




什麼是集羣?
集羣是一組(>2)相互獨立的,通過高速網絡互聯的計算機組成的集合。羣集一般可以分爲科學集羣,負載均衡集羣,高可用性集羣三大類。
科學集羣是並行計算的基礎。它對外就好象一個超級計算機,這種計算機內部由十至上萬個獨立處理器組成,並且在公共消息傳遞層上進行通信以運行併發應用程序,像中國的銀河,曙光超級計算機。
高可用性集羣,當集羣中的一個系統發生故障時,集羣軟件迅速作出反應,將該系統的任務分配至集羣中其它正在工作的系統上執行,通過消除單一故障點和節點故障轉移功能來提供高可用性,次節點通常是主節點的鏡像。
負責均衡集羣將服務請求分攤處理到集羣中的多個節點上。如軟件型LVS,硬件型F5。
在實際生產環境中,這三種集羣相互交融,如高可用性集羣也可以在節點之間均衡用戶負載。
什麼是RHCS?
RHCS即REDHAT CLUSTER SUITE,中文意思即紅帽集羣套件。它是一套綜合的軟件組件,可以通過在部署時採用不同的配置,以滿足你的對高可用性,負載均衡,可擴展性,文件共享和節約成本的需要。
RED HAT公司在2007年發佈RHEL5時,就將原本作爲獨立軟件發售的用於構建企業級集羣的集羣套件redhat cluster suite(RHCS)集成到了操作系統中一同發佈。
RHCS提供如下兩種不同類型的集羣:
1、應用/服務故障切換----通過創建N個節點的服務器集羣來實現關鍵應用和服務的故障切換
2、IP負載均衡----對一羣服務器上收到的IP網絡請求進行負載均衡
RHCS技術要點:
1、最多支持128個節點(紅帽3和4支持16個節點)
2、可同時爲多個應用提供高可用性
3、NFS/CIFS故障切換:支持UNIX和WINDOWS環境下使用的高可用性文件
4、完全共享的存儲子系統:所有集羣成員都可以訪問同一個存儲子系統
5、綜合數據完整性:使用最新的I/O屏障(barrier)技術,如可編輯的嵌入式和外部電源開關裝置(power switches)。
6、服務故障切換:它可以確保及時發現硬件停止運行或故障的發生並自動恢復系統,同時,它還可以通過監控應用來確保應用的正確運行並在其發生故障時進行自動重啓。
RHCS組件說明:
分佈式集羣管理器(cman)
Cluster manager 簡稱CMAN,是一個分佈式集羣管理工具,運行在集羣的各個節點上,爲RHCS提供集羣管理任務。
它用於管理集羣成員、消息和通知。它通過監控每個節點的運行狀態來了解節點成員之間的有關係。當集羣中某個節點出現故障時,節點成員關係將發生改變,CMAN及時將這種改變通知底層,進而做出相應的調整。
CMAN根據每個節點的運行狀態,統計出一個法定節點數,作爲集羣是否存活的依據。當整個集羣中有多於一半的節點處於激活狀態時,表示達到了法定節點數,此集羣可以正常運行,當集羣中有一半或少於一半的節點處於激活狀態時,表示沒有達到法定的節點數,此時整個集羣系統將變得不可用。
CMAN依賴於CCS,並且CMAN通過CCS讀取cluster.conf文件。
鎖管理(DLM)
Distributed Lock Manager,簡稱DLM,是一個分佈式鎖管理器,它是RHCS的一個底層基礎構件,同時也爲集羣提供了一個公用的鎖運行機制。DLM運行在每個節點上,GFS通過鎖管理器的機制來同步訪問文件系統的元數據。CLVM通過鎖管理器來同步更新數據到LVM卷和卷組。
DLM不需要設定鎖管理服務器,它採用對等的鎖管理方式,大大提高了處理性能。同時,DLM避免了單個節點失敗需要整體恢復的性能瓶頸。另外,DLM的請求是本地的,不需要網絡請求,因此請求會立即生效。最後,DLM通過分層機制,可以實現多個鎖空間的並行鎖模式。
配置文件管理(CCS)
Cluster configuration system 簡稱CCS,主要用於集羣配置文件管理和配置文件在節點之間的同步。CCS運行在集羣的每個節點上,監控每個集羣節點上的單一配置文件/etc/cluster/cluster.conf的狀態。當這個文件發生任何變化 時,都將些變化更新至集羣中的每個節點上,時刻保持每個節點的配置文件同步。
Cluster.conf是一個XML文件,其中包含集羣名稱,集羣節點信息,集羣資源和服務信息,fence設備等。
柵設備(Fence)
通過柵設備可以從集羣共享存儲中斷開一個節點,切斷I/O以保證數據的完整性。當CMAN確定一個節點失敗後,它在集羣結構中通告這個失敗的節點,fenced進程將失敗的節點隔離,以保證失敗節點不破壞共享數據。它可以避免因出現不可預知的情況而造成的“腦裂”(split-brain)現象。“腦裂”是指當兩個節點之間的心跳線中斷時,兩臺主機都無法獲取對方的信息,此時兩臺主機都認爲自己是主節點,於是對集羣資源(共享存儲,公共IP地址)進行爭用,搶奪。
Fence的工作原理是:當意外原因導致主機異常或宕機時,備用機會首先調用fence設備,然後通過fence設備將異常的主機重啓或從網絡上隔離,釋放異常主機佔據的資源,當隔離操作成功後,返回信息給備用機,備用機在接到信息後,開始接管主機的服務和資源。
RHCS的Fence設備可以分爲兩種:內部Fence和外部Fence。內部fence有IBM RSAII卡,HP的ILO卡,以及IPMI設備等;外部FENCE設備有UPS,SAN switch ,Network switch等。
柵設備實例
當節點A上的柵過程發現C節點失效時,它通過柵代理通知光纖通道交換機將C節點隔離,從而釋放佔用的共享存儲。
當A上的柵過程發現C節點失效時,它通過柵代理直接對服務器做電源power on/off,而不是去執行操作系統的開關機指令。
rgmanager管理
它主要用來監督、啓動、停止集羣的應用、服務和資源。當一個節點的服務失敗時,高可用集羣服務管理進程可以將服務從這個失敗節點轉移至其點健康節點上,這種服務轉移能力是自動動,透明的。
RHCS通過rgmanager來管理集羣服務,rgmanager運行在每個集羣節點上,在服務器上對應的進程爲clurgmgrd。
在RHCS集羣中,高可用生服務包括集羣服務和集羣資源兩個方面。集羣服務其實就是應用,如APACHE,MYSQL等。集羣資源有IP地址,腳本,EXT3/GFS文件系統等。
在RHCS集羣中,高可用性服務是和一個失敗轉移域結合在一起的。由幾個節點負責一個特定的服務的集合叫失敗轉移域,在失敗遷移域中可以設置節點的優先級,主節點失效,服務會遷移至次節點,如果沒有設置優先,集羣高可用服務將在任意節點間轉移。
說了這麼多,初學者可能還是不明白RHCS組件之間的關係,所以整個圖給大家作感性認識一下,RHCS組件可以歸到以下圖示中:
集羣配置和管理工具
RHCS提供了多種集羣配置和管理工具,常用有基於GUI的system-config-cluster,conga等,還提供了基於命令行的管理工具。
System-config-cluster由集羣節點配置和集羣管理兩個部分組成,分別用於創建集羣節點配置文件和維護節點運行狀態,一般用於早期的RHCS版本中。
Conga是新的基於網絡的集羣配置工具。它是web界面管理的,由luci和ricci組成,luci可以安裝在一臺獨立的計算機上,也可安裝在節點上,用於配置和管理集羣,ricci是一個代理,安裝在每個集羣節點上,luci通過ricci和集羣中的每個節點通信。
GFS是RHCS爲集羣系統提供的一個存儲解決方案,它允許集羣的多個節點在塊級別上共享 存儲,多個節點同時掛載一個文件系統分區,而使文件系統數據不受破壞,單一的ext2或ext3無法做到。
爲了實現多個節點對一個文件系統同時進行讀寫操作,GFS使用鎖管理器(DLM)來管理I/O操作:當一個寫進程操作一個文件時,此文件被鎖定,其它進程無法進行讀寫操作,操作完成後,RHCS底層機制會把此操作在其它節點上可見。
有GFS就有RHCS,但建立RHCS時,如果不用共享存儲,就沒有必要用GFS。
資源(Resource)
腳本(script),IP Address,File system可以用來定義一個高可用的web服務功能
實例操作(不帶共享存儲)
紅帽建議做RHCS集羣,一般要三臺服務器以上,含三臺,其中一臺作LUCI,這裏作實驗因爲用的是虛擬環境,加上PC機性能差,所以只用到二臺。
修改各節點的/etc/hosts文件
注意格式要一致,特別是127.0.0.1行,默認的不合rhcs集羣要求,必須改,否則在用luci建立集羣時會報錯。
在節點1上安裝luci軟件
[root@rhcs1 ~]# yum install luci*
Luci初始化及重啓
在所有集羣節點上(rhcs1,rhcs2)安裝RHCS軟件
[root@rhcs1 ~]# yum install cman
[root@rhcs1 ~]# yum install ricci
[root@rhcs1 ~]# yum install rgmanager
其它ricci,rgmanager不截圖了
安裝完所有RHCS組件後,重啓所有節點,並啓動ricci,luci服務,rhcs1節點需要啓動luci,rhcs2不需要,服務啓動完畢後,查看rhcs1節點的11111端口,8084端口有沒有在監聽,rhcs2節點的11111端口有沒有在監聽。
[root@rhcs1 ~]# /etc/init.d/ricci start
[root@rhcs1 ~]# /etc/init.d/luci start
Web登錄luci進行集羣設置
在客戶機上,打開瀏覽器,這裏我用火狐,輸入https://192.168.145.232:8084,輸入初始化時設置的密碼,進行web登錄。
新建cluster
設置集羣名稱,節點信息,然後點submit按鈕


火狐瀏覽器中,顯示這個進度有問題,總是初始化,正常情況下,如果install完畢後,空心圓點會變實心圓點,然後接下是reboot階段,configure階段,join階段,因爲我在建集羣時選擇了reboot所以,集羣建完後,所有節點會自動重啓。重啓後,要確保luci,ricci服務有沒有起來。
建立mtt_web後情況
點cluster list,查看一下剛創建的集羣狀態是否正常,從圖上看,集羣顯示綠色,表示正常。
新建一個失敗轉移域
點擊mtt_web,進去一個新界面,然後在左邊窗中選failover domains下的add a failover domain,根據選項填寫轉移域名,這裏我們取web-failover,在此界面中,可以設置轉移域中的優先級,從圖上所示,rhcs1節點的優先級爲1,rhcs2節點的優先級爲10,數值越大,優先級越低,在生產環境中也可以把優先級設置爲一樣,誰先啓動服務,誰就是主節點。
創建必要的web資源
創建一些web服務所需要的資源,IP地址,腳本,這裏的虛擬IP或叫公用IP,我們設置爲192.168.145.235,這個IP要確保不能被其它服務器佔用了。

創建一個腳本資源,這個腳本文件其實是一個shell程序,因爲本次的httpd是通過yum安裝的所以系統會把apache的啓動腳本放在/etc/init.d/httpd目錄下,如果是源碼包安裝的,就需要自己編寫apache的啓動腳本,該腳本里要包括start,stop等字段。
新建service
這裏的service,並不指apache服務,或mysql服務,這裏指整個集羣的資源全部組成一個服務,所以這裏先定義一個service,然後選擇上面定義好的策略,如失敗轉移域,轉移策略,所用的公共IP及腳本資源。

新建fence設備
上面已講到fence設備是防止腦裂現象出現,所以我們在此集羣中,再增加一個fence設備,因爲我們用的是虛擬機,所以就添加虛擬設備的選項,實際生產環境中,根據條件定fence設備。
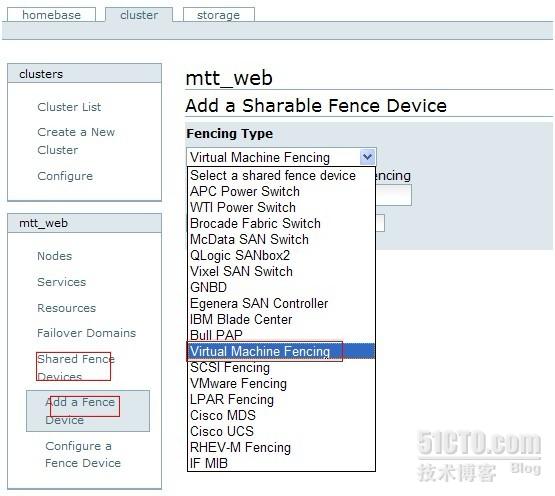




這樣下來,集羣的環境都搭建好了,完整的配置文件見/etc/cluster/cluster.conf文件
在所有節點上安裝http服務
Shell>[root@rhcs1 ~]# yum install httpd
在rhcs1節點上的/var/www/html目錄,新建index.html,內容如下:
<html> <body> kkkk this is 145.232 </body> </html>
在rhcs2節點上的/var/www/html目錄,新建index.html,內容如下:
<html> <body> kkkk this is 145.233 </body> </html>
啓動RHCS集羣
先在所有節點是啓動cman
Shell>service cman start
如果cman啓動沒有報錯,再在所有節點是啓動rgmanager,集羣管理器
Shell>service rgmanager start
通過瀏覽器訪問一下,集羣
http://192.168.145.235
在rhcs1節點上,把httpd關閉
Shell>pkill -9 httpd
再通過客戶端計算機訪問145.235,建立先關閉剛打開的頁面,新開一個頁面,再輸入IP地址,發現,頁面顯示爲145.233。
同樣,在rhcs2節點上把httpd關閉,不到一分鐘,再到訪問,網頁結果又顯示爲145.232了。
這裏我用兩個不同的index.html來顯示內容,是爲了好區別集羣有沒有作故障轉移,在實際環境裏,所有節點都是一樣的,即次節點是主節點的鏡像。
後記:
生產環境中,很多情況下,集羣都會掛共享存儲,一般爲SAN或DAS,所以在以上基礎上,還要加GFS文件系統,配置表決磁盤,具體可看附件中redhat官方手冊
http://369369.blog.51cto.com/319630/836001