




服務器的衡量標準:
計算機系統的可用性(availability)是通過系統的可靠性(reliability)和可維護性(maintainability)來度量的。工程上通常用平均無故障時間(MTTF)來度量系統的可靠性,用平均維修時間(MTTR)來度量系統的可維護性。於是可用性被定義爲:MTTF/(MTTF+MTTR)*100%
99.9% 一年宕機時間不超過10h
99.999% 一年宕機時間不超過6min
如何提高服務器的可用性呢,這就需要使用HA(high availability)集羣,一般是由多個節點的來組成。
99.9% 一年宕機時間不超過10h
99.999% 一年宕機時間不超過6min
如何提高服務器的可用性呢,這就需要使用HA(high availability)集羣,一般是由多個節點的來組成。
HA集羣是集羣中較爲常見的一種,當硬件和軟件系統發生故障的時候,運行在集羣系統中的數據不易丟失,而且能在儘可能短的時間裏恢復正常運行。
雙機熱備是HA集羣中常見的一種解決方案,雙機熱備按照工作方式不同可以分爲一下幾種:
1.主-備(active-standby)主 - 備方式即指的是一臺服務器處於某種業務的激活狀態,另一臺服務器處於該業務的備用狀態;
2.主-主(active-active)雙主機方式即指兩種不同業務分別在兩臺服務器上互爲主備狀態;
1.主-備(active-standby)主 - 備方式即指的是一臺服務器處於某種業務的激活狀態,另一臺服務器處於該業務的備用狀態;
2.主-主(active-active)雙主機方式即指兩種不同業務分別在兩臺服務器上互爲主備狀態;
主服務器&&備用服務器
主服務器和備用服務器是建立雙機熱備的基本條件。兩個系統上的數據庫服務器共享同一個數據庫文件。通常情況下,數據庫文件掛靠在主數據庫服務器上,用戶連接到主服務器上進行數據庫操作。當主服務器出現故障時,備用服務器會自動連接數據庫文件,並接替主系統的工作。用戶在未告知的情況下,通過備用數據庫連接到數據庫文件進行操作。等主服務器的故障修復之後,又可以重新加入集羣;
主服務器和備用服務器是建立雙機熱備的基本條件。兩個系統上的數據庫服務器共享同一個數據庫文件。通常情況下,數據庫文件掛靠在主數據庫服務器上,用戶連接到主服務器上進行數據庫操作。當主服務器出現故障時,備用服務器會自動連接數據庫文件,並接替主系統的工作。用戶在未告知的情況下,通過備用數據庫連接到數據庫文件進行操作。等主服務器的故障修復之後,又可以重新加入集羣;
說到這裏,那麼備用服務器是如何知道主服務器掛掉了呢,這就要使用一定的機制,如心跳檢測,也就是說每一個節點都會定期向其他節點通知自己的心跳信息,尤其主服務器,如果備用服務器在3~5個心跳週期還沒有檢測到的話,就認爲主服務器宕掉了,而這期間在通告心跳信息當然不能使用tcp的,如果使用tcp檢測,還要經過三次握手,等手握完了,不定經過幾個心跳週期了,所以在檢測心跳信息的時候採用的是udp的端口號694進行傳遞信息的
如果主服務器在某一端時間由於服務繁忙,沒時間響應心跳信息,如果這個時候備用服務器要是一下子把服務資源搶過去,但是這個時候主服務器還沒有宕掉,這樣就會導致資源搶佔,就這樣用戶在主輔上都能訪問,如果僅僅是讀操作還沒事,要是有寫的操作,那就會導致文件系統崩潰,這樣一切都玩了,所以在資源搶佔的時候,可以採用一定的隔離方法,來實現,就是備用服務器搶佔資源的時候,直接把主服務器給“一腳踹死”;
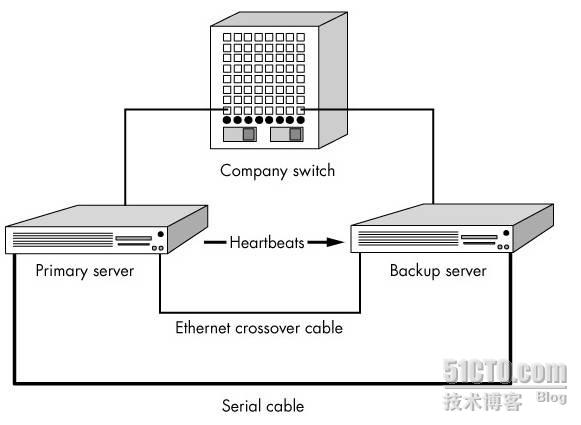
運行於備用主機上的Heartbeat可以通過以太網連接檢測主服務器的運行狀態,一旦其無法檢測到主服務器的“心跳”則自動接管主服務器的資源。通常情況下,主、備服務器間的心跳連接是一個獨立的物理連接,這個連接可以是串行線纜、一個由“交叉線”實現的以太網連接。Heartbeat甚至可同時通過多個物理連接檢測主服務器的工作狀態,而其只要能通過其中一個連接收到主服務器處於活動狀態的信息,就會認爲主服務器處於正常狀態。從實踐經驗的角度來說,建議爲Heartbeat配置多條獨立的物理連接,以避免Heartbeat通信線路本身存在單點故障。
1、串行電纜:被認爲是比以太網連接安全性稍好些的連接方式,因爲hacker無法通過串行連接運行諸如telnet、ssh或rsh類的程序,從而可以降低其通過已劫持的服務器再次侵入備份服務器的機率。但串行線纜受限於可用長度,因此主、備服務器的距離必須非常短。
2、以太網連接:使用此方式可以消除串行線纜的在長度方面限制,並且可以通過此連接在主備服務器間同步文件系統,從而減少了從正常通信連接帶寬的佔用。
3、光電交換機
總體部署如下圖所示,當然只是選擇其中的一種方式就行了:
![]()
1、串行電纜:被認爲是比以太網連接安全性稍好些的連接方式,因爲hacker無法通過串行連接運行諸如telnet、ssh或rsh類的程序,從而可以降低其通過已劫持的服務器再次侵入備份服務器的機率。但串行線纜受限於可用長度,因此主、備服務器的距離必須非常短。
2、以太網連接:使用此方式可以消除串行線纜的在長度方面限制,並且可以通過此連接在主備服務器間同步文件系統,從而減少了從正常通信連接帶寬的佔用。
3、光電交換機
總體部署如下圖所示,當然只是選擇其中的一種方式就行了:
隔離級別:
1.節點級別:
STONITH:Shoot The Other Node In the Head (俗稱“爆頭”)呵呵,挺形象的,意思就是直接切斷電源;常用的方法是所有節點都接在一個電源交換機上,如果有故障,就直接導致該節點的電壓不穩定,或斷電,是有故障的節點重啓
2.資源級別:
fencing 只是把某種資源截獲過來
而對於多節點的集羣就要複雜了,在多節點集羣中要有個“頭頭”就是指定的“協調員”DC,就是一個集羣中每個幾點上都有一個相當於選舉票的權值,而這個權值就是根據服務器的性能進行手動分配的,性能好的可以分配的大點,而所有的其他節點都要聽從DC的調度,在一個集羣中只有選票達到50%以上才能稱爲集羣系統。
如果出現故障了,就會有一個故障轉移(failover),設置不同的優先級,可以使故障按照優先級的高低進行轉移,選擇一個性能好的服務器當DC。
1.節點級別:
STONITH:Shoot The Other Node In the Head (俗稱“爆頭”)呵呵,挺形象的,意思就是直接切斷電源;常用的方法是所有節點都接在一個電源交換機上,如果有故障,就直接導致該節點的電壓不穩定,或斷電,是有故障的節點重啓
2.資源級別:
fencing 只是把某種資源截獲過來
而對於多節點的集羣就要複雜了,在多節點集羣中要有個“頭頭”就是指定的“協調員”DC,就是一個集羣中每個幾點上都有一個相當於選舉票的權值,而這個權值就是根據服務器的性能進行手動分配的,性能好的可以分配的大點,而所有的其他節點都要聽從DC的調度,在一個集羣中只有選票達到50%以上才能稱爲集羣系統。
如果出現故障了,就會有一個故障轉移(failover),設置不同的優先級,可以使故障按照優先級的高低進行轉移,選擇一個性能好的服務器當DC。
既然前面講到了共享存儲,下面就簡單的介紹一下共享存儲的方式:
DAS:(Direct attached storage)設備直接連接到主機總線上的,距離有限,而且還要重新掛載,之間有耽誤時間
RAID
SCSI
NAS:(network attached storage)網絡附加存儲
文件級別的共享
SAN:(storage area network)存儲區域網絡
塊級別的
模擬的scsi協議
FC光網絡(交換機的光接口超貴,有一個差不多2萬,如果使用這個,代價太高)
IPSAN(iscsi)存取快,塊級別
DAS:(Direct attached storage)設備直接連接到主機總線上的,距離有限,而且還要重新掛載,之間有耽誤時間
RAID
SCSI
NAS:(network attached storage)網絡附加存儲
文件級別的共享
SAN:(storage area network)存儲區域網絡
塊級別的
模擬的scsi協議
FC光網絡(交換機的光接口超貴,有一個差不多2萬,如果使用這個,代價太高)
IPSAN(iscsi)存取快,塊級別
集羣文件系統:GFS2、OCFS2,這只能在集羣中使用
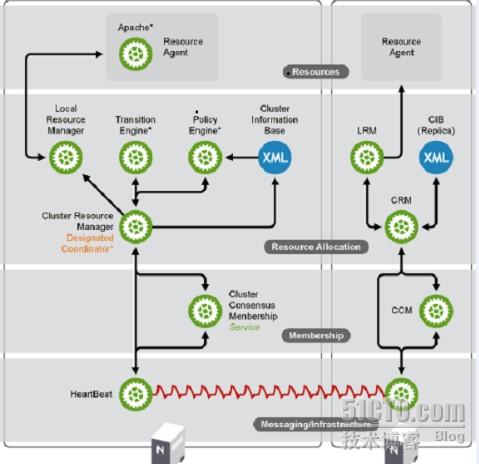
HA的架構層次:
從下向上講:
1.Messageing and Infrastructure Layer (信息基礎架構層):<套件---heartbeat,keepalive,corosync/openais,RHCS
傳遞心跳信息的非常重要的子層,通過單獨的服務組件來實現,除了心跳信息,還傳遞集羣事務信息
2.Membership 成員層: <套件-----pacemaker(心臟起搏器),cman
(CCM,成員信息)
重新收斂集羣成員信息,生成一個概覽圖,爲第三層採取動作提供信息
3.Resource Allocation資源分配層
Cluster Resource Manage(集羣資源管理)
LRM,決策本地資源(local resource manage)。定義資源的屬性,反映本地資源的信息
policy engine 策略引擎,做決策
transition engine 執行引擎,執行策略引擎做的決定
Cluster information Base 集羣信息基礎,他是一個包括membership,resoutces,constraints的XML文,在任意一個節點上使用命令進行修改,都會自動的同步到主節點DC的配置文件中去
4.Resource Layer(資源層)
Resource Agent資源代理:就是運行具體的服務,服務啓動的腳本,數據文件等資源整體結構如下圖所示:
HA的架構層次:
從下向上講:
1.Messageing and Infrastructure Layer (信息基礎架構層):<套件---heartbeat,keepalive,corosync/openais,RHCS
傳遞心跳信息的非常重要的子層,通過單獨的服務組件來實現,除了心跳信息,還傳遞集羣事務信息
2.Membership 成員層: <套件-----pacemaker(心臟起搏器),cman
(CCM,成員信息)
重新收斂集羣成員信息,生成一個概覽圖,爲第三層採取動作提供信息
3.Resource Allocation資源分配層
Cluster Resource Manage(集羣資源管理)
LRM,決策本地資源(local resource manage)。定義資源的屬性,反映本地資源的信息
policy engine 策略引擎,做決策
transition engine 執行引擎,執行策略引擎做的決定
Cluster information Base 集羣信息基礎,他是一個包括membership,resoutces,constraints的XML文,在任意一個節點上使用命令進行修改,都會自動的同步到主節點DC的配置文件中去
4.Resource Layer(資源層)
Resource Agent資源代理:就是運行具體的服務,服務啓動的腳本,數據文件等資源整體結構如下圖所示:
heartbeat v1上的配置
總體拓撲如下圖所示:
![]()
總體拓撲如下圖所示:

一、首先實現兩個節點之間的主機相互登錄不使用密碼,方便後面的使用
Node1上的配置
#ssh-keygen -t rsa //生成公鑰和密鑰,一步enter到底就行了
## ssh-copy-id -i .ssh/id_rsa [email protected] //輸入密碼就行了
Node2上的配置
#ssh-keygen -t rsa //生成公鑰和密鑰,一步enter到底就行了
## ssh-copy-id -i .ssh/id_rsa [email protected] //輸入密碼就行了
二、配置Node1:
1.配置網卡的地址,強烈建議使用靜態地址
2.#vim /etc/hosts對所有的節點主機的心跳IP和主機名都寫入
10.1.1.1 node1.a.org node1
10.1.1.2 node2.a.org node2
3.編輯主機名
#vim /etc/sysconfig/network
HOSTNAME=node1.a.org
#hostname node1.a.org
#yum install httpd
#echo "<h1>node1server</h1>" >/var/www/html/index.html
任何集羣服務都不能自動啓動,而且還不能開機自動啓動
#server httpd stop
#chkconfig httpd off
4.安裝heartbeat,複製配置文件及配置
Node1上的配置
#ssh-keygen -t rsa //生成公鑰和密鑰,一步enter到底就行了
## ssh-copy-id -i .ssh/id_rsa [email protected] //輸入密碼就行了
Node2上的配置
#ssh-keygen -t rsa //生成公鑰和密鑰,一步enter到底就行了
## ssh-copy-id -i .ssh/id_rsa [email protected] //輸入密碼就行了
二、配置Node1:
1.配置網卡的地址,強烈建議使用靜態地址
2.#vim /etc/hosts對所有的節點主機的心跳IP和主機名都寫入
10.1.1.1 node1.a.org node1
10.1.1.2 node2.a.org node2
3.編輯主機名
#vim /etc/sysconfig/network
HOSTNAME=node1.a.org
#hostname node1.a.org
#yum install httpd
#echo "<h1>node1server</h1>" >/var/www/html/index.html
任何集羣服務都不能自動啓動,而且還不能開機自動啓動
#server httpd stop
#chkconfig httpd off
4.安裝heartbeat,複製配置文件及配置
所需的軟件包如下所示

#yum localinstall * -y --nogpgcheck //安裝heartbeat軟件包
#cd /usr/share/doc/heartbeat-2.1.4/
#cp ha.cf haresources authkeys /etc/ha.d/
#cd /etc/ha.d/
#vim /etc/ha.d/ha.cf
修改如下內容
keepalive 2 //保持時間
deadtime 30 //死亡時間
warntime 10 //警告時間
initdead 120 //啓動時間
udpport 694 //使用udp的端口
bcast eth1 //心跳接口
logfile /var/log/ha-log //日誌文件
auto_failback on //失敗自動退回
node node1.a.org //節點對應的主機名,這裏面要寫所有的
node node2.a.org
#vim authkeys
auth 2
2 sha1 jlasdlfladddd //這個後面的密碼可以隨意寫,也可以使用自動生成隨機數(#dd if=/dev/urandom bs=512 count=1 |md5sum )的方式來生成,但是節點之間是一樣的
#chmod 400 authkeys //修改權限
#vim haresources
node1.a.org 192.168.1.254/24eth0/192.168.1.255 httpd //生成一個VIP
#cd /usr/lib/heabeat
./ha_propagate //拷貝文件authkeys和ha.cf文件
三、配置Node2:
1.配置網卡的地址,強烈建議使用靜態地址
2.#vim /etc/hosts對所有的節點主機的心跳IP和主機名都寫入
10.1.1.1 node1.a.org node1
10.1.1.2 node2.a.org node2
3.編輯主機名
#vim /etc/sysconfig/network
HOSTNAME=node2.a.org
#hostname node2.a.org
#yum install httpd
#echo "<h1>node2server</h1>" >/var/www/html/index.html
任何集羣服務都不能自動啓動,而且還不能開機自動啓動
#server httpd stop
#chkconfig httpd off
#cd /usr/share/doc/heartbeat-2.1.4/
#cp ha.cf haresources authkeys /etc/ha.d/
#cd /etc/ha.d/
#vim /etc/ha.d/ha.cf
修改如下內容
keepalive 2 //保持時間
deadtime 30 //死亡時間
warntime 10 //警告時間
initdead 120 //啓動時間
udpport 694 //使用udp的端口
bcast eth1 //心跳接口
logfile /var/log/ha-log //日誌文件
auto_failback on //失敗自動退回
node node1.a.org //節點對應的主機名,這裏面要寫所有的
node node2.a.org
#vim authkeys
auth 2
2 sha1 jlasdlfladddd //這個後面的密碼可以隨意寫,也可以使用自動生成隨機數(#dd if=/dev/urandom bs=512 count=1 |md5sum )的方式來生成,但是節點之間是一樣的
#chmod 400 authkeys //修改權限
#vim haresources
node1.a.org 192.168.1.254/24eth0/192.168.1.255 httpd //生成一個VIP
#cd /usr/lib/heabeat
./ha_propagate //拷貝文件authkeys和ha.cf文件
三、配置Node2:
1.配置網卡的地址,強烈建議使用靜態地址
2.#vim /etc/hosts對所有的節點主機的心跳IP和主機名都寫入
10.1.1.1 node1.a.org node1
10.1.1.2 node2.a.org node2
3.編輯主機名
#vim /etc/sysconfig/network
HOSTNAME=node2.a.org
#hostname node2.a.org
#yum install httpd
#echo "<h1>node2server</h1>" >/var/www/html/index.html
任何集羣服務都不能自動啓動,而且還不能開機自動啓動
#server httpd stop
#chkconfig httpd off
四、安裝heartbeat軟件包並拷貝配置文件
#yum localinstall * -y --nogpgcheck //和Node1 一樣的安裝
#yum localinstall * -y --nogpgcheck //和Node1 一樣的安裝
#cd /usr/lib/heatbeat
#./ha_propagate //拷貝文件authkeys和ha.cf文件
#cd /etc/ha.d/
#scp haresources node2:/etc/ha.d/
五、啓動服務
#/etc/init.d/heartbeat start
#ssh node2 --'/etc/init.d/heartbeat start' //無論哪個先啓動,但是所有集羣的節點必須在同一個上面啓動其他節點
六、測試:
在瀏覽器中輸入http://192.168.1.254進行訪問
測試的時候,在Node2上停止Node1的服務
#ssh node1 --'/etc/init.d/heartbeat stop'
在主節點上執行/usr/lig/heartbeat/hb_standy 讓出主節點
/usr/lig/heartbeat/hb_takeover 主節點把資源搶回來
實驗結束!
#./ha_propagate //拷貝文件authkeys和ha.cf文件
#cd /etc/ha.d/
#scp haresources node2:/etc/ha.d/
五、啓動服務
#/etc/init.d/heartbeat start
#ssh node2 --'/etc/init.d/heartbeat start' //無論哪個先啓動,但是所有集羣的節點必須在同一個上面啓動其他節點
六、測試:
在瀏覽器中輸入http://192.168.1.254進行訪問
測試的時候,在Node2上停止Node1的服務
#ssh node1 --'/etc/init.d/heartbeat stop'
在主節點上執行/usr/lig/heartbeat/hb_standy 讓出主節點
/usr/lig/heartbeat/hb_takeover 主節點把資源搶回來
實驗結束!