Jdk 1.8
-
數據結構
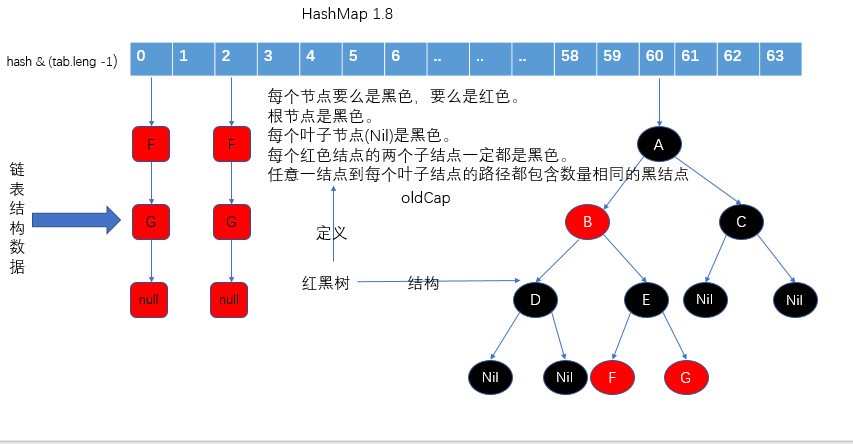
1.8的版本的HashMap採用數組+鏈表+紅黑樹的數據結構來存儲數據,還是通過hash & (tab.length - 1)來確定在數組的位置,不過在數據的存儲方面加了一個紅黑樹,當鏈表的大於等於8時,並且table的長度大於等於64時,就把這個鏈樹化,不然還是擴容.增加紅黑樹,是爲了提高查找節點的時間.結構如下圖所示.
![HashMap 源碼淺析 1.8]()
-
基本成員變量
capacity 容量/** * 初始容量 */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16max_capacity 最大容量
/** * 最大容量 */ static final int MAXIMUM_CAPACITY = 1 << 30;loadFactor 負載因子
/** * 負載因子 */ static final float DEFAULT_LOAD_FACTOR = 0.75f;treeify_threshold 樹化(轉換爲紅黑樹)的閾值
// 鏈表轉爲紅黑樹的閾值,第9個節點 static final int TREEIFY_THRESHOLD = 8;untreeify_threshold 轉換爲鏈表的閾值
// 紅黑樹轉爲鏈表的閾值,6個節點轉移 static final int UNTREEIFY_THRESHOLD = 6;min_treeify_capacity 樹化的最小容量
// 轉紅黑樹時,table的最小長度 static final int MIN_TREEIFY_CAPACITY = 64;node 鏈表
static class Node<K,V> implements Map.Entry<K,V> { // 當前node的hash final int hash; final K key; V value; // 指向下個node Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }TreeNode 紅黑樹
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // 父節點 TreeNode<K,V> left; // 左兒子節點 TreeNode<K,V> right; // 右兒子基點 TreeNode<K,V> prev; // 上一個節點 boolean red; // 是否爲紅色 TreeNode(int hash, K key, V val, Node<K,V> next) { super(hash, key, val, next); } - 構造方法
有參構造 (和1.7一樣)public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); }無參構造(和1.7一樣)
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted } -
基本方法
Put()方法
執行流程:
(1) 判斷當前table有沒有初始化,沒有就調用resize()方法初始化.(resize方法既是擴容也是初始化)
(2) 判斷算出的位置i處有沒有值,沒有值,創建一個新的node,插入i位置.
(3) 當前i位置有值,判斷頭結點的hash和key是否和傳入的key和hash相等,相等則記錄這個e.
(4) 與頭節點的key和hash不同,判斷節點是否是樹節點,如果是,調用樹節點的插入方法putTreeVal()方法.(佔時不瞭解紅黑樹的底層方法實現邏輯,待續).
(5) 不是樹結構,那證明是鏈表結構,遍歷鏈表結構,並記錄鏈表長度binCount.主要做了兩步,(1)在鏈表裏找到和傳入的key和hash相等的基點,並記錄,(2) 沒有找到,創建一個節點,插入鏈表的尾部,並判斷鏈表長度有沒有大於等於8,如果是就調treeifyBin方法決定是否需要樹化.
(6) 判斷前面記錄的e節點是否爲空,不爲空證明找到了相同的基點,那就替換value,返回oldValue.
(7) 整個插入流程已經結束,接下來要判斷是否需要擴容,如果(++size > threshold)滿足,那麼就調用擴容方法resize();public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } /** * put */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) // table爲null,table的length爲0,table還沒有初始化 n = (tab = resize()).length; //調用擴容方法,初始化table if ((p = tab[i = (n - 1) & hash]) == null) //table{[i] 沒有值,直接插入 tab[i] = newNode(hash, key, value, null); else { // 有值 Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) // 找到了相同的key e = p; else if (p instanceof TreeNode) // 判斷是否是樹結構 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // 調用樹的插入 else { // 遍歷鏈表,並記錄節點的長度 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { // 找到最後一個節點了 p.next = newNode(hash, key, value, null); //設置當前節點爲爲p的next if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 如果節點長度大於等於了8,就調用treeifyBin方法 treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) // 找到了相同的key // 此時break,返回的是e.key與傳入的key相等的e,以便下面進行替換 break; p = e; } } // e != null 說明前面的遍歷找到了相同的key,下面就行替換,返回舊值 if (e != null) { // existing mapping for key // V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) // onlyIfAbsent默認是false e.value = value; // 替換value afterNodeAccess(e); return oldValue; // 返回舊的value } } ++modCount; // 當前值大於閾值,進行擴容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }resize()方法(初始化和擴容都是創建新的table)
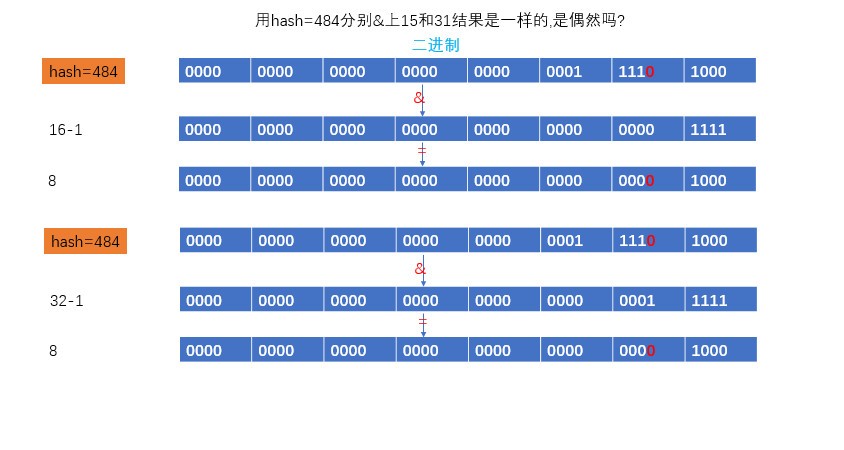
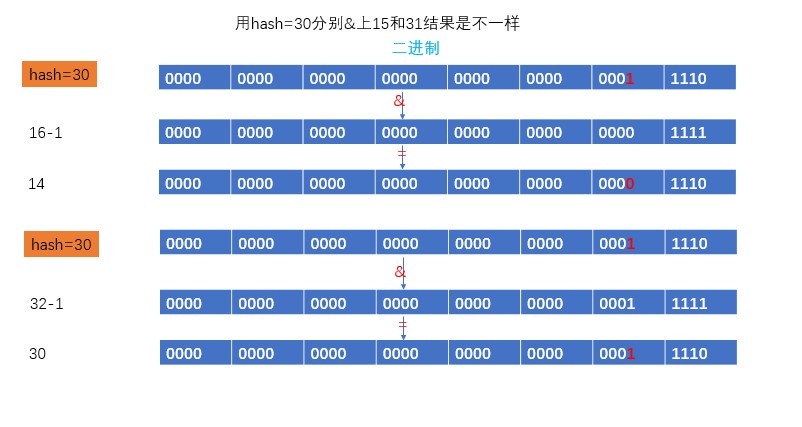
解釋爲什麼在新table的位置沒有重新計算,而是根據(e.hash & oldCap) == 0,等於0就是在原位置,不等於0時,就是newtable[原位置+oldCap] ,如下圖.
table長度我們以16爲例,hash值我們以484和30爲例,我們發現484&16=0,30&16=30,我們發現一個區別就是他們的他們的低5位一個是0,一個是1.![HashMap 源碼淺析 1.8]()
我們讓低5位是0的484,分別&上(16-1)和(32-1),結論是位置沒有發生變化,所以說如果低5位是0,那麼擴容前和擴容後位置不變.![HashMap 源碼淺析 1.8]()
我們讓低5位是1的30,分別&上(16-1)和(32-1),結論是位置發生變化,所以說如果低5位是1,那麼新位置就是原來位置+oldCap.![HashMap 源碼淺析 1.8]()
其實我們發現(e.hash & oldCap) == 0 只是爲了證明低5位是0還是1,這是爲什麼了,其實是和(16-1)和(32-1)有着密切的關係,15二進制是1111,31是11111,我們發現不管哪個數&上15或者31都是這個數低4位或者低5位本身,所以e.hash如果低5位0,那其實都是&1111,因爲低5位是0&運算下還是0,如果e.hash的低5位是1,那麼和0相比就是低5位會變成1,所以需要加上這個多的位置的值oldCap./** * 擴容 * @return */ final Node<K,V>[] resize() { // 舊table Node<K,V>[] oldTab = table; // 舊的table長度 int oldCap = (oldTab == null) ? 0 : oldTab.length; // 舊的閾值 int oldThr = threshold; int newCap, newThr = 0; // 證明就table,已經被初始化了 if (oldCap > 0) { // 如果舊的table大於做大值,閾值就設置爲Internet的最大值,返回 if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } // 給newCap賦值 newCap = oldCap << 1 (* 2^1) < MAXIMUM_CAPACITY(1 << 30) // oldCap >= 16 證明已經初始化過了,現在是擴容(假如oldCap就是16) // 新閾值 newThr = (oldThr = threshold) = 12 << 1(12 * 2^1) else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold // 新的閾值 } // 這種情況是table還沒有初始化 // oldThr >0 是因爲在有參構造裏面會把cap賦值給threshold else if (oldThr > 0) // initial capacity was placed in threshold // 容量就是oldThr newCap = oldThr; // 無參構造,容量和閾值都使用默認 else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } // newThr=0證明使用的是有參構造,容量有值,閾值沒有值 // 所以初始化閾值 if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } /** 上面屬於table參數準備部分,分爲初始化或者擴容 */ // 新的閾值 threshold = newThr; // 創建新的table @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { // 開始遍歷舊的table,進行數據遷移 for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; // 釋放內存地址 if (e.next == null) // 表示只有一個元素 newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) // 如果是樹結構,調用樹結構的方法 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order // 鏈表結構的數據 lo 表示位置不變 hi表示位置是原來的位置+oldCap // 是通過(e.hash & oldCap) == 0 這句話來判斷的 Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; // 解釋在上面的圖片 if ((e.hash & oldCap) == 0) { if (loTail == null) // 第一次循環 tail 爲null,所以頭和尾都是 e loHead = e; // 頭部是當前的e else // 接下來的循環tail不爲null loTail.next = e; // loTail 是上一次滿足if的e // e 是這一次滿足if的e // 所以loTail.next = e的目的就是,上一次滿足if的e指向下一次滿足if的e // 代碼就是loTail.next = e loTail = e; // 每次循環尾部就是當前節點 } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); // 位置不變還是j if (loTail != null) { loTail.next = null; // 尾部節點的next設置爲null newTab[j] = loHead; // 設置頭結點指向table[j] (第一次循環時,head=tail,接下來循環給tail追加節點) } // 位置變化,是 j+oldCap if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }get()方法
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } /** * 獲取值 */ final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && // table不是null,table的長度大於0 (first = tab[(n - 1) & hash]) != null) { // ,根據可以取得第一個node不爲空 if (first.hash == hash && // always check first node 對比第一個hash和當前值的hash是否一樣 ((k = first.key) == key || (key != null && key.equals(k)))) return first; // 等於第一個,返回 if ((e = first.next) != null) { // 向下遍歷,next不等於空 if (first instanceof TreeNode) // 判斷是否是樹結構 return ((TreeNode<K,V>)first).getTreeNode(hash, key); // 查找 do { // 不是樹,就是鏈表,遍歷鏈表 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; // 沒有找到,返回null } - 總結
1.8 在數據結構方面加入了紅黑樹,提升了查詢的性能,在鏈表插入方面是先插入的在前面,而在1.7先插入的在後面.在擴容方面,沒有重新計算hash,這算是一大改變,還有就是在擴容後鏈表的順序沒有改變.紅黑樹方面佔時不太瞭解.
前面的1.7 HashMap和1.8我們都講了loadFactor負載因子,來解釋下這個的作用,loadFactor越小,說明存儲的元素就少,因爲HashMap存在hash衝突,所以存的元素越少,衝突就越小,查詢的效率就的到了提升,但是存的元素少了,就浪費了容量,所以這是一種以空間換時間的做法.loadFactor越大,說明存的元素就越多,數據多了hash衝突就會提高,所以查詢時間就會提高,這是一種以時間換空間的做法.所以具體是需要時間還是空間根據自己的功能來確定.