




一、Keepalived 詳解配置
1、Keepalived 軟件介紹:
Keeplived 軟件起初就是專爲 LVS 負載均衡軟件設計的,用來管理並監控 LVS 集羣系統中各個服務器節點的狀態,後來又加入了可以實現高可用的 VRRP 功能。因此 Keepalived 除了能夠管理 LVS 軟件外,還可以作爲其他服務(Nginx、Haproxy、MySQL 等)的高可用解決方案軟件。
Keeplived 軟件主要是通過 VRRP 協議實現高可用功能的,VRRP 出現的目的就是爲了解決靜態路由單點故障問題的,它能夠保證當個別節點宕機時,整個網絡可以不間斷的運行,所以 Keepalived 一方面具有配置管理 LVS 的功能,同時還具有對 LVS 下面節點進行健康檢查的功能,另一方面也可實現系統網絡服務的高可用性。
Keeplived 軟件的官方網站是 http://www.keepalived.org。
2、Keeplived 高可用故障切換轉移原理:
Keeplived 高可用服務對之間的故障切換轉移,是通過 VRRP 協議(Virtual Router Redundancy Protocol,中文意思:虛擬路由器冗餘協議)來實現的。
在 Keepailved 服務正常工作時,主 Master 節點會不斷地向備節點發送(多播的方式)心跳消息,用以告訴備 Backup 節點自己還活着,當主 Master 節點發生故障時,就無法發送心跳信息了,備節點也就因此無法繼續監測到來自主 Master 節點的心跳了,進而調用自身的接管程序,接管主 Master 節點的 IP 資源及服務。而當主 Master 節點恢復時,備 Bacckup 節點又會釋放主節點故障時自身接管的 IP 資源及服務,恢復到原來的備用角色。
3、企業面試題:簡要回答 Keeplived 的工作原理:
Keeplived 軟件高可用對之間是通過 VRRP 協議通信的,因此,我從 VRRP 協議介紹開始:
① VRRP 協議全稱 Virtual Router Redundancy Protocol,中文意思:虛擬路由器冗餘協議。它的出現是爲了解決靜態路由的單點故障;
② VRRP 協議是通過一種競選協議機制來將路由任務交給某臺 VRRP 路由器的;
③ VRRP 協議是通過 IP 多播方式(默認多播地址 224.0.0.18)實現高可用對之間通信的;
④ 工作主節點發包,備節點接包,當備節點接收不到主節點發的數據包的時候,就啓動接管程序接管主節點的資源,備節點可以有多個,通過優先級競選,但一般 Keepalived 系統運維工作中都是用一對。
⑤ VRRP 使用了加密協議加密數據,但 Keepalived 官方目前還是推薦用明文的方式配置認證類型和密碼。
介紹完了 VRRP 協議,接下來介紹 Keepalived 服務的工作原理:
Keepalived 高可用對之間是通過 VRRP 協議進行通信的,VRRP 協議是通過競選機制來確定主備的,主優先級高於備,因此工作時主會優先獲得所有的資源,備節點處於等待狀態,當主掛了的時候,備節點就會接管主節點的資源,然後頂替主節點對外提供服務。
在 Keepalived 服務對之間,只有作爲主的服務器會一直髮送 VRRP 廣播包,告訴備它還活着,此時備不會搶佔主,當主不可用時,即備監聽不到主發送的廣播包時就會啓動相關服務接管資源,保證業務的連續性,接管速度最快可以小於 1 秒。
4、keepalived 高可用服務搭建:
1)、搭建環境準備:
2)、Keepalived 軟件安裝:
a、在兩臺負載均衡服務器安裝 Keepalived 軟件:
[root@lb01 ~]# yum install keepalived -y
[root@lb01 ~]# rpm -qa keepalived
keepalived-1.2.13-5.el6_6.x86_64b、在兩臺負載均衡服務器啓動 Keepalived 軟件:
[root@lb01 ~]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
[root@lb01 ~]# ps -ef|grep keep|grep -v grep # 有三個進程表示正常
root 1186 1 0 Jul26 ? 00:00:03 /usr/sbin/keepalived -D
root 1187 1186 0 Jul26 ? 00:00:03 /usr/sbin/keepalived -D
root 1188 1186 0 Jul26 ? 00:00:12 /usr/sbin/keepalived -Dc、添加虛擬 IP 的兩種方式:
① ifconfig eth0:0 192.168.153.100/24 up
② ip addr add 192.168.153.100/24 dev eth0 label eth0:1 # 這種給添加的 IP 加標籤的方式可以用 ifconfig 命令查到添加的 IP,否則只能用 ip add 查看添加的 IP。
提示:Keepalived 默認使用第二種方式添加的虛擬 IP 。早期的 Heartbeat 使用第一種方式添加虛擬 IP,在 Heartbeat 3.0 版本以後也使用第二種方式添加虛擬 IP 了。
[root@lb01 ~]# ip addr add 192.168.153.100/24 dev eth0 label eth0:1
[root@lb01 ~]# ip add|grep 153.100
inet 192.168.153.100/24 scope global secondary eth0:1d、編輯 Keepalived 配置文件:
[root@lb01 ~]# man keepalived.conf # Keepalived 配置文件有三個部分。
TOP HIERACHY
GLOBAL CONFIGURATION # 全局配置
VRRPD CONFIGURATION # VRRP 的配置
LVS CONFIGURATION # 結合 LVS 的配置[root@lb01 ~]# vim /etc/keepalived/keepalived.conf
1 ! Configuration File for keepalived # 這裏井號歎號都爲註釋。
2
3 global_defs { # 全局配置。
4 notification_email {
5 [email protected] ##############
6 [email protected] # 這三行是接收郵件的收件人(沒什麼用)。
7 [email protected] ##############
8 }
9 notification_email_from [email protected] # 發件人。
10 smtp_server 192.168.200.1 # 郵件服務器。
11 smtp_connect_timeout 30 # 郵件服務器。
12 router_id LVS_DEVEL # 路由 ID,不同機器之間不能重複。
13 }
14
15 vrrp_instance VI_1 { # VRRP 實例【VI_1 是實例名字,可以配多個(VI_2等)】。
16 state MASTER # 角色(主),傀儡、不決定主備。
17 interface eth0 # 通信的接口。
18 virtual_router_id 51 # 該實例的 ID,不同的實例 ID 要不同。
19 priority 150 # 優先級,競選看優先級(決定主備的參數)。
20 advert_int 1 # 通信檢查間隔時間爲 1 s,發廣播的間隔時間內從 Backup 服務器沒有接收到廣播就接替工作。
21 authentication { # 主備通信方式。
22 auth_type PASS # 認證機制,明文的密碼方式。
23 auth_pass 1111 # 認證的密碼。
24 }
25 virtual_ipaddress { # VIP 虛擬 IP,可以是一組也可以是一個。
26 192.168.153.100/24 dev eth0 label eth0:1
27 }
28 }
上面爲主服務器的配置文件,綠色的部分都是備服務器需要修改的:
12 router_id LVS_DEVEL1
16 state BACKUP
19 priority 100e、Master 節點和 Backup 節點特殊參數的不同:
3)、此時查看兩臺服務器上面的虛擬 IP:
在主節點查看虛擬 IP 的存在:
[root@lb01 ~]# ip add|grep 153.100 # 主 Master 節點有添加的虛擬 IP(優先級高)。
inet 192.168.153.100/24 scope global secondary eth0:1
在備節點查看虛擬 IP 的存在:
[root@lb02 ~]# ip add |grep 153.100 # 備 Backup 節點沒有(主正常,備等待)。4)、以 Windows爲客戶端測試主備節點的高可用:
① 通過 Windows 客戶端連續 ping 虛擬 IP:
② 此時在主節點可以看到虛擬 IP :
[root@lb01 ~]# ip add|grep 192.168.136.100
inet 192.168.136.100/24 scope global secondary eth0:1③ 關掉主節點的 Keepalived 服務:
[root@lb01 ~]# /etc/init.d/keepalived stop
Stopping keepalived: [ OK ] ④ 查看備節點的虛擬 IP(備接管主的工作):
[root@lb02 ~]# ip add|grep 192.168.136.100
inet 192.168.136.100/24 scope global secondary eth0:1⑤ 啓動主節點的 Keepalived 服務並查看虛擬 IP :
[root@lb01 ~]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
[root@lb01 ~]# ip add|grep 192.168.136.100 # 略有延遲,編譯安裝快?
inet 192.168.136.100/24 scope global secondary eth0:15)、Keepalived 多實例的配置及實現:
首先添加另一個虛擬 IP :[root@lb01 ~]# ip addr add 192.168.153.200/24 dev eth0 label eth0:2
修改兩臺負載均衡器的 keepalived.conf 配置文件:
① 在 lb 01 的 keepalived.conf 配置文件添加如下內容:
vrrp_instance VI_2 { # 表示第二個實例名字。(與第一個實例不同)
state BACKUP # 第二個實例的備 Backup 節點。
interface eth0
virtual_router_id 52 # 虛擬路由 id,不同實例要不同,同一實例主備相同。
priority 100 # 優先級。
advert_int 1
authentication {
auth_type PASS
auth_pass 1112 # 主備通信的密碼,同一實例主備相同(不同實例最好區分,非必須)。
}
virtual_ipaddress {
192.168.153.200/24 dev eth0 label eth0:2 # 添加的虛擬 IP 不同實例不同,網卡標籤不同。
}
}② 在 lb 02 的 keepalived.conf 配置文件添加如下內容:
vrrp_instance VI_2 { # 表示第二個實例名字。(與第一個實例不同)
state MASTER # 第二個實例的主 MASTER 節點。
interface eth0
virtual_router_id 52 # 虛擬路由 id,不同實例要不同,同一實例主備相同。
priority 150 # 優先級。
advert_int 1
authentication {
auth_type PASS
auth_pass 1112 # 主備通信的密碼,同一實例主備相同(不同實例最好區分,非必須)。
}
virtual_ipaddress {
192.168.153.200/24 dev eth0 label eth0:2· # 添加的虛擬 IP 不同實例不同,網卡標籤不同。
}
}③ 重啓兩臺服務器使配置生效:
[root@lb01 ~]# /etc/init.d/keepalived restart
Stopping keepalived: [ OK ]
Starting keepalived: [ OK ]
[root@lb02 ~]# /etc/init.d/keepalived restart
Stopping keepalived: [ OK ]
Starting keepalived: [ OK ]④ 通過查看虛擬 IP 測試多實例的生效:
[root@lb01 ~]# ip add|egrep "153.100|153.200" # 實例一優先級高的是 lb01,所以 VIP 100存在。
inet 192.168.153.100/24 scope global secondary eth0:1
[root@lb02 ~]# ip add |egrep "153.100|153.200" # 實例二優先級高的是 lb02,所以 VIP 200存在。
inet 192.168.153.200/24 scope global secondary eth0:2關閉 lb01 服務器的 Keepalived 服務:
[root@lb01 ~]# /etc/init.d/keepalived stop
Stopping keepalived: [ OK ]
[root@lb01 ~]# ip add |egrep "153.100|153.200" # 此時該服務器沒有 VIP 在工作了。
[root@lb02 ~]# ip add|egrep "153.100|153.200" # lb02 服務器接管了兩個 VIP 的工作。
inet 192.168.153.100/24 scope global secondary eth0:1
inet 192.168.153.200/24 scope global secondary eth0:2啓動 lb01 服務器的 Keepalived 服務:
[root@lb01 ~]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
[root@lb01 ~]# ip add|egrep "153.100|153.200" # 實例一優先級高的是 lb01,所以 VIP 100存在。
inet 192.168.153.100/24 scope global secondary eth0:1
[root@lb02 ~]# ip add |egrep "153.100|153.200" # 實例二優先級高的是 lb02,所以 VIP 200存在。
inet 192.168.153.200/24 scope global secondary eth0:2關閉 lb02 服務器的 Keepalived 服務:
[root@lb02 ~]# /etc/init.d/keepalived stop
Stopping keepalived: [ OK ]
[root@lb02 ~]# ip add |egrep "153.100|153.200" # 此時該服務器沒有 VIP 在工作了。
[root@lb01 ~]# ip add|egrep "153.100|153.200" # lb01 服務器接管了兩個 VIP 的工作。
inet 192.168.153.100/24 scope global secondary eth0:1
inet 192.168.153.200/24 scope global secondary eth0:25、Keepalived 配合 Nginx 負載均衡實現高可用: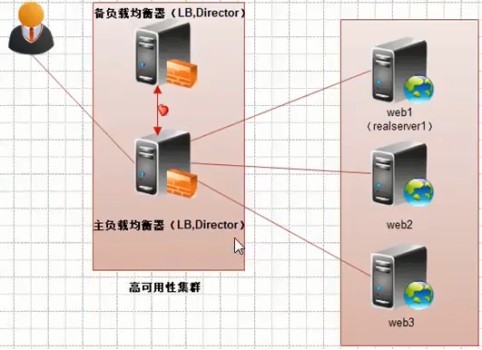
方案一:兩臺負載同時啓動 Nginx 代理,Keepalived 負責 VIP 漂移,VIP 漂移到哪個機器哪個就提供訪問:
① 檢查環境:
兩臺 Nginx 負載均衡器的 Keepalived 服務和 Nginx 服務都是開啓狀態:
[root@lb01 ~]# /etc/init.d/keepalived status
keepalived (pid 2622) is running...
[root@lb02 ~]# /etc/init.d/keepalived status
keepalived (pid 2622) is running...
[root@lnmp01 conf]# ps -ef|grep nginx|grep -v grep
root 2045 1 0 Jun22 ? 00:00:00 nginx: master process /application/nginx/sbin/nginx
nginx 2137 2045 0 Jun22 ? 00:00:00 nginx: worker process
[root@lnmp02 conf]# ps -ef|grep nginx|grep -v grep
root 2045 1 0 Jun22 ? 00:00:00 nginx: master process /application/nginx/sbin/nginx
nginx 2137 2045 0 Jun22 ? 00:00:00 nginx: worker process ② 備份並編輯 Web 服務器的配置文件:
[root@lb01 conf]# pwd
/application/nginx/conf
[root@lb01 conf]# vim nginx.conf
[root@lb01 conf]# cat nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream www_server_pools{
# ip_hash;
server 192.168.136.150:80 weight=1;
server 192.168.136.151:80 weight=1;
}
server {
listen 80;
server_name www.etiantian.org;
location / {
proxy_pass http://www_server_pools;
}
}
}③ 檢查 Web01 和 Web02 服務器 www 站點首頁文件:
[root@lnmp01 ~]# cat /application/nginx/html/www/index.html
www.etiantian.org 150
[root@lnmp02 ~]# cat /application/nginx/html/www/index.html
www.etiantian.org 151④ 修改負載均衡服務器 hosts 並 curl 訪問 Web 服務器:
[root@lb01 conf]# vim /etc/hosts
[root@lb01 conf]# cat /etc/hosts
192.168.153.100 www.etiantian.org # 將域名解析到虛擬 IP。[root@lb01 conf]# for n in `seq 10`;do curl www.etiantian.org;done # 實現。
www.etiantian.org 150
www.etiantian.org 151
www.etiantian.org 150
www.etiantian.org 151
www.etiantian.org 150
www.etiantian.org 151
www.etiantian.org 150
www.etiantian.org 151
www.etiantian.org 150
www.etiantian.org 151⑤ 實現兩臺負載均衡器的高可用,要讓它們的 Nginx 配置文件一致:
[root@lb02 conf]# cd /application/nginx/conf/
[root@lb02 conf]# vim nginx.conf # 跟以上配置一致。
[root@lb02 conf]# ../sbin/nginx -t
nginx: the configuration file /application/nginx-1.6.3/conf/nginx.conf syntax is ok
nginx: configuration file /application/nginx-1.6.3/conf/nginx.conf test is successful
[root@lb02 conf]# ../sbin/nginx -s reload測試 lb02 負載均衡器的工作是否正常:
[root@lb02 conf]# tail -1 /etc/hosts
192.168.136.162 www.etiantian.org # 備節點沒有 VIP,所以解析到自己的 IP 測試。[root@lb02 conf]# for n in `seq 10`;do curl www.etiantian.org;done
www.etiantian.org 150
www.etiantian.org 151
www.etiantian.org 150
www.etiantian.org 151
www.etiantian.org 150
www.etiantian.org 151
www.etiantian.org 150
www.etiantian.org 151
www.etiantian.org 150
www.etiantian.org 151⑥ 在 Windows 做域名對應 VIP 的解析並通過瀏覽器訪問:
徽標鍵 + R 運行窗口 drivers 命令修改 hosts如下:
192.168.136.100 www.etiantian.org
通過瀏覽器訪問域名 www.etiantian.org:
訪問到 Web 01 的首頁文件:
刷新後訪問到 Web 02 的首頁文件: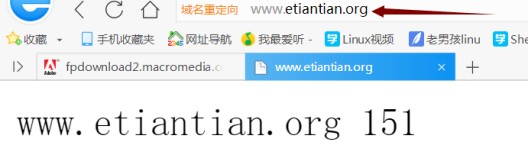
⑦ 此時讓 LB01 宕機,再訪問,業務不受影響:
原因:VIP 飄到 LB 02 服務器了,lb 02 接管工作,如下:
[root@lb02 conf]# ip add|egrep 136.100
inet 192.168.136.100/24 scope global secondary eth0:1⑧ 開啓 LB01 服務器,再訪問,業務不受影響,VIP 重新飄回LB01:
[root@lb01 conf]# ip add|egrep 136.100
inet 192.168.136.100/24 scope global secondary eth0:1
[root@lb02 conf]# ip add|egrep 136.100 # lb02 沒有 VIP 100 了。方案二:通過 Keepalived 多實例配合 Nginx 實現雙主:
www.etiantian.org 的 VIP 爲 192.168.136.100 ,在 lb01 上是主。
blog.etiantian.org 的 VIP 爲 192.168.136.200 ,在 lb02 上是主。
① 編輯 lb01 的 Nginx 配置文件:
[root@lb01 conf]# vim nginx.conf
[root@lb01 conf]# cat nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream www_server_pools{
# ip_hash;
server 192.168.136.150:80 weight=1;
server 192.168.136.151:80 weight=1;
}
server {
listen 192.168.136.100:80;
server_name www.etiantian.org;
location / {
proxy_pass http://www_server_pools;
}
}
server {
listen 192.168.136.200:80;
server_name blog.etiantian.org;
location / {
proxy_pass http://www_server_pools;
}
}
}② Nginx 無法啓動的問題:
[root@lb01 conf]# pkill nginx
[root@lb01 conf]# /application/nginx/sbin/nginx
nginx: [emerg] bind() to 192.168.136.200:80 failed (99: Cannot assign requested address)
[root@lb01 conf]# lsof -i :80 # Nginx 無法啓動。
[root@lb01 conf]# ifconfig|egrep 136.200 # 原因:配置文件監聽了網卡上不存在的 IP。
[root@lb01 conf]# echo 'net.ipv4.ip_nonlocal_bind = 1' >>/etc/sysctl.conf # 添加內核參數。
[root@lb01 conf]# sysctl -p|grep net.ipv4.ip_nonlocal_bind
net.ipv4.ip_nonlocal_bind = 1 # 啓動 Nginx 時忽略配置中監聽的 VIP 是否存在。
[root@lb01 conf]# /application/nginx/sbin/nginx # 啓動成功。
[root@lb01 conf]# lsof -i :80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 3040 root 6u IPv4 15768 0t0 TCP www.etiantian.org:http (LISTEN)
nginx 3040 root 7u IPv4 15769 0t0 TCP 192.168.136.200:http (LISTEN)
nginx 3041 nginx 6u IPv4 15768 0t0 TCP www.etiantian.org:http (LISTEN)
nginx 3041 nginx 7u IPv4 15769 0t0 TCP 192.168.136.200:http (LISTEN) ③ 讓 lb02 服務器的 Nginx 配置文件和 lb01 相同:
[root@lb02 conf]# vim nginx.conf
[root@lb02 conf]# echo 'net.ipv4.ip_nonlocal_bind = 1' >>/etc/sysctl.conf
[root@lb02 conf]# sysctl -p|grep net.ipv4.ip_nonlocal_bind
net.ipv4.ip_nonlocal_bind = 1
[root@lb02 conf]# pkill nginx
[root@lb02 conf]# ../sbin/nginx -t
[root@lb02 conf]# ../sbin/nginx④ 查看 Keepalilved 配置文件(多實例):
說明:192.168.136.100 這個 VIP 在 lb01 上是 MASTER,在 lb02 上是 BACKUP;
192.168.136.200 這個 VIP 在 lb02 上是 MASTER,在 lb01 上是 BACKUP;
[root@lb01 conf]# cat /etc/keepalived/keepalived.conf # lb01 配置。(lb02 略)
router_id LVS_DEVEL_1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.136.100/24 dev eth0 label eth0:1
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 5
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1112
}
virtual_ipaddress {
192.168.136.200/24 dev eth0 label eth0:2
}
}⑤ 查看兩邊運行的 VIP 及Web 服務器 blog 站點首頁文件:
[root@lb01 conf]# ip add|egrep "136.100|136.200" # lb01 提供服務的 VIP 是 100。
inet 192.168.136.100/24 scope global secondary eth0:1
[root@lb02 conf]# ip add|egrep "136.100|136.200" # lb02 提供服務的 VIP 是 200。
inet 192.168.136.200/24 scope global secondary eth0:2[root@lnmp01 ~]# cat /application/nginx/html/blog/index.html
blog.etiantian.org 150
[root@lnmp02 ~]# cat /application/nginx/html/blog/index.html
blog.etiantian.org 151⑥ 在負載均衡器測試訪問 blog 站點:
[root@lb02 conf]# vim /etc/hosts # lb02 上面提供服務的 VIP 爲 200。
192.168.136.200 blog.etiantian.org[root@lb02 conf]# for n in `seq 10`;do curl blog.etiantian.org;done
blog.etiantian.org 150
blog.etiantian.org 151
blog.etiantian.org 150
blog.etiantian.org 151
blog.etiantian.org 150
blog.etiantian.org 151
blog.etiantian.org 150
blog.etiantian.org 151
blog.etiantian.org 150
blog.etiantian.org 151 ⑦ 在 WINDOWS 上做 hosts 解析並通過瀏覽器測試:
Windows 上的 hosts 解析:
192.168.136.100 www.etiantian.org
192.168.136.200 blog.etiantian.org通過 ping 域名確保配置可用:
C:\Users\admin>ping blog.etiantian.org -t
正在 Ping blog.etiantian.org [192.168.136.200] 具有 32 字節的數據
來自 192.168.136.200 的回覆: 字節=32 時間<1ms TTL=64
來自 192.168.136.200 的回覆: 字節=32 時間<1ms TTL=64
來自 192.168.136.200 的回覆: 字節=32 時間<1ms TTL=64C:\Users\admin>ping www.etiantian.org -t
正在 Ping www.etiantian.org [192.168.136.100] 具有 32 字節的數據:
來自 192.168.136.100 的回覆: 字節=32 時間=38ms TTL=64
來自 192.168.136.100 的回覆: 字節=32 時間<1ms TTL=64
來自 192.168.136.100 的回覆: 字節=32 時間<1ms TTL=64通過瀏覽器訪問域名測試:
首先訪問 www.etiantian.org 結果如下: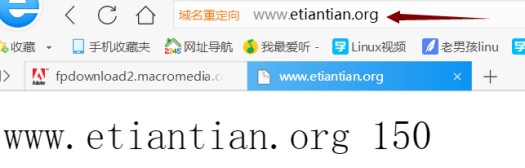
刷新後實現負載均衡: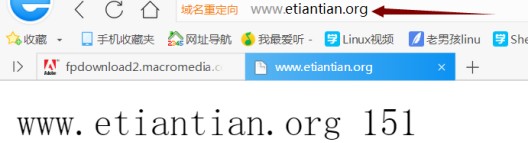
通過訪問 blog.etiantian.org 結果如下:
刷新後實現負載均衡: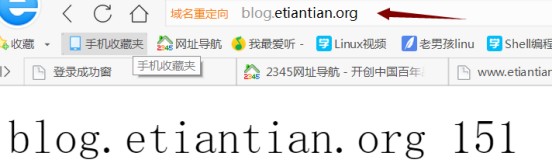
⑧ 把 lb01 停掉,查看業務運行情況:
關掉後 ping 兩個域名都是能通的:
C:\Users\admin>ping blog.etiantian.org -t
正在 Ping blog.etiantian.org [192.168.136.200] 具有 32 字節的數據
來自 192.168.136.200 的回覆: 字節=32 時間<1ms TTL=64
來自 192.168.136.200 的回覆: 字節=32 時間<1ms TTL=64
來自 192.168.136.200 的回覆: 字節=32 時間<1ms TTL=64C:\Users\admin>ping www.etiantian.org -t
正在 Ping www.etiantian.org [192.168.136.100] 具有 32 字節的數據:
來自 192.168.136.100 的回覆: 字節=32 時間=38ms TTL=64
來自 192.168.136.100 的回覆: 字節=32 時間<1ms TTL=64
來自 192.168.136.100 的回覆: 字節=32 時間<1ms TTL=64查看 lb02 負載均衡器提供服務的 VIP:
[root@lb02 conf]# ifconfig|egrep "136.100|36.200"
inet addr:192.168.136.100 Bcast:0.0.0.0 Mask:255.255.255.0 # 該 VIP 飄到 lb02 了。
inet addr:192.168.136.200 Bcast:0.0.0.0 Mask:255.255.255.0此時通過瀏覽器訪問兩個域名,業務是正常的(結果略)。
⑨ 重新把負載均衡器 lb01 啓動,檢查業務情況:
通過 ping 兩個域名都能 ping 通:
C:\Users\admin>ping blog.etiantian.org -t
正在 Ping blog.etiantian.org [192.168.136.200] 具有 32 字節的數據
來自 192.168.136.200 的回覆: 字節=32 時間<1ms TTL=64
來自 192.168.136.200 的回覆: 字節=32 時間<1ms TTL=64
來自 192.168.136.200 的回覆: 字節=32 時間<1ms TTL=64C:\Users\admin>ping www.etiantian.org -t
正在 Ping www.etiantian.org [192.168.136.100] 具有 32 字節的數據:
來自 192.168.136.100 的回覆: 字節=32 時間=38ms TTL=64
來自 192.168.136.100 的回覆: 字節=32 時間<1ms TTL=64
來自 192.168.136.100 的回覆: 字節=32 時間<1ms TTL=64此時通過瀏覽器訪問兩個域名,業務是正常的(結果略)。
查看兩個負載均衡器 VIP 的工作情況:
[root@lb01 conf]# ifconfig|egrep "136.100|36.200" # VIP 100 重新飄回。
inet addr:192.168.136.100 Bcast:0.0.0.0 Mask:255.255.255.0
[root@lb02 conf]# ifconfig|egrep "136.100|36.200" # VIP 200 正常。
inet addr:192.168.136.200 Bcast:0.0.0.0 Mask:255.255.255.0⑩ 把 lb02 停掉,查看業務運行情況(同上,略)。
注意:Web 服務可以來回切換,但是數據庫千萬不能用該方式切換,因爲把數據庫從主切到備,用戶在備上寫數據,再切回主會導致主從數據庫數據不一致的情況(一般數據庫通過手動切換)。
二、Keepalived 常見故障解決:
服務器網線鬆動等網絡故障;
服務器硬件故障發生損壞現象而崩潰;
Nginx 服務死掉。
提示:keepalived 是服務器級別的切換(基於系統的,不是基於軟件的)。1、問題描述:負載均衡服務器沒宕機,但 Nginx 服務宕了,如何保證高可用正常切換?
思路:監控 Nginx 服務狀態,如果不正常就停掉 Keepalived 或 halt 關機。
模擬問題場景如下:
[root@lb01 conf]# pkill nginx
[root@lb01 conf]# lsof -i :80
[root@lb01 conf]# ifconfig|egrep "136.100|136.200"
inet addr:192.168.136.100 Bcast:0.0.0.0 Mask:255.255.255.0此時 www.etiantian.org 域名無法訪問:
方法一:通過守護進程腳本實現:
[root@lb01 scripts]# ps -C nginx
PID TTY TIME CMD
3436 ? 00:00:00 nginx
3437 ? 00:00:00 nginx
[root@lb01 scripts]# ps -C nginx --no-header
3482 ? 00:00:00 nginx
3483 ? 00:00:00 nginx
[root@lb01 scripts]# ps -C nginx --no-header|wc -l
2[root@lb01 scripts]# pkill nginx
[root@lb01 scripts]# ps -C nginx --no-header
[root@lb01 scripts]# ps -C nginx --no-header|wc -l
0[root@lb01 scripts]# /application/nginx/sbin/nginx
[root@lb01 conf]# mkdir -p /server/scripts/
[root@lb01 conf]# cd /server/scripts/
[root@lb01 scripts]# vim check_w_proxy.sh
[root@lb01 scripts]# cat check_w_proxy.sh
#!/bin/sh
while true
do
nginxpid=`ps -C nginx --no-header|wc -l`
if [ $nginxpid -eq 0 ];then
/application/nginx/sbin/nginx
sleep 5
nginxpid=`ps -C nginx --no-header|wc -l`
if [ $nginxpid -eq 0 ];then
/etc/init.d/keepalived stop
exit 1
fi
fi
sleep 5
done[root@lb01 scripts]# yum install dos2unix -y
[root@lb01 scripts]# dos2unix check_w_proxy.sh
[root@lb01 scripts]# sh check_w_proxy.sh & # 讓腳本後臺運行。
[1] 3510測試過程:
[root@lb01 scripts]# ps -ef|grep nginx # Nginx 服務正常。
root 3482 1 0 23:54 ? 00:00:00 nginx: master process /application/nginx/sbin/nginx
nginx 3483 3482 0 23:54 ? 00:00:00 nginx: worker process
[root@lb01 scripts]# ps -ef|grep keepalived # Keepalived 服務正常。
root 2622 1 0 18:16 ? 00:00:01 /usr/sbin/keepalived -D
root 2624 2622 0 18:16 ? 00:00:01 /usr/sbin/keepalived -D
root 2625 2622 0 18:16 ? 00:00:12 /usr/sbin/keepalived -D
root 3618 3087 0 23:59 pts/1 00:00:00 grep keepalived
[root@lb01 scripts]# ifconfig|egrep "136.100|136.200" # VIP 100 工作正常。
inet addr:192.168.136.100 Bcast:0.0.0.0 Mask:255.255.255.0[root@lb01 scripts]# pkill nginx # 殺掉 Nginx 服務進程。
[root@lb01 scripts]# ifconfig|egrep "136.100|136.200" # VIP 沒有飄移。
inet addr:192.168.136.100 Bcast:0.0.0.0 Mask:255.255.255.0
[root@lb01 scripts]# ps -ef|grep nginx # 查看 Nginx 服務進程(腳本里啓動了 Nginx)。
root 3772 1 0 00:02 ? 00:00:00 nginx: master process /application/nginx/sbin/nginx
nginx 3774 3772 0 00:02 ? 00:00:00 nginx: worker process
root 3786 3087 0 00:02 pts/1 00:00:00 grep nginx編輯上面的腳本讓 Nginx 不嘗試啓動:
[root@lb01 scripts]# vim check_w_proxy.sh
[root@lb01 scripts]# cat check_w_proxy.sh # 註釋掉啓動 Nginx 的內容。
#!/bin/sh
while true
do
nginxpid=`ps -C nginx --no-header|wc -l`
if [ $nginxpid -eq 0 ];then
# /application/nginx/sbin/nginx
# sleep 5
# nginxpid=`ps -C nginx --no-header|wc -l`
# if [ $nginxpid -eq 0 ];then
/etc/init.d/keepalived stop
exit 1
fi
# fi
sleep 5
done重新執行該腳本:
[root@lb01 scripts]# ps -ef|grep check # 查看該守護進程。
root 3510 3087 0 Jun23 pts/1 00:00:00 sh check_w_proxy.sh
[root@lb01 scripts]# jobs # 查看後臺執行的程序。
[1]+ Running sh check_w_proxy.sh &
[root@lb01 scripts]# fg # 拿到前臺執行。
sh check_w_proxy.sh
^C # 通過 Ctrl + c 停止該程序的運行。
[root@lb01 scripts]# sh check_w_proxy.sh & # 再讓腳本後臺運行。
[1] 4178
[root@lb01 scripts]# ps -ef|grep nginx|grep -v grep # Nginx 是運行狀態。
root 3772 1 0 00:02 ? 00:00:00 nginx: master process /application/nginx/sbin/nginx
nginx 3774 3772 0 00:02 ? 00:00:00 nginx: worker process
[root@lb01 scripts]# ifconfig|egrep "136.100|136.200" # VIP 工作正常。
inet addr:192.168.136.100 Bcast:0.0.0.0 Mask:255.255.255.0[root@lb01 scripts]# pkill nginx # 殺掉 Nginx 進程。
[root@lb01 scripts]# Stopping keepalived: [ OK ] # 守護進程自動關閉 Keepalived。
[1]+ Exit 1 sh check_w_proxy.sh
[root@lb01 scripts]# ps -ef|grep nginx # 查看 Nginx 進程(沒有了)。
root 4374 3087 0 00:16 pts/1 00:00:00 grep nginx
[root@lb01 scripts]# ps -ef|grep nginx|grep -v grep
[root@lb01 scripts]# ifconfig|egrep "136.100|136.200" # VIP 沒有了。到 lb02 查看 VIP 漂移的情況:
[root@lb02 conf]# ifconfig|egrep "136.100|136.200" # VIP 飄到了 lb02 上提供服務。
inet addr:192.168.136.100 Bcast:0.0.0.0 Mask:255.255.255.0
inet addr:192.168.136.200 Bcast:0.0.0.0 Mask:255.255.255.0此時業務也迴歸正常了:
方法二:Keepalived 配置觸發:
① 修改 Keepalived 配置文件:
[root@lb01 scripts]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL_1
}
vrrp_script check_w_proxy { # 定義 VRRP 腳本檢查 Nginx 進程號。
script "/server/scripts/check_w_proxy.sh" # 當 Nginx 有問題就執行腳本停掉 Keepailved。
interval 2 # 間隔時間 2s 。
weight 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.136.100/24 dev eth0 label eth0:1
}
track_script { # 放到哪個實例哪個實例就進行觸發。
check_w_proxy # 觸發檢查。
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 5
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1112
}
virtual_ipaddress {
192.168.136.200/24 dev eth0 label eth0:2
}
}② 重啓並測試配置結果:
[root@lb01 scripts]# /application/nginx/sbin/nginx # 啓動 Nginx。
[root@lb01 scripts]# /etc/init.d/keepalived stop # 關閉 Keepalived 服務。
Stopping keepalived: [ OK ]
[root@lb01 scripts]# /etc/init.d/keepalived start # 啓動 Keepalived 服務。
Starting keepalived: [ OK ]
[root@lb01 scripts]# chmod +x check_w_proxy.sh # 給腳本加執行權限。
[root@lb01 scripts]# ps -ef|grep nginx|grep -v grep # Nginx 服務正常。
root 4485 1 0 00:40 ? 00:00:00 nginx: master process /application/nginx/sbin/nginx
nginx 4486 4485 0 00:40 ? 00:00:00 nginx: worker process
[root@lb01 scripts]# ifconfig|egrep "136.100|136.200" # VIP 工作正常。
inet addr:192.168.136.100 Bcast:0.0.0.0 Mask:255.255.255.0③ 正常情況下殺掉 Nginx 後 Keepalived 會停掉,VIP 飄移到 lb02上面:
[root@lb01 ~]# ip add|grep 136.100 # lb01 上的 VIP 正常工作。
inet 192.168.136.100/24 scope global secondary eth0:1
[root@lb01 ~]# pkill nginx # 殺掉 Nginx 進程。
[root@lb01 ~]# ps -ef|grep keepalived|grep -v grep # 觸發腳本關掉了 Keepalived 服務。
[root@lb01 ~]# ip add|grep 136.100 # lb01 上的 VIP 沒有了(漂移到 lb02 了)。
[root@lb02 scripts]# ip add|egrep "136.100|136.200" # LB02 接替 lb01 的工作,VIP 飄過來。
inet 192.168.136.200/24 scope global secondary eth0:2
inet 192.168.136.100/24 scope global secondary eth0:1
[root@lb01 ~]# /application/nginx/sbin/nginx # 重新啓動 Nginx 服務。
[root@lb01 ~]# /etc/init.d/keepalived start # 重新啓動 Keepalived 服務。
Starting keepalived: [ OK ]
[root@lb01 ~]# ip add|grep 136.100 # lb01 上的 VIP 恢復了正常工作。
inet 192.168.136.100/24 scope global secondary eth0:1
[root@lb02 scripts]# ip add|egrep "136.100|136.200" # lb02 恢復正常工作狀態。
inet 192.168.136.200/24 scope global secondary eth0:22、多組 Keepalived 服務器在一個局域網的衝突問題:
當在同一個局域網內部署了多組 Keepalived 服務器對,而又未使用專門的心跳線通信時,可能會發生高可用接管的嚴重故障問題。Keepalived 高可用功能是通過 VRRP 協議實現的,VRRP 協議默認通過 IP 多播的形式實現高可用對之間的通信,如果同一個局域網內存在多組 Keepalived 服務器對,就會造成 IP 多播地址衝突問題,導致接管錯亂,不同組的 Keepalived 都會使用默認的 224.0.0.
18 作爲多播地址。此時的解決辦法是在同組的 Keepalived 服務器所有的配置文件裏指定獨一無二的多播地址,配置如下:
global_defs {
route_id LVS_19
vrrp_mcast_group4 224.0.0.19 # 這個就是指定多播地址的配置。
}3、配置指定文件接收 Keepalived 服務日誌:
默認情況下 Keepalived 服務日誌會輸出到系統日誌 /var/log/message,和其他日誌信息混合在一起很不方便,可以將其調整成獨立的文件記錄 Keepalived 服務日誌。
[root@lb01 scripts]# tailf /var/log/messages
Jun 24 01:01:32 lb01 Keepalived[5896]: Stopping Keepalived v1.2.13 (03/19,2015)
Jun 24 01:01:32 lb01 Keepalived_vrrp[5899]: VRRP_Instance(VI_1) sending 0 priority
Jun 24 01:01:32 lb01 Keepalived_vrrp[5899]: VRRP_Instance(VI_1) removing protocol VIPs.
Jun 24 01:01:32 lb01 Keepalived_healthcheckers[5898]: Netlink reflector reports IP 192.168.136.100 removed配置指定文件記錄 Keepalived 服務日誌操作步驟:
① 編輯文件 /etc/sysconfig/keepalived 如下:
KEEPALIVED_OPTIONS="-D -d -S 0"
[root@lb01 scripts]# less /etc/sysconfig/keepalived # 查看配置參數的詳細信息。
# --vrrp -P Only run with VRRP subsystem.
# --check -C Only run with Health-checker subsystem.
# --dont-release-vrrp -V Dont remove VRRP VIPs & VROUTEs on daemon stop.
# --dont-release-ipvs -I Dont remove IPVS topology on daemon stop.
# --dump-conf -d Dump the configuration data. # 導出數據。
# --log-detail -D Detailed log messages. # 詳細日誌。
# --log-facility -S 0-7 Set local syslog facility (default=LOG_DAEMON) # 指定設備。
KEEPALIVED_OPTIONS="-D -d -S 0"
[root@lb01 scripts]# sed -i '14 s#KEEPALIVED_OPTIONS="-D"#KEEPALIVED_OPTIONS="-D -d -S 0"#g' /etc/sysconfig/keepalived # 修改內容。
[root@lb01 scripts]# sed -n '14p' /etc/sysconfig/keepalived
KEEPALIVED_OPTIONS="-D -d -S 0"② 修改 /etc/rsyslog.conf 文件添加如下內容:
[root@lb01 scripts]# tail -3 /etc/rsyslog.conf
# keepalived
local0.* /var/log/keepalived.log
# ### end of the forwarding rule ###[root@lb01 scripts]# /etc/init.d/rsyslog restart # 重啓 rsyslog。
Shutting down system logger: [ OK ]
Starting system logger: [ OK ]
[root@lb01 scripts]# cat /var/log/keepalived.log
[root@lb01 scripts]# /etc/init.d/keepalived restart
Stopping keepalived: [FAILED]
Starting keepalived: [ OK ]
[root@lb01 scripts]# cat /var/log/keepalived.log # 生成 Keepalived 日誌內容。
Jun 24 01:49:27 lb01 Keepalived[6057]: Starting Keepalived v1.2.13 (03/19,2015)
Jun 24 01:49:27 lb01 Keepalived[6058]: Starting Healthcheck child process, pid=6060
Jun 24 01:49:27 lb01 Keepalived[6058]: Starting VRRP child process, pid=6061
。。。。。。。。。。。。省略若干內容。。。。。。。。。。。。。③ 讓 /var/log/message 不記錄 Keepalived 日誌:【local0.none】
[root@lb01 scripts]# vim /etc/rsyslog.conf
[root@lb01 scripts]# sed -n '42p' /etc/rsyslog.conf
*.info;mail.none;authpriv.none;cron.none;local0.none /var/log/messages
[root@lb01 scripts]# /etc/init.d/rsyslog restart
Shutting down system logger: [ OK ]
Starting system logger: [ OK ]
[root@lb01 scripts]# > /var/log/messages # 清空系統日誌。
[root@lb01 scripts]# > /var/log/keepalived.log # 清空 Keepalived 日誌。
[root@lb01 scripts]# /etc/init.d/keepalived restart
Stopping keepalived: [ OK ]
Starting keepalived: [ OK ]
[root@lb01 scripts]# cat /var/log/messages # 系統日誌爲空(不再記錄 Keepalived 日誌)。[root@lb01 scripts]# cat /var/log/keepalived.log
# 只有配置的 Keepalived 日誌文件記錄 Keepalived 的日誌。
Jun 24 02:00:47 lb01 Keepalived[6058]: Stopping Keepalived v1.2.13 (03/19,2015)
Jun 24 02:00:47 lb01 Keepalived_vrrp[6061]: VRRP_Instance(VI_1) sending 0 priority
Jun 24 02:00:47 lb01 Keepalived_vrrp[6061]: VRRP_Instance(VI_1) removing protocol VIPs
```.
**4、Keepalived 高可用服務器對裂腦問題:**
**什麼是裂腦:**
由於某些原因,導致兩臺高可用服務器對在指定時間內,無法檢測到對方的心跳信息,各自取得資源及服務的所有權,而此時的兩臺高可用服務器對都還活着並在正常運行,這樣就會導致同一個 IP 或服務在兩端同時存在而發生衝突,最嚴重的是兩臺主機佔用同一個 VIP 地址,每當用戶寫入數據時可能會分別寫入到兩端,這可能會導致服務器兩端的數據不一致或數據丟失,這種情況被稱爲裂腦。
**列腦發生的原因:**
① 高可用服務器對之間心跳線鏈路故障,導致無法正常通信:
心跳線壞了(斷掉、老化);
網卡及相關驅動壞了,IP 配置及衝突問題(網卡直連);
心跳間連接的設備故障(網卡及交換機);
仲裁的機器出問題(採用仲裁的方案)。
② 高可用服務器對上開啓了 iptables 防火牆阻擋了心跳消息傳輸:
③ 高可用服務器對上心跳網卡地址等信息配置不正確,導致發送心跳失敗:
④ 其他服務配置不當等原因,如心跳方式不同,心跳廣播衝突、軟件 Bug 等。
提示:Keepalived 配置統一 VRRP 實例,如果 virtual_route_id 參數兩端配置不一致也會導致裂腦。
**避免裂腦問題的常見方法:**
① 同時使用串行電纜和以太網電纜連接,同時用兩條心跳線路,這樣一條線路壞了,另一個還是好的,依然能傳送心跳信息;
② 當檢測到裂腦時強行關閉一個心跳節點(這個功能需要特殊設備,如 Stonith、Fence)。相當於設備節點接收不到心跳信息,發送關機命令通過單獨的線路關閉主節點的電源;【Stonith:Shoot the other node in the head(爆頭,關掉另一個節點)】。
③ 做好對裂腦的監控報警(如郵件及手機短信等或值班),在問題發生時人爲第一時間介入仲裁,降低損失。例如:百度的監控報警短信就有上行和下行的區別。報警信息報到管理員手機上,管理員可以通過手機回覆對應數字或簡單的字符串操作返回給服務器,讓服務器根據指令自動處理相應故障,這樣解決故障的時間更短。
當然,在實施高可用方案時,要根據實際業務確定是否能容忍這樣的損失,根據不同的需求選擇不同的解決方案(一般網站的常規業務,這個損失是可容忍的)。
**常見的解決裂腦的方案:**
作爲互聯網應用服務器的高可用,特別是前端 Web 負載均衡器的高可用,裂腦的問題對普通業務的影響是可以忍受的,如果是數據庫或者存儲的業務,一般出現裂腦問題就非常嚴重了。因此可以通過增加冗餘心跳線路來避免裂腦問題的發生,同時加強對系統的監控,以便裂腦發生時人爲快速介入解決問題。
① 如果開啓 iptables 防火牆,一定要讓心跳消息通過,一般通過允許 IP 段的方式解決;
② 可以拉一條以太網網線或者串口線作爲主備節點心跳線路的冗餘;
③ 開發檢測程序通過監控軟件(例如 Nagios)監控裂腦。
生產場景檢測裂腦的思路:
① 簡單判斷的思想:只要備節點出現 VIP 就報警,這個報警有兩種情況,一是主機宕機備機接管了;二十主機沒宕,裂腦了,無論哪種情況,都進行報警,然後由人工查看判斷及解決。
② 比較嚴禁的判斷:備節點出現對應 VIP,並且主節點及對應服務(如果遠程連接主節點看是否有 VIP 就更好了)還活着,就說明裂腦了。
在備節點開發腳本測試是否發生裂腦問題:[root@lb01 conf]# cd /server/scripts/
[root@lb01 scripts]# vim check_split_brain.sh
[root@lb01 scripts]# cat check_split_brain.sh
#!/bin/sh
lb01_vip=192.168.136.100
lb01_ip=192.168.136.161
while true
do
ping -c 2 -W 3 $lb01_ip &>/dev/null
if [ $? -eq 0 -a ip add|grep "$lb01_vip"|wc -l -eq 1 ]
then
echo "Ha is split brain.Warning."
else
echo "Ha is OK"
fi
sleep 5
done
[root@lb02 scripts]# sh check_split_brain.sh # 執行腳本檢查結果。
Ha is OK
Ha is OK