




簡介
Prometheus是SoundCloud公司開發的一站式監控告警平臺,依賴少,功能齊全。
於2016年加入CNCF,廣泛用於 Kubernetes集羣的監控系統中,2018.8月成爲繼K8S之後第二個畢業的項目。Prometheus作爲CNCF生態圈中的重要一員,其活躍度僅次於 Kubernetes。
關鍵功能包括:
多維數據模型:metric,labels
靈活的查詢語言:PromQL, 在同一個查詢語句,可以對多個 metrics 進行乘法、加法、連接、取分數位等操作。
可獨立部署,拆箱即用,不依賴分佈式存儲
通過Http pull的採集方式
通過push gateway來做push方式的兼容
通過靜態配置或服務發現獲取監控項
支持圖表和dashboard等多種方式
核心組件:
Prometheus Server: 採集和存儲時序數據
client庫: 用於對接 Prometheus Server, 可以查詢和上報數據
push gateway處理短暫任務:用於批量,短期的監控數據的彙總節點,主要用於業務數據彙報等
定製化的exporters,比如:HAProxy, StatsD,Graphite等等, 彙報機器數據的插件
告警管理:Prometheus 可以配置 rules,然後定時查詢數據,當條件觸發的時候,會將 alert 推送到配置的 Alertmanager
多種多樣的支持工具
優勢和劣勢:
同InfluxDB相比, 在場景方面:PTSDB 適合數值型的時序數據。不適合日誌型時序數據和用於計費的指標統計。InfluxDB面向的是通用時序平臺,包括日誌監控等場景。而Prometheus更側重於指標方案。兩個系統之間有非常多的相似之處,包括採集,存儲,報警,展示等等
Influxdata的組合有:telegraf+Influxdb+Kapacitor+Chronograf
Promethues的組合有:exporter+prometheus server+AlertManager+Grafana
採集端prometheus主推拉的模式,同時通過push gateway支持推的模式。influxdata的採集工具telegraf則主打推的方式。
存儲方面二者在基本思想上相通,關鍵點上有差異包括:時間線的索引,亂序的處理等等。
數據模型上Influxdb支持多值模型,String類型等,更豐富一些。
Kapacitor 是一個混合了 prometheus 的數據處理,存儲規則,報警規則以及告警通知功能的工具.而AlertManager進一步提供了分組,去重等等。
influxdb之前提供的cluster模式被移除了,現在只保留了基於relay的高可用,集羣模式作爲商業版本的特性發布。prometheus提供了一種很有特色的cluster模式,通過多層次的proxy來聚合多個prometheus節點實現擴展。
同時開放了remote storage,因此二者又相互融合,Influxdb作爲prometheus的遠端存儲。
OpenTSDB 的數據模型與Prometheus幾乎相同,查詢語言上PromQL更簡潔,OpenTSDB功能更豐富。OpenTSDB依賴的是Hadoop生態,Prometheus成長於Kubernetes生態。
數據模型
採用單值模型, 數據模型的核心概念是metric,labels和samples.
格式:<metric name>{<label name>=<label value>, …}
例如:http_requests_total{method="POST",endpoint="/api/tracks"}。
metric的命名具有業務含義,比如http_request_total.
指標的類型分爲:Counter, Gauge,Historgram,Summary
labels用於表示維度.Samples由時間戳和數值組成。
jobs and instances
Prometheus 會自動生成target和instances作爲標籤
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
整體設計思路
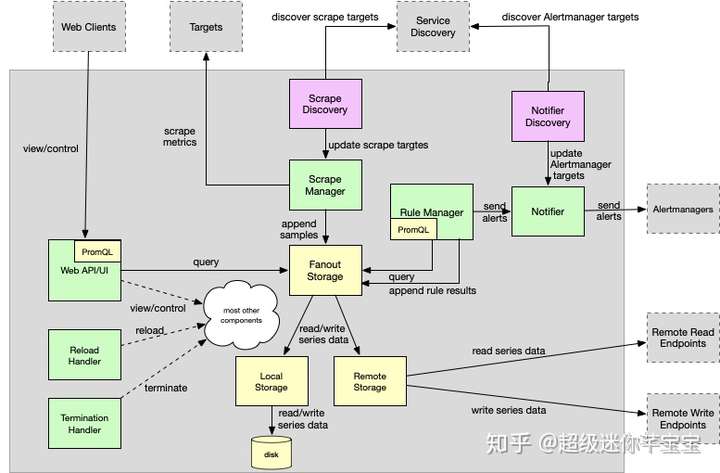
Prometheus的整體技術架構可以分爲幾個重要模塊:
Main function:作爲入口承擔着各個組件的啓動,連接,管理。以Actor-Like的模式協調組件的運行
Configuration:配置項的解析,驗證,加載
Scrape discovery manager:服務發現管理器同抓取服務器通過同步channel通信,當配置改變時需要重啓服務生效。
Scrape manager:抓取指標併發送到存儲組件
Storage:
Fanout Storage:存儲的代理抽象層,屏蔽底層local storage和remote storage細節,samples向下雙寫,合併讀取。
Remote Storage:Remote Storage創建了一個Queue管理器,基於負載輪流發送,讀取客戶端merge來自遠端的數據。
Local Storage:基於本地磁盤的輕量級時序數據庫。
PromQL engine:查詢表達式解析爲抽象語法樹和可執行查詢,以Lazy Load的方式加載數據。
Rule manager:告警規則管理
Notifier:通知派發管理器
Notifier discovery:通知服務發現
Web UI and API:內嵌的管控界面,可運行查詢表達式解析,結果展示。
PTSDB概述
本文側重於Local Storage PTSDB的解析. PTSDB的核心包括:倒排索引+窗口存儲Block。
數據的寫入按照兩個小時爲一個時間窗口,將兩小時內產生的數據存儲在一個Head Block中,每一個塊中包含該時間窗口內的所有樣本數據(chunks),元數據文件(meta.json)以及索引文件(index)。
最新寫入數據保存在內存block中, 2小時後寫入磁盤。後臺線程把2小時的數據最終合併成更大的數據塊,一般的數據庫在固定一個內存大小後,系統的寫入和讀取性能會受限於這個配置的內存大小。而PTSDB的內存大小是由最小時間週期,採集週期以及時間線數量來決定的。
爲防止內存數據丟失,實現wal機制。刪除記錄在獨立的tombstone文件中。
核心數據結構和存儲格式
PTSDB的核心數據結構是HeadAppender,Appender commit時wal日誌編碼落盤,同時寫入head block中。
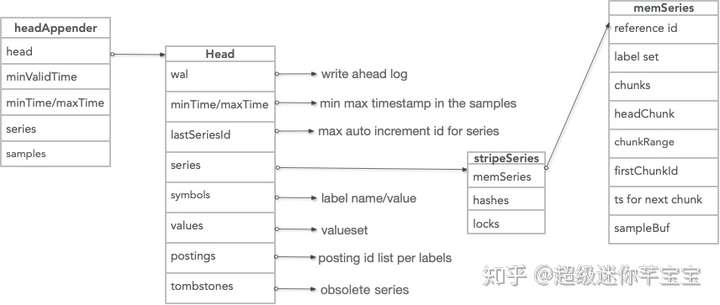
PTSDB本地存儲使用自定義的文件結構。主要包含:WAL,元數據文件,索引,chunks,tombstones
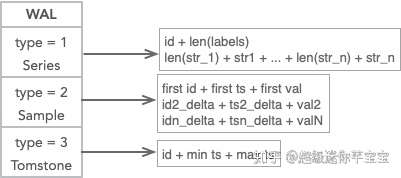
Write Ahead Log
WAL 有3種編碼格式:時間線,數據點,以及刪除點。總體策略是基於文件大小滾動,並且根據最小內存時間執行清除。
當日志寫入時,以segment爲單位存儲,每個segment默認128M, 記錄數大小達到32KB頁時刷新一次。當剩餘空間小於新的記錄數大小時,創建新的Segment。
當compation時WAL基於時間執行清除策略,小於內存中block的最小時間的wal日誌會被刪除。
重啓時,首先打開最新的Segment,從日誌中恢復加載數據到內存。
元數據文件
meta.json文件記錄了Chunks的具體信息, 比如新的compactin chunk來自哪幾個小的chunk。 這個chunk的統計信息,比如:最小最大時間範圍,時間線,數據點個數等等
compaction線程根據統計信息判斷該blocks是否可以做compact:(maxTime-minTime)佔整體壓縮時間範圍的50%, 刪除的時間線數量佔總體數量的5%。

索引
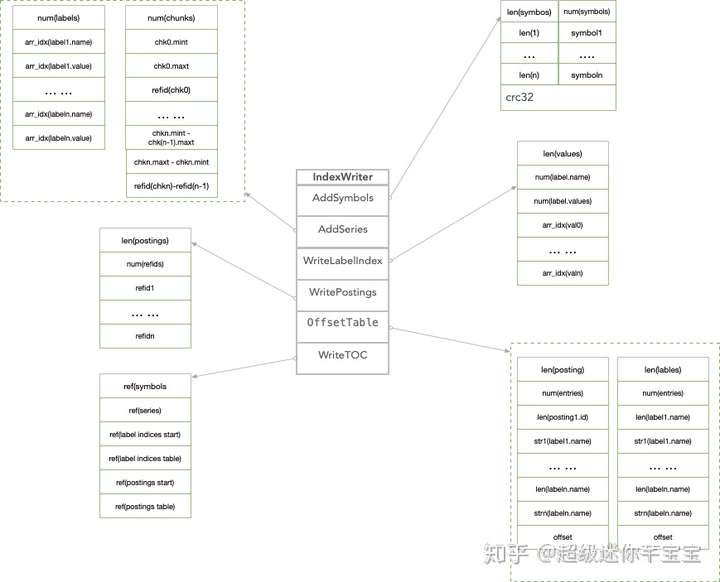
索引一部分先寫入Head Block中,隨着compaction的觸發落盤。
索引採用的是倒排的方式,posting list裏面的id是局部自增的,作爲reference id表示時間線。索引compact時分爲6步完成索引的落盤:Symbols->Series->LabelIndex->Posting->OffsetTable->TOC
Symbols存儲的是tagk, tagv按照字母序遞增的字符串表。比如__name__,go_gc_duration_seconds, instance, localhost:9090等等。字符串按照utf8統一編碼。
Series存儲了兩部分信息,一部分是標籤鍵值對的符號表引用;另外一部分是時間線到數據文件的索引,按照時間窗口切割存儲數據塊記錄的具體位置信息,因此在查詢時可以快速跳過大量非查詢窗口的記錄數據,
爲了節省空間,時間戳範圍和數據塊的位置信息的存儲採用差值編碼。LabelIndex存儲標籤鍵以及每一個標籤鍵對應的所有標籤值,當然具體存儲的數據也是符號表裏面的引用值。
Posting存儲倒排的每個label對所對應的posting refid
OffsetTable加速查找做的一層映射,將這部分數據加載到內存。OffsetTable主要關聯了LabelIndex和Posting數據塊。TOC是各個數據塊部分的位置偏移量,如果沒有數據就可以跳過查找。
Chunks
數據點存放在chunks目錄下,每個data默認512M,數據的編碼方式支持XOR,chunk按照refid來索引,refid由segmentid和文件內部偏移量兩個部分組成。
Tombstones
記錄刪除通過mark的方式,數據的物理清除發生在compaction和reload的時候。以時間窗口爲單位存儲被刪除記錄的信息。

查詢PromQL
Promethues的查詢語言是PromQL,語法解析AST,執行計劃和數據聚合是由PromQL完成,fanout模塊會向本地和遠端同時下發查詢數據,PTSDB負責本地數據的檢索。
PTSDB實現了定義的Adpator,包括Select, LabelNames, LabelValues和Querier.
PromQL定義了三類查詢:
瞬時數據 (Instant vector): 包含一組時序,每個時序只有一個點,例如:http_requests_total
區間數據 (Range vector): 包含一組時序,每個時序有多個點,例:http_requests_total[5m]
純量數據 (Scalar): 純量只有一個數字,沒有時序,例如:count(http_requests_total)
一些典型的查詢包括:
查詢當前所有數據
http_requests_total
select * from http_requests_total where timestamp between xxxx and xxxx條件查詢
http_requests_total{code="200", handler="query"}
select * from http_requests_total where code="200" and handler="query" and timestamp between xxxx and xxxx模糊查詢: code 爲 2xx 的數據
http_requests_total{code~="20"}
select * from http_requests_total where code like "%20%" and timestamp between xxxx and xxxx值過濾: value大於100
http_requests_total > 100
select * from http_requests_total where value > 100 and timestamp between xxxx and xxxx範圍區間查詢: 過去 5 分鐘數據
http_requests_total[5m]
select * from http_requests_total where timestamp between xxxx-5m and xxxxcount 查詢: 統計當前記錄總數
count(http_requests_total)
select count(*) from http_requests_total where timestamp between xxxx and xxxxsum 查詢:統計當前數據總值
sum(http_requests_total)
select sum(value) from http_requests_total where timestamp between xxxx and xxxxtop 查詢: 查詢最靠前的 3 個值
topk(3, http_requests_total)
select * from http_requests_total where timestamp between xxxx and xxxx order by value desc limit 3irate查詢:速率查詢
irate(http_requests_total[5m])
select code, handler, instance, job, method, sum(value)/300 AS value from http_requests_total where timestamp between xxxx and xxxx group by code, handler, instance, job, method;
PTSDB關鍵技術點
亂序處理
PTSDB對於亂序的處理採用了最小時間窗口的方式,指定合法的最小時間戳,小於這一時間戳的數據會丟棄不再處理。
合法最小時間戳取決於當前head block裏面最早的時間戳和可存儲的chunk範圍。
這種對於數據行爲的限定極大的簡化了設計的靈活性,對於compaction的高效處理以及數據完整性提供了基礎。
內存的管理
使用mmap讀取壓縮合並後的大文件(不佔用太多句柄),
建立進程虛擬地址和文件偏移的映射關係,只有在查詢讀取對應的位置時纔將數據真正讀到物理內存。
繞過文件系統page cache,減少了一次數據拷貝。
查詢結束後,對應內存由Linux系統根據內存壓力情況自動進行回收,在回收之前可用於下一次查詢命中。
因此使用mmap自動管理查詢所需的的內存緩存,具有管理簡單,處理高效的優勢。
Compaction
Compaction主要操作包括合併block、刪除過期數據、重構chunk數據。
合併多個block成爲更大的block,可以有效減少block個,當查詢覆蓋的時間範圍較長時,避免需要合併很多block的查詢結果。
爲提高刪除效率,刪除時序數據時,會記錄刪除的位置,只有block所有數據都需要刪除時,纔將block整個目錄刪除。
block合併的大小也需要進行限制,避免保留了過多已刪除空間(額外的空間佔用)。
比較好的方法是根據數據保留時長,按百分比(如10%)計算block的最大時長, 當block的最小和最大時長超過2/3blok範圍時,執行compaction
快照
PTSDB提供了快照備份數據的功能,用戶通過admin/snapshot協議可以生成快照,快照數據存儲於data/snapshots/-目錄。
PTSDB最佳實踐
在一般情況下,Prometheus中存儲的每一個樣本大概佔用1-2字節大小。如果需要對Prometheus Server的本地磁盤空間做容量規劃時,可以通過以下公式計算:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample保留時間(retention_time_seconds)和樣本大小(bytes_per_sample)不變的情況下,如果想減少本地磁盤的容量需求,
只能通過減少每秒獲取樣本數(ingested_samples_per_second)的方式。
因此有兩種手段,一是減少時間序列的數量,二是增加採集樣本的時間間隔。
考慮到Prometheus會對時間序列進行壓縮,因此減少時間序列的數量效果更明顯。PTSDB的限制在於集羣和複製。因此當一個node宕機時,會導致一定窗口的數據丟失。
當然,如果業務要求的數據可靠性不是特別苛刻,本地盤也可以存儲幾年的持久化數據。
當PTSDB Corruption時,可以通過移除磁盤目錄或者某個時間窗口的目錄恢復。PTSDB的高可用,集羣和歷史數據的保存可以藉助於外部解決方案,不在本文討論範圍。
歷史方案的侷限性,PTSDB在早期採用的是單條時間線一個文件的存儲方式。這中方案有非常多的弊端,比如:
Snapshot的刷盤壓力:定期清理文件的負擔;低基數和長週期查詢查詢,需要打開大量文件;時間線膨脹可能導致inode耗盡。
PTSDB面臨的挑戰
在使用過程中,PTSDB也在某些方面遇到了一些問題,比如;
Compaction對於IO, CPU, 以及Memory的影響
冷啓動後,預熱階段CPU和內存佔用會上升
在高速寫入時會出現CPU的Spike等等
總結
PTSDB 作爲K8S監控方案裏面存儲時序數據的實施標準,其在時序屆影響力和熱度都在逐步上升。Alibaba TSDB目前已經支持通過Adapter的方式作爲其remote storage的方案。
#阿里雲開年Hi購季#幸運抽好禮!
點此抽獎:【阿里雲】開年Hi購季,幸運抽好禮
本文爲雲棲社區原創內容,未經允許不得轉載。