




在阿里雲上,很多客戶的應用都是多地域部署的, 比如在北京(cn-beijing)的地域部署一個應用讓北方的客戶訪問快一點,同時在杭州(cn-hangzhou)地域部署一份讓南方的客戶訪問快一點。多地域部署之後,業務數據被拆成了多份,而各個地域的數據庫都是獨立的,網絡又不通,給總體業務數據的分析造成了困難。今天我給大家介紹一套基於 DataLakeAnalytics, OSS, DataX 等幾個阿里雲產品的跨地域數據分析的解決方案。
其實雲產品本身(比如我們 DataLakeAnalytics 自己)也有跨地域數據分析的需求,這個方案也同樣適用。這個方案本來就是爲了分析 DataLakeAnalytics 自己的業務數據而探索出來的。
方案概覽
我們知道各個地域的RDS是不通的,除非你開公網訪問權限(有很大的安全風險,不推薦), 而且即使你開公網,要對多個數據庫裏面的數據進行聯合分析也不是一件容易的事情;而且這種數據分析的需求我們不希望它佔用太多的預算。
我們的方案是把各個地域的數據都同步到同一個地域的OSS上面去,然後用 DataLakeAnalytics 進行聯合分析。這個方案的優點在於 OSS 存儲收費非常便宜, DataLakeAnalytics 也是按查詢量收費的,你平時不查詢的時候一分錢都不用花。總體方案如下圖:
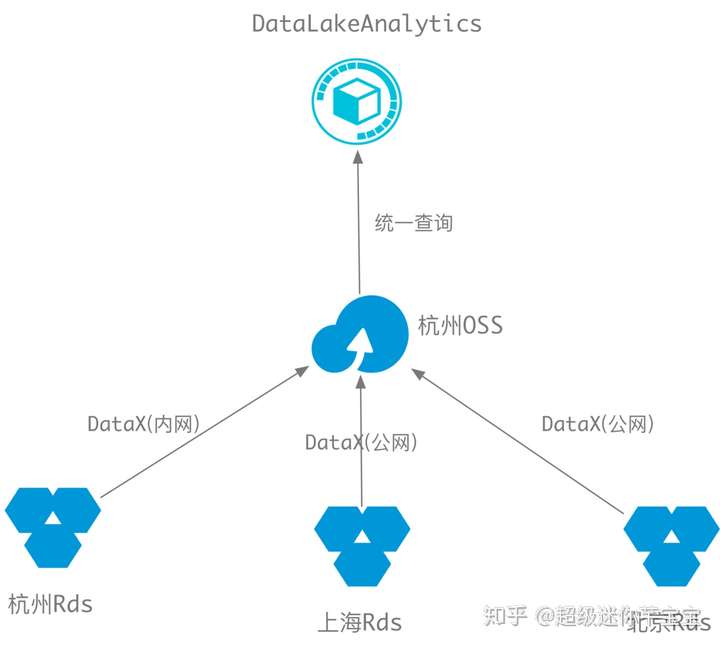
匯聚各個地域的數據
我們方案的第一步是把各個地域的RDS數據同步到同一個地域的OSS裏面去。阿里巴巴集團開源了一個很棒的數據搬運的工具: DataX, 可以把數據在各種不同的數據源之間進行搬運,它支持的數據源類型非常豐富: 從關係型的 MySQL, SQLServer, 到各種文件系統如 HDFS, OSS等等,其中我們需要的是從 MySQL 讀數據的 mysqlreader 插件以及往 OSS 寫數據的 osswriter 插件。
假定我們有下面這麼一個記錄人員信息的表 person 需要同步:
create table person ( id int primary key auto_increment, name varchar(1023), age int );
我們寫一個類似下面這樣的DataX任務描述文件 person.json :
{
"job": {
"setting": {
"speed": {
"channel": 1,
"byte": 104857600
},
"errorLimit": {
"record": 10
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "your-user-name",
"password": "your-password",
"column": [
"id",
"name",
"age",
],
"connection": [
{
"table": [
"person"
],
"jdbcUrl": [
"jdbc:mysql://your-rds.mysql.rds.aliyuncs.com:3306/dbname"
]
}
]
}
},
"writer": {
"name": "osswriter",
"parameter": {
"endpoint": "http://oss.aliyuncs.com",
"accessId": "your-access-id",
"accessKey": "your-access-secret",
"bucket": "mydb-bucket",
"object": "mydb/person/region=cn-hangzhou/person.csv",
"encoding": "UTF-8",
"fieldDelimiter": "|",
"writeMode": "truncate"
}
}
}
]
}
}這裏 MySQL 相關的信息填你的業務庫的信息,而 OSS 相關的信息選擇一個我們同步到的OSS的地址。注意 OSS 配置部分的 object 字段,mydb 保存你所有的數據, person 這個目錄保存你的 person 表的數據,region=cn-hangzhou 這個目錄就有意思了,它保存的是你的應用在 cn-hangzhou 這個region裏面的數據,同樣的,你可能還會有 cn-beijing, cn-shangahi 的數據等等。
然後執行如下命令:
// 執行前確保你已經下載並正確配置好 DataX 了。 python datax/bin/datax.py person.json
正確執行的話你會看到下面的輸出:
.....省略N行...... 2018-09-06 19:53:19.900 [job-0] INFO JobContainer - PerfTrace not enable! 2018-09-06 19:53:19.901 [job-0] INFO StandAloneJobContainerCommunicator - Total 251 records, 54067 bytes | Speed 5.28KB/s, 25 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.001s | All Task WaitReaderTime 0.026s | Percentage 100.00% 2018-09-06 19:53:19.902 [job-0] INFO JobContainer - 任務啓動時刻 : 2018-09-06 19:53:09 任務結束時刻 : 2018-09-06 19:53:19 任務總計耗時 : 10s 任務平均流量 : 5.28KB/s 記錄寫入速度 : 25rec/s 讀出記錄總數 : 251 讀寫失敗總數 : 0
這樣數據就自動同步到 OSS 上去了,你可以下載一個 oss-browser 去查看oss上面的數據:
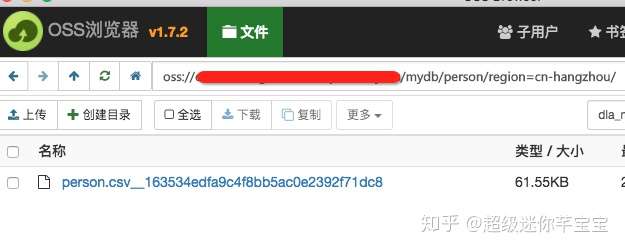
文件裏面數據大概是這樣的:
9|ethan|10 10|julian|20 11|train|30 12|wally|40
完成了一個地域的數據搬運之後,其它地域都可以照葫蘆畫瓢,唯一需要注意的地方是,雖然 MySQL 數據是各個 地域 的數據,但是 OSS 要用同一個根目錄 person ,因爲我們要做數據彙集嘛,把幾個地域的數據彙集完成之後,person 目錄的結構大概是這樣的:
使用 DataLakeAnalytics 分析匯聚後的OSS數據
下面的分析就可以交給 DataLakeAnalytics 了,分析OSS上的數據是 DataLakeAnalytics 的拿手好戲,在開始之前我們要有一個 DataLakeAnalytics 的賬號,目前 DataLakeAnalytics 正在公測,直接申請試用就好了。試用審批成功之後,你會獲得一個用戶名和密碼, 然後在控制檯登錄就可以使用:
或者如果你是極客,更偏愛命令行,你也可以使用普通的 MySQL 客戶端就可以連接 DLA 了:
mysql -hservice.cn-shanghai.datalakeanalytics.aliyuncs.com -P10000 -u<your-user-name> -p<your-password>
在這篇文章裏面,我會使用 MySQL 命令行給大家演示 DLA 的功能。
首先我們來建一個 DataLakeAnalytics 的數據庫:
CREATE DATABASE `mydb` WITH DBPROPERTIES ( catalog = oss, location = 'oss://your-bucket/mydb/' );
這裏的 oss://mydb-bucket/mydb/ 就是前面我們數據匯聚的 person 目錄的父目錄。
建好庫之後,我們再建一個表:
CREATE EXTERNAL TABLE IF NOT EXISTS `person` ( `id` bigint, `name` varchar(128), `age` int ) PARTITIONED BY (region varchar(63)) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' STORED AS TEXTFILE LOCATION 'oss://mydb-bucket/mydb/person';
注意這是一個分區表,分區的key是我們的region,這樣的好處一是各個地域在同步數據的時候比較簡單,不用擔心把別的地域的數據沖掉了;另外利用地域分區也使得我們在分析單個地域的時候掃描數據量會比較小,查詢速度更快。
建好表之後,我們運行如下命令讓 DataLakeAnalytics 去對OSS上的文件列表進行掃描以找到所有的 region 分區:
mysql> msck repair table person; +-----------------------------------------------------------------------------------------------------------+ | Result | +-----------------------------------------------------------------------------------------------------------+ | Partitions not in metastore: person:region=cn-beijing person:region=cn-hangzhou person:region=cn-shanghai | | Repair: Added partition to metastore mydb.person:region=cn-beijing | | Repair: Added partition to metastore mydb.person:region=cn-hangzhou | | Repair: Added partition to metastore mydb.person:region=cn-shanghai | +-----------------------------------------------------------------------------------------------------------+
現在我們就可以開心的對所有地域的數據進行聯合查詢了 :)
mysql> select * from person limit 5; +------+-------+------+-------------+ | id | name | age | region | +------+-------+------+-------------+ | 1 | james | 10 | cn-beijing | | 2 | bond | 20 | cn-beijing | | 3 | lucy | 30 | cn-beijing | | 4 | lily | 40 | cn-beijing | | 5 | trump | 10 | cn-hangzhou | +------+-------+------+-------------+ 5 rows in set (0.43 sec) mysql> select region, count(*) cnt from person group by region; +-------------+------+ | region | cnt | +-------------+------+ | cn-beijing | 4 | | cn-hangzhou | 4 | | cn-shanghai | 4 | +-------------+------+ 3 rows in set (0.18 sec)
總結
在這篇文章裏面,我們介紹了一種通過 DataLakeAnalytics, OSS, DataX 進行跨地域數據分析的方法。限於篇幅的原因方案的很多細節沒有進一步優化,比如我們其實可以對數據進行進一步按天分區,這樣每天同步的數據可以更少,效率更高;再比如我們沒有介紹如何週期性的進行數據同步,用crontab? 還是什麼調度系統?這些就留給讀者自己去探索了。
#阿里雲開年Hi購季#幸運抽好禮!
點此抽獎:【阿里雲】開年Hi購季,幸運抽好禮
本文爲雲棲社區原創內容,未經允許不得轉載。