




關於elk這方面的介紹我這邊就不多說了,之前有過介紹。我這篇文章爲了應對目前我們這個公司業務量不大情況而搭建的日誌收集系統。
一、安裝Elasticsearch
安裝docker我這裏及不說了
從官網拉取elasticsearch鏡像
[root@devon ~]# docker pull docker.elastic.co/elasticsearch/elasticsearch:7.3.1
[root@devon ~]# docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.3.1 <!--啓動-->
二、安裝kibana
拉取kibana鏡像
[root@devon ~]# docker pull docker.elastic.co/kibana/kibana:7.3.1
啓動
[root@devon ~]# docker run --name kibana -d -p 5601:5601 -e ELASTICSEARCH_HOSTS=http://192.168.10.8:9200 kibana:7.3.1 <!--IP換成自己的-->
[root@devon ~]# docker run --name kibana -d -p 5601:5601 -e ELASTICSEARCH_HOSTS=http://192.168.10.8:9200 kibana:7.3.1
0e07e9d646fe3e0786e434d2b97a813dac9c17cbd2ea664e0e5151dc4c4d4417
[root@devon ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS
0e07e9d646fe kibana:7.3.1 "/usr/local/bin/du..." 8 seconds ago Up 7 seconds
400f07c09c01 docker.elastic.co/elasticsearch/elasticsearch:7.3.1 "/usr/local/bin/do..." 6 hours ago Up 6 hours訪問kibana IP+5601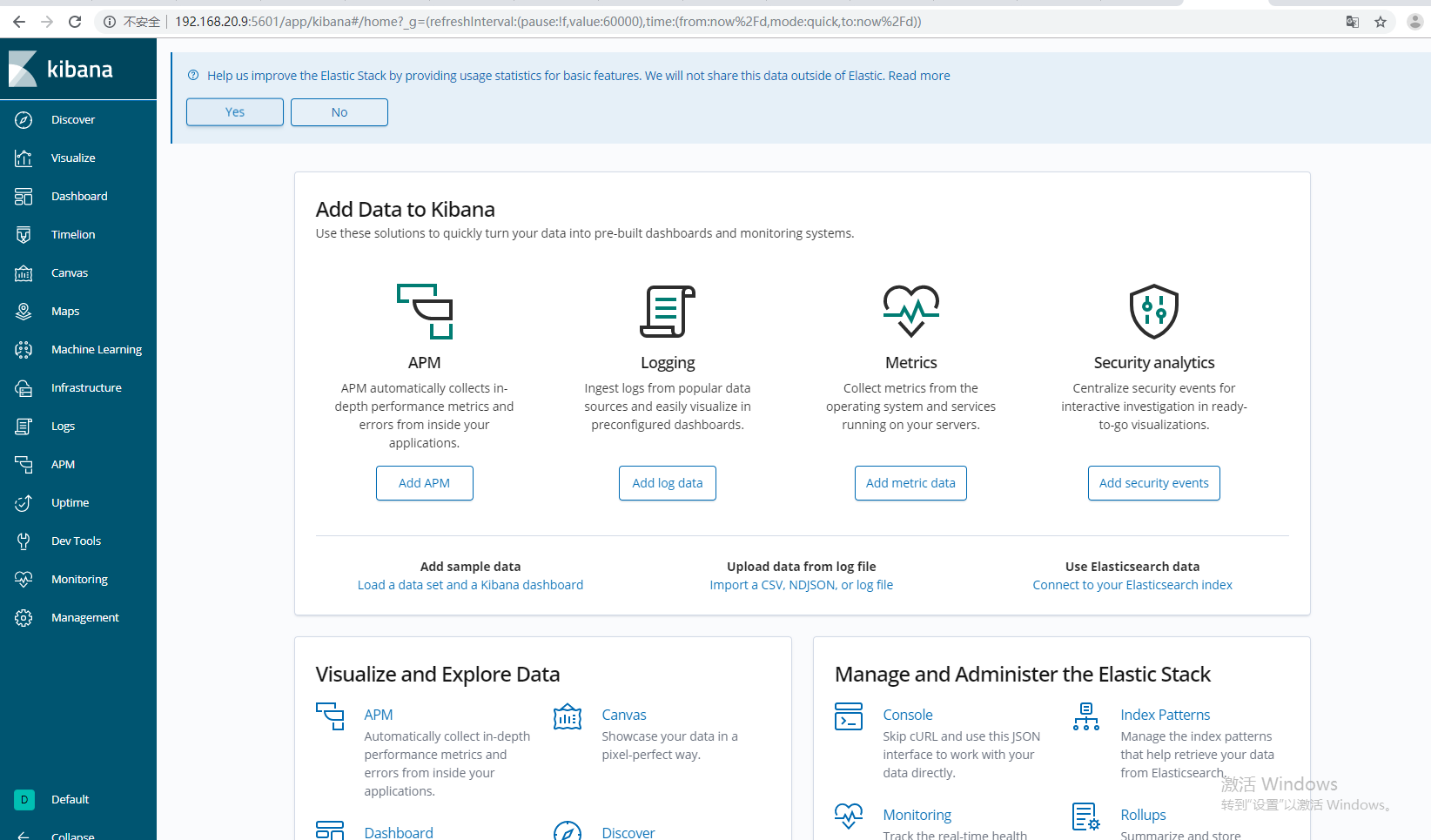
下面我們就利用filebeat收集日誌吧
[root@devon ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.4-linux-x86_64.tar.gz
[root@devon ~]# tar -zxf filebeat-6.2.4-linux-x86_64.tar.gz -C /data/
[root@devon ~]# mv /data/filebeat-6.2.4-linux-x86_64/ /data/filebeat-6.2.4
[root@devon ~]# vim /data/filebeat-6.2.4/filebeat.yml
怎麼利用filebeat設置多個索引,方便查詢日誌呢,我選擇自定義的filebeat.yml文件
下面是我簡單的收集的三個Java服務的日誌。也可以更改默認模板,如果安裝了logstash,格式需要修改,分析日誌的格式一般由開發定。他們若有特殊要求格式,就另有他們便也json格式文件或者其他格式。
filebeat.prospectors:
- input_type: log
paths:
- /var/application/ivy-user-service/logs/catalina.out
fields:
type: "user"
- input_type: log
paths:
- /var/application/ivy-sbd-service/logs/catalina.out
fields:
type: "sbd"
- input_type: log
paths:
- /var/application/ivy-order-service/logs/catalina.out
fields:
type: "order"
json.message_key: log
json.keys_under_root: true
output.elasticsearch:
hosts: ["192.168.20.10:9200"]
#index: "logs-%{[beat.version]}-%{+yyyy.MM.dd}"
indices:
- index: "user-service-log"
when.equals:
fields.type: "user"
- index: "sbd-service-log"
when.equals:
fields.type: "sbd"
- index: "order-service-log"
when.equals:
fields.type: "order"然後如果我們有利用elasticsearch-head插件來管理集羣的話我們可以看到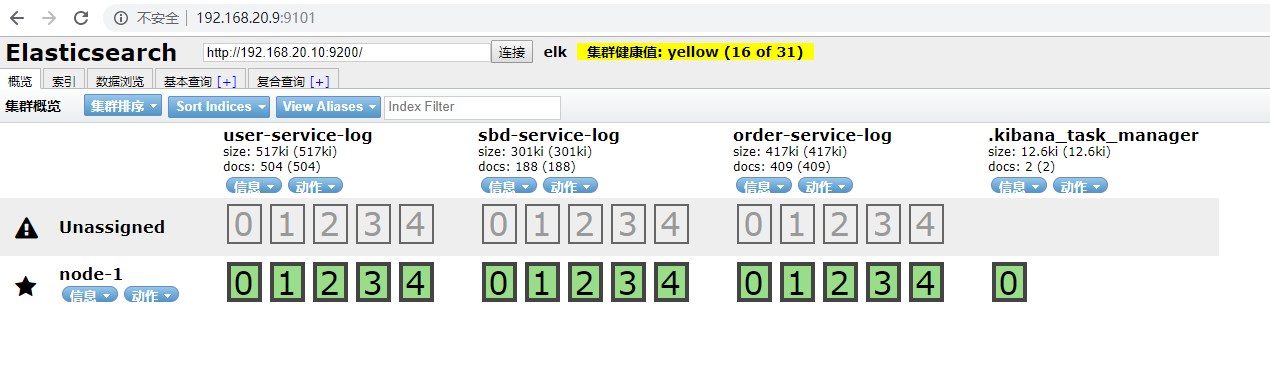
elasticsearch-head默認9100端口,爲了避免端口發生衝突我就更改了下。如果線上的話,也沒必要用這個管理。看自己的需求吧。
利用kibana和elasticsearch索引關聯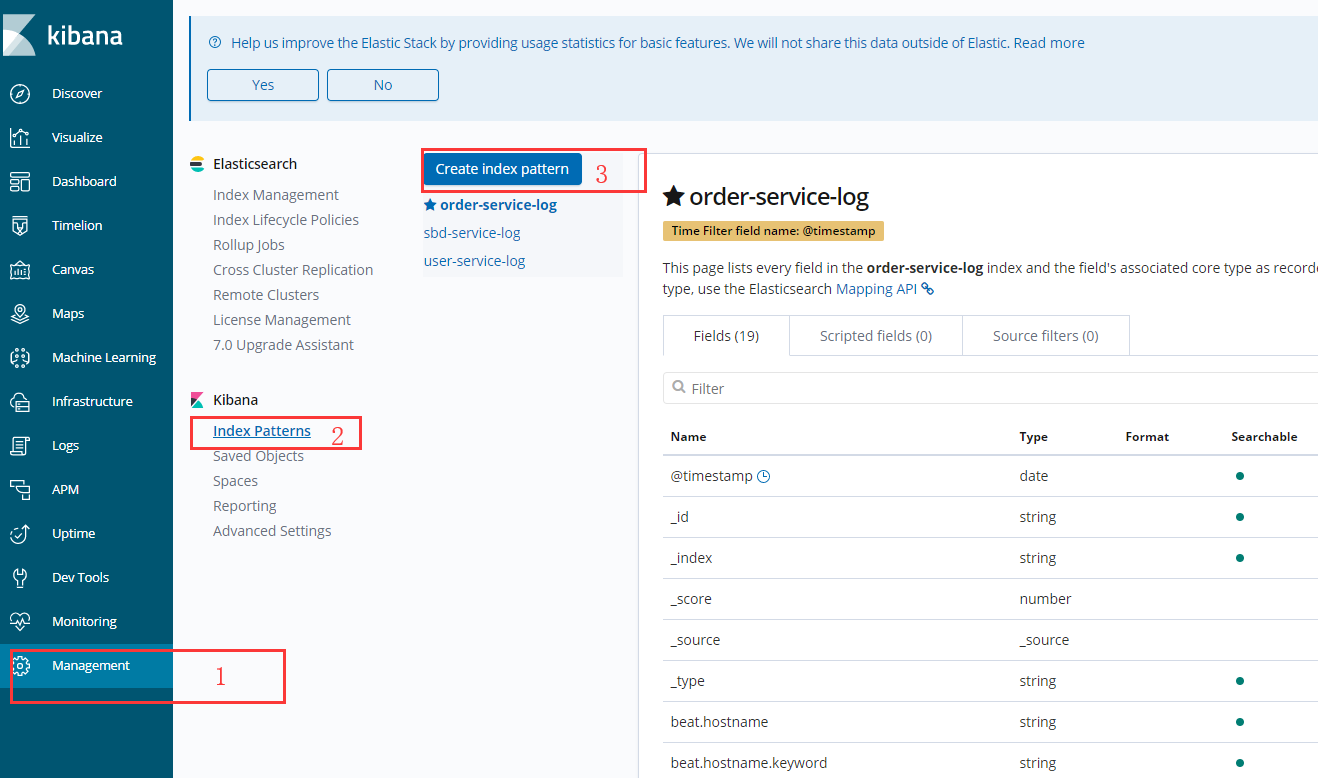
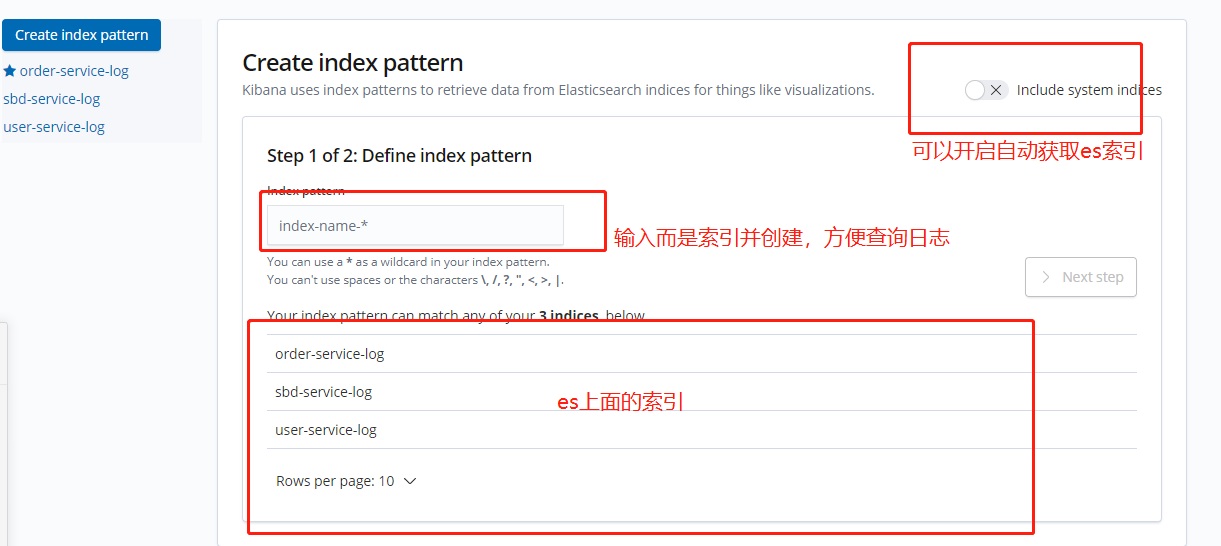
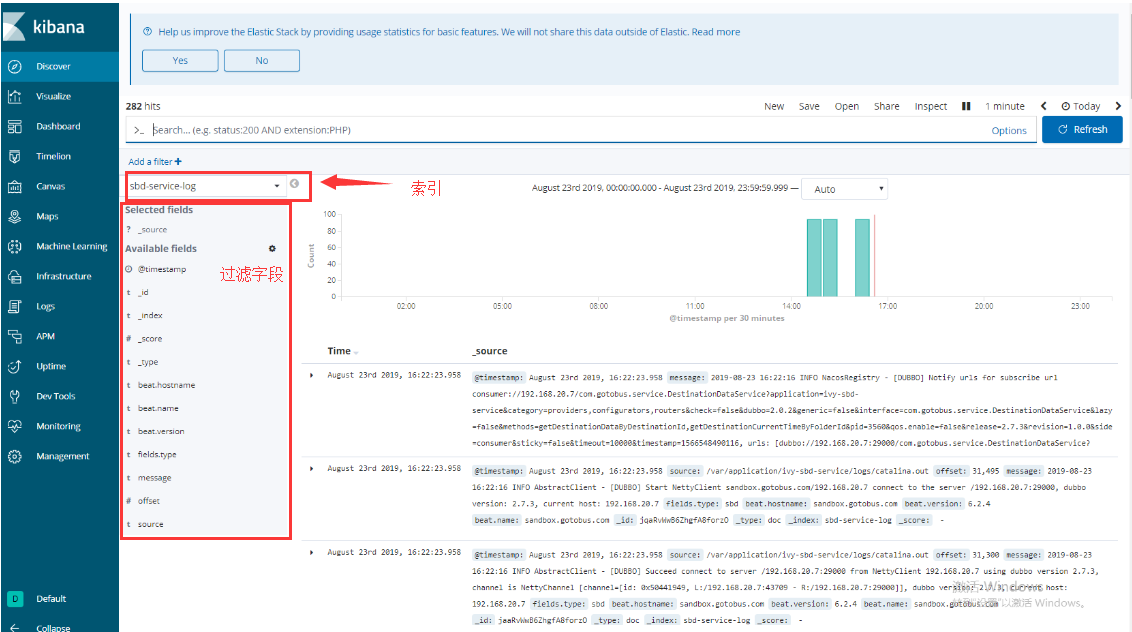
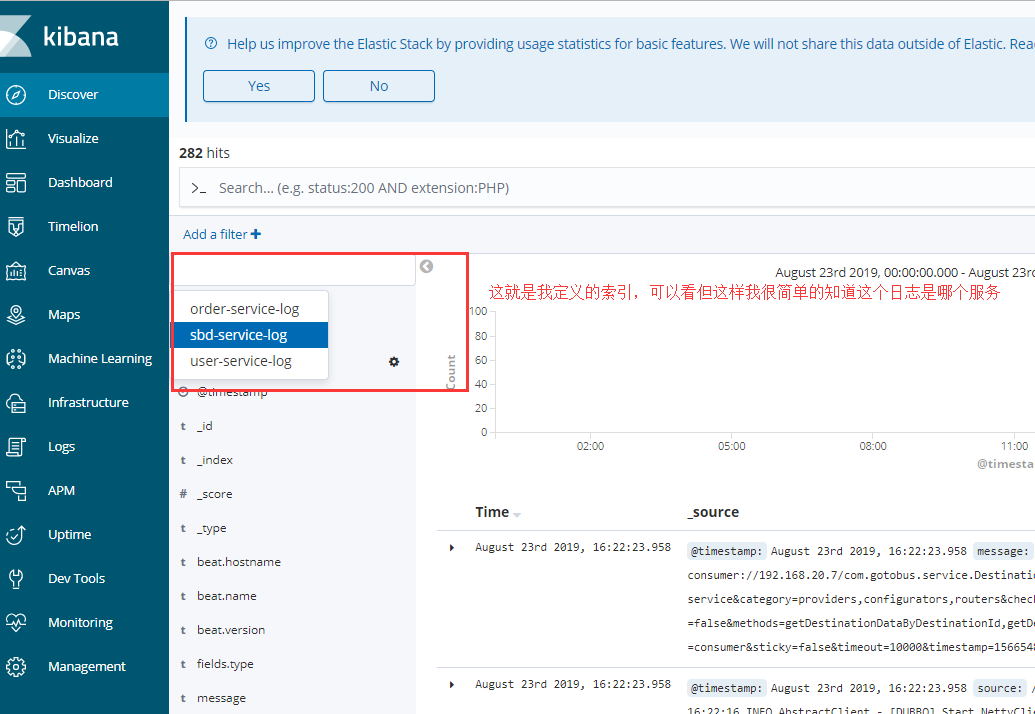
其上面的圖是我6.8.2版本的kinbana,到現在的7.3.1幾乎沒有差別
下面我們就來創建可視化圖形吧。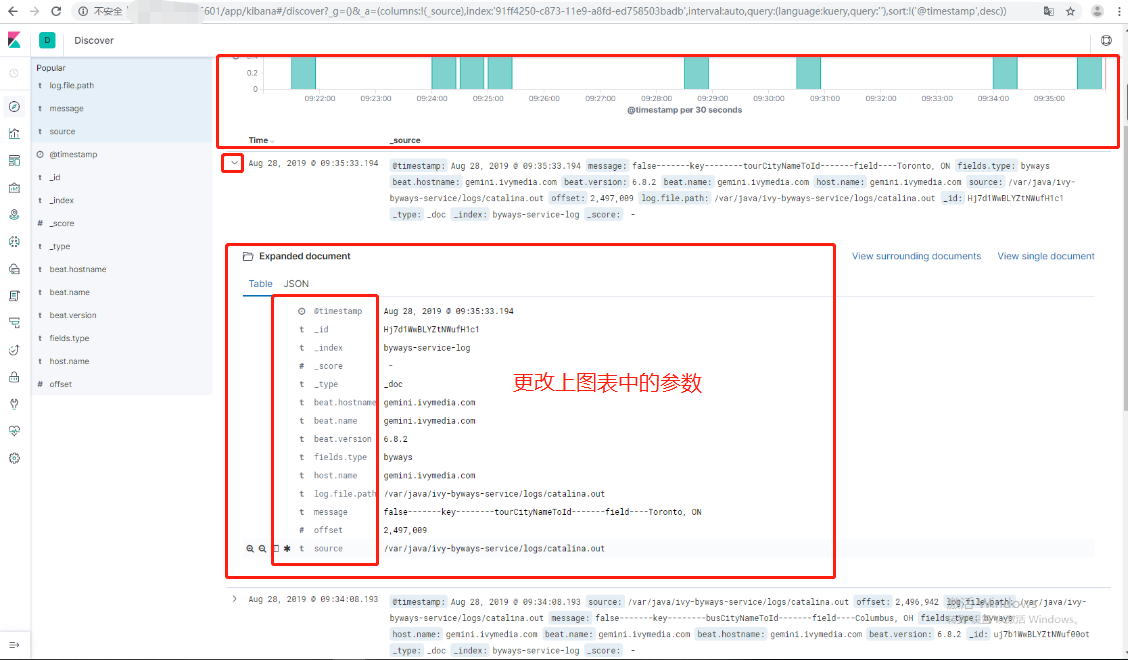
7.3.1版本創建圖表發生一點變化。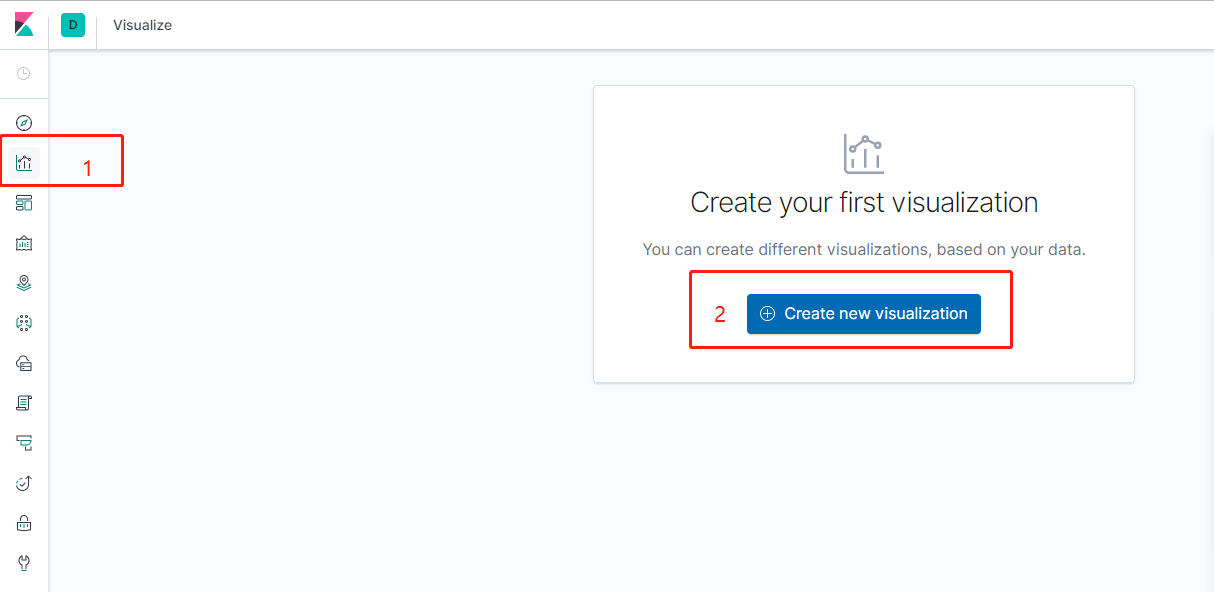
可以根據自己的需求來創建不同樣式的圖表,這裏我就先創建line圖表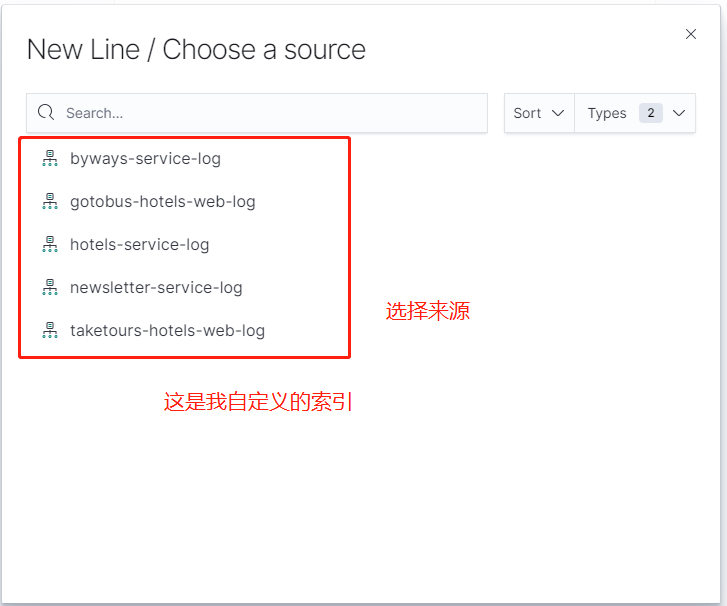
點擊你想創建的索引
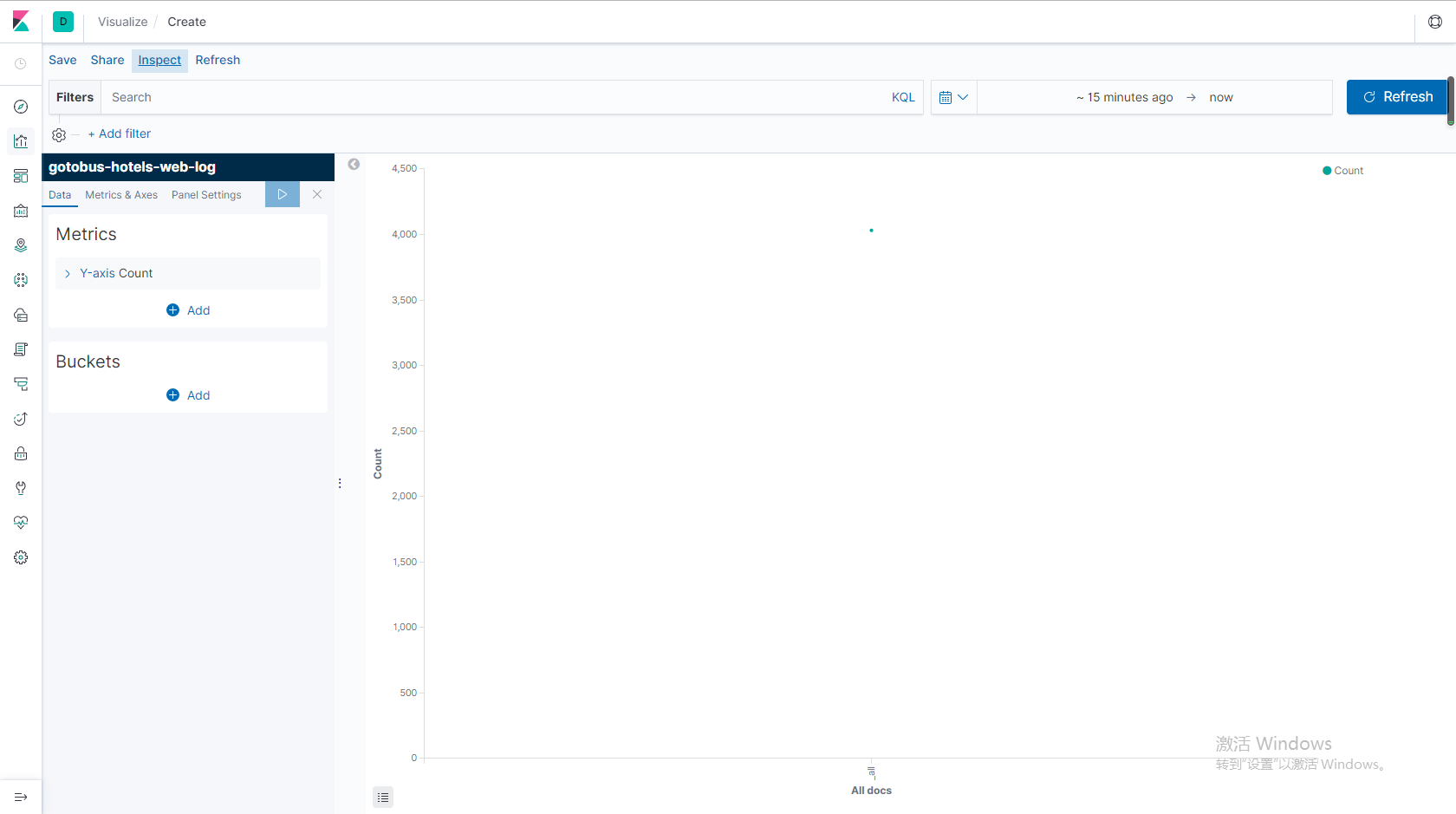
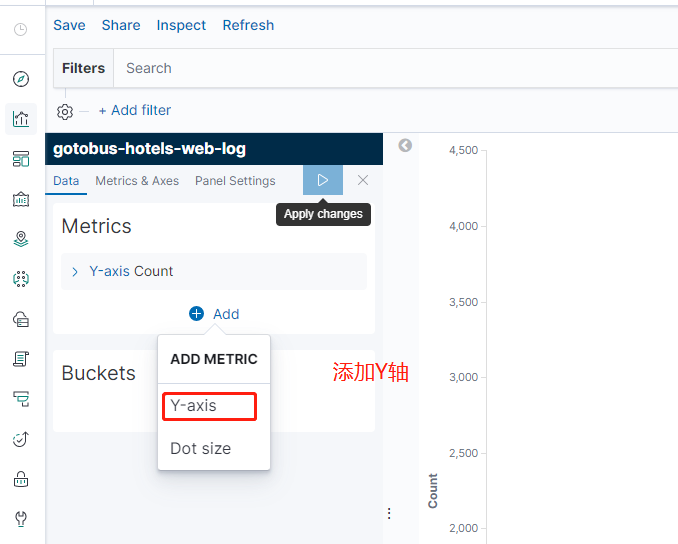
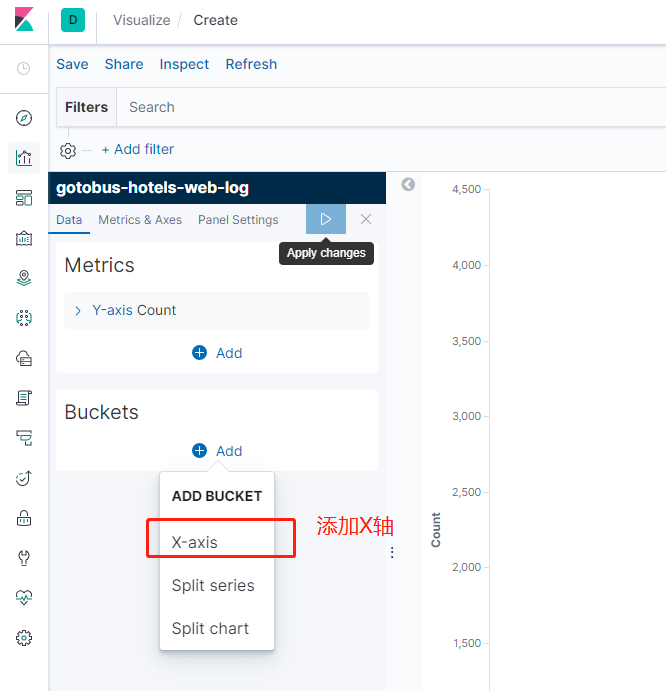
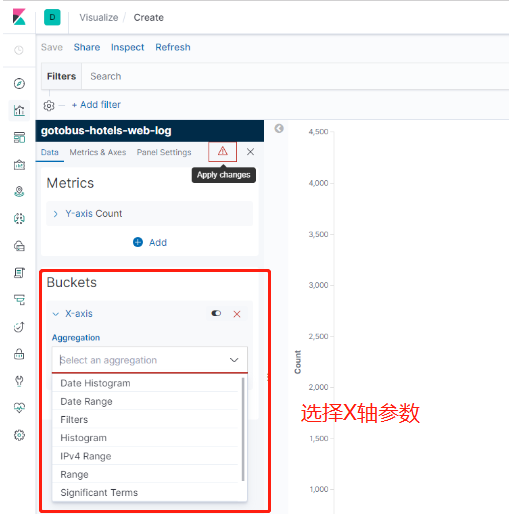
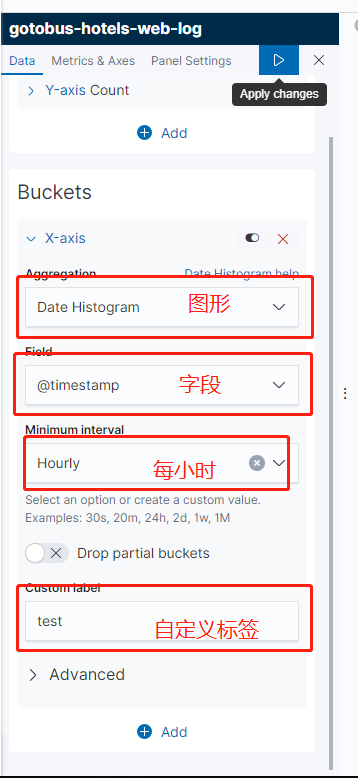
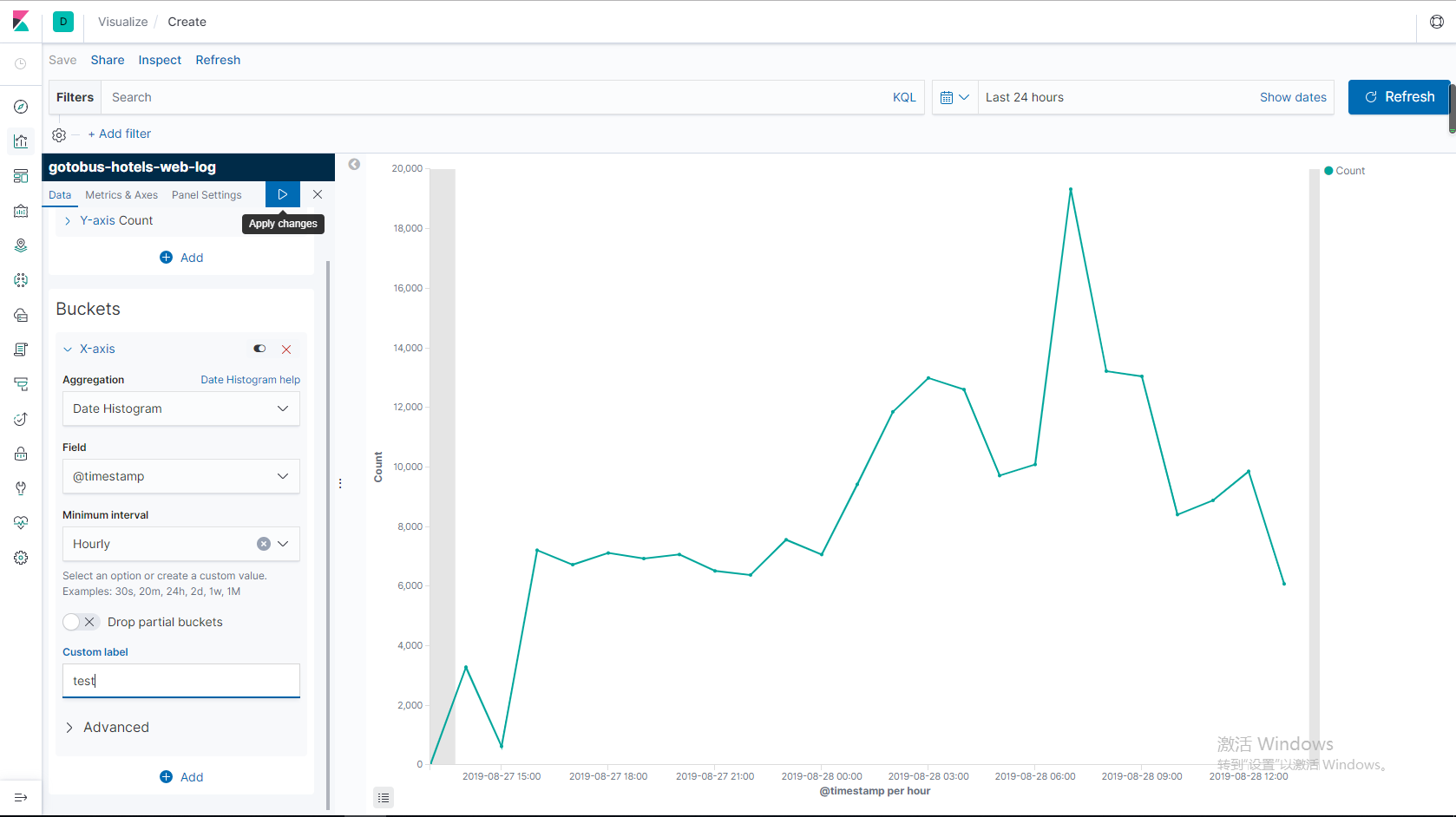
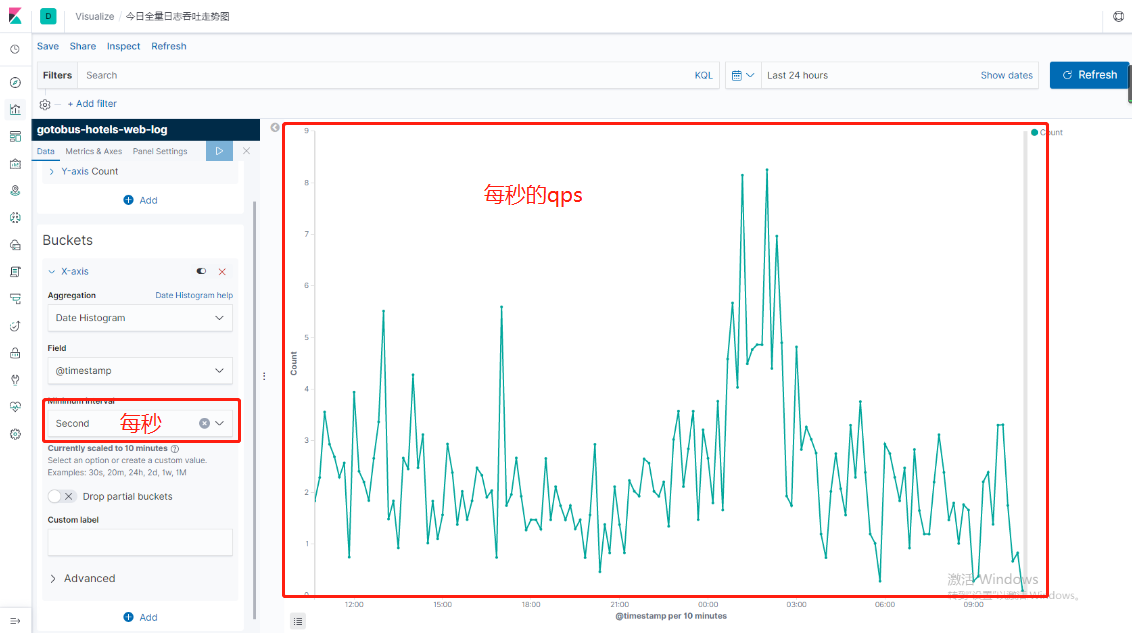
至於kibana其他功能就自己探討嘍,
如果這樣的架構滿足不了也可以換成elk+kafaka+zookeeper等等
如果是集羣模式的可以介紹兩個管理集羣的插件。
cerebo是kopf在es5上的替代者,通過web界面來管理和監控elasticsearch集羣狀態信息
bigdesk 統計分析和圖表化elasticsearch集羣狀態信息
ES數據定期刪除
如果不刪除ES數據,將會導致ES存儲的數據越來越多,磁盤滿了之後將無法寫入新的數據。這時可以使用腳本定時刪除過期數據。
#/bin/bash
#es-index-clear
#只保留7天內的日誌索引
LAST_DATA=`date -d "-7 days" "+%Y.%m.%d"`
#刪除上個月份所有的索引
curl -XDELETE 'http://ip:port/*-'${LAST_DATA}'*'可以視個人情況調整保留的天數,這裏的ip和port同樣設置爲不存儲數據的那臺機器。該腳本只需要在ES中一臺機器定時運行即可。然後再調用crontab
crontab -e添加定時任務:
0 1 * * * /root/cron/del_es.sh每天的凌晨一點清除索引。
也可以把es-index-clear.sh內容換成其它優秀代碼,如下:
#!/bin/bash
###################################
#刪除早於十天的ES集羣的索引
###################################
function delete_indices() {
comp_date=`date -d "10 day ago" +"%Y-%m-%d"`
date1="$1 00:00:00"
date2="$comp_date 00:00:00"
t1=`date -d "$date1" +%s`
t2=`date -d "$date2" +%s`
if [ $t1 -le $t2 ]; then
echo "$1時間早於$comp_date,進行索引刪除"
#轉換一下格式,將類似2017-10-01格式轉化爲2017.10.01
format_date=`echo $1| sed 's/-/\./g'`
curl -XDELETE http://127.0.0.1:9200/*$format_date
fi
}
curl -XGET http://127.0.0.1:9200/_cat/indices | awk -F" " '{print $3}' | awk -F"-" '{print $NF}' | egrep "[0-9]*\.[0-9]*\.[0-9]*" | sort | uniq | sed 's/\./-/g' | while read LINE
do
#調用索引刪除函數
delete_indices $LINE
done下面這兩個腳本是在網上借鑑的,歡迎大家一起學習研究。