




背景
Apache Spark作爲當前最爲流行的開源大數據計算框架,廣泛應用於數據處理和分析應用,它提供了兩種方式來處理數據:一是交互式處理,比如用戶使用spark-shell或是pyspark腳本啓動Spark應用程序,伴隨應用程序啓動的同時Spark會在當前終端啓動REPL(Read–Eval–Print Loop)來接收用戶的代碼輸入,並將其編譯成Spark作業提交到集羣上去執行;二是批處理,批處理的程序邏輯由用戶實現並編譯打包成jar包,spark-submit腳本啓動Spark應用程序來執行用戶所編寫的邏輯,與交互式處理不同的是批處理程序在執行過程中用戶沒有與Spark進行任何的交互。
兩種處理交互方式雖然看起來完全不一樣,但是都需要用戶登錄到Gateway節點上通過腳本啓動Spark進程。這樣的方式會有什麼問題嗎?
首先將資源的使用和故障發生的可能性集中到了這些Gateway節點。由於所有的Spark進程都是在Gateway節點上啓動的,這勢必會增加Gateway節點的資源使用負擔和故障發生的可能性,同時Gateway節點的故障會帶來單點問題,造成Spark程序的失敗。
其次難以管理、審計以及與已有的權限管理工具的集成。由於Spark採用腳本的方式啓動應用程序,因此相比於Web方式少了許多管理、審計的便利性,同時也難以與已有的工具結合,如Apache Knox。
同時也將Gateway節點上的部署細節以及配置不可避免地暴露給了登陸用戶。
爲了避免上述這些問題,同時提供原生Spark已有的處理交互方式,並且爲Spark帶來其所缺乏的企業級管理、部署和審計功能,本文將介紹一個新的基於Spark的REST服務:Livy。
Livy
Livy是一個基於Spark的開源REST服務,它能夠通過REST的方式將代碼片段或是序列化的二進制代碼提交到Spark集羣中去執行。它提供了以下這些基本功能:
提交Scala、Python或是R代碼片段到遠端的Spark集羣上執行;
提交Java、Scala、Python所編寫的Spark作業到遠端的Spark集羣上執行;
提交批處理應用在集羣中運行。
從Livy所提供的基本功能可以看到Livy涵蓋了原生Spark所提供的兩種處理交互方式。與原生Spark不同的是,所有操作都是通過REST的方式提交到Livy服務端上,再由Livy服務端發送到不同的Spark集羣上去執行。說到這裏我們首先來了解一下Livy的架構。
Livy的基本架構
Livy是一個典型的REST服務架構,它一方面接受並解析用戶的REST請求,轉換成相應的操作;另一方面它管理着用戶所啓動的所有Spark集羣。具體架構可見圖1。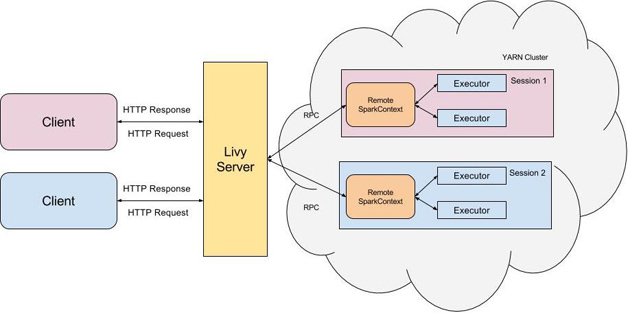
圖1 Livy的基本架構
用戶可以以REST請求的方式通過Livy啓動一個新的Spark集羣,Livy將每一個啓動的Spark集羣稱之爲一個會話(session),一個會話是由一個完整的Spark集羣所構成的,並且通過RPC協議在Spark集羣和Livy服務端之間進行通信。根據處理交互方式的不同,Livy將會話分成了兩種類型:
交互式會話(interactive session),這與Spark中的交互式處理相同,交互式會話在其啓動後可以接收用戶所提交的代碼片段,在遠端的Spark集羣上編譯並執行;
批處理會話(batch session),用戶可以通過Livy以批處理的方式啓動Spark應用,這樣的一個方式在Livy中稱之爲批處理會話,這與Spark中的批處理是相同的。
可以看到,Livy所提供的核心功能與原生Spark是相同的,它提供了兩種不同的會話類型來代替Spark中兩類不同的處理交互方式。接下來我們具體瞭解一下這兩種類型的會話。
交互式會話(Interactive Session)
使用交互式會話與使用Spark所自帶的spark-shell、pyspark或sparkR相類似,它們都是由用戶提交代碼片段給REPL,由REPL來編譯成Spark作業並執行。它們的主要不同點是spark-shell會在當前節點上啓動REPL來接收用戶的輸入,而Livy交互式會話則是在遠端的Spark集羣中啓動REPL,所有的代碼、數據都需要通過網絡來傳輸。
我們接下來看看如何使用交互式會話。
創建交互式會話
POST /sessions

使用交互式會話的前提是需要先創建會話。當我們提交請求創建交互式會話時,我們需要指定會話的類型(“kind”),比如“spark”,Livy會根據我們所指定的類型來啓動相應的REPL,當前Livy可支持spark、pyspark或是sparkr三種不同的交互式會話類型以滿足不同語言的需求。
當創建完會話後,Livy會返回給我們一個JSON格式的數據結構表示當前會話的所有信息: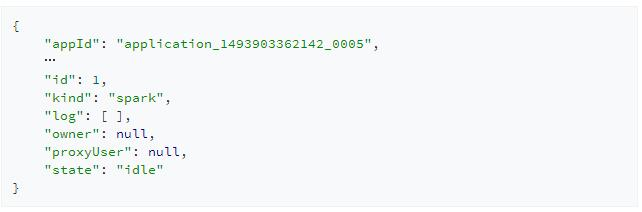
其中需要我們關注的是會話id,id代表了此會話,所有基於該會話的操作都需要指明其id。
提交代碼
POST /sessions/{sessionId}/statements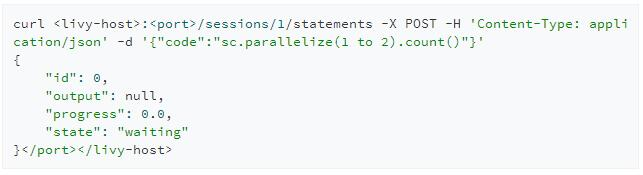
創建完交互式會話後我們就可以提交代碼到該會話上去執行。與創建會話相同的是,提交代碼同樣會返回給我們一個id用來標識該次請求,我們可以用id來查詢該段代碼執行的結果。
查詢執行結果
GET /sessions/{sessionId}/statements/{statementId}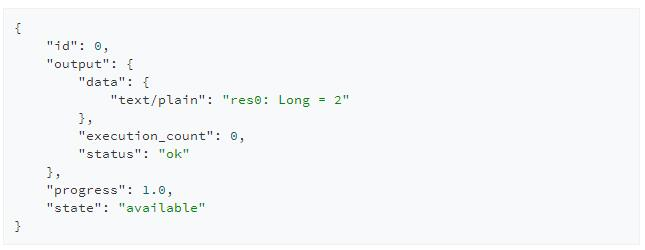
Livy的REST API設計爲非阻塞的方式,當提交代碼請求後Livy會立即返回該請求id而並非阻塞在該次請求上直到執行完成,因此用戶可以使用該id來反覆輪詢結果,當然只有當該段代碼執行完畢後用戶的查詢請求才能得到正確結果。
當然Livy交互式會話還提供許多不同的REST API來操作會話和代碼,在這就不一一贅述了。
使用編程API
在交互式會話模式中,Livy不僅可以接收用戶提交的代碼,而且還可以接收序列化的Spark作業。爲此Livy提供了一套編程式的API供用戶使用,用戶可以像使用原生Spark API那樣使用Livy提供的API編寫Spark作業,Livy會將用戶編寫的Spark作業序列化併發送到遠端Spark集羣中執行。表1就是使用Spark API所編寫PI程序與使用Livy API所編寫的程序的比較。
表1 使用Spark API所編寫PI程序與使用Livy API所編寫程序的比較
可以看到除了入口函數不同,其核心邏輯完全一致,因此用戶可以很方便地將已有的Spark作業遷移到Livy上。
Livy交互式會話是Spark交互式處理基於HTTP的實現。有了Livy的交互式會話,用戶無需登錄到Gateway節點上去啓動Spark進程並執行代碼。以REST的方式進行交互式處理提供給用戶豐富的選擇,也方便了用戶的使用,更爲重要的是它方便了運維的管理。
批處理會話(Batch Session)
在Spark應用中有一大類應用是批處理應用,這些應用在運行期間無須與用戶進行交互,最典型的就是Spark Streaming流式應用。用戶會將業務邏輯編譯打包成jar包,並通過spark-submit啓動Spark集羣來執行業務邏輯:
Livy也爲用戶帶來相同的功能,用戶可以通過REST的方式來創建批處理應用:
通過用戶所指定的“className”和“file”,Livy會啓動Spark集羣來運行該應用,這樣的一種方式就稱爲批處理會話。
至此我們簡單介紹了Livy的兩種會話類型,與它相對應的就是Spark的兩種處理交互方式,因此可以說Livy以REST的方式提供了Spark所擁有的兩種交互處理方式。
企業級特性
前面我們介紹了Livy的核心功能,相比於核心功能的完整性,Livy的企業級特性則更體現了其相比於原生Spark處理交互方式的優勢。本章節將介紹Livy幾個關鍵的企業特性。
多用戶支持
假定用戶tom向Livy服務端發起REST請求啓動一個新的會話,而Livy服務端則是由用戶livy啓動的,這個時候所創建出來Spark集羣用戶是誰呢,會是用戶tom還是livy?在默認情況下這個Spark集羣的用戶是livy。這會帶來訪問權限的問題:用戶tom無法訪問其擁有權限的資源,而相對的是他卻可以訪問用戶livy所擁有的資源。
爲了解決這個問題Livy引入了Hadoop中的代理用戶(proxy user)模式,代理用戶模式廣泛使用於多用戶的環境,如HiveServer2。在此模式中超級用戶可以代理成普通用戶去訪問資源,並擁有普通用戶相應的權限。開啓了代理用戶模式後,以用戶tom所創建的會話所啓動的Spark集羣用戶就會是tom。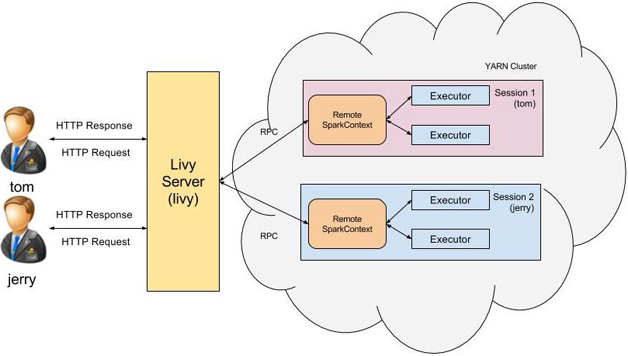
圖2 Livy多用戶支持
爲了使用此功能用戶需要配置“livy.impersonation.enabled”,同時需要在Hadoop中將Livy服務端進程的用戶配置爲Hadoop proxyuser 。當然還會有一些Livy的額外配置就不在這展開了。
有了代理用戶模式的支持,Livy就能真正做到對多用戶的支持,不同用戶啓動的會話會以相應的用戶去訪問資源。
端到端安全
在企業應用中另一個非常關鍵的特性是安全性。一個完整的Livy服務中有哪些點是要有安全考慮的呢?
客戶端認證
當用戶tom發起REST請求訪問Livy服務端的時候,我們如何知道該用戶是合法用戶呢?Livy採用了基於Kerberos的Spnego認證。在Livy服務端配置Spnego認證後,用戶發起Http請求之前必須先獲得Kerberos認證,只有通過認證後才能正確訪問Livy服務端,不然的話Livy服務端會返回401錯誤。
HTTPS/SSL
那麼如何保證客戶端與Livy服務端之間HTTP傳輸的安全性呢?Livy使用了標準的SSL來加密HTTP協議,以確保傳輸的Http報文的安全。爲此用戶需要配置Livy服務端SSL相關的配置已開啓此功能。
SASL RPC
除了客戶端和Livy服務端之間的通信,Livy服務端和Spark集羣之間也存在着網絡通信,如何確保這兩者之間的通信安全性也是需要考慮的。Livy採用了基於SASL認證的RPC通信機制:當Livy服務端啓動Spark集羣時會產生一個隨機字符串用作兩者之間認證的祕鑰,只有Livy服務端和該Spark集羣之間纔有相同的祕鑰,這樣就保證了只有Livy服務端才能和該Spark集羣進行通信,防止匿名的連接試圖與Spark集羣通信。
將上述三種安全機制歸結起來就如圖3所示。

圖3 Livy端到端安全機制
這樣構成了Livy完整的端到端的安全機制,確保沒有經過認證的用戶,匿名的連接無法與Livy服務中的任何一個環節進行通信。
失敗恢復
由於Livy服務端是單點,所有的操作都需要通過Livy轉發到Spark集羣中,如何確保Livy服務端失效的時候已創建的所有會話不受影響,同時Livy服務端恢復過來後能夠與已有的會話重新連接以繼續使用?
Livy提供了失敗恢復的機制,當用戶啓動會話的同時Livy會在可靠的存儲上記錄會話相關的元信息,一旦Livy從失敗中恢復過來它會試圖讀取相關的元信息並與Spark集羣重新連接。爲了使用該特性我們需要配置Livy使其開啓此功能: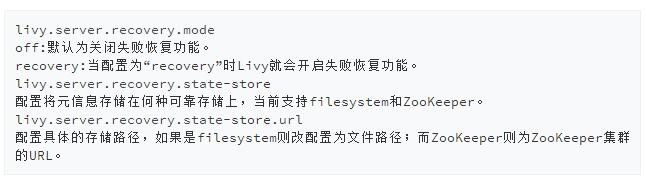
失敗恢復能夠有效地避免因Livy服務端單點故障造成的所有會話的不可用,同時也避免了因Livy服務端重啓而造成的會話不必要失效。
結語
本文從Spark處理交互方式的侷限引出了Livy這樣一個基於Spark的REST服務。同時全面介紹了其基本架構、核心功能以及企業級特性,Livy不僅涵蓋了Spark所提供了所有處理交互方式,同時又結合了多種的企業級特性,雖然Livy項目現在還處於早期,許多的功能有待增加和改進,我相信假以時日Livy必定能成爲一個優秀的基於Spark的REST服務。
爲了幫助大家讓學習變得輕鬆、高效,給大家免費分享一大批資料,幫助大家在成爲大數據工程師,乃至架構師的路上披荊斬棘。在這裏給大家推薦一個大數據學習交流圈:658558542 歡迎大家進×××流討論,學習交流,共同進步。
當真正開始學習的時候難免不知道從哪入手,導致效率低下影響繼續學習的信心。
但最重要的是不知道哪些技術需要重點掌握,學習時頻繁踩坑,最終浪費大量時間,所以有有效資源還是很有必要的。
最後祝福所有遇到瓶疾且不知道怎麼辦的大數據程序員們,祝福大家在往後的工作與面試中一切順利。