




開源項目,請勿用於任何商業用途。
源代碼地址:https://github.com/asdud/Bigdata_project
本項目是基於Spark MLLib的大數據電商推薦系統項目,使用了scala語言和java語言。基於python語言的推薦系統項目會另外寫一篇博客。在閱讀本博客以前,需要有以下基礎:
1.linux的基本命令
2.至少有高中及以上的數學基礎。
3.至少有java se基礎,會scala語言和Java
EE更佳(Jave EE非必需,但是可以幫助你更快理解項目的架構)。
4.有github賬戶,並且至少知道git clone,fork,branch的概念。
5.有網絡基礎,至少知道服務器端和客戶端的區別。
6.有大數據基礎,最好會Hadoop,HDFS,MapReduce,Sqoop,HBase,Hive,Spark,Storm。
7.有mysql數據庫基礎,至少會最基本的增刪改查。
你要是大神,估計看這篇博客也沒有任何用處,至少給點意見和建議唄!
PC配置要求
1.CPU:主流CPU即可
2.內存RAM:至少8G,推薦16G及以上,32G不浪費。
3.硬盤:由於VM對I/O流讀取速度要求高,推薦使用256G及以上固態硬盤(SATA3即可.NVME更好),系統盤需要60-100G,其餘的專門劃一個盤用於安裝虛擬機。或者採用傲騰內存+機械硬盤的方案。
4.GPU顯卡;無要求。但是如果你想學習深度學習框架的話,可考慮1060 6g甚至是2080TI。
5.網速:CentOS 8GB多,HDP接近7個G,CDH幾個包加起來2.5G。自己算算需要下載多長時間,或者考慮用U盤從別人那裏拷貝?
你也可以考慮用阿里雲,騰訊雲等雲主機。
步驟一:
搭建CentOS+HDP的環境,或者CentOS+CDH的環境,這些都是開源的,不用擔心版權問題,企業上一般也是用這兩種方案。
在這裏我採用的是CentOS+HDP的方案
大數據之搭建HDP環境,以三個節點爲例(上——部署主節點以及服務)
http://blog.51cto.com/6989066/2173573
大數據之搭建HDP環境,以三個節點爲例(下——擴展節點,刪除節點,以及部署其他服務)
http://blog.51cto.com/6989066/2175476
也可以採用CentOS+CDH的方案
搭建CDH實驗環境,以三個節點爲例的安裝配置
http://blog.51cto.com/6989066/2296064
開發工具:Eclipse oxygen版本或者IDEA
代碼實現部分
1.數據:用戶查詢日誌來源
搜狗實驗室
.https://www.sogou.com/labs/resource/q.php
介紹:
搜索引擎查詢日誌庫設計爲包括約1個月(2008年6月)Sogou搜索引擎部分網頁查詢需求及用戶點擊情況的網頁查詢日誌數據集合。爲進行中文搜索引擎用戶行爲分析的研究者提供基準研究語料
格式說明:
數據格式爲
訪問時間\t用戶ID\t[查詢詞]\t該URL在返回結果中的排名\t用戶點擊的順序號\t用戶點擊的URL
其中,用戶ID是根據用戶使用瀏覽器訪問搜索引擎時的Cookie信息自動賦值,即同一次使用瀏覽器輸入的不同查詢對應同一個用戶ID
2.首先新建一個Maven工程MyMapReduceProject,然後更新pom.xml文件
pom文件地址
https://github.com/asdud/Bigdata_project/blob/master/MyMapReduceProject/pom.xml
這個時候就會自動下載對應的依賴的jar包
查詢搜索結果排名第1點,擊次序排在第2的數據
使用MapReduce進行分析處理
https://github.com/asdud/Bigdata_project/blob/master/MyMapReduceProject/src/main/java/day0629/sogou/SogouLogMain.java
https://github.com/asdud/Bigdata_project/blob/master/MyMapReduceProject/src/main/java/day0629/sogou/SogouLogMapper.java
使用Spark進行分析和處理
首先使用Ambari,添加Spark2的服務;由於依賴其他的服務,比如Hive等等,需要在啓動Ambari Server的時候,指定MySQL的JDBC驅動。
登錄spark-shell,需要用下面的方式:
spark-shell --master yarn-client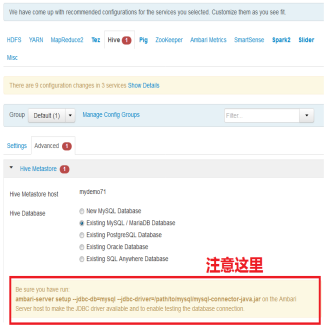
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar
jdbc-driver地址與你安裝mysql-connector-java.jar目錄對應。
推薦系統常用算法
協同過濾算法
協同過濾算法(Collaborative Filtering:CF)是很常用的一種算法,在很多電商網站上都有用到。CF算法包括基於用戶的CF(User-based CF)和基於物品的CF(Item-based CF)。