




Kafka 是非常流行的分佈式流式處理和大數據消息隊列解決方案,在技術行業已經得到了廣泛採用,在 Dropbox 也不例外。Kafka 在 Dropbox 的很多分佈式系統數據結構中發揮着重要的作用:數據分析、機器學習、監控、搜索和流式處理,等等。在 Dropbox,Kafka 集羣由 Jetstream 團隊負責管理,他們的主要職責是提供高質量的 Kafka 服務。他們的一個主要目標是瞭解 Kafka 在 Dropbox 基礎設施中的吞吐量極限,這對於針對不同用例做出適當的配置決策來說至關重要。最近,他們創建了一個自動化測試平臺來實現這一目標。這篇文章將分享他們所使用的方法和一些有趣的發現。
測試平臺
上圖描繪了本文所使用的測試平臺的設置。我們在 Spark 中使用 Kafka 客戶端,這樣就可以以任意規模生成和消費流量。我們搭建了三個不同大小的 Kafka 集羣,要調整集羣大小,只需要將流量重定向到不同的集羣。我們創建了一個 Kafka 主題,用於生成測試流量。爲簡單起見,我們將流量均勻地分佈在 Kafka broker 之間。爲實現這一目標,我們創建了測試主題,分區數量是 broker 數量的 10 倍,這樣每個 broker 都是 10 個分區的首領。因爲寫入單個分區是串行的,所以如果每個 broker 的分區太少會導致寫入競爭,從而限制了吞吐量。根據我們的實驗,10 是一個恰到好處的數字,可以避免寫入競爭造成吞吐量瓶頸。
由於基礎設施的分佈式特性,客戶端遍佈在美國的不同地區。因爲測試流量遠低於 Dropbox 網絡主幹的限制,所以我們可以安全地假設跨區域流量的限制也適用於本地流量。
是什麼影響了工作負載?
有一系列因素會影響 Kafka 集羣的工作負載:生產者數量、消費者羣組數量、初始消費者偏移量、每秒消息數量、每條消息的大小,以及所涉及的主題和分區的數量,等等。我們可以自由地設置參數,因此,很有必要找到主導的影響因素,以便將測試複雜性降低到實用水平。
我們研究了不同的參數組合,最後得出結論,我們需要考慮的主要因素是每秒產生的消息數(mps)和每個消息的字節大小(bpm)。
流量模型
我們採取了正式的方法來了解 Kafka 的吞吐量極限。特定的 Kafka 集羣都有一個相關聯的流量空間,這個多維空間中的每一個點都對應一個 Kafka 流量模式,可以通過參數向量來表示:<mps、bpm、生產者數量、消費者羣組數量、主題數量……>。所有不會導致 Kafka 過載的流量模式都形成了一個封閉的子空間,其表面就是 Kafka 集羣的吞吐量極限。
對於初始測試,我們選擇將 mps 和 bpm 作爲吞吐量極限的基礎,因此流量空間就降到二維平面。這一系列可接受的流量形成了一個封閉的區域,找到 Kafka 的吞吐量極限相當於繪製出該區域的邊界。
自動化測試
爲了以合理的精度繪製出邊界,我們需要用不同的設置進行數百次實驗,通過手動操作的方式是不切實際的。因此,我們設計了一種算法,無需人工干預即可運行所有的實驗。
過載指示器
我們需要找到一系列能夠以編程方式判斷 Kafka 健康狀況的指標。我們研究了大量的候選指標,最後鎖定以下這些:
IO 線程空閒低於 20%:這意味着 Kafka 用於處理客戶端請求的工作線程池太忙而無法處理更多工作負載。
同步副本集變化超過 50%:這意味着在 50%的時間內至少有一個 broker 無法及時複製首領的數據。
Jetstream 團隊還使用這些指標來監控 Kafka 運行狀況,當集羣承受過大壓力時,這些指標會首當其衝發出信號。
找到邊界
爲了找到一個邊界點,我們讓 bpm 維度固定,並嘗試通過更改 mps 值來讓 Kafka 過載。當我們有一個安全的 mps 值和另一個導致集羣接近過載的 mps 值時,邊界就找到了。我們將安全的值視爲邊界點,然後通過重複這個過程來找到整條邊界線,如下所示:
值得注意的是,我們調整了具有相同生產速率的生產者(用 np 表示),而不是直接調整 mps。主要是因爲批處理方式導致單個生產者的生產速率不易控制。相反,改變生產者的數量可以線性地縮放流量。根據我們早期的研究,單獨增加生產者數量不會給 Kafka 帶來明顯的負載差異。
我們通過二分查找來尋找單邊界點。二分查找從一個非常大的 np[0,max] 窗口開始,其中 max 是一個肯定會導致過載的值。在每次迭代中,選擇中間值來生成流量。如果 Kafka 在使用這個值時發生過載,那麼這個值將成爲新的上限,否則就成爲新的下限。當窗口足夠窄時,停止該過程。我們將對應於當前下限的 mps 值視爲邊界。
結果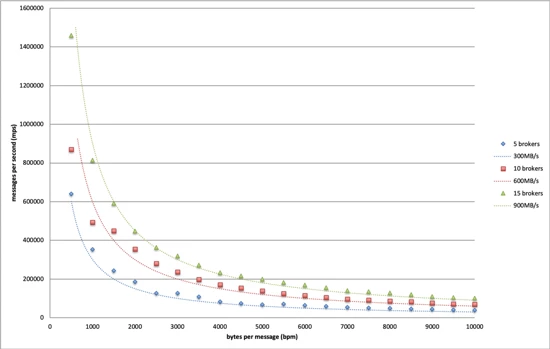
我們在上圖中繪製了不同大小的 Kafka 的邊界。基於這個結果,我們可以得出結論,Dropbox 基礎設施可以承受的最大吞吐量爲每個 broker 60MB/s。
值得注意的是,這只是一個保守的極限,因爲我們測試用的消息大小完全是隨機的,主要是爲了最小化 Kafka 內部消息壓縮機制所帶來的影響。在生產環境中,Kafka 消息通常遵循某種模式,因爲它們通常由相似的過程生成,這爲壓縮優化提供了很大的空間。我們測試了一個極端情況,消息全部由相同的字符組成,這個時候我們可以看到更高的吞吐量極限。
此外,當有 5 個消費者羣組訂閱測試主題時,這個吞吐量限制仍然有效。換句話說,當讀取吞吐量是當前 5 倍時,仍然可以實現這樣的寫入吞吐量。當消費者羣組增加到 5 個以上時,隨着網絡成爲瓶頸,寫入吞吐量開始下降。因爲 Dropbox 生產環境中的讀寫流量比遠低於 5,所以我們得到的極限適用於所有生產集羣。
這個結果爲將來的 Kafka 配置提供了指導基礎。假設我們允許最多 20%的 broker 離線,那麼單個 broker 的最大安全吞吐量應爲 60MB/s * 0.8 ~= 50MB/s。有了這個,我們可以根據未來用例的估算吞吐量來確定集羣大小。
對未來工作的影響
這個平臺和自動化測試套件將成爲 Jetstream 團隊的一筆寶貴的財富。當我們切換到新硬件、更改網絡配置或升級 Kafka 版本時,可以重新運行這些測試並獲得新的吞吐量極限。我們可以應用相同的方法來探索其他影響 Kafka 性能的因素。最後,這個平臺可以作爲 Jetstream 的測試平臺,以便模擬新的流量模式或在隔離環境中重現問題。
總結
在這篇文章中,我們提出了一種系統方法來了解 Kafka 的吞吐量極限。值得注意的是,我們是基於 Dropbox 的基礎設施得到的這些結果,因此,由於硬件、軟件棧和網絡條件的不同,我們得到的數字可能不適用於其他 Kafka 實例。我們希望這裏介紹的技術能夠幫助讀者去了解他們自己的 Kafka 系統。