




GBDT的核心就在於累加所有樹的結果作爲最終結果。
分類樹
決策樹的分類算法有很多,以具有最大熵的特徵進行分類,以信息增益特徵進行分類(ID3),以增益率特徵進行分類(C4.5),以基尼係數特徵進行分類(CART分類與迴歸樹)等等。這一類決策樹的特點就是最後的結果都是離散的具體的類別,比如蘋果的好/壞,性別男/女。
迴歸樹
迴歸樹與分類樹的流程大致一樣,不同的是迴歸樹在每個節點都會有一個預測值,以年齡爲例,該節點的預測值就是所有屬於該節點的樣本的年齡的均值。
那回歸樹是根據什麼來劃分特徵的呢?
分類樹的最大熵、信息增益、增益率什麼的在迴歸樹這都不適用了,迴歸樹用的是均方誤差。遍歷每個特徵,窮舉每個特徵的劃分閾值,而這裏不再使用最大熵,使用的是最小化均方差——(每個人的年齡-預測年齡)^2/N,N代表節點內樣本數。這很好理解,和預測年齡差距越大,均方差也就越大。因此要找到均方差最小的閾值作爲劃分點。
劃分的結束條件一般有兩個:第一是劃分到每一個節點都只包含一個年齡值,但是這太難了;第二就是劃分到一定的深度就停止,取節點內數據的均值作爲最終的預測值。
XGBoost
XGBoost其實是由一羣訓練出來的CART迴歸樹集成出來的模型。
明確目標
我們的目標其實就是訓練一羣迴歸樹,使這樹羣的預測值儘量接近真實值,並且有儘可能強大的泛化能力。來看看我們的優化函數: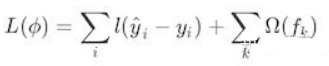
i表示的是第i個樣本,前一項是表示的是預測誤差。後一項表示的是樹的複雜度的函數,值越小表示複雜度越低,泛化能力越強。我們來看看後一項的表達式: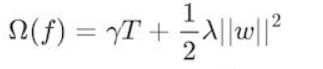
樹的複雜度函數
其中T表示葉子節點的個數,w表示的是節點的預測值(迴歸樹的節點纔有預測值)。
我們要做的就是使預測誤差儘量小,葉子節點數儘量少,預測值儘量不極端(什麼叫預測值儘量不極端?舉個栗子,一個人的真實年齡是4歲,有兩個模型,第一個模型的第一顆迴歸樹預測值是3歲,第二顆迴歸樹預測值是1歲,第二個模型的第一顆迴歸樹預測值是2歲,第二顆預測值也是2歲,那我們更傾向於選擇第二個模型,因爲第一個模型學習的太多,有過擬合的風險)
那麼我們如何才能把優化函數和迴歸樹的參數聯繫在一起呢?迴歸樹的參數我們知道有兩個:(1)選哪個feature進行分裂(2)如何求取節點的預測值,上述公式並沒有很好地反映出這兩個問題的答案,那麼是如何解決上述兩個問題的呢?
答案就是:貪心策略+最優化(二次最優化)
貪心策略
那麼是如何運用貪心策略(眼前利益最大化,每個節點的預測值都選最優)的呢?假設我們有一堆樣本,放在第一個節點,這時T=1,w是多少呢?暫時不知道,w是計算出來的,這時所有的樣本的w都相等,將w和T代入優化函數中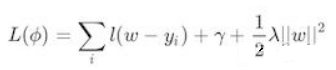
第一步的優化函數
如果我們這裏的l(w-y_i)損失函數使用的是平方損失函數,那麼上式就變成了一個關於w的二次函數,最小的點就是極值點也就是該節點的預測值。
到這你可能發現了,這不就是二次函數的最優化問題嗎?
那如果損失函數不是平方誤差函數怎麼辦?我們採用的是泰勒展開的方式,任何函數總能用泰勒展開的方法表示,不是二次函數我們總能想辦法讓它變成二次函數。
那麼我們再來看我們的兩個問題:
(1)選哪個feature進行分裂?最粗暴的枚舉法,用損失函數效果最好的那一個(粗暴枚舉和XGBoost的並行化等我們在後面介紹)
(2)如何求取節點的預測值,對!就是我們剛剛說到的二次函數求最值(固定套路:二次函數求導爲零的點就是最優值)!
那麼步驟就是:枚舉第一個feature,計算loss_function的最小值,枚舉第二個feature,計算loss_function的最小......直到遍歷完所有的feature,選擇效果最好的feature,將feature的值分成大於w和小於w的兩類,這不就把樹給分成兩叉了嗎?
接下來繼續分裂,在上一個分類的基礎上,又形成一棵樹,再形成一棵樹,每次都是在最優的基礎上進行分裂,不就是我們的貪心策略麼。
但是一般這種循環迭代的方式都需要一個終止條件,總不能讓它一直跑下去吧。
停止條件
停止條件大概有以下幾種:
(1)當引入的分裂帶來的增益(loss_function的降低量)小於一個閾值的時候,可以剪掉當前的分裂,所以並不是每一次分裂loss_function都會增加的。
(2)當樹達到最大深度時,停止建樹,因爲樹的深度太深容易出現過擬合,這裏需要設置一個超參數max_depth。
(3)當樣本權重和小於某一個閾值時也停止建樹,涉及到一個超參數:最小樣本權重和,大意就是如果每個葉子節點包含的樣本數量太少也停止,同樣是過擬合的原因。
XGBoost的亮點(重點)
節點權值
XGBoost的權值是通過最優化二次函數(求導)求出來的,算是一種創新吧,和普通的求均值的或者其他什麼規則不一樣。
避免過擬合(正則化、shrinkage與採樣技術)
正則化
一說起過擬合,我們的第一反應就是正則化。XGBoost也是這樣做的。
我們在loss_function裏看到了正則化項(樹的複雜度函數),正則化的目的就是防止過擬合。我們再看看這個函數: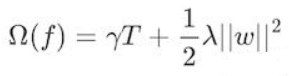
樹的複雜度函數
這裏出現了γ和λ,這是XGBoost自己定義的,在使用XGBoost時,你可以設定它們的值,顯然,γ越大,表示越希望獲得結構簡單的樹,因爲要整體最小化的話就要最小化T。λ越大也是越希望獲得結構簡單的樹。
Shrinkage
除了使用正則化,我們還有shrinkage與採樣技來避免過擬合的出現。
所謂的shrinkage就是在每次的迭代產生的樹中,對每個葉子結點乘以一個縮減權重,主要的目的就是縮減該次迭代產生的樹的影響力,留給後邊迭代生成的樹更多發揮的空間。
舉個栗子:比如第一棵樹預測值爲3.3,label爲4.0,第二棵樹才學0.7,那後面的樹就沒啥可學的了,所以給他打個折扣,比如3折,那麼第二棵樹訓練的殘差爲4.0-3.3*0.3=3.01,這就可以發揮了啦,以此類推,作用的話,就是防止過擬合。
採樣技術
採樣技術有兩種,分別是行採樣和列採樣。
列採樣效果比較好的是按層隨機的方法:之前提到,每次分裂節點的時候我們都要遍歷所有的特徵和分割點,來確定最優分割點。如果加入列採樣,我們會在同一層的結點分割前先隨機選一部分特徵,遍歷的時候只用遍歷這部分特徵就行了。
行採樣則是採用bagging的思想,每次只抽取部分樣本進行訓練,不使用全部的樣本,可以增加樹的多樣性。
損失函數
這個點也是XGBoost比較bug的地方,因爲XGBoost能夠自定義損失函數,只要能夠使用泰勒展開(能求一階導和二階導)的函數,都可以拿來做損失函數。你開心就好!
支持並行化
一直聽別人說XGBoost能並行計算,感覺這纔是XGBoost最bug的地方,但是直觀上並不好理解,明明每次分裂節點都用到了上一次的結果,明明是個串行執行的過程,並行這個小妖精到底在哪?答案就在我們的第一個問題之中:選哪個feature進行分裂?就是在枚舉,選擇最佳分裂點的時候進行(讀者可以先試着往下讀,如果理解不了的話建議將之前文章提過的AdaBoost的代碼實現一遍,有助於理解)。
注意:同層級節點之間可以並行。節點內選擇最佳分裂點,候選分裂點計算增益使用並行。
每個節點都包含樣本,我們要從中節點樣本的每一個feature中選擇最佳的分裂值。如果feature的值是離散的,比如判斷性別男/女,這樣的feature計算增益很容易。但是如果feature的值是連續的,從5k-10k都有,總不能一個一個值都當做分裂點來計算增益吧(缺點:1、計算量太大;2、分割後的葉子節點樣本過少,過擬合),常用的方法是劃分區間,具體怎麼劃分呢?
XGBoost的作者提出了一種算法:Weighted Quantile Sketch
一般的,我們的loss_function泰勒展開之後長這樣: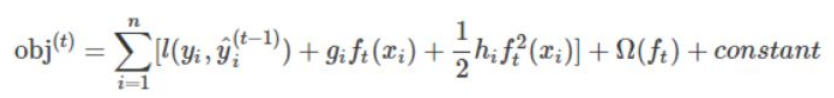
泰勒展開後的一般損失函數
f_t(x_i)是什麼?它其實就是f_t的某個葉子節點的值。之前我們提到過,葉子節點的值是可以作爲模型的參數的。其中:
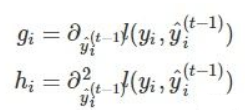
g_i和h_i
其實這裏的g_i和h_i描述的就是不同的預測值對loss_function的影響。
用通俗的例子來解釋算法:
將收入值升序排列:(5k,5.1k,5.2k...,10k),分割線(收入1,收入2,...,),滿足(節點內每個間隔的樣本的h_i之和/節點總的h_i之和)某個百分比ϵ,所以大約有1/ϵ個分裂點。
針對稀疏數據的解決方法
實際應用中,稀疏數據無法避免,產生稀疏數據的原因:(1)數據缺失;(2)統計上的0;(3)特徵表示中的one-hot形式;以往的經驗,出現稀疏值的時候算法需要很好地自適應,XGBoost提出的方法如下:
假設樣本的第i個特徵缺失,無法使用該特徵進行樣本劃分,那我們就把缺失樣本默認的分到某個節點,具體分到哪個節點還要根據算法:
算法思想:分別假設缺失屬於左節點和右節點,而且只在不缺失的樣本上迭代,分別計算樣本屬於左子樹和右子樹的增益,選擇增益最大的方向作爲缺失數據的默認方向。