




1、Vim自動添加註釋及智能換行
#vi ~/.vimrc
set autoindent
set tabstop=4
set shiftwidth=4
function AddTitle()
call setline(1,"#!/bin/bash")
call append(1,"#====================================================")
call append(2,"# Author: lizhenliang")
call append(3,"# Create Date: " . strftime("%Y-%m-%d"))
call append(4,"# Description: ")
call append(5,"#====================================================")
endf
map <F4> :call AddTitle()<cr>
打開文件後,按F4就會自動添加註釋,省了不少時間: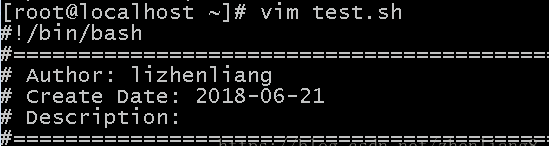
2、查找並刪除/data這個目錄7天前創建的文件
#find /data -ctime +7 -exec rm -rf {} \;
#find /data -ctime +7 | xargs rm -rf3、tar命令壓縮排除某個目錄
#tar zcvf data.tar.gz /data --exclude=tmp #--exclude參數爲不包含某個目錄或文件,後面也可以跟多個4、查看tar包存檔文件,不解壓
#tar tf data.tar.gz #t是列出存檔文件目錄,f是指定存檔文件5、使用stat命令查看一個文件的屬性
訪問時間(Access)、修改時間(modify)、狀態改變時間(Change)stat index.php
Access: 2018-05-10 02:37:44.169014602 -0500
Modify: 2018-05-09 10:53:14.395999032 -0400
Change: 2018-05-09 10:53:38.855999002 -0400
6、批量解壓tar.gz
方法1:find . -name "*.tar.gz" -exec tar zxf {} \;
方法2:for tar in *.tar.gz; do tar zxvf $tar; done
方法3:ls *.tar.gz | xargs -i tar zxvf {} 7、篩除出文件中的註釋和空格
方法1:grep -v "^#" httpd.conf |grep -v "^$"
方法2:sed -e ‘/^$/d’ -e ‘/^#/d’ httpd.conf > http.conf 或者#sed -e '/^#/d;/^$/d' #-e 執行多條sed命令
方法3:awk '/^[^#]/|/"^$"' httpd.conf 或者 #awk '!/^#|^$/' httpd.conf8、篩選/etc/passwd文件中所有的用戶
方法1:cat /etc/passwd |cut -d: -f1
方法2:awk -F ":" '{print $1}' /etc/passwd9、iptables網站跳轉
先開啓路由轉發:
echo "1" > /proc/sys/net/ipv4/ip_forward #臨時生效
內網訪問公網():
iptables –t nat -A POSTROUTING -s [內網IP或網段] -j SNAT --to [公網IP]
#內網服務器要指向防火牆內網IP爲網關
公網訪問內網(DNAT)(公網端口映射內網端口):
iptables –t nat -A PREROUTING -d [對外IP] -p tcp --dport [對外端口] -j DNAT --to [內網IP:內網端口]
#內網服務器要配置防火牆內網IP爲網關,否則數據包回不來。另外,這裏不用配置SNAT,因爲系統服務會根據數據包來源再返回去。10、iptables將本機80端口轉發到本地8080端口
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 808011、find命令查找文件並複製到/opt目錄
方法1:find /etc -name httpd.conf -exec cp -rf {} /opt/ \;: #-exec執行後面命令,{}代表前面輸出的結果,\;結束命令
方法2:find /etc -name httpd.conf |xargs -i cp {} /opt #-i表示輸出的結果由{}代替12、查看根目錄下大於1G的文件
find / -size +1024M #默認單位是b,可以使用其他單位如,C、K、M13、查看服務器IP連接數
netstat -tun | awk '{print $5}' | cut -d: -f1 |sort | uniq -c | sort -n
-tun:-tu是顯示tcp和udp連接,n是以IP地址顯示
cut -d:-f1:cut是一個選擇性顯示一行的內容命令,-d指定:爲分隔符,-f1顯示分隔符後的第一個字段。
uniq -c:報告或刪除文中的重複行,-c在輸出行前面加上出現的次數
sort -n:根據不同類型進行排序,默認排序是升序,-r參數改爲降序,-n是根據數值的大小進行排序14、插入一行到391行,包括特殊符號"/"
sed -i "391 s/^/AddType application\/x-httpd-php .php .html/" httpd.conf15、列出nginx日誌訪問最多的10個IP
方法1:awk '{print $1}' access.log |sort |uniq -c|sort -nr |head -n 10
sort :排序 uniq -c:合併重複行,並記錄重複次數 sort -nr :按照數字進行降序排序
方法2:awk '{a[$1]++}END{for(v in a)print v,a[v] |"sort -k2 -nr |head -10"}' access.log16、顯示nginx日誌一天訪問量最多的前10位IP
awk '$4>="[16/May/2017:00:00:01" && $4<="[16/May/2017:23:59:59"' access_test.log |sort |uniq -c |sort-nr |head -n 10
awk '$4>="[16/Oct/2017:00:00:01" && $4<="[16/Oct/2017:23:59:59"{a[$1]++}END{for(i in a){print a[i],i|"sort -k1 -nr |head -n 10"}}' access.log17、獲取當前時間前一分鐘日誌訪問量
date=`date +%d/%b/%Y:%H:%M --date="-1 minute"` ; awk -vd=$date '$0~d{c++}END{print c}' access.log
date=`date +%d/%b/%Y:%H:%M --date="-1 minute"`; awk -vd=$date '$4>="["d":00" && $4<="["d":59"{c++}END{print c}' access.log
grep `date +%d/%b/%Y:%H:%M --date="-1 minute"` access.log |awk 'END{print NR}'
start_time=`date +%d/%b/%Y:%H:%M:%S --date="-5 minute"`;end_time=`date +%d/%b/%Y:%H:%M:%S`;awk -vstart_time="[$start_time" -vend_time="[$end_time" '$4>=start_time && $4<=end_time{count++}END{print count}' access.log18、找出1-255之間的整數
方法1:ifconfig |grep -o '[0-9]\+' #+號匹配前一個字符一次或多次
方法2:ifconfig |egrep -o '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'19、找出IP地址
ifconfig |grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}' #-o只顯示匹配字符20、給文檔增加開頭和結尾說明信息
awk ‘BEGIN{print "開頭顯示信息"}{print $1,$NF} END{print "結尾顯示信息"}’/etc/passwd
awk 'BEGIN{printf " date ip\n------------------\n"} {print $3,$4} END{printf "------------------\nend...\n"}' /var/log/messages
date ip03:13:01 localhost
10:51:45 localhostend...21、查看網絡狀態命令
netstat -antp #查看所有網絡連接
netstat -lntp #只查看監聽的端口信息
lsof -p pid #查看進程打開的文件句柄
lsof -i:80 #查看端口被哪個進程佔用22、生成8位隨機字符串
方法1:echo $RANDOM |md5sum |cut -c 1-8
方法2:openssl rand -base64 4
方法3:cat /proc/sys/kernel/random/uuid | cut -c 1-823、while死循環
while true; do #條件精確等於真,也可以直接用條件[ "1" == "1" ],條件一直爲真
ping -c 2 www.baidu.com
done24.awk格式化輸出
將文本列進行左對齊或右對齊。
左對齊:
awk '{printf "%-15s %-10s %-20s\n",$1,$2,$3}' test.txt
右對齊:
awk '{printf "%15s %10s %20s\n",$1,$2,$3}' test.txt25.整數運算保留小數點
方法1:echo 'scale=2; 10/3;'|bc #scale參數代表取小數點位數
方法2:awk BEGIN'{printf "%.2f\n",10/3}' 26.數字求和
cat a.txt
10
23
53
56
方法1:
#!/bin/bash
while read num;
do
sum=`expr $sum + $num`
done < a.txt
echo $sum
方法2:
cat a.txt |awk '{sum+=$1}END{print sum}'27、判斷是否爲數字(字符串判斷也如此)
[[ $num =~ ^[0-9]+$ ]] && echo yes || echo no #[[]]比[]更加通用,支持模式匹配=~和字符串比較使用通配符`
^ $:從開始到結束是數字才滿足條件
=~:一個操作符,表示左邊是否滿足右邊(作爲一個模式)正則表達式28、刪除換行符並將空格替換別的字符
cat a.txt |xargs echo -n |sed 's/[ ]/|/g' #-n 不換行
cat a.txt |tr -d '\n' #刪除換行符29、查看文本中20至30行內容(總共100行)
方法1:awk '{if(NR > 20 && NR < 31) print $0}' test.txt
方法2:sed -n '20,30p' test.txt
方法3:head -30 test.txt |tail30、文本中兩列位置替換
cat a.txt
60.35.1.15 www.baidu.com
45.46.26.85 www.sina.com.cn
awk '{print $2"\t"$1}' a.txt31、監控目錄,新創建的文件名追加到日誌中
#要安裝inotify-tools軟件包
#!/bin/bash
MON_DIR=/opt
inotifywait -mq --format %f -e create $MON_DIR |\
while read files; do
echo $files >> test.log
done32、find一次查找多個指定文件類型
find ./ -name '*.jpg' -o -name '*.png'
find ./ -regex ".*\.jpg\|.*\.png"33、字符串拆分
echo "hello" |awk -F '' '{for(i=1;i<=NF;i++)print $i}'
echo "hello" |sed 's/./&\n/g'
echo "hello" |sed -r 's/(.)/\1\n/g'34、實時監控命令運行結果
`watch -d -n 1 'ifconfig'`35、解決郵件亂碼問題
echo `echo "content" | iconv -f utf8 -t gbk` | mail -s "`echo "title" | iconv -f utf8 -t gbk`" [email protected]
注:通過iconv工具將內容字符集轉換36、在文本中每隔三行添加一個換行或內容
sed '4~3s/^/\n/' file
awk '$0;NR%3==0{print "\n"}' file
awk '{print NR%3?$0:$0 "\n"}' file37、刪除匹配行及後一行或前一行
sed '/abc/,+1d' file #刪除匹配行及後一行
sed '/abc/{n;d}' file #刪除後一行
tac file |sed '/abc/,+1d' |tac #刪除前一行38、統計總行數
效率1 # wc -l file
效率2 # grep -c . file
效率3 # awk 'END{print NR}' file
效率4 # sed -n '$=' file39、去除文本開頭和結尾空格
sed -i 's/^[ \t]*//;s/[ \t]*$//' file40、給單個IP加單引號
echo '10.10.10.1 10.10.10.2 10.10.10.3' |sed -r 's/[^ ]+/"&"/g'
echo '10.10.10.1 10.10.10.2 10.10.10.3' |awk '{for(i=1;i<=NF;i++)printf "\047"$i"\047"}' 41、腳本中打印等待時間
wait(){
echo -n "wait 3s"
for ((i=1;i<=3;i++)); do
echo -n "."
sleep 1
done
echo
}
wait42、刪除指定行
awk 'NR==1{next}{print $0}' file #$0可省略
awk 'NR!=1{print}' file
awk 'NR!=1{print $0}' 或刪除匹配行:awk '!/test/{print $0}'
sed '1d' file
sed -n '1!p' file43、在指定行前後加一行
在第二行前一行加txt:
awk 'NR==2{sub('/.*/',"txt\n&")}{print}' a.txt
sed'2s/.*/txt\n&/' a.txt
在第二行後一行加txt:
awk 'NR==2{sub('/.*/',"&\ntxt")}{print}' a.txt
sed'2s/.*/&\ntxt/' a.txt44、通過IP獲取網卡名
ifconfig |awk -F'[: ]' '/^eth/{nic=$1}/192.168.18.15/{print nic}'45、浮點數運算(數字46保留小數點)
# awk 'BEGIN{print 46/100}'
0.46
# echo 46|awk '{print $0/100}'
0.46
# awk 'BEGIN{printf "%.2f\n",46/100}'
0.46
# echo 'scale=2;46/100' |bc|sed 's/^/0/'
0.46
# printf "%.2f\n" $(echo "scale=2;46/100" |bc)
0.4646、浮點數比較
方法1:
if [ $(echo "4>3"|bc) -eq 1 ]; then
echo yes
else
echo no
fi
方法2:
if [ $(awk 'BEGIN{if(4>3)print 1;else print 0}') -eq 1 ]; then
echo yes
else
echo no
fi47、替換換行符爲逗號
cat a.txt
1:
2
3
替換後:1,2,3
方法1:
$ tr '\n' ',' < a.txt
$ sed ':a;N;s/\n/,/;$!b a' a.txt
$ sed ':a;$!N;s/\n/,/;t a' a.txt :
方法2:
while read line; do
a+=($line)
done < a.txt
echo ${a[*]} |sed 's/ /,/g'
方法3:
awk '{s=(s?s","$0:$0)}END{print s}' a.txt
#三目運算符(a?b:c),第一個s是變量,s?s","$0:$0,第一次處理1時,s變量沒有賦值爲假,結果打印1,第二次處理2時,s值是1,爲真,結果1,2。以此類推,小括號可以不寫。
awk '{if($0!=3)printf "%s,",$0;else print $0}' a.txt48、windows下文本到linux下隱藏格式去除
方法1:打開文件後輸入
:set fileformat=unix
方法2:打開文件後輸入
:%s/\r*$// #^M可用\r代替
方法3:
sed -i 's/^M//g' a.txt #^M的輸入方式是ctrl+v,然後ctrl+m
方法4:
dos2unix a.txt49、xargs巧用
xargs -n1 #將單個字段作爲一行
# cat a.txt
1 2
3 4
# xargs -n1 < a.txt
1
2
3
4xargs -n2 #將兩個字段作爲一行
$ cat b.txt
string
number
a
1
b
2
$ xargs -n2 < a.txt
string number
a 1
b 250、統計當前目錄中以.html結尾的文件總大小
方法1:
find . -name "*.html" -maxdepth 1 -exec du -b {} \; |awk '{sum+=$1}END{print sum}'
方法2:
for size in $(ls -l *.html |awk '{print $5}'); do
sum=$(($sum+$size))
done
echo $sum
遞歸統計:find . -name "*.html" -exec du -k {} \; |awk '{sum+=$1}END{print sum}'