




018 年接近尾聲,我018 年接近尾聲,我策劃了“解讀 2018”年終技術盤點系列文章,希望能夠給讀者清晰地梳理出重要技術領域在這一年來的發展和變化。本文是實時流計算 2018 年終盤點,作者對實時流計算技術的發展現狀進行了深入剖析,並對當前大火的各個主流實時流計算框架做了全面、客觀的對比,同時對未來流計算可能的發展方向進行預測和展望。
策劃了“解讀 2018”年終技術盤點系列文章,希望能夠給讀者清晰地梳理出重要技術領域在這一年來的發展和變化。本文是實時流計算 2018 年終盤點,作者對實時流計算技術的發展現狀進行了深入剖析,並對當前大火的各個主流實時流計算框架做了全面、客觀的對比,同時對未來流計算可能的發展方向進行預測和展望。
今年實時流計算技術爲何這麼火
今年除了正在熱火落地的 AI 技術,實時流計算技術也開始步入主流,各大廠都在不遺餘力地試用新的流計算框架,升級替換 Storm 這類舊系統。上半年 P2P 狂想曲的驟然破滅,讓企業開始正視價值投資。互聯網下半場已然開始,線上能夠榨錢的不多了,所以,技術和資本開始賦能線下,如拼多多這類奇思妙想劍走偏鋒實在不多。
而物聯網這個早期熱炒的領域連接線上線下,如今已積累的足夠。物聯網卡包年資費降到百元以下,NB-IoT 技術的興起在畜牧業、新農業、城市管理方面都凸顯極大價值。各大廠都在血拼智能城市、智慧工廠、智慧醫療、車聯網等實體領域。但,這些跟實時流計算有幾毛錢的關係?
上述領域有一個共同的特點,那就是實時性。城市車流快速移動、工廠流水線不等人、醫院在排號、叫的外賣在快跑,打車、點餐、網購等等,人們無法忍受長時間等待,等待意味着訂單流失。所以,毫秒級、亞秒級大數據分析就凸顯極大價值。流計算框架和批計算幾乎同時起步,只不過流計算現在能挖掘更大的利益價值,纔會火起來。
實時流計算框架一覽
目前首選的流計算引擎主要是 Flink 和 Spark,第二梯隊 Kafka、Pulsar,小衆的有 Storm、JStorm、nifi、samza 等。下面逐一簡單介紹下每個系統優缺點。
Flink 和 Spark是分佈式流計算的首選,下文會單獨對二者做對比分析。
Storm、JStorm、Heron:較早的流計算平臺。相對於 MapReduce,Storm 爲流計算而生,是早期分佈式流計算框架首選。但 Storm 充其量是個半成品,ack 機制並不優雅,exactly-once 恰好一次的可靠性語義不能保證。不丟數據、不重複數據、不丟也不重地恰好送達,是不同可靠性層次。Clojure 提供的 LISP 方言反人類語法,學習成本極爲陡峭。後來阿里中間件團隊另起爐竈開發了 JStorm。JStorm 在架構設計理念上比 Storm 好些,吞吐、可靠性、易用性都有大幅提升,容器化跟上了大勢。遺憾的是,阿里還有 Blink(Flink 改進版),一山不容二虎,JStorm 團隊擁抱變化,項目基本上停滯了。另起爐竈的還有 twitter 團隊,搞了個 Heron,據說在 twitter 內部替換了 Storm,也經過了大規模業務驗證。但是,Heron 明顯不那麼活躍,乏善可陳。值得一提的是,Heron 的存儲用了 twitter 開源的另一個框架 DistributedLog。
DistributedLog、Bookkeeper、Pulsar、Pravega:大家寫 Spark Streaming 作業時,一定對裏面 kafka 接收到數據後,先保存到 WAL(write ahead log)的代碼不陌生。DistributedLog 就是一個分佈式的 WAL(write ahead log)框架,提供毫秒級時延,保存多份數據確保數據可靠性和一致性,優化了讀寫性能。又能跑在 Mesos 和 Yarn 上,同時提供了多租戶能力,這跟公有云的多租戶和企業多租戶特性契合。Bookeeper 就是對 DistributedLog 的再次封裝,提供了高層 API 和新的特性。而 Pulsar 則是自己重點做計算和前端數據接入,趕上了 serverless 潮流,提供輕量級的 function 用於流計算,而存儲交給了 DistributedLog。Pulsar 在流計算方面有新意,但也只是對 Flink 和 Spark 這類重量級框架的補充。筆者認爲,Pulsar 如果能在 IoT 場景做到捨我其誰,或許還有機會。 Pravega 是 Dell 收購的團隊,做流存儲,內部也是使用 Bookeeper,主要用於 IoT 場景。四者關係大致如此。
Beam、Gearpump、Edgent:巨頭的佈局。三個項目都進入 Apache 基金會了。Beam 是 Google 的,Gearpump 是 Intel 的,Edgent 是 IBM 的,三巨頭提前對流計算做出了佈局。Gearpump 是以 Akka 爲核心的分佈式輕量級流計算,Akka stream 和 Akka http 模塊享譽技術圈。Spark 早期的分佈式消息傳遞用 Akka,Flink 一直用 Akka 做模塊間消息傳遞。Akka 類似 erlang,採用 Actor 模型,對線程池充分利用,響應式、高性能、彈性、消息驅動的設,CPU 跑滿也能響應請求且不死,可以說是高性能計算中的奇葩戰鬥機。Gearpum 自從主力離職後項目進展不大,且在低功耗的 IoT 場景裏沒有好的表現,又幹不過 Flink 和 Spark。Edgent 是爲 IoT 而生的,內嵌在網關或邊緣設備上,實時分析流數據,目前還在 ASF 孵化中。物聯網和邊緣計算要依託 Top 級的雲廠商才能風生水起,而各大廠商都有 IoT 主力平臺,僅靠 Edgent 似乎拼不過。
Kafka Stream: Kafka 是大數據消息隊列標配,基於 log append-only,得益於零拷貝,Kafka 成爲大數據場景做高吞吐的發佈訂閱消息隊列首選。如今,不甘寂寞的 Kafka 也幹起了流計算,要處理簡單的流計算場景,Kafka SQL 是夠用的。但計算和存儲分離是行業共識,資源受限的邊緣計算場景需要考慮計算存儲一體化。重量級的 Kafka 在存儲的同時支持流分析,有點大包大攬。第一,存儲計算界限不明確,都在 Kafka 內;第二,Kafka 架構陳舊笨重,與基於 DistributedLog 的流存儲體系相比仍有差距;計算上又不如 Pulsar 等輕量。Kafka Stream SQL 輪子大法跟 Flink SQL 和 Spark SQL 有不小差距。個人感覺,危機大於機遇。
實時流計算技術的進一步發展,需要 IoT、工業 IoT、智慧 xx 系列、車聯網等新型行業場景催生,同時背靠大樹纔好活。
後來者 Flink
Flink 到 16 年纔開始嶄露頭角,不得不八卦一下其發家史。
Stratosphere項目最早在 2010 年 12 月由德國柏林理工大學教授 Volker Markl 發起,主要開發人員包括 Stephan Ewen、Fabian Hueske。Stratosphere 是以 MapReduce 爲超越目標的系統,同時期有加州大學伯克利 AMP 實驗室的 Spark。相對於 Spark,Stratosphere 是個徹底失敗的項目。所以 Volker Markl 教授參考了谷歌的流計算最新論文 MillWheel,決定以流計算爲基礎,開發一個流批結合的分佈式流計算引擎 Flink。Flink 於 2014 年 3 月進入 Apache 孵化器並於 2014 年 11 月畢業成爲 Apache 頂級項目。
流批合一,是以流爲基礎,批是流的特例或上層 API;批流合一,是以批計算爲基礎,微批爲特例,粘合模擬流計算。
Spark vs. Flink
醜話說在前面,筆者無意於撩撥 Flink 和 Spark 兩個羣體的矛盾,社區間取長補短也好,互相抄襲也好,都不是個事,關鍵在於用戶羣體的收益。
在各種會上,經常會被問到 Spark 和 Flink 的區別,如何取捨?
下面從數據模型、運行時架構、調度、時延和吞吐、反壓、狀態存儲、SQL 擴展性、生態、適用場景等方面來逐一分析。
數據模型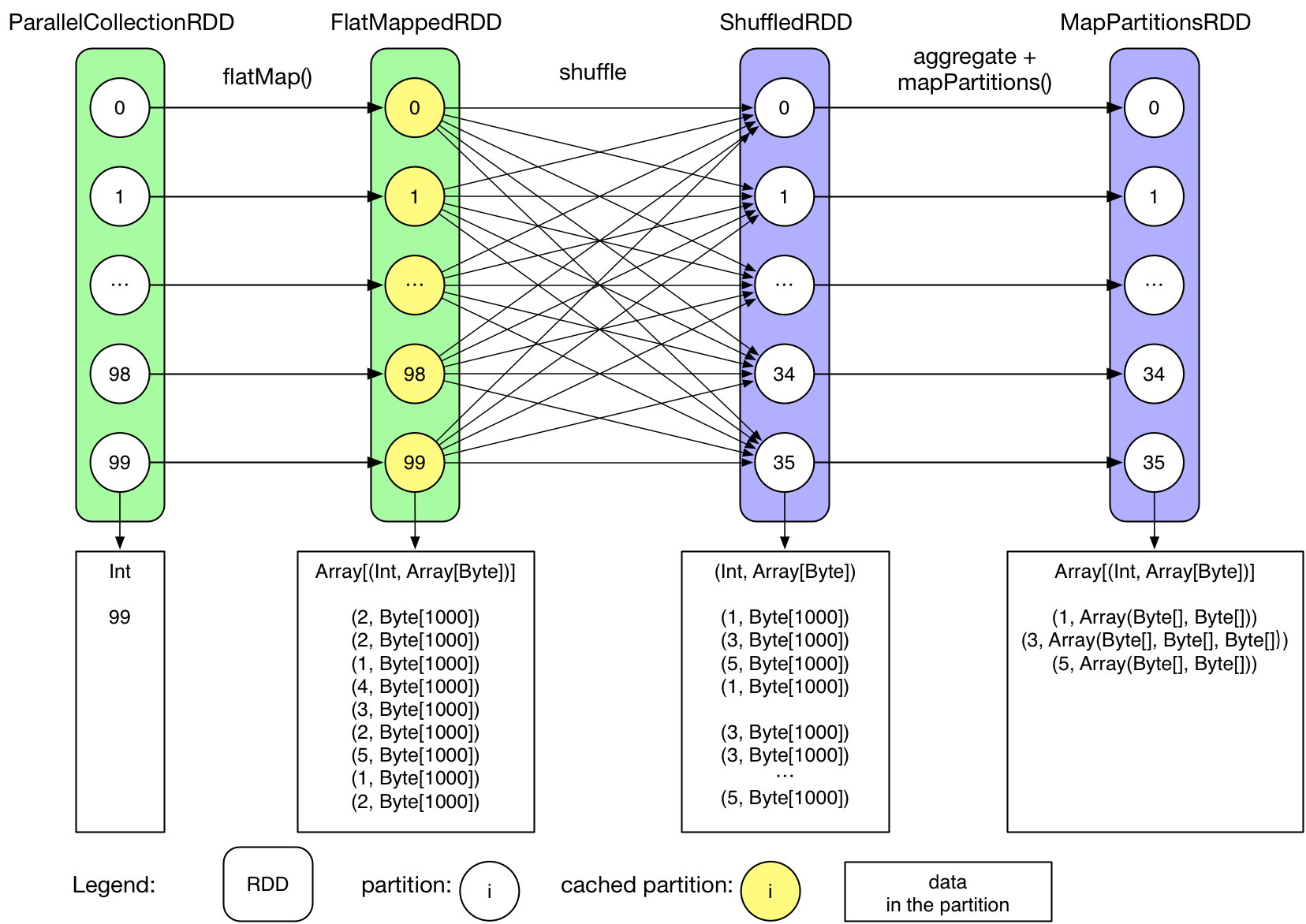
Spark RDD 關係圖。圖片來自 JerryLead 的 SparkInternals 項目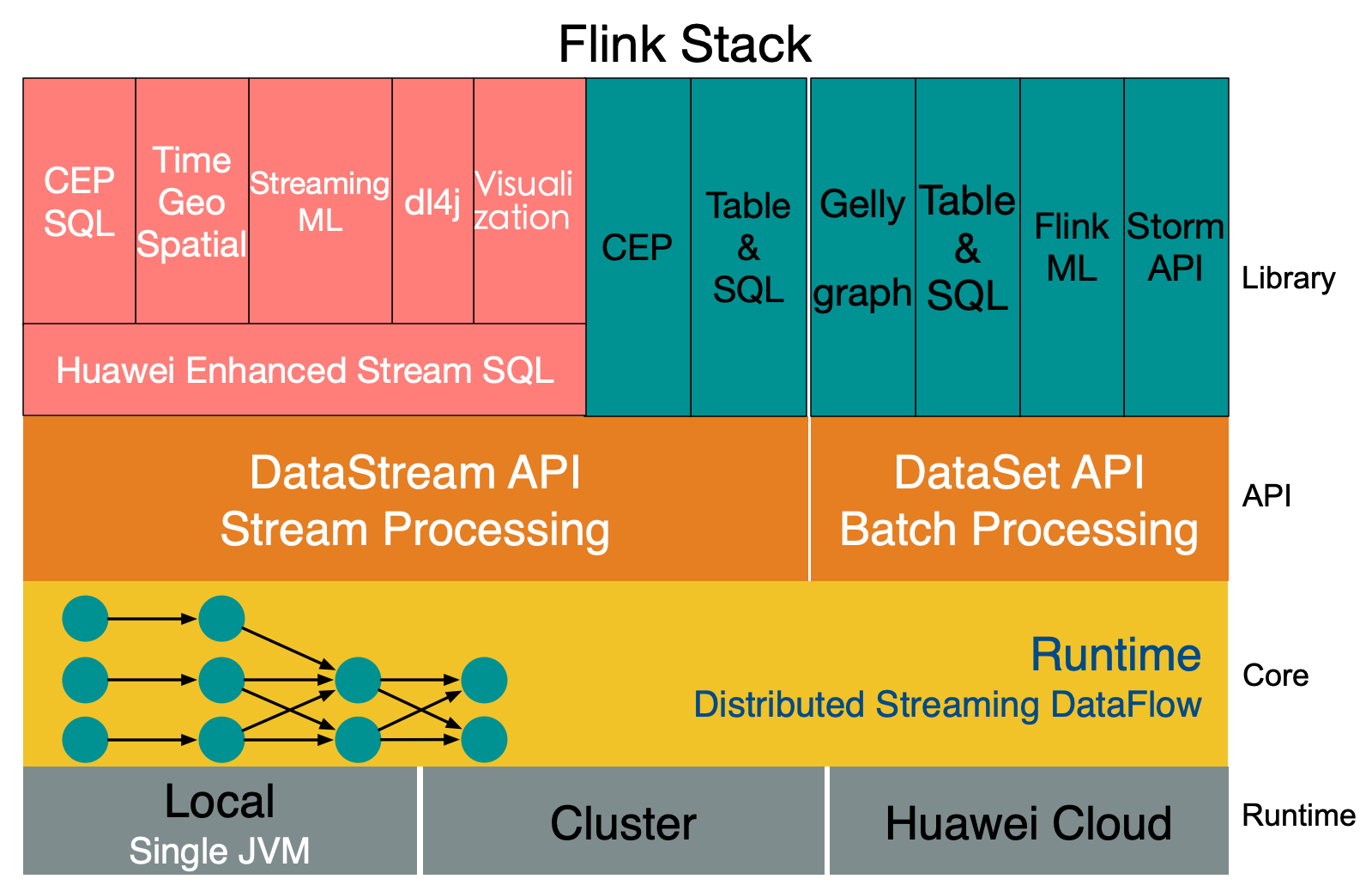
Flink 框架圖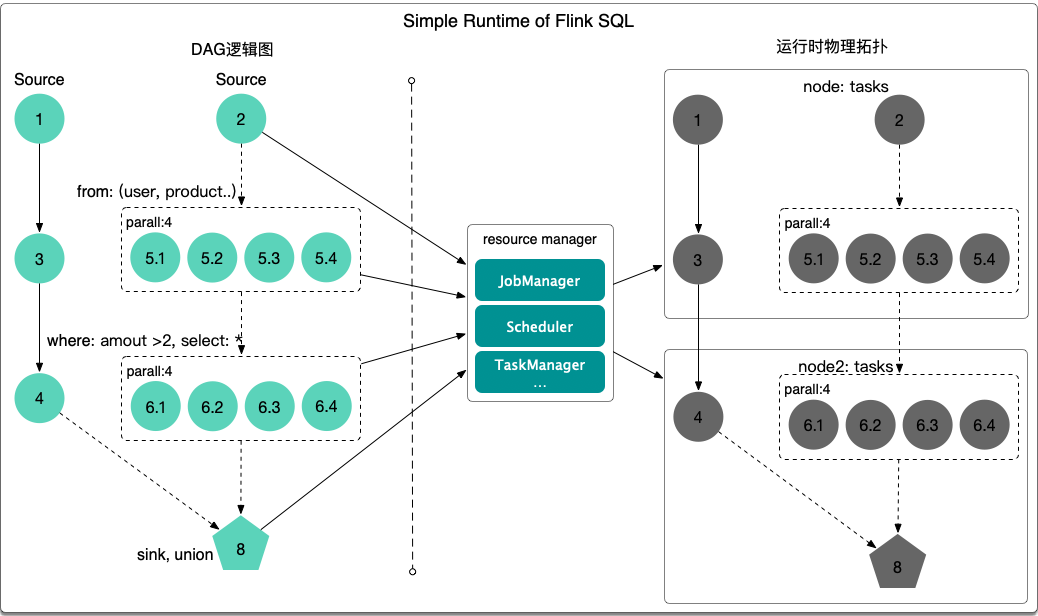
Flink 運行時
Spark 的數據模型
Spark 最早採用 RDD 模型,達到比 MapReduce 計算快 100 倍的顯著優勢,對 Hadoop 生態大幅升級換代。RDD 彈性數據集是分割爲固定大小的批數據,RDD 提供了豐富的底層 API 對數據集做操作。爲持續降低使用門檻,Spark 社區開始開發高階 API:DataFrame/DataSet,Spark SQL 作爲統一的 API,掩蓋了底層,同時針對性地做 SQL 邏輯優化和物理優化,非堆存儲優化也大幅提升了性能。
Spark Streaming 裏的 DStream 和 RDD 模型類似,把一個實時進來的無限數據分割爲一個個小批數據集合 DStream,定時器定時通知處理系統去處理這些微批數據。劣勢非常明顯,API 少、難勝任複雜的流計算業務,調大吞吐量而不觸發背壓是個體力活。不支持亂序處理,把前面的 Kafka topic 設置爲 1 個分區,雞賊式緩解亂序問題。Spark Streaming 僅適合簡單的流處理,會被 Structured Streaming 完全替代。
Spark Structured Streaming 提供了微批和流式兩個處理引擎。微批的 API 雖不如 Flink 豐富,窗口、消息時間、trigger、watermarker、流表 join、流流 join 這些常用的能力都具備了。時延仍然保持最小 100 毫秒。當前處在試驗階段的流式引擎,提供了 1 毫秒的時延,但不能保證 exactly-once 語義,支持 at-least-once 語義。同時,微批作業打了快照,作業改爲流式模式重啓作業是不兼容的。這一點不如 Flink 做的完美。
綜上,Spark Streaming 和 Structured Streaming 是用批計算的思路做流計算。其實,用流計算的思路開發批計算纔是最優雅的。對 Spark 來講,大換血不大可能,只有局部優化。其實,Spark 裏 core、streaming、structured streaming、graphx 四個模塊,是四種實現思路,通過上層 SQL 統一顯得不純粹和諧。
Flink 的數據模型
Flink 採用 Dataflow 模型,和 Lambda 模式不同。Dataflow 是純粹的節點組成的一個圖,圖中的節點可以執行批計算,也可以是流計算,也可以是機器學習算法,流數據在節點之間流動,被節點上的處理函數實時 apply 處理,節點之間是用 netty 連接起來,兩個 netty 之間 keepalive,網絡 buffer 是自然反壓的關鍵。經過邏輯優化和物理優化,Dataflow 的邏輯關係和運行時的物理拓撲相差不大。這是純粹的流式設計,時延和吞吐理論上是最優的。
Flink 在流批計算上沒有包袱,一開始就走在對的路上。
運行時架構
Spark 運行時架構
批計算是把 DAG 劃分爲不同 stage,DAG 節點之間有血緣關係,在運行期間一個 stage 的 task 任務列表執行完畢,銷燬再去執行下一個 stage;Spark Streaming 則是對持續流入的數據劃分一個批次,定時去執行批次的數據運算。Structured Streaming 將無限輸入流保存在狀態存儲中,對流數據做微批或實時的計算,跟 Dataflow 模型比較像。
Flink 運行時架構
Flink 有統一的 runtime,在此之上可以是 Batch API、Stream API、ML、Graph、CEP 等,DAG 中的節點上執行上述模塊的功能函數,DAG 會一步步轉化成 ExecutionGraph,即物理可執行的圖,最終交給調度系統。節點中的邏輯在資源池中的 task 上被 apply 執行,task 和 Spark 中的 task 類似,都對應線程池中的一個線程。
在流計算的運行時架構方面,Flink 明顯更爲統一且優雅一些。
時延和吞吐
兩家測試的 Yahoo benchmark,各說各好。benchmark 雞肋不可信,筆者測試的結果,Flink 和 Spark 的吞吐和時延都比較接近。
反壓
Flink 中,下游的算子消費流入到網絡 buffer 的數據,如果下游算子處理能力不夠,則阻塞網絡 buffer,這樣也就寫不進數據,那麼上游算子發現無法寫入,則逐級把壓力向上傳遞,直到數據源,這種自然反壓的方式非常合理。Spark Streaming 是設置反壓的吞吐量,到達閾值就開始限流,從批計算上來看是合理的。
狀態存儲
Flink 提供文件、內存、RocksDB 三種狀態存儲,可以對運行中的狀態數據異步持久化。打快照的機制是給 source 節點的下一個節點發一條特殊的 savepoint 或 checkpoint 消息,這條消息在每個算子之間流動,通過協調者機制對齊多個並行度的算子中的狀態數據,把狀態數據異步持久化。
Flink 打快照的方式,是筆者見過最爲優雅的一個。Flink 支持局部恢復快照,作業快照數據保存後,修改作業,DAG 變化,啓動作業恢復快照,新作業中未變化的算子的狀態仍舊可以恢復。而且 Flink 也支持增量快照,面對內存超大狀態數據,增量無疑能降低網絡和磁盤開銷。
Spark 的快照 API 是 RDD 基礎能力,定時開啓快照後,會對同一時刻整個內存數據持久化。Spark 一般面向大數據集計算,內存數據較大,快照不宜太頻繁,會增加集羣計算量。
SQL 擴展性
Flink 要依賴 Apache Calcite 項目的 Stream SQL API,而 Spark 則完全掌握在自己手裏,性能優化做的更足。大數據領域有一個共識:SQL 是一等公民,SQL 是用戶界面。SQL 的邏輯優化和物理優化,如 Cost based optimizer 可以在下層充分優化。UDX 在 SQL 之上可以支持在線機器學習 StreamingML、流式圖計算、流式規則引擎等。由於 SQL 遍地,很難有一個統一的 SQL 引擎適配所有框架,一個個 SQL-like 煙囪同樣增加使用者的學習成本。
生態和適用場景
這兩個方面 Spark 更有優勢。
Spark 在各大廠實踐多年,跟 HBase、Kafka、AWS OBS 磨合多年,已經成爲大數據計算框架的事實標準,但也有來自 TensorFlow 的壓力。14 年在生產環境上跑機器學習算法,大多會選擇 Spark,當時我們團隊還提了個 ParameterServer 的 PR,社區跟進慢也就放棄了。社區爲趕造 SQL,錯過了 AI 最佳切入時機。這兩年 Spark+AI 勢頭正勁,Matei 教授的論文 Weld 想通過 monad 把批、流、圖、ML、TensorFlow 等多個系統粘合起來,統一底層優化,想法很贊;處於 beta 階段的 MLFlow 項目,把 ML 的生命週期全部管理起來,這些都是 Spark 新的突破點。
反觀 Flink 社區,對周邊的大數據存儲框架支持較好,但在 FlinkML 和 Gelly 圖計算方面投入極匱乏,16 年給社區提 PS 和流式機器學習,沒一點進展。筆者在華爲雲這兩年多時間,選擇了 Flink 作爲流計算平臺核心,索性在 Flink 基礎之上開發了 StreamingML、Streaming Time GeoSpatial、CEP SQL 這些高級特性,等社區搞,黃花菜都涼了。
企業和開發者對大數據 AI 框架的選擇,是很重的技術投資,選錯了損失會很大。不僅要看框架本身,還要看背後的公司。
Spark 後面是 Databricks,Databricks 背靠伯克利分校,Matei、Reynold Xin、孟祥瑞等高手如雲。Databricks Platform 選擇 Azure,14 年 DB 就用改造 notebook 所見即所得的大數據開發平臺,前瞻性強,同時對 AWS 又有很好的支持。商業和技術上都是無可挑剔的。
Flink 後面是 DataArtisans,今年也推出了 data Artisans Platform,筆者感覺沒太大新意,對公有云私有云沒有很好的支持。DataArtisans 是德國公司,團隊二三十人,勤勉活躍在 Flink 社區,商業上或許勢力不足。
開源項目後面的商業公司若不在,項目本身必然走向滅亡,純粹靠分散的發燒友的力量無法支撐一個成功的開源項目。Databricks 估值 1.4 億美元,DataArtisans 估值 600 萬美元,23 倍的差距。DataArtisans 的風險在於變現能力,因爲盤子小所以有很大風險被端盤子,好在 Flink 有個好的 Dataflow 底子。這也是每個開源項目的難題,既要商業支撐開銷,又要中立發展。
對比小結
囉嗦這麼多,對比下 Flink 和 Spark: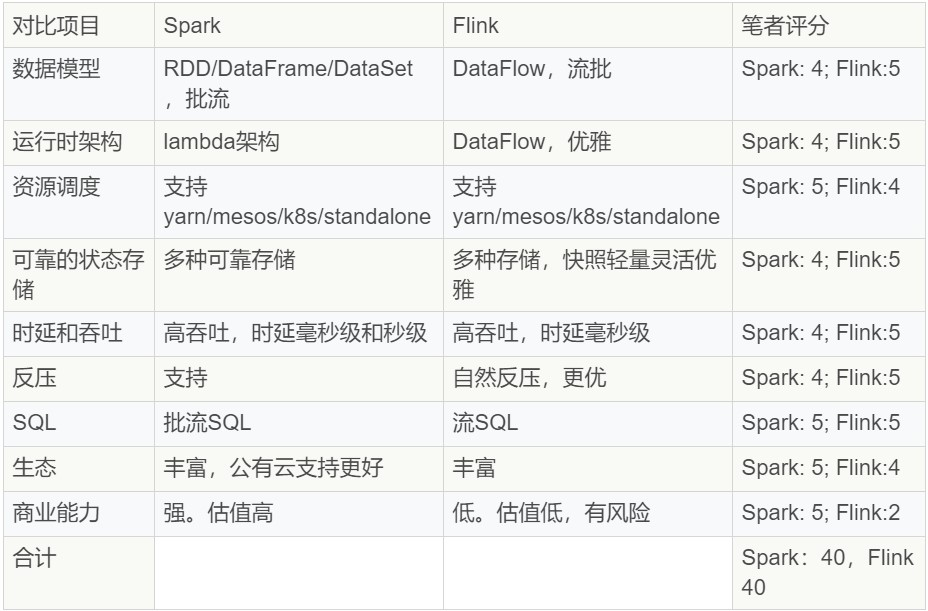
Flink 和 Spark 在流計算方面各有優缺點,分值等同。Flink 在流批計算方面已經成熟,Spark 還有很大提升空間,此消彼長,未來不好說。
邊緣計算的機會
邊緣計算近兩年概念正盛,其中依靠的大數據能力主要是流計算。公有云、私有云、混合雲這麼成熟,爲何會冒出來個邊緣計算?
IoT 技術快速成熟,賦能了車聯網、工業、智慧城市、O2O 等線下場景。線下數據高速增長,敏感數據不上雲,數據量太大無法上雲,毫秒級以下的時延,這些需求催生了靠近業務的邊緣計算。在資源受限的硬件設備上,業務數據流實時產生,需要實時處理流數據,一般可以用 lambda 跑腳本,實時大數據可以運行 Flink。華爲雲已商用的 IEF 邊緣計算服務,在邊緣側跑的就是 Flink lite,Azure 的流計算也支持流作業下發到邊緣設備上運行。
邊緣設備上不僅可以運行腳本和 Flink,也可以執行機器學習和深度學習算法推理。視頻攝像頭隨處可見,4K 高清攝像頭也越來越普遍,交警蜀黎的罰單開的越來越省心。視頻流如果全部實時上傳到數據中心,成本不划算,如果這些視頻流數據能在攝像頭上或攝像頭周邊完成人臉識別、物體識別、車牌識別、物體移動偵測、漂浮物檢測、拋灑物檢測等,然後把視頻片段和檢測結果上傳,將極大節省流量。這就催生了低功耗 AI 芯片如昇騰 310、各種智能攝像頭和邊緣盒子。
Flink 這類能敏捷瘦身且能力不減的流計算框架,正適合在低功耗邊緣盒子上大展身手。可以跑一些 CEP 規則引擎、在線機器學習 Streaming、實時異常檢測、實時預測性維護、ETL 數據清洗、實時告警等。
行業應用場景
實時流計算常見的應用場景有:日誌分析、物聯網、NB-IoT、智慧城市、智慧工廠、車聯網、公路貨運、高速公路監測、鐵路、客運、梯聯網、智能家居、ADAS 高級輔助駕駛、共享單車、打車、外賣、廣告推薦、電商搜索推薦、股票交易市場、金融實時智能反欺詐等。只要實時產生數據、實時分析數據能產生價值,那麼就可以用實時流計算技術,單純地寫一寫腳本和開發應用程序,已經無法滿足這些複雜的場景需求。
數據計算越實時越有價值,Hadoop 造就的批計算價值已被榨乾。在線機器學習、在線圖計算、在線深度學習、在線自動學習、在線遷移學習等都有實時流計算的影子。對於離線學習和離線分析應用場景,都可以問一下,如果是實時的,是否能產生更大價值?
去新白鹿用二維碼點餐,會享受到快速上菜和在線結賬;叫個外賣打個車,要是等十分鐘沒反應,必須要取消訂單。互聯網催化各個行業,實時計算是其中潮頭,已***在生活、生產、環境的方方面面。
對比各家雲廠商的流計算服務
不重複造輪子已成業界共識。使用公有云上 serverless 大數據 AI 服務(全託管、按需收費、免運維),會成爲新的行業共識。高增長的企業構築大數據 AI 基礎設施需要較高代價且週期不短,長期維護成本也高。
企業上雲主要擔心三個問題:
數據安全,數據屬於企業核心資產;
被廠商鎖定;
削弱自身技術能力。
對於數據安全,國內的《網絡安全法》已經正式實施,對個人隱私數據保護有法可依;另外歐盟 GDPR《通用數據保護條例(General Data Protection Regulation)》正式生效,都說明法律要管控數據亂象了。
選擇中立的雲廠商很關鍵。雲廠商大都會選擇開源系統作爲雲服務的基石,如果擔心被鎖定,用戶選擇雲服務的時候留意下內核就好。當然,這會導致開源社區和雲廠商的矛盾,提供企業化大數據平臺可能會被公有云搶生意,開源社區要活下去,DataBricks 跟 Azure 的合作例子就是聰明的選擇。
擔心削弱公司技術能力,倒是不必。未來大數據框架會越來越傻瓜化,運維和使用門檻也會越來越低,企業不如把主要精力聚焦於用大數據創造價值上,不爲了玩數據而玩數據,是爲了 make more money。
目前常見的流計算服務包括:
AWS Kinesis
Azure 流分析
Huawei Cloud 實時流計算服務
Aliyun 實時計算
AWS Kinesis 流計算服務推出較早,目前已經比較成熟,提供 serverless 能力,按需收費、全託管、動態擴容縮容,是 AWS 比較賺錢的產品。Kinesis 包含 Data Streams、Data Analytics、Data Firehose、Video Streams 四個部分。Data Streams 做數據接入,Data Firehose 做數據加載和轉儲,Data Analytics 做實時流數據分析,Video Streams 用於流媒體的接入、編解碼和持久化等。Azure 的流分析做的也不錯,主打 IoT 和邊緣計算場景。從 Kinesis 和 Azure 流分析能看出,IoT 是流分析的主戰場。產品雖好,國內用的不多,數據中心有限而且貴。
華爲雲實時流計算服務是以 Flink 和 Spark 爲核心的 serverless 流計算服務,早在 2012 年華爲就開始了自研的 StreamSmart 產品,廣泛在海外交付。由於生態閉源,團隊放棄了 StreamSmart,轉投 Flink 和 Spark 雙引擎。提供 StreamSQL 爲主的產品特性:CEP SQL、StreamingML、Time GeoSpartial 時間地理位置分析、實時可視化等高級特性。首創獨享集羣模式,提供用戶間物理隔離,即使是兩個競爭對手也可以同時使用實時流計算服務,用戶之間物理隔離也斷絕了用戶間突破沙箱的小心思。
阿里雲的流計算服務,最早是基於 Storm 的 galaxy 系統,同樣是基於 StreamSQL,產品早年不溫不火。自從去年流計算徹底轉變,內核改爲 Flink,經過雙 11 的流量檢驗,目前較爲活躍。
總結 & 展望
實時流計算技術已經成熟,大家可以放心使用。目前的問題在於應用場景推廣,提升企業對雲廠商的信任度,廣泛應用流計算創造價值。而流計算與 AI 的結合,也會是未來可能的方向: