




作者簡介
藍寅,開源分佈式中間件DBLE項目負責人;持續專注於數據庫方面的技術, 始終在一線從事開發;對數據複製,讀寫分離,分庫分表的有深入的理解與實踐。
3月14日,愛可生開源社區聯合IT168發佈了一期《MyCat的坑如何在分佈式中間件DBLE上改善》的直播,根據反饋,現將直播內容節選成文,以供大家回顧重溫。
Tips:考慮到大家的不同口味,開源社區官網上線了完整版錄播視頻,無論是喜歡文字,愛好圖文,青睞於完整版視頻的同學都能找到自己喜歡的打開方式!
直播視頻回顧請點擊“錄屏”,一鍵直達。
“ 以下爲分享內容的正文部分 ”
背景
近年來,隨着移動互聯網、物聯網、人工智能等技術的興起,需要處理的數據越來越多,作爲存儲架構核心的關係型數據庫不可避免的引發了需要擴容的問題,在這個過程中分庫分表被髮明出來。
分庫分表最初不需要中間件,由各自應用的開發人員自己來負責,應用除了要了解業務邏輯以外,還需要明確完整的拆分規則,成本較高,對開發人員要求也很高,並且不利於任務和邏輯的解耦。因此,中間件應運而生。
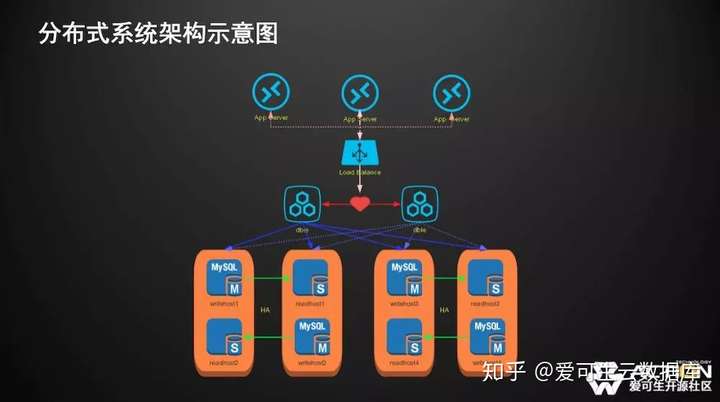
分佈式系統架構基本分成三層,最上面是一層是APP層,中間是中間件層,下面是數據存儲層。
今天分享的內容主要爲中間件,那麼一個理想的中間件應該是什麼樣的?
第一,透明性,理想的中間件會嚮應用開發人員屏蔽後面具體拆分的細節。數據存儲的工作被獨立出來,應用開發人員可以更關注業務邏輯而不是存儲方式。
第二,兼容性,理想的中間件最好是不要自定義一套規則,而是去兼容當前大家熟悉的規則,對我們來說,這個熟悉的規則就是MySQL。所以中間件的語法也好,協議也好,對於使用者來說,最好的是用戶使用時就像使用原生MySQL一樣,而不是需要花很長時間學習一套新的規則,否則無論是學習成本或者遷移成本都很高。
兼容性還有一個好處,現有的JDBC或者是其他的一些驅動都可以用,不需要再去定製開發一個驅動。
第三,性能,一般對性能的考量是延遲和吞吐量。因爲中間件多了一層,單個查詢的response會多一個RTT延遲,所以延遲方面不一定有優勢。主要看吞吐量是不是變得比原來更強。
第四,安全,不能因爲有了中間件而將原來完好的密碼管理規則變成名存實亡的存在,這種做法也是不妥的。
最後,運維性,比如與中間件配套的備份擴容工具等,這方面組件也是很重要的。

開源社區裏MyCat的是比較著名的。我們深度研究了MyCat,加上我們在分佈式中間件上既有的一些經驗,結合起來,就是形成了我們新的開源分佈式中間件DBLE。DBLE的結構大致如圖,內部主要有協議,解析,路由和運算模塊。
那麼DBLE跟MyCat相比解決了哪些問題?以下將從DBA與研發兩個方面介紹:
1.DBA的角度,站在DBA的角度,如何實現他們並不是太關心,對能用,好用十分關注,即:正確性,安全性,穩定性,可運維性等。本次分享主要關注於正確性,因爲這是最大的坑,其他方面鑑於時長有限,不在這次分享中詳細講述了。
2.開發測試的角度,從開發測試的角度來看最關注的是代碼質量,是否可維護,代碼管理是否科學,能否持續報紙質量,保證項目健康發展。
首先我們從DBA角度分享一下在MyCat上踩的坑,當然,這些坑DBLE都填了,具體的實現方式歡迎大家關注我們正在陸續釋放的公開課,會有更多的內容揭祕。
一.DBA角度看中間件
我們主要從兩方面來討論,一部分是SQL語言實現:包括select,insert,set等語句來說明正確性的問題,另一部分將舉個運維管理的例子來說明安全性的問題。
1. SQL語言實現
以下案例都採用最新版的MyCat 1.6.7舉例,在此之前分享過的一些MyCat的bug和坑,此次查看已經修了一部分,不過坑還是太多。
1.1數據查詢
簡單查詢對比案例
從拆分規則來看,最常用的hash拆分,用ID值對1024求模,求出的結果0~1023按照每256個數拆分,拆成4份,0~255在結點1;256~511在結點2,以此類推。我們準備用10條數據,覆蓋到各個分片上,都通過中間件寫入。

準備完成之後,用查詢語句案例select * from employee where id between 511 and 1791 order by id,加order by主要是爲了更容易看出問題。
如圖所示,在查詢結果中MyCat丟了三條數據,原因是因爲計算路由錯誤。像這樣大範圍查詢的SQL應該下發給所有後端結點,而實際上MyCat下發的少了。
聚合函數查詢案例

聚合函數查詢案例的準備數據與簡單查詢類似,在此不贅述了,我們計算出ID的方差,可以看到MyCat返回的是四個數,並且這4個數無論如何也不可能捏回標準差,而DBLE的結果是正確的。當然,有同學驗證的話會發現有細微的精度誤差,這是因爲二進制存儲會損失一些精度,分佈式的算法又會損失一些精度,因此會有精度上的誤差。
數據查詢-函數嵌套查詢案例

繼續舉例,準備數據不變,SQL變成了複雜一點的表達式,對count的結果取絕對值。可以看到MyCat是支持count的,但是前面去嵌套了一個其他的函數,MyCat就不認識了,它把整個語句下發給各個節點,然後對各個節點做了簡單合併,這個合並沒有加起來,只是簡單的堆積在一起,然後回到了應用;而DBLE結果正確無誤。
數據查詢 - union 查詢案例

union查詢案例的結果,數據準備如圖是簡單的兩張表,一張表hotnews分爲四個節點,規則也很簡單,就是對四求模,按照求模的結果拆分到了四個節點上。另一張表travelrecord稍微複雜一點,是兩個節點,它的規則是按1024次求模,然後0到511分到第一個節點,512到1023分到第二個節點。第一張表是四行數據,第二張表是五行數據。這個例子已經能說明問題了,現實生活中情況可能更復雜一些。
查詢:select id from hotnews union select id from travelrecord 語句,即用ID做一個union,如圖所示,MyCat的結果並沒有去重,把所有的結果都拿到了。對比之下DBLE的結果則是正確的。
數據查詢 - union all 查詢案例

在union all的查詢案例中,MyCat的查詢結果還是和union一樣。因爲MyCat在union查詢時是將union語句整體下發到各個節點上,而在計算時則是按照hotnews這張表來計算節點,由於MyCat只把查詢下發給兩個節點,拿到的結果其實是不全的。
數據查詢 - 子查詢

子查詢對比結果有三個,MyCat會直接hang住。看代碼hang住的原因是MyCat內部死鎖。中間件在做子查詢任務時,其實是拿到子查詢結果以後再拼出新的SQL來,然後再下發第二句SQL。
在這個過程中,MyCat 固定大小的線程池被佔滿了,造成了死鎖,而DBLE結果還是正確的。
數據查詢 - Join案例

重點討論一下Join,MyCat解決跨表Join的方式有3種:配置global表,配置ER表,使用hint,下面一一剖析,看看是否是真的能解決所有問題。
數據查詢 - Join案例 剖析global表

對於數據量不大的字典表可以採用global表。舉例,超市的幾十萬商品表,銷售詳單非常多,拆表時往往選擇拆數據最多的銷售詳單表,假設按照日期,將銷售詳單拆分,按天將詳單表拆成N片,在每一片的schema中有一個全量的商品表,即全局表。
當進行銷售詳單和商品表的Join查詢的時,之所以用Join,是因爲詳單裏面只有ID沒有商品名稱,進行Join查詢時才能拿到名稱,Join查詢時Join語句下發到各個節點,而各個節點上的全局表都是全量數據,因此Join可以拿到正確的數據,這就是全局表的作用。

舉一個具體例子,將商品表和銷售詳單表通過商品ID來關聯,在一定時間範圍內,根據group by日期和商品名,查看訂單量。
這樣一句Join,因爲group by中包含了拆分列,所以這條語句可以下推給所有節點,這些節點得到的結果,直接簡單的進行合併,返回到客戶端就是正確的數據,這是global表的正確用法。
global表能不能解決所有的問題呢?答案是不行。

舉例說明,在這個case中,在query裏,首先group by並不是按照拆分列去分組,其次select row裏面有count distinct的過程,這句SQL,如果下發到各個節點,會發生什麼樣的情況?

如圖,第一個分片上得到的日用品和文具是一和二,第二個節點上得到的也是。
但如果把左邊的圖不看成拆分表,大家應該對distinct都非常熟悉,可以自己試着用group by做一下,結論應該會是日用品一文具三,通過兩個節點得到的結果分別是一和二,無論怎麼合併,也無法合出第三個這樣的結果。
所以這就是global表解決不了的問題,當碰到這樣的查詢時global表就無法解決,因此它不能解決所有問題。
數據查詢 - Join案例 剖析ER表

ER表可以簡單地理解爲兩張表有邏輯外鍵關係,按照這列來拆分,幾張表都可以按照同樣一個規則拆分。涉及到了關聯列的Join,也可以同樣下發到各個節點上。
注意,外鍵列需要依賴於拆分列,不能有拆分列和外鍵列是1比N的關係。

再舉例,按照銷售單的日期拆分,流水號和日期有一一對應關係,不會出現一個流水號有兩個日期。根據流水號去拆分另一張表,拆分完之後,如果這兩張表通過流水號關聯做Join,可以直接到下發到各個節點。

ER表是萬能的嗎?
假如不是所有表的關聯關係都是同一列,當關聯關係比較複雜,A表和B表是通過關聯列COLUMN1來關聯,B表和C表是通過COLUMN2來關聯,會發現無論用哪種方式去做拆分,都無法得到一個完美的拆分方案,一定會有一張表被打散。
打散之後再做Join,就又回到了跨節點Join的問題。
跨節點Join的問題,把語句直接分發到各個節點是不正確的。
因此,ER表也不能解決所有問題。
數據查詢 - Join案例 剖析Hint

MyCat解決跨表Join的第三個方法:註解。
舉例說明,A表和B表在做Join的時候,前面加了一部分hint,在裏面寫好用哪個類來處理。
這其實就是next loopJoin的方式。如果通過MySQL的general log,或是根據debug去調試,就會發現這句Join在MyCat解析以後是分成兩句下發的。
先從第一張表中select出結果集,再按照關聯關係把結果集放在第二個表中拼接成新語句,然後再下發第二句SQL,MyCat實際是這樣一個過程。
MyCat這種操作方式存在什麼問題?
第一,解決不了多於兩個表Join的問題。
第二,無法解決複雜Join語句的問題,只能解決A.id等於B.id這兩個表格列關係直接相等的情況,稍微改變形式就不行。
第三,侵入性。應用的開發需要在每個Join下的每個查詢前拼接這樣一個hint,並且需要改應用,侵入性比較強。
所以hint表也解決不了所有的問題。
有趣的是MyCat 1.6.5之後,將hint方式直接固化到代碼裏,這樣的處理方式實在不像是工程級別的代碼,反而會引入更多的問題。

舉例說明: 這個Join內部其實偷偷在代碼中加了hint,如果是MyCat 1.6.1版本,直接結果不爭取,加了hint以後有部分改善。根據測試, MyCat的反饋結果並不穩定,有時會返回NP異常並且這個NP異常會影響當前session的正確性。

將SQL語句調整爲查詢:select a.id,a.description,b.title from travelrecord a inner join hotnews b on a.id =b.id;,B.id變成B.id+1,這句SQL,就無法返回正確結果了。受到前一個例子的影響,MyCat的查詢結果非常不穩定,即使使用新的連接,也會只返回空集,因爲MyCat本身只是把hint固化到代碼裏,並沒有良好的跨表Join的實現。
Tips:
MyCat的內部實現十分粗糙,它判斷是否要自己加hint採用的依據是拆分關的規則不一樣。但是是否能做成ER關係有2個條件,是拆分規則以及分片結點的完全一致。
如果拆分規則相同,結點或結點順序不同,返回來也是空集,此處就不舉例說明了,感興趣的同學可自行嘗試驗證。
1.2 數據操作

在Insert的處理上MyCat的insert必須將列名完全寫清楚,否則會報列名沒有提供。而DBLE則更良好的兼容了MySQL的語法。

MyCat某些時候會報告不正確的返回,比如insert拼寫錯誤,它報錯不會是語法錯誤,而是默默通過SQL語句,如果不仔細看行的影響數甚至都無法發現拼寫錯誤。

MyCat的全局序列自定義了一個語法,必須是nextvalue for sth纔可以插入。
這個語法,對應用的業務開發者而言侵入性是非常強的,需要對應用做很多無法兼容的改造。

同樣是全局序列,DBLE的實現則比較優雅,支持不帶自增列的插入,由中間件來生成自增列數據。
1.3 DBLE與MyCat的上下文變量

除了select和insert,以下將再列舉部分系統變量的例子。
如圖,表格中原來包含4條數據,現插入一行數據,然後將session的狀態設置爲只讀,顯示再繼續增加一條數據也可以通過。
雖然能夠通過select篩選出來,但實際上MyCat對於set read only並不支持並且沒有任何報錯。如果事先並沒有瞭解MyCat這個功能缺陷或進行測試,這個問題是很難被發現的。

同樣的案例,在DBLE中設置爲只讀後,再插入數據DBLE將會報錯,如此才真正符合設置session級別變量的含義。
MyCat爲什麼會出現這種情況?

再舉一個有趣的例子,如圖MyCat對於 set you =me,set 1=2 也返回OK,似乎無所不能。 而DBLE則會誠實的告訴你,這個變量不支持。
在使用過程中,如果存在不小心寫錯的情況DBLE會提供明確的報錯,而MyCat什麼set都返回ok的問題根因後面將詳述。
2.運維管理-用戶權限

以管理端用戶權限爲例,任何數據庫用戶都可登錄MyCat管理端進行高級操作,如:服務下線,修改配置等。因爲缺乏對用戶的分級,導致應用開發者本應只能進行查詢或DML等基本權限,但卻也可以進行服務下線類似的不安全操作,究其根源是項目開發者沒有從權限管理的角度思考問題,也埋下了安全隱患。

在DBLE中,我們將此問題進行改進,對不同用戶進行劃分,普通用戶不能直接登錄管理端口進行操作,如圖所示,普通用戶嘗試管理端口會遭到拒絕,更有利於安全。
以上的諸多案例都是站在DBA的角度來驗證MyCat的正確性及其存在的問題,作爲MyCat的增強版,DBLE更多的以使用者的視角對一款中間件應當具備的正確性,安全性,穩定性,可運維性等方面進行了深度系統性的考量並持續完善相應功能特性,同時,我們也吸取經驗對MyCat既存的問題也進行了增強與改進。
二.開發者角度
下面將從開發者的角度來分析MyCat的代碼質量,讓大家對於這個開源項目有更充分的認識。
概括而言,MyCat存在以下四個問題:
- 代碼修復質量差
- 代碼半成品殘留
- 部分提交者有灌水嫌疑
- 僞造實現
1.bug修復質量

首先,bug修復質量。MyCat bug #1194:在舊內存管理模式下,查詢兩個avg,會報超索引超出界限異常。
上圖爲MyCat bug #1194在GitHub上的截圖,bug提供者發現bug和重現bug,包括描述bug的邏輯都非常正確,實際上在for循環裏刪除了數據元素,然後導致下一個去處理的時候報錯越界。

在修復上,如圖,紅色部分爲刪除的代碼,綠色部分爲對應增加的代碼,仔細觀察可發現中間部分被註釋起來,沒有實際作用,最關鍵的部分在最下方,仍然是在for循環中remove某一個索引的值。
爲什麼這個修復結果卻是修復成功?
細敲其邏輯,實際上是不正確的。原因在於for循環裏採用的是int類型的包裝類,此時從數組中remove的不是某個索引的值,而是remove這個包裝類對象,數組中根本不存在這個對象,因此實際上沒有remove任何內容,而真正生效的是標記×××的部分,將它的size減了一。
這種操作歪打正着,比如原有四個數組,正常情況下是將第三和第四數組remove掉,但現在沒有remove成功,然後通過size 4-1-1結果變成了2。這時再去遍歷此數組是通過field count來遍歷的,序號爲第三和第四的數組儘管沒有刪掉,但效果卻和已經刪掉的相同了。
bug #1194的修復如果只進行測試會發現這個問題已經完美的解決了,但是作爲開發者,我們對代碼質量進行管理時會發現這樣代碼的存在十分奇怪,不但難以讀懂難以理解並且很可能存在:爲了性能放棄包裝類改成Java的基本類型、int類型,bug就會被reopen。
2.代碼半成品殘留

上圖爲MyCat啓動類的部分代碼截圖,從圖中可瞭解這是一個switch case語句,case=0和case等於1。其中case 0初始化了一個buffer pool,然後初始化了total buffer size,做了這兩件事情;而case 1除了大段註釋外,只初始化了total buffer size,並沒有初始化buffer pool。這會發生什麼情況呢?

當pufferpooltype設置爲1時,會發現MyCat啓動以後,客戶端根本連不上,然後日誌裏面也全是NP異常。作爲著名開源軟件,在它的啓動類上就存在這樣的殘留代碼,我們能夠相信它的質量嗎?
我們相信MyCat當初設計時應該也設計了不同的實現,但沒完成,這至少說明了沒有一個固定的開發團隊就沒有人去處理類似很容易被發現的問題。
3.代碼灌水

我們在對MyCat做測試的時候,發現有部分代碼覆蓋率很低,於是去查看這部分代碼實現了哪些功能。結果發現:代碼質量非常高,但整個package都是從其他著名開源項目的某個版本copy過來的,當然也不算完全copy,還是有加部分註釋的。
這部分代碼除了被貢獻者自己的單元測試使用外,沒有被任何其他人使用。即使把整個package連帶測試完全刪掉,也不影響軟件的任何功能。
可能這位貢獻者把MyCat項目當作自己學習筆記的筆記本或是能夠展示自己貢獻了很多代碼?具體原因不得而知,不過這樣的代碼貢獻也能被合併到項目裏來,實在匪夷所思。
4.僞造實現

前面我們列舉了一個較爲誇張的例子,寫set you = me也顯示成功執行。
set語句爲什麼會出現這種情況?從源碼角度來看,MyCat枚舉了幾個特殊處理,比如 set names= utf8確實進行了處理。但除了枚舉的幾個特殊的例子,其他無論set什麼,MyCat都直接返回OK,因此你會看到前面set you=me也會得到OK的結果,這對於應用端而言是相當不負責任的。
尤其是遇到真的有意義的set語句,但卻沒有實現其語義,很容易造成開發事故。
DBLE的自動化工具的引入

最後分享一下DBLE是如何進行代碼管理和保證質量的,除了正常的review機制外,我們引入了很多自動化的工具,包括靜態代碼的分析工具,用於做代碼規範的工具,可持續集成工具等。社區的travis CI會自動跑單元測試,如果代碼變更發生錯誤,那麼工具就會報錯,這樣也可以提高代碼質量。
內外部使用的工具有稍許不同,我們內部用的可持續集成工具是go cd,自動化的測試方面我們用behave做了一些行爲的比較測試,之後可能也會開源出來。還有測試代碼覆蓋率的工具,幫助我們發現測試的薄弱環節等等。
“正文完”
以上分享對一款中間件的正確性進行了詳盡充分的解讀,而“安全性、穩定性、可運維性”以及如何評估開源中間件的代碼質量、代碼管理等都將在"DBLE系列公開課"一一爲大家拆分揭祕。
自3月15日起每週更新一節發佈在「愛可生開源社區官網」,點擊官網(http://opensource.actionsky.com)博客專欄,即可查看“DBLE系列公開課”。
直播視頻回顧請點擊“錄屏”,一鍵直達。
開源分佈式中間件DBLE
社區官網:https://opensource.actionsky.com/
GitHub主頁:https://github.com/actiontech/dble
技術交流羣:669663113
開源數據傳輸中間件DTLE
社區官網:https://opensource.actionsky.com/
GitHub主頁:https://github.com/actiontech/dtle
技術交流羣:852990221
