




最近看到的另外一個介紹Twitter技術的視頻[Slides] [Video (GFWed)],這是Twitter的John Adams在Velocity 2009的一個演講,主要介紹了Twitter在系統運維方面一些經驗。 本文大部分整理的觀點都在Twitter(@xmpp)上發過,這裏全部整理出來並補充完整。
Twitter沒有自己的硬件,都是由NTTA來提供,同時NTTA負責硬件相關的網絡、帶寬、負載均衡等業務,Twitter operations team只關注核心的業務,包括Performance,Availability,Capacity Planning容量規劃,配置管理等,這個可能跟國內一般的互聯網公司有所區別。
1. 運維經驗
* Metrics
Twitter的監控後臺幾乎都是圖表(critical metrics),類似駕駛室的轉速錶,時速表,讓操作者可以迅速的瞭解系統當前的運作狀態。聯想到我們做的類似監控後臺,數據很多,但往往還需要瀏覽者做二次分析判斷,像這樣滿屏都是圖表的方法做得還不夠,可以學習下這方面經驗。 據John介紹可以從圖表上看到系統的瓶頸-系統最弱的環節(web, mq, cache, db?)
根據圖表可以科學的制定系統容量規劃,而不是事後救火。
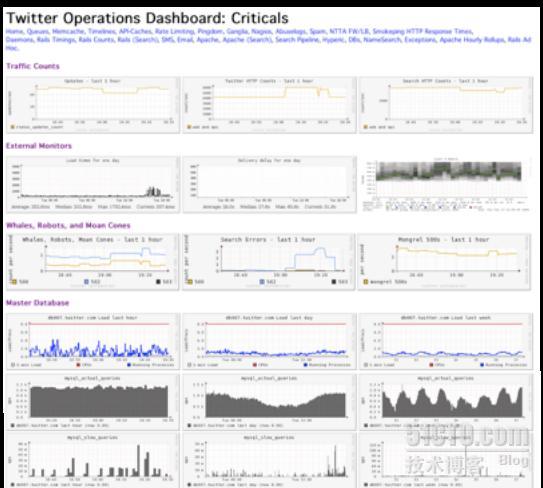
* 配置管理
每個系統都需要一個自動配置管理系統,越早越好,這條一整理髮到Twitter上去之後引起很多回應。
* Darkmode
配置界面可以enable/disable 高計算消耗或高I/O的功能,也相當於優雅降級,系統壓力過大時取消一些非核心但消耗資源大的功能。
* 進程管理
Twitter做了一個”Seppaku” patch, 就是將Daemon在完成了n個requests之後主動kill掉,以保持健康的low memory狀態,這種做法據瞭解國內也有不少公司是這樣做。
* 硬件
Twitter將CPU由AMD換成Xeon之後,獲得30%性能提升,將CPU由雙核/4核換成8核之後,減少了40%的CPU, 不過John也說,這種升級不適合自己購買硬件的公司。
2. 代碼協同經驗
* Review制度
Twitter有上百個模塊,如果沒有一個好的制度,容易引起代碼修改衝突,並把問題帶給最終用戶。所以Twitter有一強制的source code review制度, 如果提交的代碼的svn comment沒有”reviewed by xxx”, 則pre-commit腳本會讓提交失敗, review過的代碼提交後會通過自動配置管理系統應用到上百臺服務器上。 有@xiaomics同學在Twitter上馬上就問,時間成本能否接受?如果有緊急功能怎麼辦?個人認爲緊急修改時有兩人在場,一人修改一人review也不是什麼難事。
* 部署管理
從部署圖表可以看到每個發佈版本的CPU及latency變化,如果某個新版本latency圖表有明顯的向上跳躍,則說明該發佈版本存在問題。另外在監控首頁列出各個模塊最後deploy版本的時間,可以清楚的看到代碼庫的現狀。
* 團隊溝通
Campfire來協同工作,campfire有點像羣,但是更適合協同工作。對於Campfire就不做更多介紹,可參考Campfire官方說明。
3. cache
- Memcache key hash, 使用FNV hash 代替 MD5 hash,因爲FNV更快。
- 開發了Cache Money plugin(Ruby), 給應用程序提供read-through, write-through cache, 就像一個db訪問的鉤子,當讀寫數據庫的時候會自動更新cache, 避免了繁瑣的cache更新代碼。
- “Evictions make the cache unreliable for important configuration data”,Twitter使用memcache的一條經驗是,不同類型的數據需放在不同的mc,避免eviction,跟作者前文Memcached數據被踢(evictions>0)現象分析中的一些經驗一致。
- Memcached SEGVs, Memcached崩潰(cold cache problem)據稱會給這種高度依賴Cache的Web 2.0系統帶來災難,不知道Twitter具體怎麼解決。
- 在Web層Twitter使用了Varnish作爲反向代理,並對其評價較高。