




本文首發於 vivo互聯網技術 微信公衆號
鏈接:https://mp.weixin.qq.com/s/LGLqEOlGExKob8xEXXWckQ
作者:錢幸川
在分佈式環境下面,我們經常會通過一定的規則來進行數據分佈的定義,本文描述的取模算法和一致性 Hash(Consistent Hash)是通過一定規則產生一個key,對這個key進行一定規則的運算,得出這個數據該去哪兒。
本文使用軟件環境:Java 8
一、數據分佈接口定義
概述
在分佈式環境下面,我們經常會通過一定的規則來進行數據分佈的定義,比如用戶1的數據存儲到數據庫1、用戶2的數據存儲到數據庫2......
一般來說,有這麼幾種常用的方式:
-
有一個分佈式環境中唯一的中心分發節點,每次在數據存儲的時候,都會詢問中心節點這個數據該去哪兒,這個分發節點明確告訴這個數據該去哪兒。
- 通過一定規則產生一個key,對這個key進行一定規則的運算,得出這個數據該去哪兒。本文描述的取模算法和一致性Hash,就是這樣一種方式。
接口定義
/**
* 數據分佈hash算法接口定義
* @author xingchuan.qxc
*
*/
public interface HashNodeService {
/**
* 集羣增加一個數據存儲節點
* @param node
*/
public void addNode(Node node);
/**
* 數據存儲時查找具體使用哪個節點來存儲
* @param key
* @return
*/
public Node lookupNode(String key);
/**
* hash的算法
* @param key
* @return
*/
public Long hash(String key);
/**
* 模擬意外情況斷掉一個節點,用於測試緩存命中率
* @param node
*/
public void removeNodeUnexpected(Node node);
}二、數據分佈算法實現——取模算法
概述
取模算法的應用場景描述如下:
需要在集羣中實現一個用戶數據存儲的負載均衡,集羣中有n個存儲節點,如何均勻的把各個數據分佈到這n個節點呢?
實現步驟大概分成兩步:
-
通過用戶的key來取一個hash值
-
通過這個hash值來對存儲節點數n進行取模,得出一個index
- 上面這個index就是待存儲的節點標識
Note:本文例子我生成hash值的方式,我採用CRC32的方式。
代碼實現:
/**
* 取模數據分佈算法實現
* @author xingchuan.qxc
*
*/
public class NormalHashNodeServiceImpl implements HashNodeService{
/**
* 存儲節點列表
*/
private List<Node> nodes = new ArrayList<>();
@Override
public void addNode(Node node) {
this.nodes.add(node);
}
@Override
public Node lookupNode(String key) {
long k = hash(key);
int index = (int) (k % nodes.size());
return nodes.get(index);
}
@Override
public Long hash(String key) {
CRC32 crc32 = new CRC32();
crc32.update(key.getBytes());
return crc32.getValue();
}
@Override
public void removeNodeUnexpected(Node node) {
nodes.remove(node);
}
}通過上述例子我們可以看到,lookupNode的時候,是要先去取這個key的CRC32的值,然後對集羣中節點數進行取模得到r,最後返回下標爲r的Node。
測試代碼如下:
HashNodeService nodeService = new NormalHashNodeServiceImpl();
Node addNode1 = new Node("xingchuan.node1", "192.168.0.11");
Node addNode2 = new Node("xingchuan.node2", "192.168.0.12");
Node addNode3 = new Node("xingchuan.node3", "192.168.0.13");
Node addNode4 = new Node("xingchuan.node4", "192.168.0.14");
Node addNode5 = new Node("xingchuan.node5", "192.168.0.15");
Node addNode6 = new Node("xingchuan.node6", "192.168.0.16");
Node addNode7 = new Node("xingchuan.node7", "192.168.0.17");
Node addNode8 = new Node("xingchuan.node8", "192.168.0.18");
nodeService.addNode(addNode1);
nodeService.addNode(addNode2);
nodeService.addNode(addNode3);
nodeService.addNode(addNode4);
nodeService.addNode(addNode5);
nodeService.addNode(addNode6);
nodeService.addNode(addNode7);
nodeService.addNode(addNode8);
//用於檢查數據分佈情況
Map<String, Integer> countmap = new HashMap<>();
Node node = null;
for (int i = 1; i <= 100000; i++) {
String key = String.valueOf(i);
node = nodeService.lookupNode(key);
node.cacheString(key, "TEST_VALUE");
String k = node.getIp();
Integer count = countmap.get(k);
if (count == null) {
count = 1;
countmap.put(k, count);
} else {
count++;
countmap.put(k, count);
}
}
System.out.println("初始化數據分佈情況:" + countmap);運行結果如下:
初始化數據分佈情況:{192.168.0.11=12499, 192.168.0.12=12498, 192.168.0.13=12500, 192.168.0.14=12503, 192.168.0.15=12500, 192.168.0.16=12502, 192.168.0.17=12499, 192.168.0.18=12499}可以看到,每個節點的存儲分佈數量是大致一樣的。
缺點
我們可以很清楚的看到,取模算法是通過數據存儲節點個數來進行運算的,所以,當存儲節點個數變化了,就會造成災難性的緩存失效。
舉例:
初始集羣裏面只有4個存儲節點(Node0,Node1,Node2,Node3),這時候我要存儲id爲1~10的用戶,我可以通過id % 4來運算得出各個ID的分佈節點
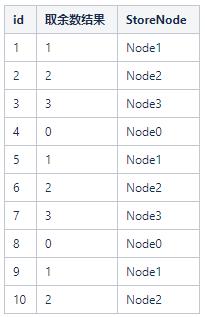
這時候,如果集羣新增一個存儲節點Node4,會發生什麼呢?
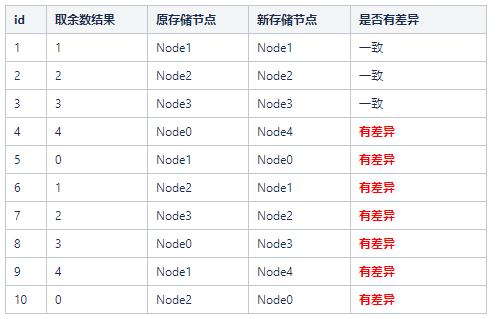
這裏我們會發現,大量的存儲節點的key和原先的對應不上了,這時候我們如果在生產環境,就需要做大量的數據遷移。
刪除一個節點,原理同上,不再贅述。
代碼模擬一個分佈式緩存存儲,使用取模的方式,新增一個節點帶來的問題。測試代碼如下:
HashNodeService nodeService = new NormalHashNodeServiceImpl();
Node addNode1 = new Node("xingchuan.node1", "192.168.0.11");
Node addNode2 = new Node("xingchuan.node2", "192.168.0.12");
Node addNode3 = new Node("xingchuan.node3", "192.168.0.13");
Node addNode4 = new Node("xingchuan.node4", "192.168.0.14");
Node addNode5 = new Node("xingchuan.node5", "192.168.0.15");
Node addNode6 = new Node("xingchuan.node6", "192.168.0.16");
Node addNode7 = new Node("xingchuan.node7", "192.168.0.17");
Node addNode8 = new Node("xingchuan.node8", "192.168.0.18");
nodeService.addNode(addNode1);
nodeService.addNode(addNode2);
nodeService.addNode(addNode3);
nodeService.addNode(addNode4);
nodeService.addNode(addNode5);
nodeService.addNode(addNode6);
nodeService.addNode(addNode7);
nodeService.addNode(addNode8);
//用於檢查數據分佈情況
Map<String, Integer> countmap = new HashMap<>();
Node node = null;
for (int i = 1; i <= 100000; i++) {
String key = String.valueOf(i);
node = nodeService.lookupNode(key);
node.cacheString(key, "TEST_VALUE");
String k = node.getIp();
Integer count = countmap.get(k);
if (count == null) {
count = 1;
countmap.put(k, count);
} else {
count++;
countmap.put(k, count);
}
}
System.out.println("初始化數據分佈情況:" + countmap);
// 正常情況下的去獲取數據,命中率
int hitcount = 0;
for (int i = 1; i <= 100000; i++) {
String key = String.valueOf(i);
node = nodeService.lookupNode(key);
if (node != null) {
String value = node.getCacheValue(key);
if (value != null) {
hitcount++;
}
}
}
double h = Double.parseDouble(String.valueOf(hitcount))/ Double.parseDouble(String.valueOf(100000));
System.out.println("初始化緩存命中率:"+ h);
// 移除一個節點
Node addNode9 = new Node("xingchuan.node0", "192.168.0.19");
nodeService.addNode(addNode9);
hitcount = 0;
for (int i = 1; i <= 100000; i++) {
String key = String.valueOf(i);
node = nodeService.lookupNode(key);
if (node != null) {
String value = node.getCacheValue(key);
if (value != null) {
hitcount++;
}
}
}
h = Double.parseDouble(String.valueOf(hitcount))/ Double.parseDouble(String.valueOf(100000));
System.out.println("增加一個節點後緩存命中率:"+ h);運行結果如下:
初始化數據分佈情況:{192.168.0.11=12499, 192.168.0.12=12498, 192.168.0.13=12500, 192.168.0.14=12503, 192.168.0.15=12500, 192.168.0.16=12502, 192.168.0.17=12499, 192.168.0.18=12499}
初始化緩存命中率:1.0
增加一個節點後緩存命中率:0.11012三、分佈式數據分佈算法——一致性Hash
概述
取模算法的劣勢很明顯,當新增節點和刪除節點的時候,會涉及大量的數據遷移問題。爲了解決這一問題,引入了一致性Hash。
一致性Hash算法的原理很簡單,描述如下:
-
想象有一個巨大的環,比如這個環的值的分佈可以是 0 ~ 4294967296
![一文了解 Consistent Hash]()
-
還是在取模算法中的那個例子,這時候我們假定我們的4個節點通過一些key的hash,分佈在了這個巨大的環上面。
- 用戶數據來了,需要存儲到哪個節點呢?通過key的hash,得出一個值r,順時針找到最近的一個Node節點對應的hash值nodeHash,這次用戶數據也就存儲在對應的這個Node上。
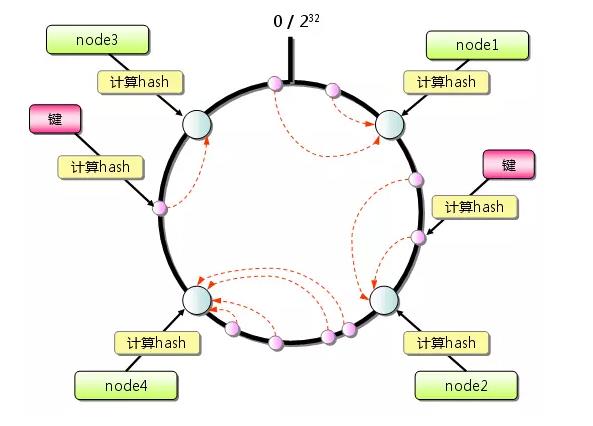
那麼問題來了,如果只有4個節點,可能會造成數據分佈不均勻的情況,舉個例子,上圖中的Node3和Node4離的很近,這時候,Node1的壓力就會很大了。如何解決這個問題呢?虛擬節點能解決這個問題。
什麼是虛擬節點?
簡單說,就是在環上模擬很多個不存在的節點,這時候這些節點是可以儘可能均勻分佈在環上的,在key的hash後,順時針找最近的存儲節點,存儲完成之後,集羣中的數據基本上就分配均勻了。唯一要做的,必須要維護一個虛擬節點到真實節點的關係。
一致性Hash的實現
下面,我們就來通過兩個進階,實現一個一致性Hash。
進階一我們不引入虛擬節點,進階二我們引入虛擬節點
一致性Hash實現,進階一,關鍵代碼如下:
@Override
public void addNode(Node node) {
nodeList.add(node);
long crcKey = hash(node.getIp());
nodeMap.put(crcKey, node);
}
@Override
public Node lookupNode(String key) {
long crcKey = hash(key);
Node node = findValidNode(crcKey);
if(node == null){
return findValidNode(0);
}
return node;
}
/**
* @param crcKey
*/
private Node findValidNode(long crcKey) {
//順時針找到最近的一個節點
Map.Entry<Long,Node> entry = nodeMap.ceilingEntry(crcKey);
if(entry != null){
return entry.getValue();
}
return null;
}
@Override
public Long hash(String key) {
CRC32 crc = new CRC32();
crc.update(key.getBytes());
return crc.getValue();
}這裏我們發現,計算key的hash的算法和取模算法例子裏是一樣的,這不是重點,重點是,在addNode的時候,我們通過ip地址來進行一次hash,並且丟到了一個TreeMap裏面,key是一個Long,是可以自動排序的。
在lookupNode的時候,我們是順時針去找最近的一個節點,如果沒有找到,數據就會存在環上順時針數第一個節點。
測試代碼如下:
和取模算法的一樣,唯一不同的,就是把算法實現的那一行改掉
HashNodeService nodeService = new ConsistentHashNodeServiceImpl();運行結果如下:
初始化數據分佈情況:{192.168.0.11=2495, 192.168.0.12=16732, 192.168.0.13=1849, 192.168.0.14=32116, 192.168.0.15=2729, 192.168.0.16=1965, 192.168.0.17=38413, 192.168.0.18=3701}
初始化緩存命中率:1.0
增加一個節點後緩存命中率:0.97022這裏我們可以看到,數據分佈是不均勻的,同時我們也發現,某一個節點失效了,對於緩存命中率的影響,要比取模算法的場景,要好得多。
一致性Hash的實現,進階2,引入虛擬節點,代碼如圖:
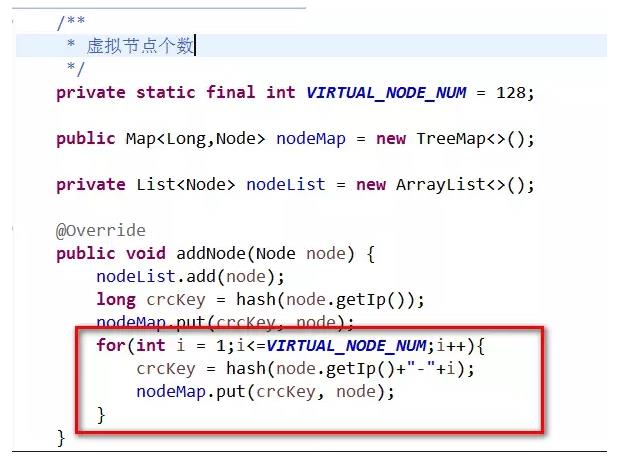
我們在新增節點的時候,每個真實節點對應128個虛擬節點
刪除節點的代碼如下,對應的虛擬節點也一併刪掉。
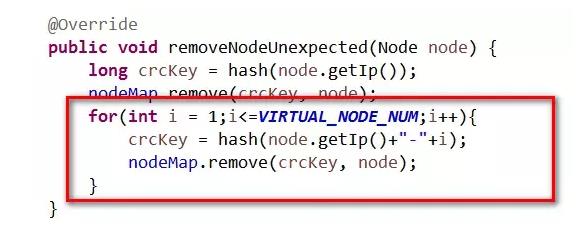
再次測試數據分佈和緩存命中率
測試代碼不變,運行結果如下:
初始化數據分佈情況:{192.168.0.11=11610, 192.168.0.12=14600, 192.168.0.13=13472, 192.168.0.14=11345, 192.168.0.15=11166, 192.168.0.16=12462, 192.168.0.17=14477, 192.168.0.18=10868}
初始化緩存命中率:1.0
增加一個節點後緩存命中率:0.91204這時,我們發現數據分佈的情況已經比上面沒有引入虛擬節點的情況好太多了。
總結
我理解一致性Hash就是爲了解決在分佈式存儲擴容的時候涉及到的數據遷移的問題。
但是,一致性Hash中如果每個節點的數據都很平均,每個都是熱點,在數據遷移的時候,還是會有比較大數據量遷移。