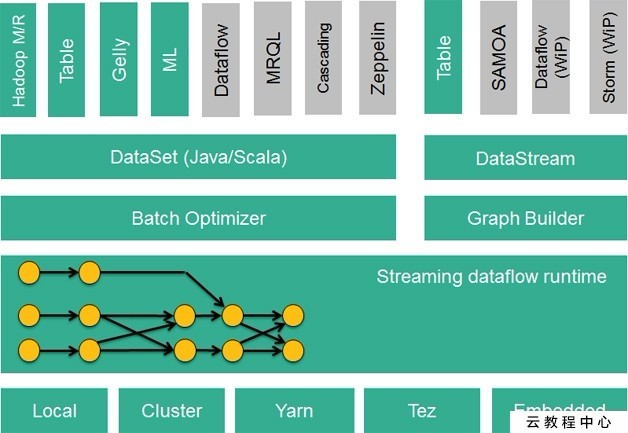
圖1 Flink技術棧
此外,Flink也可以方便地和Hadoop生態圈中其他項目集成,例如Flink可以讀取存儲在HDFS或HBase中的靜態數據,以Kafka作爲流式的數據源,直接重用MapReduce或Storm代碼,或是通過YARN申請集羣資源等。
統一的批處理與流處理系統
在大數據處理領域,批處理任務與流處理任務一般被認爲是兩種不同的任務,一個大數據項目一般會被設計爲只能處理其中一種任務,例如Apache Storm、Apache Smaza只支持流處理任務,而Aapche MapReduce、Apache Tez、Apache Spark只支持批處理任務。Spark Streaming是Apache Spark之上支持流處理任務的子系統,看似一個特例,實則不然——Spark Streaming採用了一種micro-batch的架構,即把輸入的數據流切分成細粒度的batch,併爲每一個batch數據提交一個批處理的Spark任務,所以Spark Streaming本質上還是基於Spark批處理系統對流式數據進行處理,和Apache Storm、Apache Smaza等完全流式的數據處理方式完全不同。通過其靈活的執行引擎,Flink能夠同時支持批處理任務與流處理任務。
在執行引擎這一層,流處理系統與批處理系統最大不同在於節點間的數據傳輸方式。對於一個流處理系統,其節點間數據傳輸的標準模型是:當一條數據被處理完成後,序列化到緩存中,然後立刻通過網絡傳輸到下一個節點,由下一個節點繼續處理。而對於一個批處理系統,其節點間數據傳輸的標準模型是:當一條數據被處理完成後,序列化到緩存中,並不會立刻通過網絡傳輸到下一個節點,當緩存寫滿,就持久化到本地硬盤上,當所有數據都被處理完成後,纔開始將處理後的數據通過網絡傳輸到下一個節點。這兩種數據傳輸模式是兩個極端,對應的是流處理系統對低延遲的要求和批處理系統對高吞吐量的要求。Flink的執行引擎採用了一種十分靈活的方式,同時支持了這兩種數據傳輸模型。Flink以固定的緩存塊爲單位進行網絡數據傳輸,用戶可以通過緩存塊超時值指定緩存塊的傳輸時機。如果緩存塊的超時值爲0,則Flink的數據傳輸方式類似上文所提到流處理系統的標準模型,此時系統可以獲得最低的處理延遲。如果緩存塊的超時值爲無限大,則Flink的數據傳輸方式類似上文所提到批處理系統的標準模型,此時系統可以獲得最高的吞吐量。同時緩存塊的超時值也可以設置爲0到無限大之間的任意值。緩存塊的超時閾值越小,則Flink流處理執行引擎的數據處理延遲越低,但吞吐量也會降低,反之亦然。通過調整緩存塊的超時閾值,用戶可根據需求靈活地權衡系統延遲和吞吐量。
圖2 Flink執行引擎數據傳輸模式
在統一的流式執行引擎基礎上,Flink同時支持了流計算和批處理,並對性能(延遲、吞吐量等)有所保障。相對於其他原生的流處理與批處理系統,並沒有因爲統一執行引擎而受到影響從而大幅度減輕了用戶安裝、部署、監控、維護等成本。
Flink流處理的容錯機制
對於一個分佈式系統來說,單個進程或是節點崩潰導致整個Job失敗是經常發生的事情,在異常發生時不會丟失用戶數據並能自動恢復纔是分佈式系統必須支持的特性之一。本節主要介紹Flink流處理系統任務級別的容錯機制。
批處理系統比較容易實現容錯機制,由於文件可以重複訪問,當某個任務失敗後,重啓該任務即可。但是到了流處理系統,由於數據源是無限的數據流,從而導致一個流處理任務執行幾個月的情況,將所有數據緩存或是持久化,留待以後重複訪問基本上是不可行的。Flink基於分佈式快照與可部分重發的數據源實現了容錯。用戶可自定義對整個Job進行快照的時間間隔,當任務失敗時,Flink會將整個Job恢復到最近一次快照,並從數據源重發快照之後的數據。Flink的分佈式快照實現借鑑了Chandy和Lamport在1985年發表的一篇關於分佈式快照的論文,其實現的主要思想如下:
按照用戶自定義的分佈式快照間隔時間,Flink會定時在所有數據源中插入一種特殊的快照標記消息,這些快照標記消息和其他消息一樣在DAG中流動,但是不會被用戶定義的業務邏輯所處理,每一個快照標記消息都將其所在的數據流分成兩部分:本次快照數據和下次快照數據。
圖3 Flink包含快照標記消息的消息流
快照標記消息沿着DAG流經各個操作符,當操作符處理到快照標記消息時,會對自己的狀態進行快照,並存儲起來。當一個操作符有多個輸入的時候,Flink會將先抵達的快照標記消息及其之後的消息緩存起來,當所有的輸入中對應該次快照的快照標記消息全部抵達後,操作符對自己的狀態快照並存儲,之後處理所有快照標記消息之後的已緩存消息。操作符對自己的狀態快照並存儲可以是異步與增量的操作,並不需要阻塞消息的處理。分佈式快照的流程如圖4所示:
圖4 Flink分佈式快照流程圖
當所有的Data Sink(終點操作符)都收到快照標記信息並對自己的狀態快照和存儲後,整個分佈式快照就完成了,同時通知數據源釋放該快照標記消息之前的所有消息。若之後發生節點崩潰等異常情況時,只需要恢復之前存儲的分佈式快照狀態,並從數據源重發該快照以後的消息就可以了。
Exactly-Once是流處理系統需要支持的一個非常重要的特性,它保證每一條消息只被流處理系統處理一次,許多流處理任務的業務邏輯都依賴於Exactly-Once特性。相對於At-Least-Once或是At-Most-Once, Exactly-Once特性對流處理系統的要求更爲嚴格,實現也更加困難。Flink基於分佈式快照實現了Exactly-Once特性。
相對於其他流處理系統的容錯方案,Flink基於分佈式快照的方案在功能和性能方面都具有很多優點,包括:
低延遲。由於操作符狀態的存儲可以異步,所以進行快照的過程基本上不會阻塞消息的處理,因此不會對消息延遲產生負面影響。 高吞吐量。當操作符狀態較少時,對吞吐量基本沒有影響。當操作符狀態較多時,相對於其他的容錯機制,分佈式快照的時間間隔是用戶自定義的,所以用戶可以權衡錯誤恢復時間和吞吐量要求來調整分佈式快照的時間間隔。 與業務邏輯的隔離。Flink的分佈式快照機制與用戶的業務邏輯是完全隔離的,用戶的業務邏輯不會依賴或是對分佈式快照產生任何影響。 錯誤恢復代價。分佈式快照的時間間隔越短,錯誤恢復的時間越少,與吞吐量負相關。
Flink流處理的時間窗口
對於流處理系統來說,流入的消息不存在上限,所以對於聚合或是連接等操作,流處理系統需要對流入的消息進行分段,然後基於每一段數據進行聚合或是連接。消息的分段即稱爲窗口,流處理系統支持的窗口有很多類型,最常見的就是時間窗口,基於時間間隔對消息進行分段處理。本節主要介紹Flink流處理系統支持的各種時間窗口。
對於目前大部分流處理系統來說,時間窗口一般是根據Task所在節點的本地時鐘進行切分,這種方式實現起來比較容易,不會產生阻塞。但是可能無法滿足某些應用需求,比如:
消息本身帶有時間戳,用戶希望按照消息本身的時間特性進行分段處理。
由於不同節點的時鐘可能不同,以及消息在流經各個節點的延遲不同,在某個節點屬於同一個時間窗口處理的消息,流到下一個節點時可能被切分到不同的時間窗口中,從而產生不符合預期的結果。
Flink支持3種類型的時間窗口,分別適用於用戶對於時間窗口不同類型的要求:
Operator Time。根據Task所在節點的本地時鐘來切分的時間窗口。
Event Time。消息自帶時間戳,根據消息的時間戳進行處理,確保時間戳在同一個時間窗口的所有消息一定會被正確處理。由於消息可能亂序流入Task,所以Task需要緩存當前時間窗口消息處理的狀態,直到確認屬於該時間窗口的所有消息都被處理,纔可以釋放,如果亂序的消息延遲很高會影響分佈式系統的吞吐量和延遲。
Ingress Time。有時消息本身並不帶有時間戳信息,但用戶依然希望按照消息而不是節點時鐘劃分時間窗口,例如避免上面提到的第二個問題,此時可以在消息源流入Flink流處理系統時自動生成增量的時間戳賦予消息,之後處理的流程與Event Time相同。Ingress Time可以看成是Event Time的一個特例,由於其在消息源處時間戳一定是有序的,所以在流處理系統中,相對於Event Time,其亂序的消息延遲不會很高,因此對Flink分佈式系統的吞吐量和延遲的影響也會更小。
Event Time時間窗口的實現
Flink借鑑了Google的MillWheel項目,通過WaterMark來支持基於Event Time的時間窗口。
當操作符通過基於Event Time的時間窗口來處理數據時,它必須在確定所有屬於該時間窗口的消息全部流入此操作符後才能開始數據處理。但是由於消息可能是亂序的,所以操作符無法直接確認何時所有屬於該時間窗口的消息全部流入此操作符。WaterMark包含一個時間戳,Flink使用WaterMark標記所有小於該時間戳的消息都已流入,Flink的數據源在確認所有小於某個時間戳的消息都已輸出到Flink流處理系統後,會生成一個包含該時間戳的WaterMark,插入到消息流中輸出到Flink流處理系統中,Flink操作符按照時間窗口緩存所有流入的消息,當操作符處理到WaterMark時,它對所有小於該WaterMark時間戳的時間窗口數據進行處理併發送到下一個操作符節點,然後也將WaterMark發送到下一個操作符節點。
爲了保證能夠處理所有屬於某個時間窗口的消息,操作符必須等到大於這個時間窗口的WaterMark之後才能開始對該時間窗口的消息進行處理,相對於基於Operator Time的時間窗口,Flink需要佔用更多內存,且會直接影響消息處理的延遲時間。對此,一個可能的優化措施是,對於聚合類的操作符,可以提前對部分消息進行聚合操作,當有屬於該時間窗口的新消息流入時,基於之前的部分聚合結果繼續計算,這樣的話,只需緩存中間計算結果即可,無需緩存該時間窗口的所有消息。
對於基於Event Time時間窗口的操作符來說,流入WaterMark的時間戳與當前節點的時鐘一致是最簡單理想的狀況,但是在實際環境中是不可能的,由於消息的亂序以及前面節點處理效率的不同,總是會有某些消息流入時間大於其本身的時間戳,真實WaterMark時間戳與理想情況下WaterMark時間戳的差別稱爲Time Skew,如圖5所示:
圖5 WaterMark的Time Skew圖
Time Skew決定了該WaterMark與上一個WaterMark之間的時間窗口所有數據需要緩存的時間,Time Skew時間越長,該時間窗口數據的延遲越長,佔用內存的時間也越長,同時會對流處理系統的吞吐量產生負面影響。
基於時間戳的排序
在流處理系統中,由於流入的消息是無限的,所以對消息進行排序基本上被認爲是不可行的。但是在Flink流處理系統中,基於WaterMark,Flink實現了基於時間戳的全局排序。排序的實現思路如下:排序操作符緩存所有流入的消息,當其接收到WaterMark時,對時間戳小於該WaterMark的消息進行排序,併發送到下一個節點,在此排序操作符中釋放所有時間戳小於該WaterMark的消息,繼續緩存流入的消息,等待下一個WaterMark觸發下一次排序。
由於WaterMark保證了在其之後不會出現時間戳比它小的消息,所以可以保證排序的正確性。需要注意的是,如果排序操作符有多個節點,只能保證每個節點的流出消息是有序的,節點之間的消息不能保證有序,要實現全局有序,則只能有一個排序操作符節點。
通過支持基於Event Time的消息處理,Flink擴展了其流處理系統的應用範圍,使得更多的流處理任務可以通過Flink來執行。
定製的內存管理
Flink項目基於Java及Scala等JVM語言,JVM本身作爲一個各種類型應用的執行平臺,其對Java對象的管理也是基於通用的處理策略,其垃圾回收器通過估算Java對象的生命週期對Java對象進行有效率的管理。
針對不同類型的應用,用戶可能需要針對該類型應用的特點,配置針對性的JVM參數更有效率的管理Java對象,從而提高性能。這種JVM調優的黑魔法需要用戶對應用本身及JVM的各參數有深入瞭解,極大地提高了分佈式計算平臺的調優門檻。Flink框架本身瞭解計算邏輯每個步驟的數據傳輸,相比於JVM垃圾回收器,其瞭解更多的Java對象生命週期,從而爲更有效率地管理Java對象提供了可能。
JVM存在的問題
Java對象開銷
相對於c/c++等更加接近底層的語言,Java對象的存儲密度相對偏低,例如[1],“abcd”這樣簡單的字符串在UTF-8編碼中需要4個字節存儲,但採用了UTF-16編碼存儲字符串的Java則需要8個字節,同時Java對象還有header等其他額外信息,一個4字節字符串對象在Java中需要48字節的空間來存儲。對於大部分的大數據應用,內存都是稀缺資源,更有效率地內存存儲,意味着CPU數據訪問吞吐量更高,以及更少磁盤落地的存在。
對象存儲結構引發的cache miss
爲了緩解CPU處理速度與內存訪問速度的差距[2],現代CPU數據訪問一般都會有多級緩存。當從內存加載數據到緩存時,一般是以cache line爲單位加載數據,所以當CPU訪問的數據如果是在內存中連續存儲的話,訪問的效率會非常高。如果CPU要訪問的數據不在當前緩存所有的cache line中,則需要從內存中加載對應的數據,這被稱爲一次cache miss。當cache miss非常高的時候,CPU大部分的時間都在等待數據加載,而不是真正的處理數據。Java對象並不是連續的存儲在內存上,同時很多的Java數據結構的數據聚集性也不好。
大數據的垃圾回收
Java的垃圾回收機制一直讓Java開發者又愛又恨,一方面它免去了開發者自己回收資源的步驟,提高了開發效率,減少了內存泄漏的可能,另一方面垃圾回收也是Java應用的不×××,有時秒級甚至是分鐘級的垃圾回收極大影響了Java應用的性能和可用性。在時下數據中心,大容量內存得到了廣泛的應用,甚至出現了單臺機器配置TB內存的情況,同時,大數據分析通常會遍歷整個源數據集,對數據進行轉換、清洗、處理等步驟。在這個過程中,會產生海量的Java對象,JVM的垃圾回收執行效率對性能有很大影響。通過JVM參數調優提高垃圾回收效率需要用戶對應用和分佈式計算框架以及JVM的各參數有深入瞭解,而且有時候這也遠遠不夠。
OOM問題
OutOfMemoryError是分佈式計算框架經常會遇到的問題,當JVM中所有對象大小超過分配給JVM的內存大小時,就會出現OutOfMemoryError錯誤,JVM崩潰,分佈式框架的健壯性和性能都會受到影響。通過JVM管理內存,同時試圖解決OOM問題的應用,通常都需要檢查Java對象的大小,並在某些存儲Java對象特別多的數據結構中設置閾值進行控制。但是JVM並沒有提供官方檢查Java對象大小的工具,第三方的工具類庫可能無法準確通用地確定Java對象大小[6]。侵入式的閾值檢查也會爲分佈式計算框架的實現增加很多額外與業務邏輯無關的代碼。
Flink的處理策略
爲了解決以上提到的問題,高性能分佈式計算框架通常需要以下技術:
定製的序列化工具。顯式內存管理的前提步驟就是序列化,將Java對象序列化成二進制數據存儲在內存上(on heap或是off-heap)。通用的序列化框架,如Java默認使用java.io.Serializable將Java對象及其成員變量的所有元信息作爲其序列化數據的一部分,序列化後的數據包含了所有反序列化所需的信息。這在某些場景中十分必要,但是對於Flink這樣的分佈式計算框架來說,這些元數據信息可能是冗餘數據。定製的序列化框架,如Hadoop的org.apache.hadoop.io.Writable需要用戶實現該接口,並自定義類的序列化和反序列化方法。這種方式效率最高,但需要用戶額外的工作,不夠友好。 顯式的內存管理。一般通用的做法是批量申請和釋放內存,每個JVM實例有一個統一的內存管理器,所有內存的申請和釋放都通過該內存管理器進行。這可以避免常見的內存碎片問題,同時由於數據以二進制的方式存儲,可以大大減輕垃圾回收壓力。
緩存友好的數據結構和算法。對於計算密集的數據結構和算法,直接操作序列化後的二進制數據,而不是將對象反序列化後再進行操作。同時,只將操作相關的數據連續存儲,可以最大化的利用L1/L2/L3緩存,減少Cache miss的概率,提升CPU計算的吞吐量。以排序爲例,由於排序的主要操作是對Key進行對比,如果將所有排序數據的Key與Value分開並對Key連續存儲,那麼訪問Key時的Cache命中率會大大提高。
定製的序列化工具
分佈式計算框架可以使用定製序列化工具的前提是要待處理數據流通常是同一類型,由於數據集對象的類型固定,從而可以只保存一份對象Schema信息,節省大量的存儲空間。同時,對於固定大小的類型,也可通過固定的偏移位置存取。在需要訪問某個對象成員變量時,通過定製的序列化工具,並不需要反序列化整個Java對象,而是直接通過偏移量,從而只需要反序列化特定的對象成員變量。如果對象的成員變量較多時,能夠大大減少Java對象的創建開銷,以及內存數據的拷貝大小。Flink數據集都支持任意Java或是Scala類型,通過自動生成定製序列化工具,既保證了API接口對用戶友好(不用像Hadoop那樣數據類型需要繼承實現org.apache.hadoop.io.Writable接口),也達到了和Hadoop類似的序列化效率。
Flink對數據集的類型信息進行分析,然後自動生成定製的序列化工具類。Flink支持任意的Java或是Scala類型,通過Java Reflection框架分析基於Java的Flink程序UDF(User Define Function)的返回類型的類型信息,通過Scala Compiler分析基於Scala的Flink程序UDF的返回類型的類型信息。類型信息由TypeInformation類表示,這個類有諸多具體實現類,例如:
BasicTypeInfo任意Java基本類型(裝包或未裝包)和String類型。 BasicArrayTypeInfo任意Java基本類型數組(裝包或未裝包)和String數組。 WritableTypeInfo任意Hadoop的Writable接口的實現類。 TupleTypeInfo任意的Flink tuple類型(支持Tuple1 to Tuple25)。 Flink tuples是固定長度固定類型的Java Tuple實現。 CaseClassTypeInfo任意的 Scala CaseClass(包括 Scala tuples)。 PojoTypeInfo任意的POJO (Java or Scala),例如Java對象的所有成員變量,要麼是public修飾符定義,要麼有getter/setter方法。 GenericTypeInfo任意無法匹配之前幾種類型的類。
前6種類型數據集幾乎覆蓋了絕大部分的Flink程序,針對前6種類型數據集,Flink皆可以自動生成對應的TypeSerializer定製序列化工具,非常有效率地對數據集進行序列化和反序列化。對於第7種類型,Flink使用Kryo進行序列化和反序列化。此外,對於可被用作Key的類型,Flink還同時自動生成TypeComparator,用來輔助直接對序列化後的二進制數據直接進行compare、hash等操作。對於Tuple、CaseClass、Pojo等組合類型,Flink自動生成的TypeSerializer、TypeComparator同樣是組合的,並把其成員的序列化/反序列化代理給其成員對應的TypeSerializer、TypeComparator,如圖6所示:
圖6 Flink組合類型序列化
此外如有需要,用戶可通過集成TypeInformation接口定製實現自己的序列化工具。
顯式的內存管理
垃圾回收是JVM內存管理迴避不了的問題,JDK8的G1算法改善了JVM垃圾回收的效率和可用範圍,但對於大數據處理實際環境還遠遠不夠。這也和現在分佈式框架的發展趨勢有所衝突,越來越多的分佈式計算框架希望儘可能多地將待處理數據集放入內存,而對於JVM垃圾回收來說,內存中Java對象越少、存活時間越短,其效率越高。通過JVM進行內存管理的話,OutOfMemoryError也是一個很難解決的問題。同時,在JVM內存管理中,Java對象有潛在的碎片化存儲問題(Java對象所有信息可能在內存中連續存儲),也有可能在所有Java對象大小沒有超過JVM分配內存時,出現OutOfMemoryError問題。Flink將內存分爲3個部分,每個部分都有不同用途:
Network buffers: 一些以32KB Byte數組爲單位的buffer,主要被網絡模塊用於數據的網絡傳輸。 Memory Manager pool大量以32KB Byte數組爲單位的內存池,所有的運行時算法(例如Sort/Shuffle/Join)都從這個內存池申請內存,並將序列化後的數據存儲其中,結束後釋放回內存池。 Remaining (Free) Heap主要留給UDF中用戶自己創建的Java對象,由JVM管理。
Network buffers在Flink中主要基於Netty的網絡傳輸,無需多講。Remaining Heap用於UDF中用戶自己創建的Java對象,在UDF中,用戶通常是流式的處理數據,並不需要很多內存,同時Flink也不鼓勵用戶在UDF中緩存很多數據,因爲這會引起前面提到的諸多問題。Memory Manager pool(以後以內存池代指)通常會配置爲最大的一塊內存,接下來會詳細介紹。
在Flink中,內存池由多個MemorySegment組成,每個MemorySegment代表一塊連續的內存,底層存儲是byte[],默認32KB大小。MemorySegment提供了根據偏移量訪問數據的各種方法,如get/put int、long、float、double等,MemorySegment之間數據拷貝等方法和java.nio.ByteBuffer類似。對於Flink的數據結構,通常包括多個向內存池申請的MemeorySegment,所有要存入的對象通過TypeSerializer序列化之後,將二進制數據存儲在MemorySegment中,在取出時通過TypeSerializer反序列化。數據結構通過MemorySegment提供的set/get方法訪問具體的二進制數據。Flink這種看起來比較複雜的內存管理方式帶來的好處主要有:
二進制的數據存儲大大提高了數據存儲密度,節省了存儲空間。 所有的運行時數據結構和算法只能通過內存池申請內存,保證了其使用的內存大小是固定的,不會因爲運行時數據結構和算法而發生OOM。對於大部分的分佈式計算框架來說,這部分由於要緩存大量數據最有可能導致OOM。 內存池雖然佔據了大部分內存,但其中的MemorySegment容量較大(默認32KB),所以內存池中的Java對象其實很少,而且一直被內存池引用,所有在垃圾回收時很快進入持久代,大大減輕了JVM垃圾回收的壓力。 Remaining Heap的內存雖然由JVM管理,但是由於其主要用來存儲用戶處理的流式數據,生命週期非常短,速度很快的Minor GC就會全部回收掉,一般不會觸發Full GC。
Flink當前的內存管理在最底層是基於byte[],所以數據最終還是on-heap,最近Flink增加了off-heap的內存管理支持。Flink off-heap的內存管理相對於on-heap的優點主要在於:
啓動分配了大內存(例如100G)的JVM很耗費時間,垃圾回收也很慢。如果採用off-heap,剩下的Network buffer和Remaining heap都會很小,垃圾回收也不用考慮MemorySegment中的Java對象了。 更有效率的IO操作。在off-heap下,將MemorySegment寫到磁盤或是網絡可以支持zeor-copy技術,而on-heap的話則至少需要一次內存拷貝。 off-heap可用於錯誤恢復,比如JVM崩潰,在on-heap時數據也隨之丟失,但在off-heap下,off-heap的數據可能還在。此外,off-heap上的數據還可以和其他程序共享。 緩存友好的計算
磁盤IO和網絡IO之前一直被認爲是Hadoop系統的瓶頸,但是隨着Spark、Flink等新一代分佈式計算框架的發展,越來越多的趨勢使得CPU/Memory逐漸成爲瓶頸,這些趨勢包括:
更先進的IO硬件逐漸普及。10GB網絡和SSD硬盤等已經被越來越多的數據中心使用。 更高效的存儲格式。Parquet,ORC等列式存儲被越來越多的Hadoop項目支持,其非常高效的壓縮性能大大減少了落地存儲的數據量。 更高效的執行計劃。例如很多SQL系統執行計劃優化器的Fliter-Push-Down優化會將過濾條件儘可能的提前,甚至提前到Parquet的數據訪問層,使得在很多實際的工作負載中並不需要很多的磁盤IO。
由於CPU處理速度和內存訪問速度的差距,提升CPU的處理效率的關鍵在於最大化的利用L1/L2/L3/Memory,減少任何不必要的Cache miss。定製的序列化工具給Flink提供了可能,通過定製的序列化工具,Flink訪問的二進制數據本身,因爲佔用內存較小,存儲密度比較大,而且還可以在設計數據結構和算法時儘量連續存儲,減少內存碎片化對Cache命中率的影響,甚至更進一步,Flink可以只是將需要操作的部分數據(如排序時的Key)連續存儲,而將其他部分的數據存儲在其他地方,從而最大可能地提升Cache命中的概率。
以Flink中的排序爲例,排序通常是分佈式計算框架中一個非常重的操作,Flink通過特殊設計的排序算法獲得了非常好的性能,其排序算法的實現如下:
將待排序的數據經過序列化後存儲在兩個不同的MemorySegment集中。數據全部的序列化值存放於其中一個MemorySegment集中。數據序列化後的Key和指向第一個MemorySegment集中值的指針存放於第二個MemorySegment集中。 對第二個MemorySegment集中的Key進行排序,如需交換Key位置,只需交換對應的Key+Pointer的位置,第一個MemorySegment集中的數據無需改變。 當比較兩個Key大小時,TypeComparator提供了直接基於二進制數據的對比方法,無需反序列化任何數據。 排序完成後,訪問數據時,按照第二個MemorySegment集中Key的順序訪問,並通過Pointer值找到數據在第一個MemorySegment集中的位置,通過TypeSerializer反序列化成Java對象返回。
圖7 Flink排序算法
這樣實現的好處有:
通過Key和Full data分離存儲的方式儘量將被操作的數據最小化,提高Cache命中的概率,從而提高CPU的吞吐量。 移動數據時,只需移動Key+Pointer,而無須移動數據本身,大大減少了內存拷貝的數據量。 TypeComparator直接基於二進制數據進行操作,節省了反序列化的時間。
通過定製的內存管理,Flink通過充分利用內存與CPU緩存,大大提高了CPU的執行效率,同時由於大部分內存都由框架自己控制,也很大程度提升了系統的健壯性,減少了OOM出現的可能。