(1)shuffle概述:
大多數spark作業的性能主要就是消耗了shuffle過程,因爲該環節包含了大量的磁盤IO、序列化、網絡數據傳輸等操作。因此,如果要讓作業的性能更上一層樓,就有必要對shuffle過程進行調優。但是也必須提醒大家的是,影響一個Spark作業性能的因素,主要還是代碼開發、資源參數以及數據傾斜,shuffle調優只能在整個Spark的性能調優中佔到一小部分而已。
(2)spark 的shuffle的四種策略:
spark1.2版本以前:hashShuffleManager
- 未經優化的hashShuffleManager
- 經過優化的hashShuffleManager
spark1.2版本以後:SortShuffleManager - 普通機制
- ByPass機制
(3)spark 的shuffle的四種策略的詳細介紹:
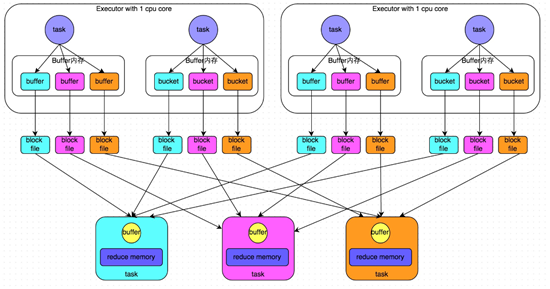
1)未經優化的hashShuffleManager:
![spark調優之shuffle調優]()
對相同的key執行hash算法,從而將相同的key都寫入到一個磁盤文件中,而每一個磁盤文件都只屬於下游stage的一個task。在將數據寫入磁盤之前,會先將數據寫入到內存緩衝,當內存緩衝填滿之後,纔會溢寫到磁盤文件中。但是這種策略的不足在於,下游有幾個task,上游的每一個task都就都需要創建幾個臨時文件,每個文件中只存儲key取hash之後相同的數據,導致了當下游的task任務過多的時候,上游會堆積大量的小文件。2)經過優化的hashShuffleManager:
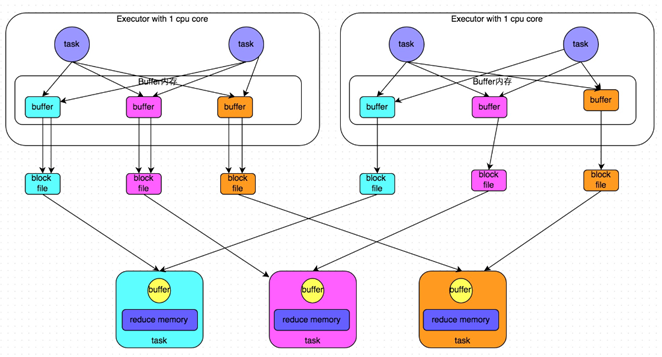
![spark調優之shuffle調優]()
在shuffle write過程中,task就不是爲下游stage的每個task創建一個磁盤文件了。此時會出現shuffleFileGroup的概念,每個shuffleFileGroup會對應一批磁盤文件,磁盤文件的數量與下游stage的task數量是相同的。一個Executor上有多少個CPU core,就可以並行執行多少個task。而第一批並行執行的每個task都會創建一個shuffleFileGroup,並將數據寫入對應的磁盤文件內。當Executor的CPU core執行完一批task,接着執行下一批task時,下一批task就會複用之前已有的shuffleFileGroup,包括其中的磁盤文件。也就是說,此時task會將數據寫入已有的磁盤文件中,而不會寫入新的磁盤文件中。因此,consolidate機制允許不同的task複用同一批磁盤文件,這樣就可以有效將多個task的磁盤文件進行一定程度上的合併,從而大幅度減少磁盤文件的數量,進而提升shuffle write的性能。
注意:如果想使用優化之後的ShuffleManager,需要將:spark.shuffle.consolidateFiles調整爲true。(當然,默認是開啓的)
總結:未經優化: 上游的task數量:m 下游的task數量:n 上游的executor數量:k (m>=k) 總共的磁盤文件:m*n優化之後的: 上游的task數量:m 下游的task數量:n 上游的executor數量:k (m>=k) 總共的磁盤文件:k*n3)SortShuffleManager-普通機制:
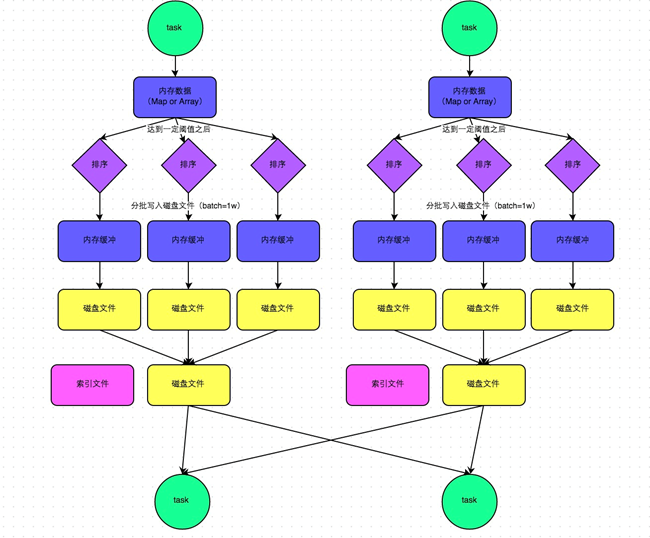
![spark調優之shuffle調優]()
名詞介紹: - shuffle write:mapper階段,上一個stage得到最後的結果寫出
- shuffle read :reduce階段,下一個stage拉取上一個stage進行合併
在普通模式下,數據會先寫入一個內存數據結構中,此時根據不同的shuffle算子,可以選用不同的數據結構。如果是由聚合操作的shuffle算子,就是用map的數據結構(邊聚合邊寫入內存),如果是join的算子,就使用array的數據結構(直接寫入內存)。接着,每寫一條數據進入內存數據結構之後,就會判斷是否達到了某個臨界值,如果達到了臨界值的話,就會嘗試的將內存數據結構中的數據溢寫到磁盤,然後清空內存數據結構。
在溢寫到磁盤文件之前,會先根據key對內存數據結構中已有的數據進行排序,排序之後,會分批將數據寫入磁盤文件。默認的batch數量是10000條,也就是說,排序好的數據,會以每批次1萬條數據的形式分批寫入磁盤文件,寫入磁盤文件是通過Java的BufferedOutputStream實現的。BufferedOutputStream是Java的緩衝輸出流,首先會將數據緩衝在內存中,當內存緩衝滿溢之後再一次寫入磁盤文件中,這樣可以減少磁盤IO次數,提升性能。
此時task將所有數據寫入內存數據結構的過程中,會發生多次磁盤溢寫,會產生多個臨時文件,最後會將之前所有的臨時文件都進行合併,最後會合併成爲一個大文件。最終只剩下兩個文件,一個是合併之後的數據文件,一個是索引文件(標識了下游各個task的數據在文件中的start offset與end offset)。最終再由下游的task根據索引文件讀取相應的數據文件。4)SortShuffleManager-bypass機制:
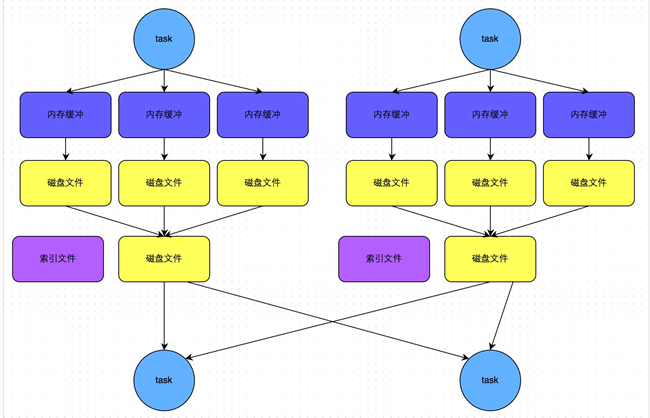
![spark調優之shuffle調優]()
此時task會爲每個下游task都創建一個臨時磁盤文件,並將數據按key進行hash然後根據key的hash值,將key寫入對應的磁盤文件之中。當然,寫入磁盤文件時也是先寫入內存緩衝,緩衝寫滿之後再溢寫到磁盤文件的。最後,同樣會將所有臨時磁盤文件都合併成一個磁盤文件,並創建一個單獨的索引文件。
機制與普通SortShuffleManager運行機制的不同在於:第一,磁盤寫機制不同;第二,不會進行排序。也就是說,啓用該機制的最大好處在於,shuffle write過程中,不需要進行數據的排序操作,也就節省掉了這部分的性能開銷。
觸發bypass機制的條件:shuffle map task的數量小於spark.shuffle.sort.bypassMergeThreshold參數的值(默認200)或者不是聚合類的shuffle算子(比如groupByKey)(4)spark 的shuffle調優:
spark.shuffle.file.buffer
參數說明:該參數用於設置shuffle write task的BufferedOutputStream的buffer緩衝大小(默認是32K)。將數據寫到磁盤文件之前,會先寫入buffer緩衝中,待緩衝寫滿之後,纔會溢寫到磁盤。
調優建議:如果作業可用的內存資源較爲充足的話,可以適當增加這個參數的大小(比如64k),從而減少shuffle write過程中溢寫磁盤文件的次數,也就可以減少磁盤IO次數,進而提升性能。在實踐中發現,合理調節該參數,性能會有1%~5%的提升。
spark.reducer.maxSizeInFlight:
參數說明:該參數用於設置shuffle read task的buffer緩衝大小,而這個buffer緩衝決定了每次能夠拉取多少數據。
調優建議:如果作業可用的內存資源較爲充足的話,可以適當增加這個參數的大小(比如96m),從而減少拉取數據的次數,也就可以減少網絡傳輸的次數,進而提升性能。在實踐中發現,合理調節該參數,性能會有1%~5%的提升。
spark.shuffle.io.maxRetries and spark.shuffle.io.retryWait:
spark.shuffle.io.retryWait:huffle read task從shuffle write task所在節點拉取屬於自己的數據時,如果因爲網絡異常導致拉取失敗,是會自動進行重試的。該參數就代表了可以重試的最大次數。(默認是3次)
spark.shuffle.io.retryWait:該參數代表了每次重試拉取數據的等待間隔。(默認爲5s)
調優建議:一般的調優都是將重試次數調高,不調整時間間隔。
spark.shuffle.memoryFraction:
參數說明:該參數代表了Executor內存中,分配給shuffle read task進行聚合操作的內存比例。
spark.shuffle.manager
參數說明:該參數用於設置shufflemanager的類型(默認爲sort)。Spark1.5x以後有三個可選項:Hash:spark1.x版本的默認值,HashShuffleManager Sort:spark2.x版本的默認值,普通機制,當shuffle read task 的數量小於等於spark.shuffle.sort.bypassMergeThreshold參數,自動開啓bypass 機制 tungsten-sort:
spark.shuffle.sort.bypassMergeThreshold
參數說明:當ShuffleManager爲SortShuffleManager時,如果shuffle read task的數量小於這個閾值(默認是200),則shuffle write過程中不會進行排序操作。
調優建議:當你使用SortShuffleManager時,如果的確不需要排序操作,那麼建議將這個參數調大一些
spark.shuffle.consolidateFiles:
參數說明:如果使用HashShuffleManager,該參數有效。如果設置爲true,那麼就會開啓consolidate機制,也就是開啓優化後的HashShuffleManager。
調優建議:如果的確不需要SortShuffleManager的排序機制,那麼除了使用bypass機制,還可以嘗試將spark.shffle.manager參數手動指定爲hash,使用HashShuffleManager,同時開啓consolidate機制。在實踐中嘗試過,發現其性能比開啓了bypass機制的SortShuffleManager要高出10%~30%。