




時序數據庫連載系列:時序數據庫那些事
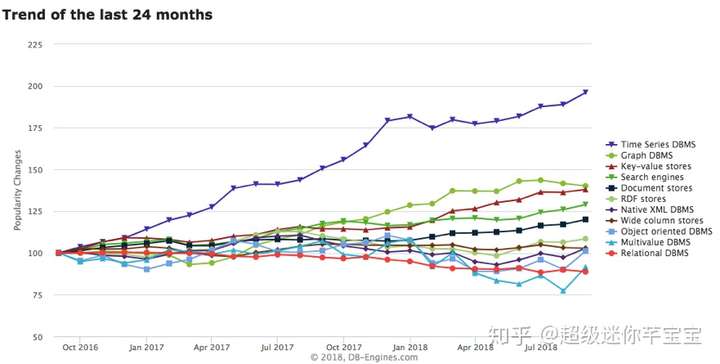
正如《銀翼殺手》中那句在影史流傳經典的臺詞:“I've seen things you people wouldn't believe... All those ... moments will be lost in time, like tears...in rain.” 時間浩瀚的人類歷史長河中總是一個耀眼的詞彙,當科技的年輪劃到數據時代,時間與數據庫碰到一起,把數據庫內建時間屬性後,產生了時序數據庫。時序數據庫是一種帶有時間戳業務屬性的垂直型數據庫。自從2014年開始,數據庫熱度排名網站DB-Engines就把時間序列數據庫作爲了獨立的目錄來分類統計,而且最近幾年的增長率在全部數據庫分類裏排名第一(見下圖)。
時序數據庫
A time series database (TSDB) is a software system that is optimized for handling time series data, arrays of numbers indexed by time (a datetime or a datetime range)
以上是維基百科對於時序數據庫的定義。可以把它拆解成3個方面來看:時序特性,數據特性,數據庫特性。
時序特性:
時間戳:通用的業務場景內以秒和毫秒精度爲主,在一些遙感等高頻採集領域,時間戳可以達到納秒級別。
時間戳種類包括unix系統時間戳和Calendar, 並且支持時區的自動適配。採樣頻率:採集頻率一般有2種,一種是週期性的時間採樣頻率,比如服務器性能相關的定期彙總指標。另外一種是離散型的採樣,比如網站的訪問等等
數據特性:
數據順序追加
數據可多維關聯
通常高頻訪問熱數據
冷數據需要降維歸檔
數據主要覆蓋數值,狀態,事件
數據庫特性(CRUD)
寫入速率穩定並且遠遠大於讀取
按照時間窗口訪問數據
極少更新,存在一定窗口期的覆蓋寫
批量刪除
具備通用數據庫要求的高可用,高可靠,可伸縮特性
通常不需要具備事務的能力
時序數據庫發展簡史
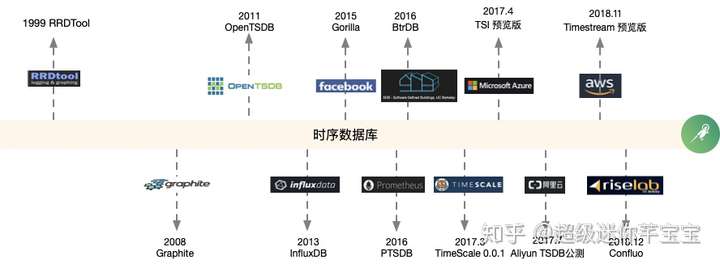
第一代時序數據存儲系統
雖然通用關係數據庫可以存儲時序數據,但是由於缺乏針對時間的特殊優化,比如按時間間隔存儲和檢索數據等等,因此在處理這些數據時效率相對不高。
第一代時序數據典型來源於監控領域,直接基於平板文件的簡單存儲工具成爲這類數據的首先存儲方式。
以RRDTool,Wishper爲代表,通常這類系統處理的數據模型比較單一,單機容量受限,並且內嵌於監控告警方案。
基於通用存儲的時序數據庫
伴隨着大數據和Hadoop的發展,時序數據量開始迅速增長,系統業務對於處理時序數據的擴展性等方面提出更多的要求。
基於通用存儲而專門構建的時間序列數據庫開始出現,它可以按時間間隔高效地存儲和處理這些數據。像OpenTSDB,KairosDB等等。
這類時序數據庫在繼承通用存儲優勢的基礎上,利用時序的特性規避部分通用存儲的劣勢,並且在數據模型,聚合分析方面做了貼合時序的大量創新。
比如OpenTSDB繼承了HBase的寬表屬性結合時序設計了偏移量的存儲模型,利用salt緩解熱點問題等等。
然而它也有諸多不足之處,比如低效的全局UID機制,聚合數據的加載不可控,無法處理高基數標籤查詢等等。
垂直型時序數據庫的出現
隨着docker,kubernetes, 微服務等技術的發展,以及對於IoT的發展預期越來越強烈。
在數據隨着時間而增長的過程中,時間序列數據成爲增長最快的數據類型之一。
高性能,低成本的垂直型時序數據庫開始誕生,以InfluxDB爲代表的具有時序特徵的數據存儲引擎逐步引領市場。
它們通常具備更加高級的數據處理能力,高效的壓縮算法和符合時序特徵的存儲引擎。
比如InfluxDB的基於時間的TSMT存儲,Gorilla壓縮,面向時序的窗口計算函數p99,rate,自動rollup等等。
同時由於索引分離的架構,在膨脹型時間線,亂序等場景下依然面臨着很大的挑戰。
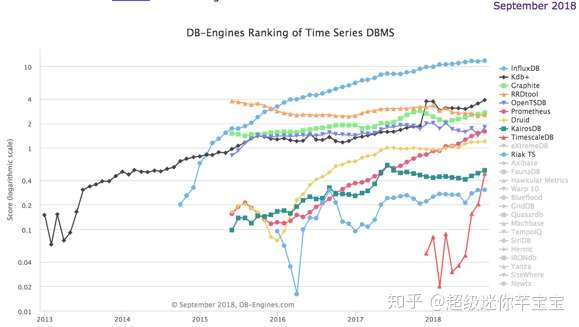
時序數據庫發展現狀
目前,DB-Engines把時間序列數據庫作爲獨立的目錄來分類統計,下圖就是2018年業內流行的時序數據庫的關注度排名和最近5年的變化趨勢。
公有云
AWS Timestream
2018.11 Amazon在AWS re Invent大會發布Timestream預覽版。適用於 IoT 和運營應用程序等場景。
提供自適應查詢處理引擎快速地分析數據,自動對數據進行彙總、保留、分層和壓縮處理。按照寫入流量,存儲空間,查詢數據量的方式計費,以serverless的形式做到最低成本管理。
Azure Series Insights
2017.4 Microsoft發佈時序見解預覽版,提供的完全託管、端到端的存儲和查詢高度情景化loT時序數據解決方案。強大的可視化效果用於基於資產的數據見解和豐富的交互式臨時數據分析。
此外,針對數據類型分爲暖數據分析和原始數據分析,按照存儲空間和查詢量分別計費。
開源
OpenTSDB
OpenTSDB是一個分佈式的、可伸縮的時間序列數據庫. 引入metric,tags等概念設計了一套針對時序場景的數據模型,底層採用HBase作爲存儲,利用時序場景的特性,採用特殊的rowkey方式,來提高時序的聚合和查詢能力。Prometheus
Prometheus會將所有採集到的樣本數據以時間序列(time-series)的方式保存在內存數據庫中,並且定時保存到硬盤上。需要遠端存儲來保證可靠和擴展性。InfluxDB
InfluxDB是單機開源的時序數據庫,由Go語言編寫,無需特殊的環境依賴,簡單方便。採用獨有的TSMT結構實現高性能的讀寫。分佈式需要商業化支持。Timescale
面向SQL生態的時序數據庫,固定Schema,底層基於PG,按時間管理chunk table。
學術
BTrDB
BtrDB面向高精度時序數據的存儲應用,設計並提出了 "time-partitioning version-annotated copy-on-write tree" 的數據結構,爲每一條時間線構建了一棵樹,並且引入版本的概念處理數據的亂序場景Confluo
Confluo設計了新型的數據結構”Atomic MultiLog“,採用現代CPU硬件支持的原子指令集,支持百萬級數據點高併發寫入,毫秒級在線查詢,佔用很少的的CPU資源實現即席查詢Chronixdb
ChronixDB基於Solr提供了時序存儲,並且實現了特有的無損壓縮算法,可以與Spark集成,提供豐富的時序分析能力。
商業&工業
PI
PI是OSI軟件公司開發的大型實時數據庫,廣泛應用於電力,化工等行業,採用了旋轉門壓縮專利技術和獨到的二次過濾技術,使進入到PI數據庫的數據經過了最有效的壓縮,極大地節省了硬盤空間KDB
KDB是Kx System開發的時間序列數據庫,通常用於處理交易行情相關數據。支持流、內存計算和實時分析Billion級別的記錄以及快速訪問TB級別的歷史數據。Gorilla
Gorilla是Facebook的一個基於內存的時序數據庫,採用了一種新的時間序列壓縮算法.
可以將數據從16字節壓縮到平均1.37字節,縮小12倍.並且設計了針對壓縮算法的內存數據結構.在保持對單個時間序列進行時間段查找的同時也能快速和高效的進行全數據掃描。
通過將時間序列數據寫到不同地域的主機中,容忍單節點故障,網絡切換,甚至是整個數據中心故障。
投資市場
2018年時序數據庫創業公司在投資市場有2筆著名的投資。
Timescale獲得了來自Benchmark Capital的\$12.4M Series A輪融資。 InfluxDB獲得了來自Sapphire Ventures的\$35M C輪融資。
業界典型時序數據庫解析
近2年來時序數據庫正處於高速發展的階段。國內外雲市場各大主流廠商已經從整個時序生態的不同角度切入,形成各自特色的解決方案完成佈局,開始搶佔流量。
而以Facebook Gorilla爲代表的優秀的時序數據庫則是脫胎於滿足自身業務發展的需要。學術上,在時序領域裏面更是涌現了一大批黑科技,把時序數據的技術深度推向更高的臺階。
阿里巴巴的TSDB團隊自2016年第一版時序數據庫落地後,逐步服務於DBPaaS,Sunfire等等集團業務,在2017年中旬公測後,於2018年3月底正式商業化。
在此過程中,TSDB在技術方面不斷吸納時序領域各家之長,開啓了自研的時序數據庫發展之路。
這個系列文章帶領讀者一起欣賞下當前時序領域的技術風景。
本文爲雲棲社區原創內容,未經允許不得轉載。