




寫代碼的過程難免會出現存在未用代碼的情況 (一般是未用到的函數)
尤其在基礎組件的編碼過程中(有些函數不會被調用)
如何讓生成的二進制可執行文件不包含冗餘信息呢?
情況是這樣的,有一個基礎組件,有六組函數,文件就一個 xxx.h 和 xxx.c
然後編譯成 xxx.o (gcc -c xxx.c)

(37K 的 xxx.o)
然後主程序用到其中的一組函數,於是需要include xxx.h
並且鏈接時需要鏈接到xxx.o (gcc -o main main.c xxx.o 編譯鏈接一起了)

(44K 的 main,實際只用了組件的很小一部分)
後來發現main程序(二進制可執行文件)特別大,因爲這個程序包含了全部六組的函數的代碼
可以使用nm命令來查看 可以清楚的看到全部函數都被鏈接進去了
(nm用來列出目標文件的符號清單)

(箭頭指向的纔是使了的函數,這個圖有誤,但無關痛癢)
原來gcc會直接鏈接整個部分而不管你使用與否
使用 readelf查看生成的 xxx.o文件裏面的 section(段)信息

全部函數和數據之類都是放到一個段(section)的
而鏈接操作以section作爲最小的處理單元,只要一個section中有某個符號被引用,該section就會被放入output中。於是全部代碼都被編譯到了main中。
怎樣解決這個問題呢?查閱了gcc的文檔後
發現有兩個參數可以使用
一個是 -ffunction-sections (爲每個function函數分配獨立的section)
另一個是 -fdata-sections (爲每個data item數據項分配獨立的section)
現在使用 gcc -c -ffunction-sections -fdata-sections xxx.c 編譯

(xxx.o的文件尺寸明顯變大了,因爲段多了)
此時再查看 section信息
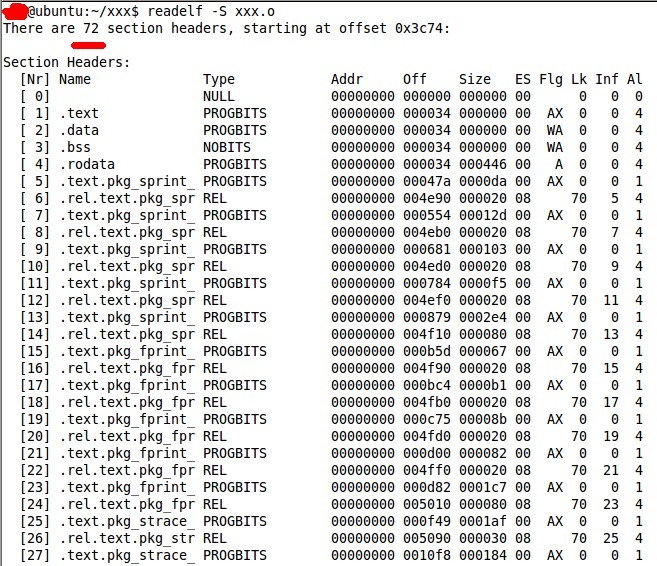
段已經多得顯示不全了(除了接口函數外,還有一系列內部函數)
然後鏈接的時候使用 -Wl,--gc-sections
-Wl,的意思是將後面的內容傳遞給鏈接器
--gc-sections是鏈接器參數,不鏈接未使用的section
現在使用 gcc -Wl,--gc-sections -o main main.c xxx.o 來編譯&鏈接

現在main的大小已經明顯變小了(44K -> 18K)
再用 nm命令查看

原來的符號表已經少了很多了(清除了無用的)
既然可以這樣,爲啥默認不採用這種方式呢?
有人說每個函數分個段,程序執行的時候段間跳轉,多慢啊
應該不會的,可以使用readelf讀取main的信息

可以清楚的看到並沒有很多的(冗餘)段,代碼主體還是在一起的
至於這個參數, gcc的 官方文檔如下

大概意思就是:在目標文件中每個函數、數據項使用獨立的段,段名由函數、數據項名決定。使用這個選項可以提高指令空間的利用率。大多數使用ELF目標文件格式和SPARC處理器運行Solaris2有鏈接器支持它。AIX將來可能支持。當你使用這個時,彙編器和鏈接器會產生更大的目標文件,並且處理得更慢。你也不能使用gprof(一個性能分析工具)在你用了這個選項後,而且如果同時用了-g選項,調試的時候可能會產生問題。
官方文檔就只說明了這些,至於有沒有其他的潛在問題,還得看gcc實現了吧。
在 Release版本中,使用這個還是有明顯的好處的。