Jdk 1.7
-
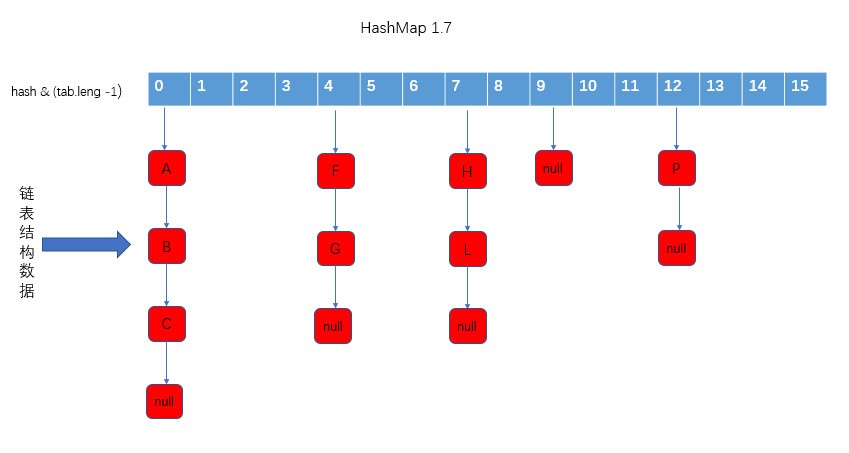
數據結構
1.7版本的HashMap採用數組加鏈表的方式存儲數據,數組是用來存儲數據的在數組的位置,鏈表則時用來存放數據的,由於根據hash可能發生碰撞,一個位置會出現多個數據,所以採用鏈表結構來存儲數據,結構如下圖所示.
![HashMap 源碼淺析 1.7]()
-
基本成員變量
capacity 數組的長度// 當前數組的容量,始終保持2^n,可以擴容,擴容後是當前線程的2倍 // 1 << 4 = 1 * 2^4 1的二進制左移4位 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16capacity 的最大值 (擴容時,如果已經是最大值,會設置成Integer.MAX_VALUE)
// 如果傳入的值大於該值,也會替換爲 1 << 30(2 ^ 30) static final int MAXIMUM_CAPACITY = 1 << 30;factor 負載因子(用來算閾值)
// 負載因子 默認值爲 0.75 static final float DEFAULT_LOAD_FACTOR = 0.75f;threshold 閾值(capacity * factor),擴容時用來判斷有沒有大於等於這個值
int threshold;size
// map的容量 transient int size;Entry (存儲數據的地方)
static class Entry<K,V> implements Map.Entry<K,V> { // 就是傳輸key final K key; // 就是value V value; // 用於指向單項鍊表的下一個Entry Entry<K,V> next; // 通過key計算的hash值 int hash; /** * Creates new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } -
構造方法
有參構造public HashMap(int initialCapacity, float loadFactor) { // 容量不能小於0 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); // 容量大於MAXIMUM_CAPACITY時,等於MAXIMUM_CAPACITY if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; // loadFactor不能小於等於0 if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init(); }無參構造
// 使用默認的容量和負載因子public HashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); } -
基本方法
Put方法 (具體流程看下面的執行流程分析或者代碼註釋)
具體執行流程:
(1) 判斷當前table是否爲EMPTY_TABLE={},證明沒有初始化,調用inflateTable初始化,具體詳見後面inflateTable()方法代碼分析.
(2) 判斷key是否爲null,是null調用putForNullKey插入方法(證明1.7的HashMap允許key爲null),具體詳見後面putForNullKey()方法代碼分析.
(3) 獲取當前key的hash,然後算出hash在數組的位置i(hash & (tab.length - 1)).給大家解釋下爲什麼數組的長度必須是2的冥,是和算i的位置有關係,因爲如果一個數是2的冥次方,假如這個數是n,那麼 hash % n = hash & (n -1),這就是爲什麼i的位置一定會在數組長度範圍中,因爲取得是餘數,還有就是位運算比直接取餘效率高.
(4) 判斷當前位置上有沒有值table[i],如果有值,遍歷鏈表,找出相同的key和hash,然後替換value,返回舊的value(oldOvalue).
(5) 如果沒有找到相同的key和hash,那麼就添加這個節點(Entry),方法addEntry().
(6) 在addEntry()方法裏面判斷需不需擴容,需要就擴容,調用擴容方法resize(),然後在調用 createEntry()方法添加節點,size++.// 插入 public V put(K key, V value) { // 當插入第一個元素時,需要初始化 if (table == EMPTY_TABLE) { // 初始化 inflateTable(threshold); } // key爲null是 if (key == null) // 找出key爲null,替換返回舊值 // 沒有則新添加一個key爲null的Entry return putForNullKey(value); // 計算hash值 int hash = hash(key); // 根據hash,找出table的位置 int i = indexFor(hash, table.length); // 因爲在table[i]中,可能存在多個元素(同一個hash),所以要基於鏈表實現 // 循環table[i]上的鏈表(不爲空),存在就修改,返回舊值(oldValue) for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; // 爲空或者不存在,則新添加(需要計算容量) addEntry(hash, key, value, i); return null; }inflateTable初始化方法 (懶加載,只有第一次調用put方法時才初始化)
// 初始化table private void inflateTable(int toSize) { // Find a power of 2 >= toSize // 計算出大於等於toSize最鄰近的2^n(所以capacity一定是2^n) int capacity = roundUpToPowerOf2(toSize); // 在此計算閾值 capacity * loadFactor threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); // 創建capacity大小的capacity數組就是hashmap的容器 table = new Entry[capacity]; initHashSeedAsNeeded(capacity); }putForNullKey方法(存儲key爲null的數據)
具體執行流程:
(1) 遍歷table[0]處的鏈表(說明nullkey永遠存在table[0]位置)
(2) 找到key==null 的數據,替換value,返回舊的value
(3) 沒有找到,就在table[0]位置添加一個key爲null的Entry,調用addEntry()方法.private V putForNullKey(V value) { // 遍歷table[0]的鏈表 // 找到key等於null的,把值覆蓋,返回舊值(oldValue) for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; // 沒有找到就添加一個key爲null的Entry addEntry(0, null, value, 0); return null; }addEntry方法(判斷是否需要擴容,然後在添加節點Entry)
執行流程:
(1) 判斷是否需要擴容,size(每次添加一個entry size++)>=threshold(閾值)並且當前這個key的hash算出的位置必須有元素才擴容,具體詳解看代碼註釋.
(2) 如果滿足擴容條件,調用擴容方法resize(2 * table.length),table長度擴大2倍,然後重新算當前key的hash和位置bucketIndex.
(3) 調用createEntry()方法,添加節點.// 添加節點到鏈表 void addEntry(int hash, K key, V value, int bucketIndex) { /* * 擴容機制必須滿足兩個條件 * (1) size大於等於了閾值 * (2) 到達閾值的這個值有沒有發生hash碰撞 * 所以閾值在默認情況下是12 是一個重要節點 * 擴容範圍是12-27 * 最小12進行擴容,最大27時必須進行擴容 * 分析最小12擴容 * 當size是12時,判斷有沒有hash碰撞,有擴容,沒有繼續不擴容. * 分析最大27擴容 * 當12沒有進行擴容時,size大於閾值就一直滿足了 * 就只需要判斷接下來的hash有沒碰撞,有就擴容,沒有就不擴容 * 最大是一種極端情況,前面11個全部在一個table索引上,接下來 * 15個全部沒有碰撞,11+15=26,table所有索引全部有值,在插入一個 * 值必須碰撞就是26+1=27最大進行擴容 * */ if ((size >= threshold) && (null != table[bucketIndex])) { // 擴容(方法裏面重點講) resize(2 * table.length); // 計算hash,null時爲0 hash = (null != key) ? hash(key) : 0; // 計算位置 bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }createEntry方法(在傳入位置加入一個節點)
// 創建一個新的Entry,放在鏈表的表頭,size++ void createEntry(int hash, K key, V value, int bucketIndex) { // 這裏可以理解爲當前的第一個節點 Entry<K,V> next = table[bucketIndex]; // 創建一個新的節點,next節點是當前的第一個節點,然後設置到bucketIndex位置 table[bucketIndex] = new Entry<>(hash, key, value, next); size++; }resize方法(擴容方法,擴容成原來的2倍)
執行流程:
(1) 計算oldTable的長度,如果oldTable的長度已經是最大值了,那麼就把閾值設置成Integer.MAX_VALUE,return.
(2) 根據新的容量創建table.
(3) 調用transfer方法轉移數據.
(4) 將新table賦值給舊table,重新就算閾值.void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; // 如果當前值已經是最大值了(2^30),就設置閾值爲Integer的最大值 if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } // 根據傳入Capacity重新創建新數組,擴容完成 Entry[] newTable = new Entry[newCapacity]; // 把原來的數據遷移到新的table(newTable) transfer(newTable, initHashSeedAsNeeded(newCapacity)); // 將table設爲新table(newTable) table = newTable; // 設置新的閾值 threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }transfer方法(負載轉移數據,把舊table的數據遷移到新table,至此擴容完成)
注意:擴容完成後鏈表的順序會反轉,如下圖解釋.![HashMap 源碼淺析 1.7]()
// 擴容之後遷移數據(重新計算hash,分配地址),很耗性能 // 順便提一下jdk7(get死循環)就是擴容時造成,造成環形鏈表 void transfer(Entry[] newTable, boolean rehash) { // 新數組的容量 int newCapacity = newTable.length; // 遍歷原table for (Entry<K,V> e : table) { // 輪詢e不等於null while(null != e) { // 保存下個元素 Entry<K,V> next = e.next; if (rehash) { // 計算出key的hash e.hash = null == e.key ? 0 : hash(e.key); } // 計算出table的位置 int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } }get方法(通過key獲取數據)
執行流程:
(1) 判斷key是否爲null,爲null調用getForNullKey()方法
(2) 不爲null,調用getEntry方法// get方法 public V get(Object key) { // key等於null if (key == null) return getForNullKey(); // 不爲null是查找 Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }getForNullKey()方法(遍歷table[0]位置數據,找到key==null的返回)
private V getForNullKey() { // 沒數據 if (size == 0) { return null; } // 從table[0]處遍歷鏈表,找到key=null的返回 for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }getEntry()方法(根據hash算出位置,遍歷當前位置的數據,找到key和hash相同的返回)
final Entry<K,V> getEntry(Object key) { // 沒數據 if (size == 0) { return null; } // 獲取hash int hash = (key == null) ? 0 : hash(key); // 獲取table的位置,找到hash和key相同的返回 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }remove()方法
final Entry<K,V> removeEntryForKey(Object key) { // 沒數據 if (size == 0) { return null; } // 獲取hash int hash = (key == null) ? 0 : hash(key); // 計算位置 int i = indexFor(hash, table.length); // 獲取i位置的entry Entry<K,V> prev = table[i]; Entry<K,V> e = prev; // 遍歷鏈表 while (e != null) { Entry<K,V> next = e.next; Object k; // 找到了hash和key相等的 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { modCount++; // 容量減減 size--; // 說明是第一個元素 // 把頭結點設置成他的下一個元素 if (prev == e) table[i] = next; // 刪除當前e,把上一個元素的next指向當前e.next // 1 -2 -3-null 刪除2,把1的next指向2的next,就是1-3-null else prev.next = next; e.recordRemoval(this); return e; } prev = e; e = next; } return e; } - 總結:
1.7HashMap需要注意的是在擴容時,不是到達閾值就會擴容的,還要判斷當前位置是否有值,來決定會否擴容,還有就是擴容的時候是遍歷了每個位置的鏈表,重新計算hash和位置,然後插入新的table,每條鏈的順序是和原來相反的,這樣如果數據量很大,其實很消耗性能.還有就是採用鏈表的數據結構來存儲數據,如果hash碰撞嚴重的話,這條鏈就會很長,這樣不管是get,或者put都需要遍歷鏈,這樣也遍歷也很慢,這是1.7HashMap個人覺得一些缺陷吧(因爲看了1.8 HashMap 源碼淺析).
PS 1.7的HashMap在多線程下擴容會導致環鏈,然後導致再次遍歷鏈表的時候回是死循環,進而cpu100%,所以多線程下就不要用HashMap.