




向量(Vector),計算機編程語言用語,在如VB、C、C++、Pascal、Python或者其他編程語言中的向量,就是一個存放數據的地方,類似於一維數組和鏈表。
至於向量,通常會被用在比較兩個數據的差異上
舉個例子,我想知道“文章 A 和文章 B 的相似度”:
那麼我可能會收集這些信息:
文章 A 和 B 的字數差異
文章 A 和 B 中相同的單詞及其數量
文章 A 和 B 中完全相同的句子及其數量
這些信息是“不同維度上的值”,其實也就是向量了。
在實際應用中,我很可能會再設計一種算法,來”比較 A 和 B 的相似度與 A 和 C 的相似度哪個更高“,
這其實就是在定義一種向量減法。


神經網絡分析
假設我們的詞彙只有4個,girl, woman, boy, man,下面就思考用兩種不同的表達方式會有什麼區別。
儘管我們知道他們彼此的關係,但是計算機並不知道。在神經網絡的輸入層中,每個單詞都會被看作一個節點。 而我們知道訓練神經網絡就是要學習每個連接線的權重。如果只看第一層的權重,下面的情況需要確定43個連接線的關係,因爲每個維度都彼此獨立,girl的數據不會對其他單詞的訓練產生任何幫助,訓練所需要的數據量,基本就固定在那裏了。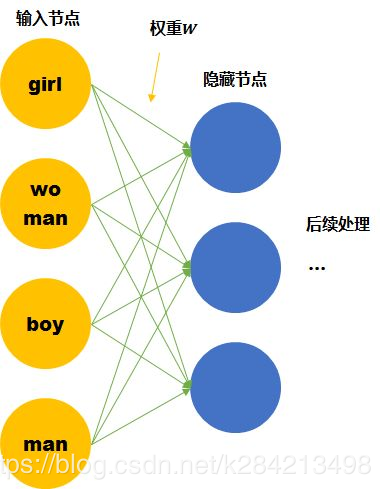
Distributed representation
我們這裏手動的尋找這四個單詞之間的關係 f 。可以用兩個節點去表示四個單詞。每個節點取不同值時的意義如下表。 那麼girl就可以被編碼成向量[0,1],man可以被編碼成[1,1](第一個維度是gender,第二個維度是age)。
那麼這時再來看神經網絡需要學習的連接線的權重就縮小到了23。同時,當送入girl爲輸入的訓練數據時,因爲它是由兩個節點編碼的。那麼與girl共享相同連接的其他輸入例子也可以被訓練到(如可以幫助到與其共享female的woman,和child的boy的訓練)。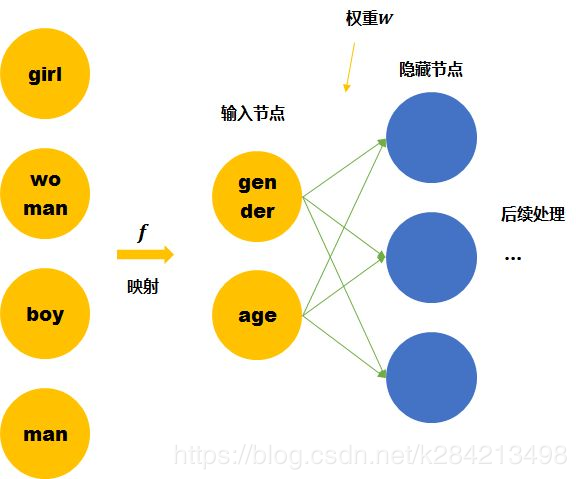
Word embedding也就是要達到第二個神經網絡所表示的結果,降低訓練所需要的數據量。
Word embedding就是要從數據中自動學習到輸入空間到Distributed representation空間的 映射f 。