




推薦系統能夠爲用戶提供個性化體驗,現在基本上各大電商平臺、資訊平臺都會用推薦系統爲自家評價下的用戶提供千人千面的服務。平均精度均值(Mean Average Precision,MAP)便是評估推薦系統性能的度量標準之一。
但是,使用其他診斷指標和可視化工具可以讓模型評估更加深入,甚至還會帶來一些其他啓發。本文探討了召回率、覆蓋率、個性化和表內相似性,並使用這些指標來比較三個簡單的推薦系統。
Movielens數據集
這篇文章中的例子使用的數據是Movielens 20m數據集。這些數據包含用戶對電影的評分以及電影類型的標記。 (爲了延長訓練時間,該數據被下采樣,評分僅包括給超過1000部電影打過分的用戶的評分,以及3星及其以上的評分。)
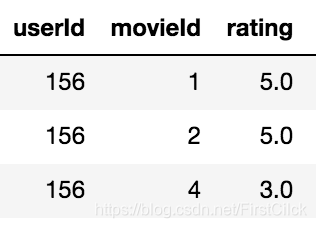
模型
本文測試並比較了三種不同的推薦系統:
1.隨機推薦(隨機爲每位用戶推薦10部電影)
2.根據流行度推薦(向每位用戶推薦最受歡迎的10部電影)
3.協同過濾器(使用SVD的矩陣分解方法)
接下來就讓我們深入瞭解這些指標和診斷圖,並比較這些模型!
長尾圖
長尾圖用於挖掘用戶-項交互數據中的流行度模式,例如點擊次數、評分或購買行爲等。通常,只有一小部分項目具有大量的交互,我們稱之爲“頭部”;而大多數項目都集中在“長尾”中,它們只佔交互的一小部分。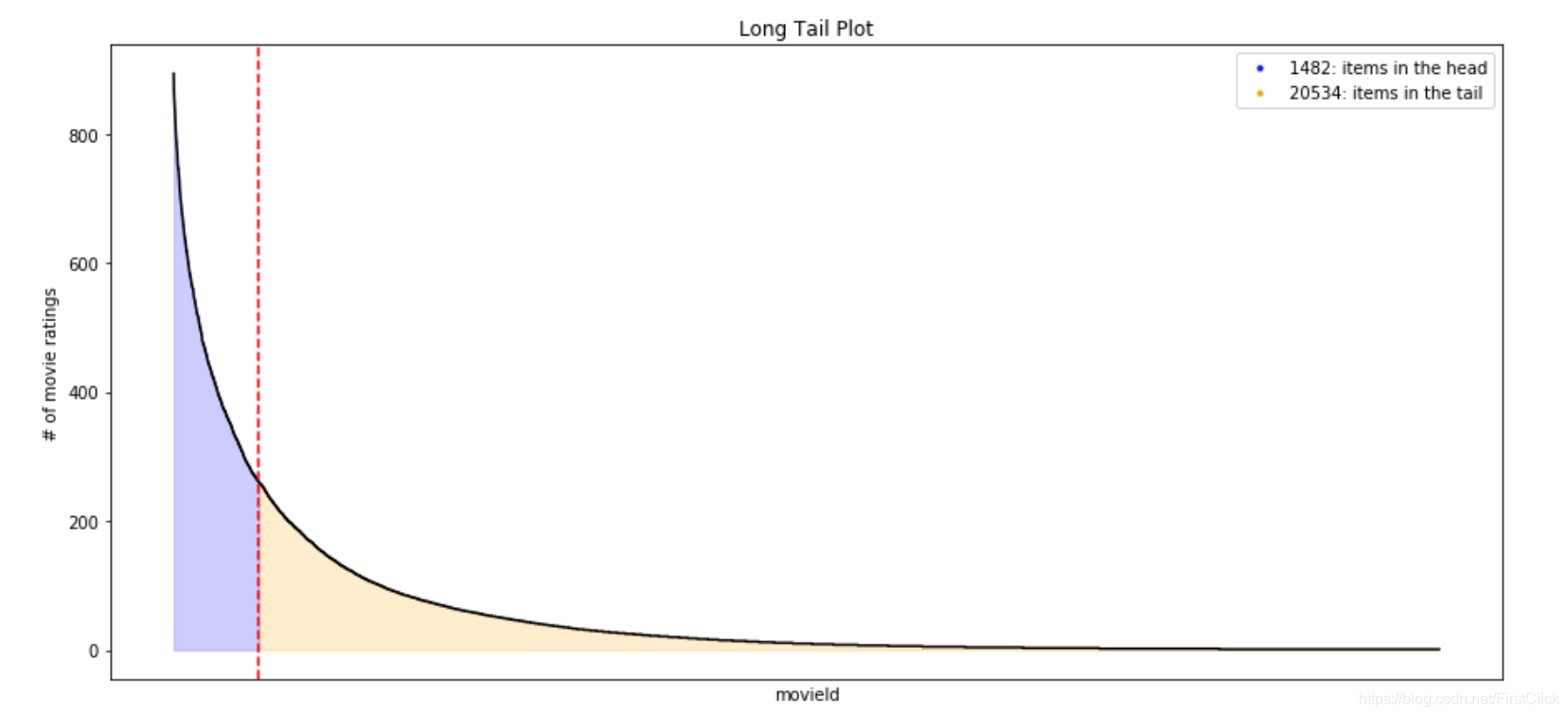
在訓練數據中會對許多熱門項目進行多方觀察,因此,推薦系統想要準確預測這些項目並不難。在電影數據集中,最受歡迎的電影是大片和經典老片。這些電影已爲大多數用戶所熟知,推薦這些電影,對用戶來說可能並非是個性化推薦,也可能無法幫助用戶發現其他新的電影。相關推薦被定義爲用戶在測試數據時給予正面評價的項目的推薦。這裏的指標用來評估推薦系統的相關性和實用性。
MAP和MAR
推薦系統會爲測試集中的每個用戶生成推薦的有序列表。平均精度均值(MAP)可以讓開發者深入瞭解推薦項目列表的相關性,而召回率可以讓開發者深入瞭解推薦系統的調試性能,如調試用戶給予正向評價的所有項目。MAP和MAR的詳細描述如下:
Mean Average Precision (MAP) For Recommender Systems
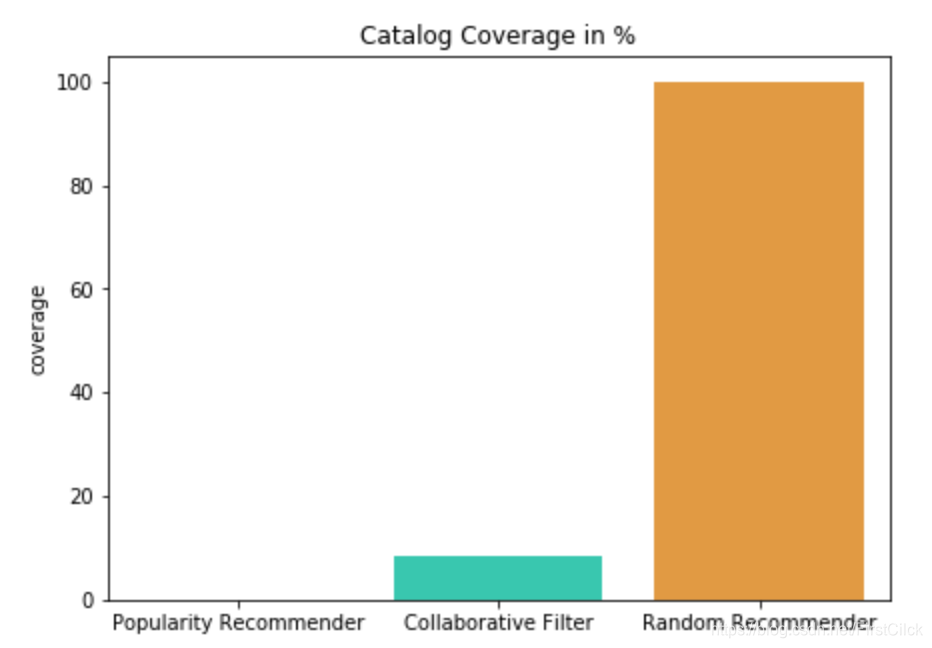
覆蓋率
覆蓋率是指模型能夠在測試集上推薦的項目佔訓練數據的百分比。在此示例中,受歡迎度推薦的覆蓋率僅爲0.05%,它只推薦了10件物品。隨機推薦器的覆蓋率接近100%。出乎意料的是,協同過濾只能推薦其訓練的項目的8.42%。
三個推薦系統的覆蓋率比較:
個性化
個性化是評估模型是否向不同用戶推薦相同項目的方法。用戶的推薦列表之間存在差異(1-餘弦相似性)。下邊的例子能很好地說明如何計算個性化程度。
3個不同用戶的推薦項目示例列表:
首先,每個用戶的推薦項目會被表示爲二進制指示符變量(1:向用戶推薦該項目.0:不向用戶推薦該項目)。
然後,跨所有用戶的推薦向量計算餘弦相似度矩陣。
最後,計算餘弦矩陣的上三角的平均值。個性化是1-平均餘弦相似度。
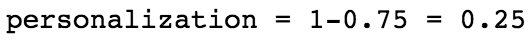
高個性化分數表示用戶的推薦不同,這也意味着該模型爲每一位用戶提供個性化體驗。
列表內相似性
列表內相似性是推薦列表中所有項目的平均餘弦相似度。該計算使用推薦項目(例如電影類型)的特徵來計算相似度。該計算方法可以通過以下示例說明。
針對3個不同用戶的電影ID的推薦示例:

這些電影類型特徵用於計算推薦給用戶的所有項目之間的餘弦相似度。該矩陣顯示了向用戶1推薦的所有電影的特徵。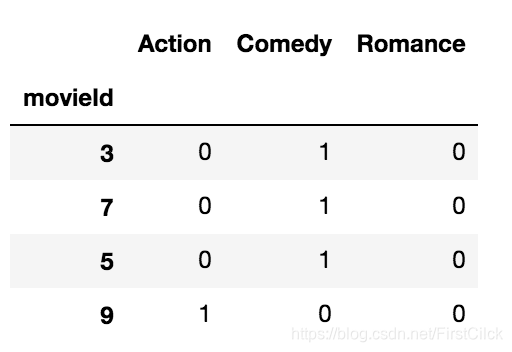
我們可以爲每個用戶計算表內相似性,並對測試集中的所有用戶求平均值,從而得到對模型的表內相似性的估計。

如果推薦系統向每一個用戶推薦非常相似的項目列表(如用戶僅接收浪漫電影的推薦),那麼列表內相似性將很高。
使用正確的訓練數據
我們可以對訓練數據進行如下操作,從而快速改進推薦系統:
1.從培訓數據中刪除熱門項目 (這一點適用於用戶可以自行找到這些項目,以及發現這些項目不具備實用性的情況)。
2.按照用戶的值來放大項目評級,例如平均交易值。這樣做有助於模型推薦能夠帶來忠誠度或高價值客戶的項目。
結論
一個好的推薦系統能夠生成兼具實用性和相關性的推薦結果。
使用多個評估指標來評估模型,能夠更加全面地衡量一個推薦系統的性能。
原文鏈接:Evaluation Metrics for Recommender Systems請添加鏈接描述
以上內容由第四範式先薦編譯,僅供於學習交流,版權歸原作者所有。