




ZuulException REJECTED_SEMAPHORE_EXECUTION 是一個最近在性能測試中經常遇到的異常。查詢資料發現是因爲zuul默認每個路由直接用信號量做隔離,並且默認值是100,也就是當一個路由請求的信號量高於100那麼就拒絕服務了,返回500。
信號量隔離
既然默認值太小,那麼就在gateway的配置提高各個路由的信號量再實驗。
兩個路由的信號量分開提高到2000和1000。我們再用gatling測試一下。
1setUp(scn.inject(rampUsers(200) over (3seconds)).protocols(httpConf))
這是我們的模型,3s內啓動200個用戶,順序訪問5個API。所以會有1000個request。機器配置只有2核16G,並且是docker化的數據庫。所以整體性能不高。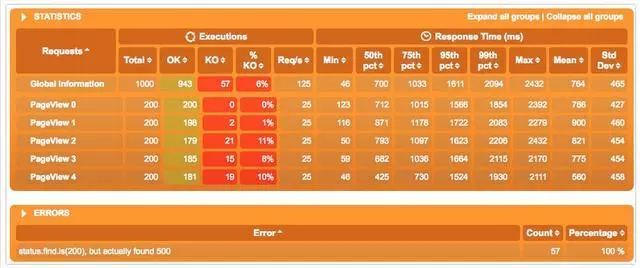
看結果仍然有57個KO,但是比之前1000個Request有900個KO的比例好很多了。
線程隔離
Edgware版本的spring cloud提供了另一種基於線程池的隔離機制。實現起來也非常簡單,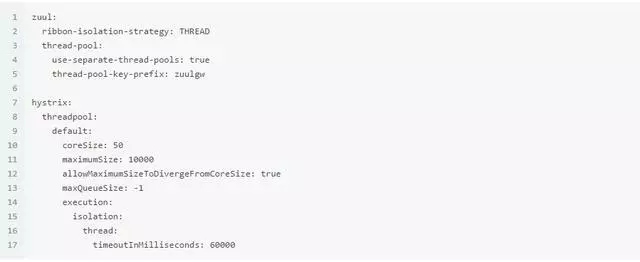
use-separate-thread-pools的意思是每個路由都有自己的線程池,而不是共享一個。
thread-pool-key-prefix會指定一個線程池前綴方便調試。
hystrix的部分主要設置線程池的大小,這裏設置了10000,其實並不是越大越好。線程池越大削峯填谷的效果越顯著,也就是時間換空間。系統的整體負載會上升,導致響應時間越來越長,那麼當響應時間超過某個限度,其實系統也算是不可用了。後面可以看到數據。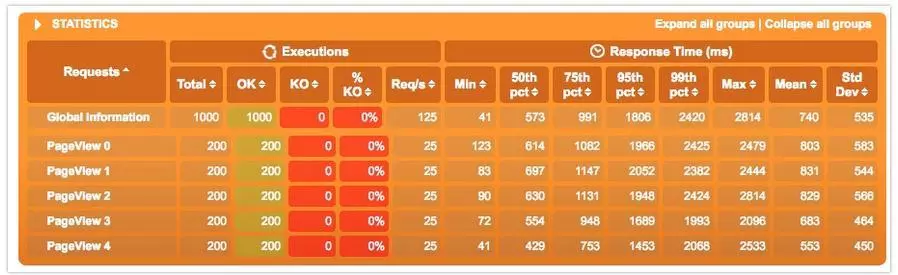
這次沒有500的情況了,1000個Request都正常返回了。
比較
從幾張圖對比下兩種隔離的效果,上圖是信號量隔離,下圖是線程隔離。
響應時間分佈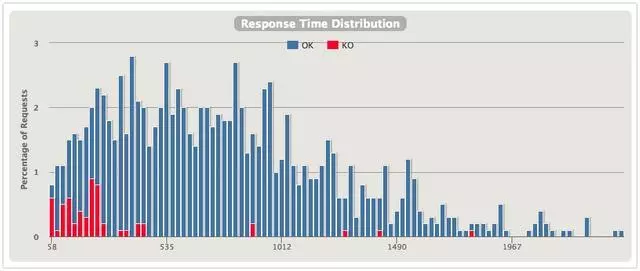
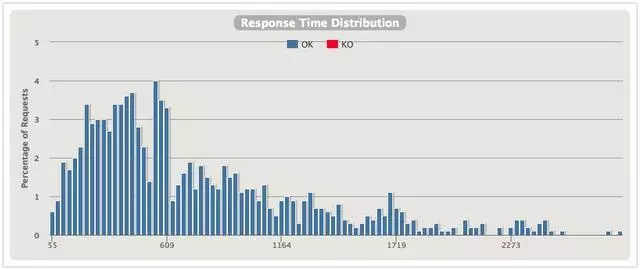
直觀上能發現使用線程隔離的分佈更好看一些,600ms內的響應會更多一些。
QPS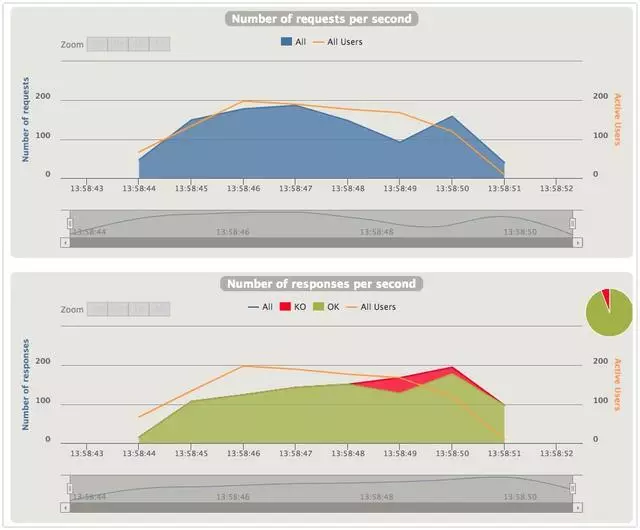
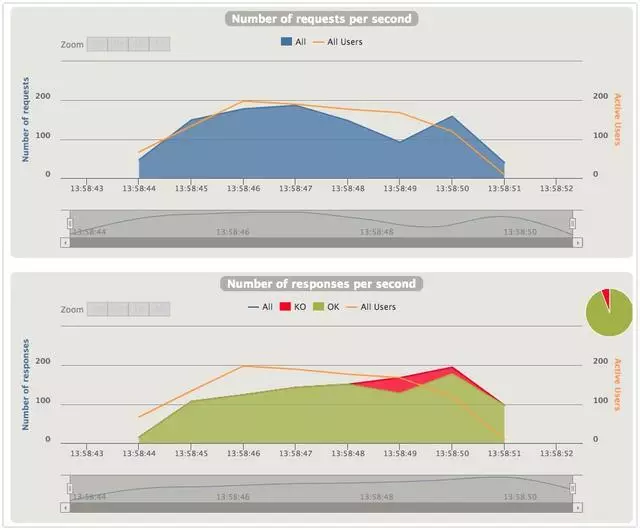
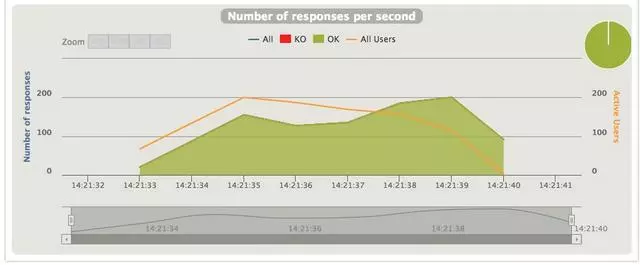
兩張圖展示的是同一時刻的Request和Response的數量。
先看信號量隔離的場景,Response per second是逐步提升的,但是達到一個量級後,gateway開始拒絕服務。猜測是超過了信號量的限制或是超時?
線程隔離的這張就比較有意思了,可以看到Request per second上升的速度要比上面的快,說明系統是試圖接收更多的請求然後分發給線程池。再看在某個時間點Response per second反而開始下降,因爲線程不斷的創建消耗了大量的系統資源,響應變慢。之後因爲請求少了,負載降低,Response又開始擡升。所以線程池也並非越大越好,需要不斷調試尋找一個平衡點。
在此我向大家推薦一個交流學習羣:855801563 裏面會分享一些資深架構師錄製的視頻錄像:有Spring,MyBatis,Netty源碼分析,高併發、高性能、分佈式、微服務架構的原理,JVM性能優化這些成爲架構師必備的知識體系。還能領取免費的學習資源。
小結
線程池提供了比信號量更好的隔離機制,並且從實際測試發現高吞吐場景下可以完成更多的請求。但是信號量隔離的開銷更小,對於本身就是10ms以內的系統,顯然信號量更合適。