




#(1)安裝node exporter
node exporter 作用: 是收集操作系統的基本系統, 例如cpu, 內存, 硬盤空間等基本信息, 並對外提供api接口用於prometheus查詢存儲;
1)docker方式運行node exporter
docker run -d --name node-exporter -p 9100:9100 -v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" --restart=always --net="host" prom/node-exporter \
--path.procfs /host/proc \
--path.sysfs /host/sys \
--collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)" 2)驗證, 可以通過對外暴露的api接口獲取數據
curl http://192.168.1.42:9100/metrics
#(2)安裝consul
consul作用: 服務註冊中心,向外提供服務的增刪api接口, prometheus可以向consul動態獲取節點信息以及自動加載配置
1)docker安裝consul
docker run --restart=always --name consul -d -p 8500:8500 consul2)向consul的api接口添加服務
curl -X PUT -d '{"id": "node03","name": "node03","address": "192.168.1.42","port": 9100,"tags": ["test"],"checks": [{"http": "http://192.168.1.42:9100/","interval": "5s"}]}' http://localhost:8500/v1/agent/service/register
擴展: 刪除服務節點
curl -X PUT http://localhost:8500/v1/agent/service/deregister/node023)服務註冊成功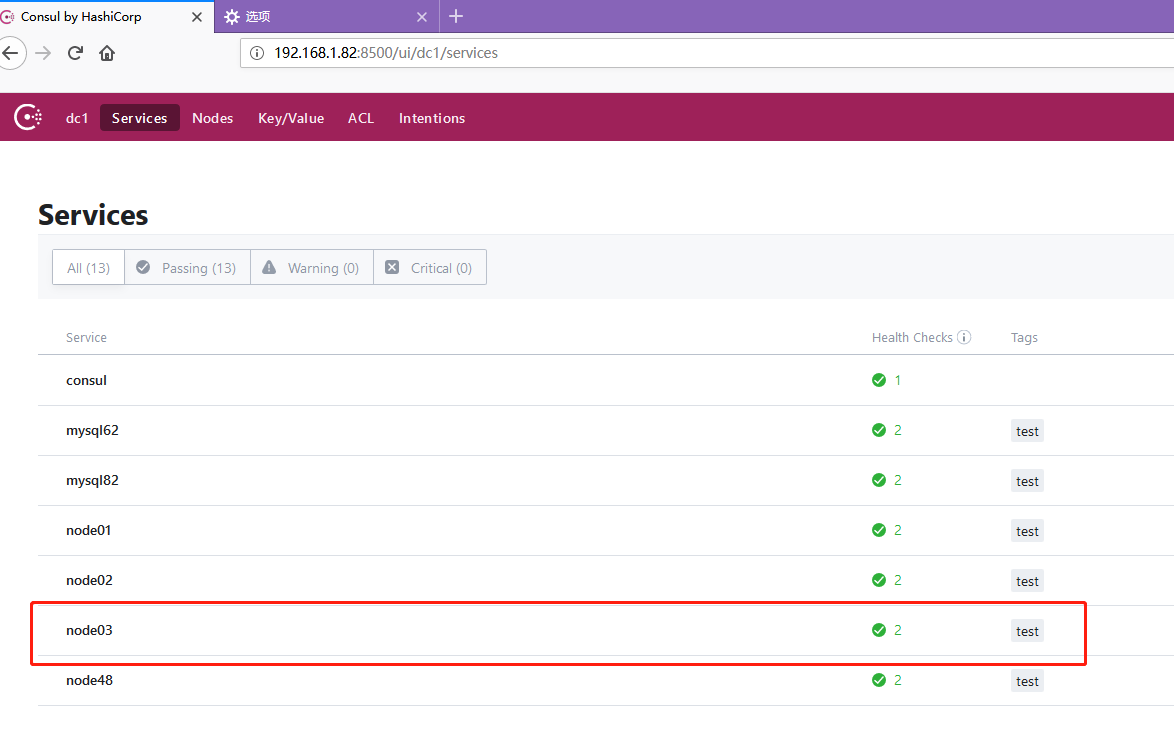
#(3)安裝和配置altermanger
altermanager作用: 接收prometheus發送的告警信息, 通過相關方式例如郵件和微信等方式發送給接收者;
0)準備目錄
test -d /etc/alertmanager || mkdir -pv /etc/alertmanager1)準備配置文件
# cat /etc/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
templates:
- '/etc/alertmanager/wechat.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'wwc08fcb42fc6fe93c'
to_party: '2'
agent_id: '1000002'
api_secret: 'cLG91Xgcd3o3zPJp6NbOJV9m7SBIlhtCScxov3Hp-XQ'
send_resolved: true2)準備模板文件
# cat /etc/alertmanager/wechat.tmpl
{{ define "wechat.default.message" }}
{{ range .Alerts }}
========start==========
告警程序:prometheus_alert
告警級別:{{ .Labels.severity }}
告警類型:{{ .Labels.alertname }}
故障主機: {{ .Labels.instance }}
告警主題: {{ .Annotations.summary }}
告警詳情: {{ .Annotations.description }}
觸發時間: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
========end==========
{{ end }}
{{ end }}3)啓動容器
docker run --restart=always -d -p 9093:9093 -v /etc/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /etc/alertmanager/wechat.tmpl:/etc/alertmanager/wechat.tmpl --name alertmanager prom/alertmanager4)驗證容器是否有報錯
docker logs -f alertmanager
#(4)安裝和配置prometheus
prometheus作用: 用於向exporter獲取數據並保存數據, 同時可以設置規則和觸發器, 向報警器發送信息;
1)準備目錄
test -d /etc/prometheus || mkdir /etc/prometheus -pv2)準備prometheus配置文件
rule_files : 報警規則文件
alerting: 當觸發報警, 把報警相關發送給altermanager, 由altermanager接收告警信息在發送給接收人;
job_name: consul : prometheus 向consul註冊;
# cat /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
- "/etc/prometheus/*.rules"
alerting:
alertmanagers:
- static_configs:
- targets:
- "192.168.1.82:9093"
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: 'consul'
consul_sd_configs:
- server: '192.168.1.82:8500'
services: []
relabel_configs:
- source_labels: [__meta_consul_tags]
regex: .*test.*
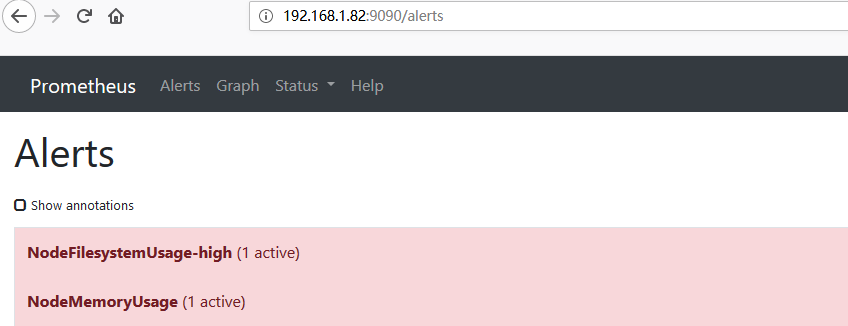
action: keep3)準備告警規則文件 , 注意該文件不能有tag鍵, 同時key和value之間必須要有空格
# cat /etc/prometheus/prometheus.rules
groups:
- name: alert-rule
rules:
- alert: NodeFilesystemUsage-high
expr: (1- (node_filesystem_free_bytes{fstype=~"ext3|ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext3|ext4|xfs"}) ) * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: High Node Filesystem usage detected"
description: "{{$labels.instance}}: Node Filesystem usage is above 80% ,(current value is: {{ $value }})"
- alert: NodeMemoryUsage
expr: (100 - (((node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes)/node_memory_MemTotal_bytes) * 100)) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: High Node Memory usage detected"
description: "{{$labels.instance}}: Node Memory usage is above 80% ,(current value is: {{ $value }})"
- alert: NodeCPUUsage
expr: (100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: Node High CPU usage detected"
description: "{{$labels.instance}}: Node CPU usage is above 80% ,(current value is: {{ $value }})"4)docker方式啓動prometheus
docker run --restart=always --name prometheus -d -p 9090:9090 -v /etc/prometheus:/etc/prometheus prom/prometheus 5)登錄到prometheus驗證
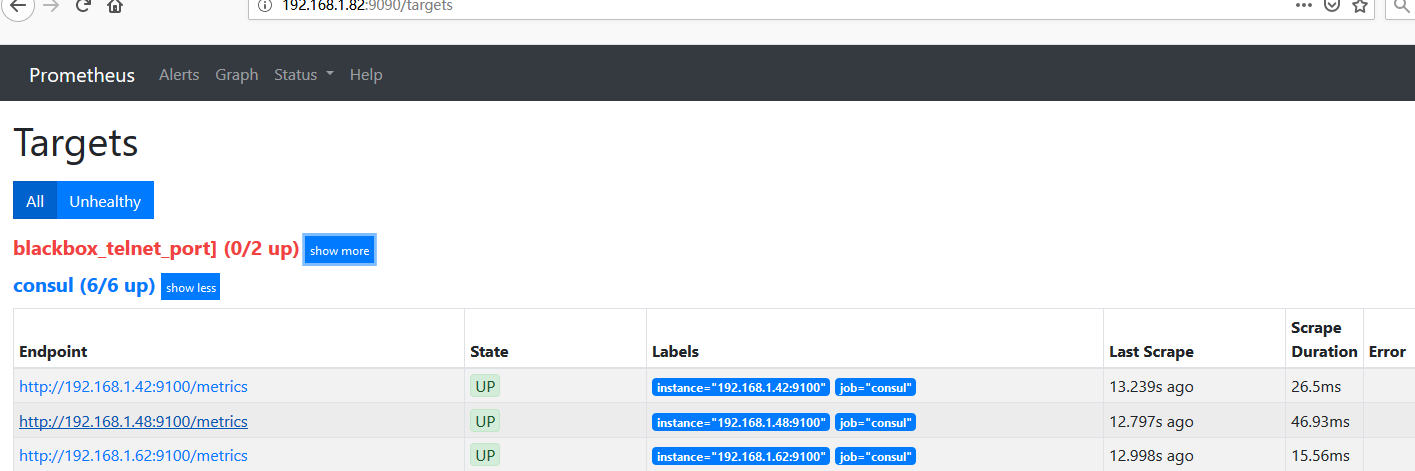
rule這裏能看到相關規則
#(4)下載安裝和配置grafana
1)下載和啓動grafana
wget https://dl.grafana.com/oss/release/grafana-6.0.2-1.x86_64.rpm
yum install grafana-6.0.2-1.x86_64.rpm -y
systemctl start grafana-server
systemctl enable grafana-server
ss -anltup |grep 3000 2)添加圖形
https://grafana.com/dashboards 頁面搜索node exporter 根據id導入模板 id 爲8919
3)查看圖形
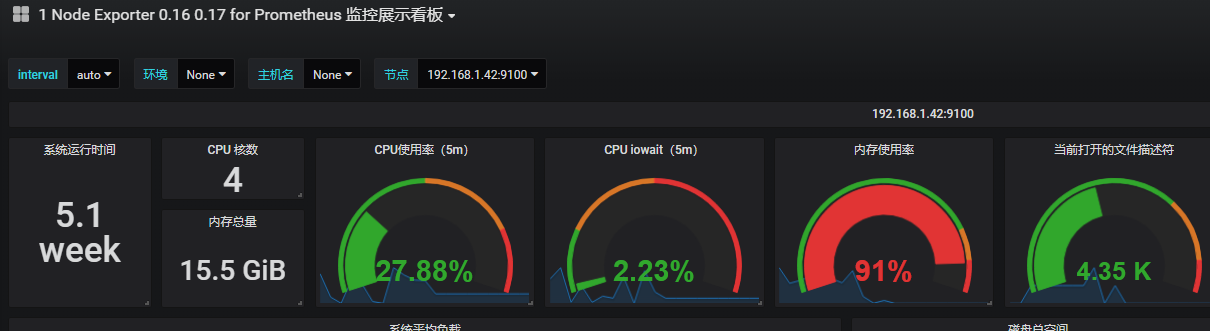
9)安裝餅圖插件
grafana-cli plugins install grafana-piechart-panel
systemctl restart grafana-server