




Standby Namenode(sbn)在進入standby狀態後對FSNamesystem調用startStandbyServices(final Configuration conf),該方法會創建兩個重要的對象:EditLogTailer 和 StandbyCheckpointer,前者有兩個功能:
- 觸發Active Namenode(nn) edits log roll
- 從JournalNodes拉取edit log供fsimage合併

後者有三個功能:
-
對namespace進行checkpoint
-
清理陳舊的fsimage文件和edits文件(sbn並不會將拉取的edit log保存到磁盤,所以就不存在清理。nn將edit log寫到本地和JournalNodes,所以就涉及到陳舊edits文件的清理),詳細清理過程後續博客會繼續分析。
-
上傳新checkpoint出的fsimaeg文件到nn

StandbyCheckpointer內部維護一個CheckpointerThread線程,該線程負責週期性檢查checkpoint條件是否滿足,如果滿足就進行checkpoint。
-
檢測週期(checkpointPeriod):1000*Math.min(dfs.namenode.checkpoint.period, dfs.namenode.checkpoint.check.period)秒
-
條件1:最近一次合併到namespace的edit log的 txid 和最近一次做了checkpoint的txid的差值大於或者等於dfs.namenode.checkpoint.txns配置的數量(默認1000000)
-
條件2:當前時間距離最近一次checkpoint的時間間隔大於或者等於dfs.namenode.checkpoint.period (默認3600秒)
CheckpointerThread每隔checkpointPeriod 秒檢查一次。優先檢查條件1是否滿足,如果滿足就進行checkpoint,否則檢查條件2,如果條件2滿足就進行checkpoint,否則就等待下一個檢查週期。一旦條件滿足,就進入doCheckpoint()方法進行checkpoint,流程如下: 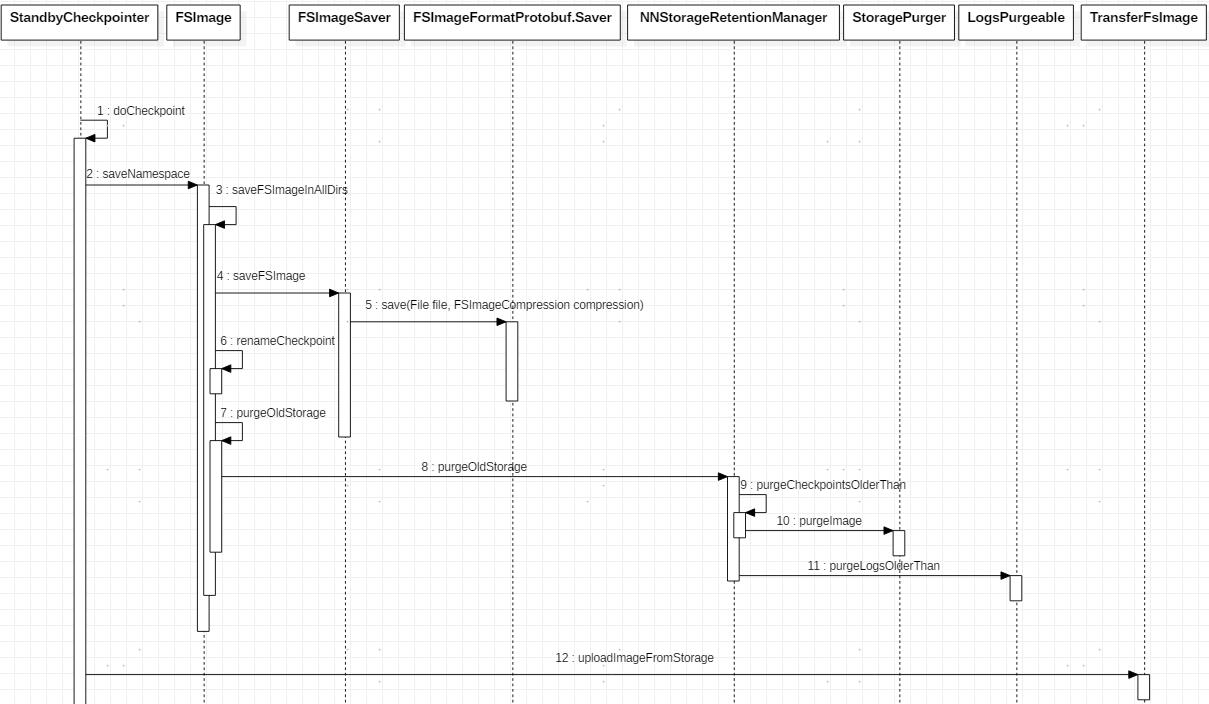
{kind=link}
checkpoint過程本質就是將維護在內存中的namespace全量inode樹導出到磁盤保存爲fsimage_txid文件,並生成fsimage_txid文件的md5保存到fsimage_txid.md5文件。考慮到磁盤故障等問題,sbn 和 nn都可以配置多個目錄保存fsimage文件和edits文件【通常建議將fsimsge和edits分開保存到不同磁盤,這樣可以緩解磁盤壓力,畢竟運行中的nn會頻繁刷editlog到磁盤,checkpoint也會寫大文件到磁盤】,所以就需要將fsimage導出到多個目錄。導出過程由FSImageSaver完成,FSImageSaver實現了Runnable接口,內部根據_Protocol Buffer_定義好的fsimage的數據格式和壓縮格式將namespace寫入fsimage_txid.ckpt文件,寫入完成後再將此文件重名字爲fsimage_txid文件,並生成文件的md5碼保存到fsimage_txid.md5文件。對應於每個保存目錄都會創建一個線程和一個FSImageSaver對象,多個目錄並行導出。
待新的fsimage文件生成之後,sbn會將磁盤上保留的陳舊的fsimage文件清理掉。歷史fsimage文件通常只會在元數據損壞的時候被用來做恢復用,適當保留幾份就夠了,太多了不僅沒用反而浪費磁盤空間。有關清理過程,後續會分析。
最後一步,sbn將新的fsimage文件上傳給nn,這也是sbn除ha外的另一個存在意義。爲了在文件傳輸過程中也能快速完成transition to active(HDFS-4816),StandbyCheckpointer會單獨啓動一個線程,在其內部由TransferFsImage用http協議(nn 用jetty維護了一個ImageServlet 用於 fsimage文件的上傳、下載)完成fsimage傳輸。
涉及到的幾個重要參數:
| 參數名稱 | 說明 | 默認值 |
|---|---|---|
| dfs.namenode.checkpoint.period | checkpoint的時間間隔 | 3600(秒) |
| dfs.namenode.checkpoint.check.period | 檢查週期 | 60(秒) |
| dfs.namenode.checkpoint.txns | 兩次checkpoint間的txid數量,超過該值就應該checkpoint | 1000000 |
| dfs.image.compress | 是否壓縮生成的fsimage文件 | false |
| dfs.image.compression.codec | 壓縮格式 | org.apache.hadoop.io.compress.DefaultCodec |
前三個參數關係到checkpoint的頻率,如果過於頻繁會導致頻繁上傳fsimaeg文件、頻繁寫磁盤,給nn造成壓力,影響正常服務。如果頻率低,則會導致過多事務得不到持久化,最終nn重啓時間延長,sbn也就失去了意義。