




Elasticsearch與Postgresql數據檢索性能對比與融合
一般來說,影響數據庫最大的性能問題有兩個,一個是對數據庫的讀寫操作,一個是數據庫中的數據太大導致操作慢,對於前者我們可以適當藉助緩存來減少一部分讀操作,而針對一些複雜的報表分析和搜索可以交給hadoop和elasticsearch,對於寫併發大,讀也併發大,我們可以考慮分庫分表,主從讀寫分離或者兩者結合等方式來提高併發性和時效性,例如PG大併發寫,大數據查看可以用elasticsearch與PG數據同步來讀,可以啓到很好的效果。
ElasticSearch做爲搜索服務器,在性能上確實優勢突出,是當前流行的企業級搜索引擎。它提供了一個分佈式多用戶能力的全文搜索引擎,基於RESTful web接口。主要用於實時搜索和分析引擎,,支持對結構化數據和非結構數據處理檢索。
例如,我們使用的數據庫時Postgres數據庫,主從配置,從庫主要用於數據分析檢索爲主,如果使用postgres進行多表多維度全量方式檢索分析用戶行爲等挖掘有價值的數據,這樣性能上無法及時滿足客戶時時性要求,因此我們可以使用Elasticsearch數據庫代替PG從庫做爲挖掘分析數據庫,使用過程中發現兩者表與數據的兼容性都還不錯,而且展現數據的性能確實快,
如下圖是同一張表數據在postgres數據庫中對應的表,在Elasticsearch數據庫中對應,說明數據是兼容的。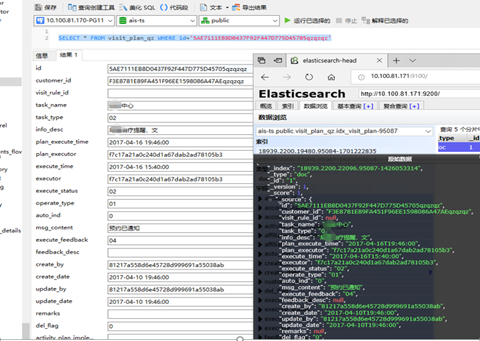
而在postgres數據庫中針對visit_plan_qz 表3073920筆數據進行全量查詢,耗時大於5分鐘都無法正常展現出來,
如果使用Elasticsearch進程全量查詢僅使用0.0005秒就可以展現出數據,當然Elasticsearch會自動對該表劃分爲5個分片來展現數據。

工作原理:
PG關係數據庫 ⇒ 數據庫 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 類型(type) ⇒ 文檔(Docments) ⇒ 字段(Fields)
可以看出Elasticsearch性能上的優勢在索引,它提供強大的索引能力,Elasticsearch 是通過 Lucene 的倒排索引技術實現比關係型數據庫更快的過濾
Elasticsearch的索引思路:將磁盤裏的東西儘量搬進內存,減少磁盤隨機讀取次數(同時也利用磁盤順序讀特性),結合各種算法,用及其苛刻的態度使用內存。