




2019 年的雙十一是螞蟻金服的重要時刻,大規模落地了 Service Mesh 並順利保障雙十一平穩渡過。我們第一時間與這次的落地負責人進行了交流。
採訪的開頭:
花肉:“這次大規模上了 Service Mesh ,雙十一值班感覺是什麼?”
卓與:“Service Mesh 真的穩。”
圖爲卓與 TOP100 北京峯會分享現場圖
落地負責人介紹
Service Mesh 是螞蟻金服下一代架構的核心,今年螞蟻金服大規模的 Service Mesh 落地,我有幸帶領並面對了這個挑戰,並非常平穩的通過了雙十一的大考。
我個人主要專注在微服務領域,在服務註冊與服務框架方向深耕多年,主導過第五代服務註冊中心(SOFARegistry)設計與實施,在微服務的架構演進中持續探索新方向,並在螞蟻金服第五代架構演進中負責內部 Service Mesh 方向的架構設計與落地。
SOFAStack:https://github.com/sofastack
SOFAMosn:https://github.com/sofastack/sofa-mosn
SOFARegistry:https://github.com/sofastack/sofa-registry
Service Mesh 在螞蟻金服
螞蟻金服很早開始關注 Service Mesh,並在 2018 年發起 ServiceMesher 社區,目前已有 4000+ 開發者在社區活躍。在技術應用層面,Service Mesh 的場景已經渡過探索期,今年已經全面進入深水區探索。
2019 年的雙十一是我們的重要時刻,我們進行了大規模的落地,可能是目前業界最大規模的實踐。作爲技術人能面對世界級的流量挑戰,是非常緊張和興奮的。當 Service Mesh 遇到雙十一又會迸發出怎樣的火花?螞蟻金服的 LDC 架構繼續演進的過程中,Service Mesh 要承載起哪方面的責任?我們藉助四個“雙十一考題”一一爲大家揭曉。
Service Mesh 背景知識
Service Mesh 這個概念社區已經火了很久,相關的背景知識從我們的公衆號內可以找到非常多的文章,我在這裏不做過於冗餘的介紹,僅把幾個核心概念統一,便於後續理解。
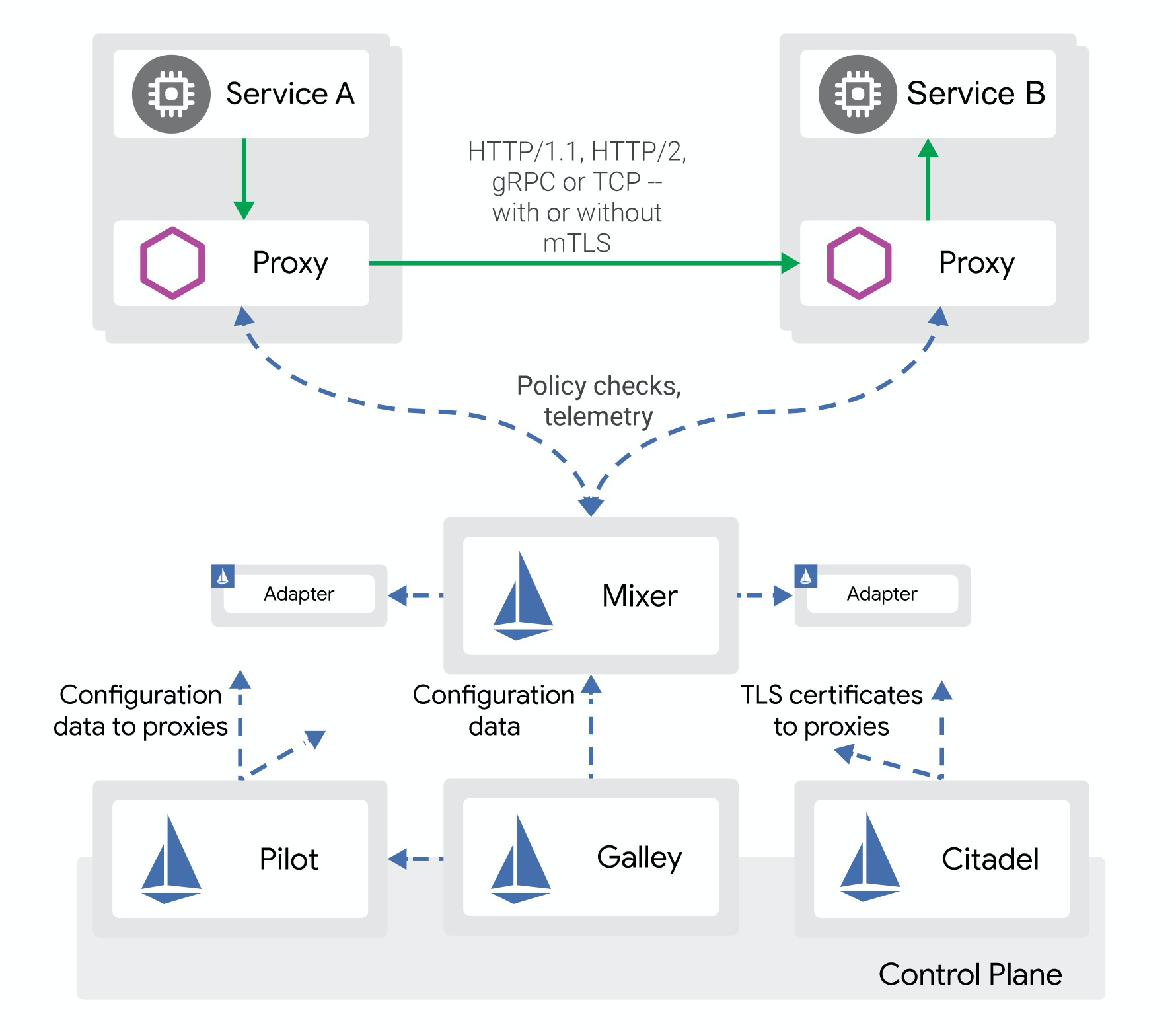
圖1. Service Mesh 開源架構來自 https://istio.io/
Istio 的架構圖上清晰的描述了 Service Mesh 最核心的兩個概念:數據面與控制面。數據面負責做網絡代理,在服務請求的鏈路上做一層攔截與轉發,可以在鏈路中做服務路由、鏈路加密、服務鑑權等,控制面負責做服務發現、服務路由管理、請求度量(放在控制面頗受爭議)等。
Service Mesh 帶來的好處不再贅述,我們來看下螞蟻金服的數據面和控制面產品,如下圖:
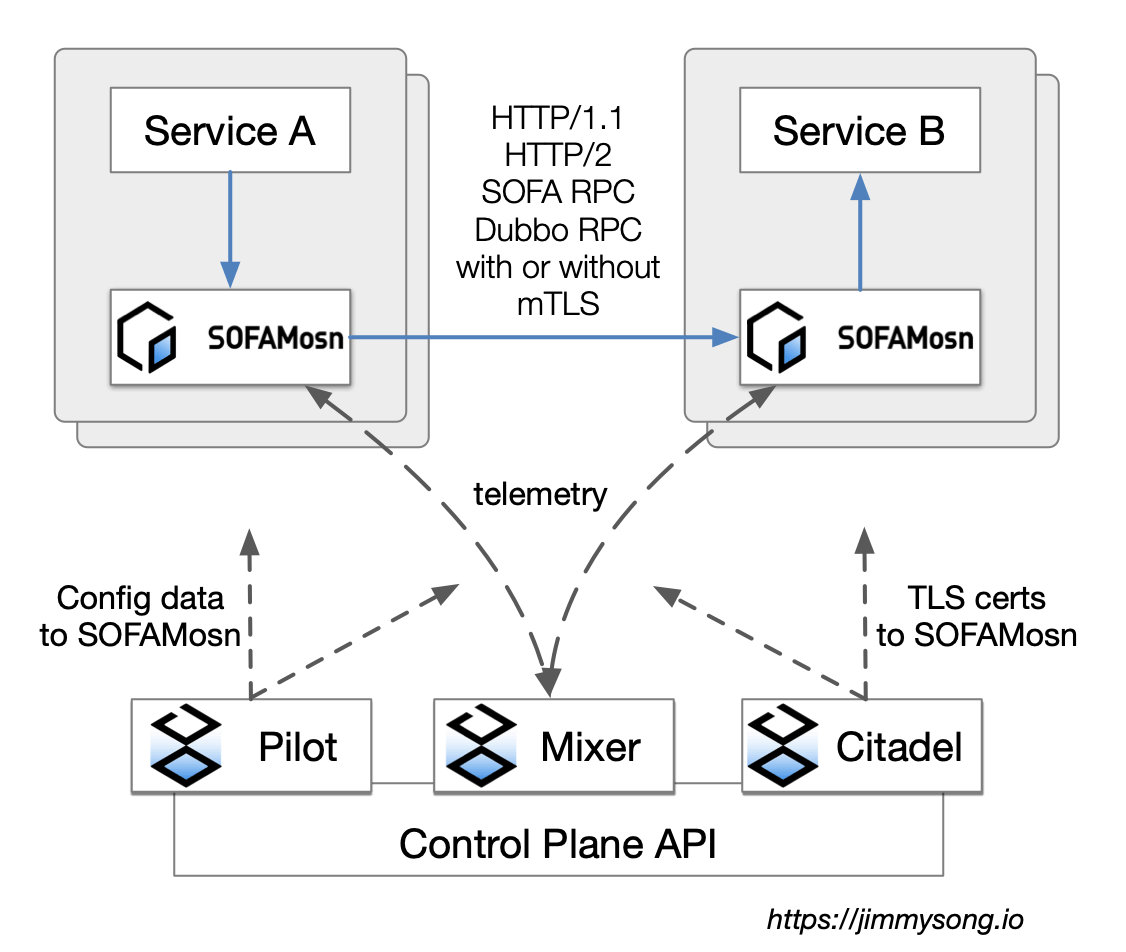
圖2. 螞蟻金服 Service Mesh 示意架構
數據面:SOFAMosn。螞蟻金服使用 Golang 研發的高性能網絡代理,作爲 Service Mesh 的數據面,承載了螞蟻金服雙十一海量的核心應用流量。
控制面:SOFAMesh。Istio 改造版,落地過程中精簡爲 Pilot 和 Citadel,Mixer 直接集成在數據面中避免多一跳的開銷。
2019 Service Mesh 雙十一大考揭祕
雙十一 SOFAMosn 與 SOFAMesh 經歷海量規模大考,順利保障雙十一平穩渡過。今年雙十一螞蟻金服的百十多個核心應用全面接入 SOFAMosn,生產 Mesh 化容器幾十萬臺,雙十一峯值 SOFAMosn 承載數據規模數千萬 QPS,SOFAMosn 轉發平均處理耗時 0.2ms。
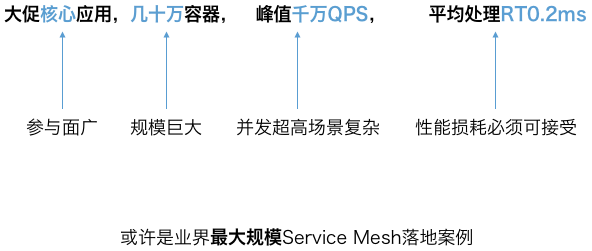
圖3. 雙十一落地數據
在如此大規模的接入場景下,我們面對的是極端複雜的場景,同時需要多方全力合作,更要保障數據面的性能穩定性滿足大促訴求,整個過程極具挑戰。下面我們將從幾個方面來分享下我們在這個歷程中遇到的問題及解決方案。
雙十一考題
如何讓 Service Mesh 發揮最大的業務價值?
如何達成幾十萬容器接入 SOFAMosn 的目標?
如何處理幾十萬容器 SOFAMosn 的版本升級問題?
如何保障 Service Mesh 的性能與穩定性達標?
落地架構
爲了更加方便的理解以上問題的解決與後續介紹中可能涉及的術語等,我們先來看下 Service Mesh 落地的主要架構:
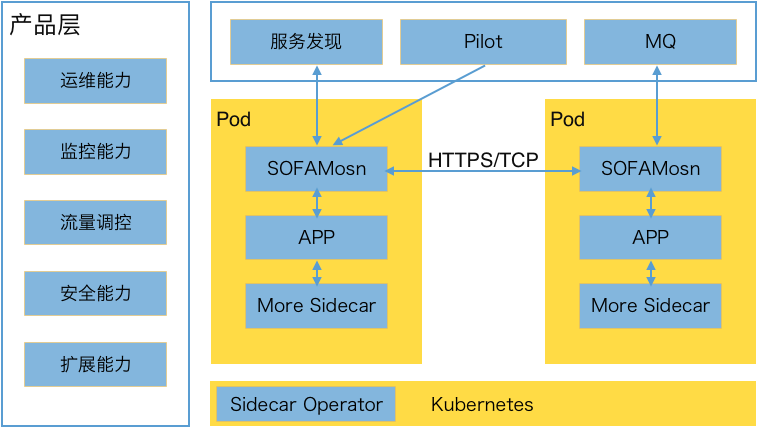
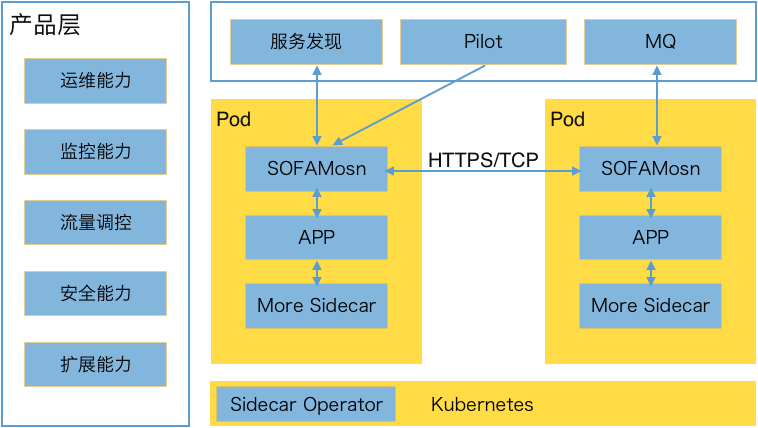
圖4. Service Mesh 落地架構
以上架構圖中主要分幾部分:
數據面:藉助 Kubernetes 中的 Pod 模型,SOFAMosn 以獨立鏡像和 App 鏡像共同編排在同一個 Pod 內,共享相同的 Network Namespace、CPU、Memory,接入 SOFAMosn 後所有的 App RPC 流量、消息流量均不在直接對外,而是直接和 SOFAMosn 交互,由 SOFAMosn 直接對接服務註冊中心做服務發現,對接 Pilot 做配置下發,對接 MQ Server 做消息收發等;
控制面:由 Pilot、Citadel 和服務註冊中心等組件組成,負責服務地址下發、服務路由下發、證書下發等;
底層支撐:Sidecar 的接入與升級等均依賴 Kubernetes 能力,通過 webhook 做 Sidecar 的注入,通過 Operator 做 Sidecar 的版本升級等,相關運維動作均離不開底層的支撐;
產品層:結合底層提供的原子能力做運維能力封裝,監控對接,採集 Sidecar 暴露的 Metrics 數據做監控與預警,流量調控,安全等產品化能力;
螞蟻金服的答卷
1. 如何讓 Service Mesh 發揮最大的業務價值?
作爲一個技術人,我們非常堅持不要爲了技術革新本身去做技術革新,一定要讓技術幫助業務,用技術驅動業務。這幾年隨着大家消費習慣以及網絡行爲的改變,雙十一面對的業務場景遠比想象中複雜。舉個例子大家感受下,大家有沒有發現你的女友或者老婆每天對着李佳琦的淘寶直播購物,主播們不斷的、實時的紅包、上新等等,帶來了遠比秒殺更復雜的業務場景和體量。大促的模式也更加豐富,不同場景下的大促涉及的應用是不同的,每一類應用在應對獨特的洪峯時都需要有足夠的資源。
假如運營同學在不同時間點設計了兩種活動,兩種活動分別會對應兩類不同的應用,如果這兩類應用都在大促前準備充足的資源自然是輕鬆渡過大促峯值,但大促洪峯時間短暫,大量的資源投入有很長一段時間都處於空閒狀態,這自然不符合技術人的追求。
那麼如何在不增加資源的場景下渡過各種大促呢?
核心問題就是如何在足夠短的時間內做到大規模資源騰挪,讓一批機器資源可以在不同時間點承載起不同的大促洪峯。
面對這樣的挑戰,我們會有怎樣的解法呢?
Service Mesh 618 大促落地試點時,我們有介紹到爲什麼要做這個事情,核心價值是業務與基礎設施解耦,雙方可以並行發展,快速往前走。那麼並行發展究竟能爲業務帶來哪些實際的價值?除了降低基礎組件的升級難度之外,我們還在資源調度方向做了以下探索:
1.1 騰挪調度
說到資源調度,最簡單的自然是直接做資源騰挪,比如大促A峯值過後,大促A對應的應用通過縮容把資源釋放出來,大促B對應的應用再去申請資源做擴容,這種方式非常簡單,難點在於當資源規模非常龐大時,縮容擴容的效率極低,應用需要把資源申請出來並啓動應用,耗時很長,假如多個大促之間的時間間隔很短,騰挪需要的耗時極有可能超過大促時間間隔,這種調度方案已不能滿足雙十一多種大促的訴求。
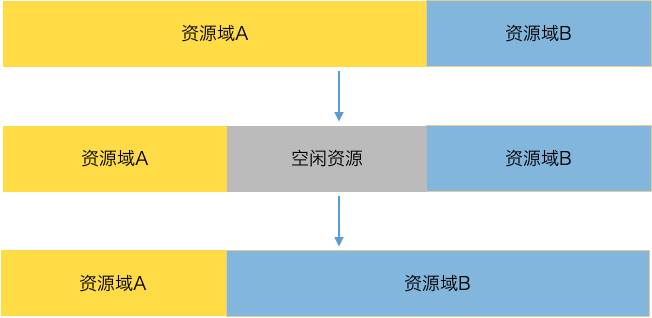
圖5. 騰挪調度
1.2 分時調度
騰挪調度最大的問題是應用需要冷啓動,冷啓動本身的耗時,加上冷啓動後預熱需要的耗時,對整個騰挪時間影響極大。假如應用不需要啓動就能完成資源騰挪,整個調度速度將會加快很多。基於應用不需要重新啓動即可完成資源騰挪的思路,我們提出了分時調度的方案:分時調度會通過超賣的機制申請出足夠的容器。
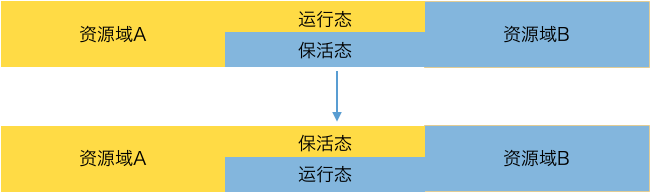
圖6. 分時調度
我們把資源池中的應用容器分爲兩種狀態(4C8G 規格爲例):
運行態:運行態的應用處於全速運行的狀態(資源可使用到 4C8G),它們可以使用充足的資源全速運行,承載 100% 的流量;
保活態:保活態的應用處於低速運行的狀態(資源可使用到 1C2G),它們僅可使用受限的資源低速運行,承載 1% 的流量,剩餘 99% 的流量由 SOFAMosn 轉發給運行態節點;
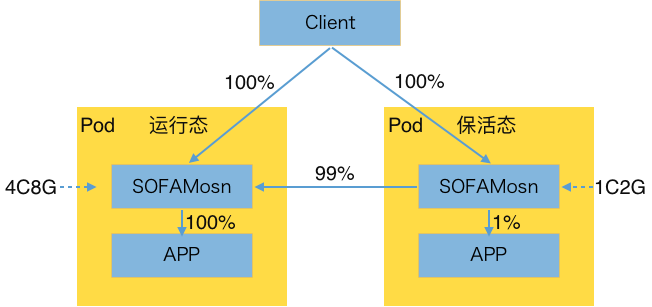
圖7. 保活態流量轉發
保活態和運行態可以快速切換,切換時僅需要做 JVM 內存 Swap 以及基於 SOFAMosn 的流量比例切換,即可快速做到大促A到大促B間資源的快速切換。
SOFAMosn 流量比例切換的能力是分時調度中非常核心的一部分,有了這份流量轉發,Java 內存 Swap 後纔可以降低流量以保持各種連接活性,如應用與 DB 間的連接活性等。通過分時調度的技術手段,我們達成了雙十一多種大促不加機器的目標,這個目標達成後能節省的成本是極大的,這也是 Service Mesh 化後將能帶來的重要業務價值。
每個公司落地 Service Mesh 的路徑不盡相同,這裏給出的建議依然是不要爲了技術革新本身去做技術革新,多挖掘 Service Mesh 化後能給當前業務帶來的實際價值,並以此價值爲抓手設定目標,逐步落地。
2. 如何達成幾十萬容器接入 SOFAMosn 的目標?
說到數據面的接入,瞭解社區方案的同學應該會聯想到 Istio 的 Sidecar Injector。Istio 通過在 Kubernetes 中集成 Sidecar Injector 來注入 Envoy。標準的 Kubernetes 更新行爲也是 Pod 的重建,創建新 Pod 銷燬舊 Pod,更新過程中 IP 會改變等。
在螞蟻金服的場景下,或者說在國內較多公司使用 Kubernetes 做內部運維體系升級時,都會走先替換底層資源調度再替換上層 Paas 產品的路子,因爲已有的 Paas 是客觀存在的,Paas 的能力也非一朝一夕可以直接雲原生化的,那麼先用 Kubernetes 替換掉底層的資源調度的路子就變的順理成章了。這條路子上還涉及非 Kubernetes 體系和 Kubernetes 體系的兼容性,如保持 IP 地址不變的 Pod 更新能力,有了這些能力對上層 Paas 來講,運維體系和運維傳統 VM 的場景類似,只是發佈部署可以由上傳 zip 包解壓發佈變成鏡像化發佈,同時在更多高階場景可以藉助 Operator 實現更加面向終態的運維模式。
我們上面介紹 圖4. Service Mesh 落地架構 時,有看到 SOFAMosn 和應用 App 編排在同一個 Pod 內,那麼一個應用要接入 SOFAMosn 首先要先完成鏡像化,可以被 Kubernetes 管理起來,然後是 SOFAMosn 的注入,注入後還需要可原地更新(InPlace Update)。
2.1 替換接入
在我們落地的初期,SOFAMosn 的接入方式主要是替換接入。替換接入就是指定某個應用做 SOFAMosn 接入時,我們會通過創建新 Pod,然後在創建的同時注入 SOFAMosn,新 Pod 創建完成後縮容舊容器。爲什麼說是縮容舊容器而不是說縮容舊 Pod,是因爲接入早期,我們內部的調度系統 Sigma(螞蟻金服版 Kubernetes)還處於底層逐步替換的過程中,有部分容器還是非 Kubernetes 管理的狀態,這部分容器沒有 Pod 的概念。
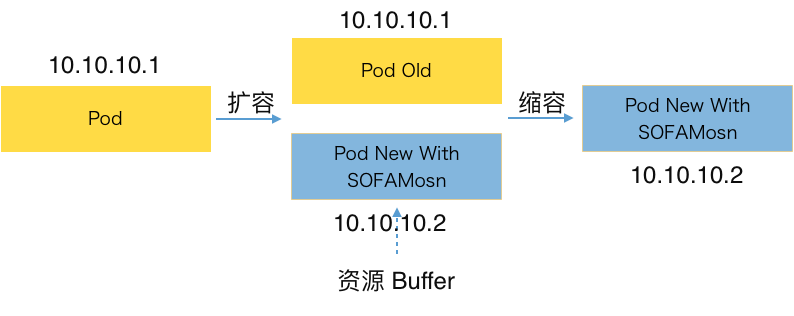
圖8. 替換接入
替換接入最大的問題就是需要充足的資源 Buffer,否則新的 Pod 調度不出來,接入進度便會受阻,而且整個接入週期加上資源申請,以及資源申請出後附帶的一系列周邊配套系統的數據初始化等,週期較長、依賴較多,所以這個能力是很難在短時間內滿足我們幾十萬容器的接入進度目標的。
2.2 原地接入
基於替換接入的已知問題,我們嘗試結合資源調度層的改造,將接入方案做了大幅簡化,並提供了原地接入能力。原地接入會首先把不在 Kubernetes 集羣中管理的容器原地替換爲由 Kubernetes 集羣管理的 Pod,然後通過 Pod Upgrade 時直接新增 Sidecar 的方式將 SOFAMosn 注入 Pod,省去了擴容的資源 Buffer 開銷,將整個接入過程變的簡單順滑。

圖9. 原地接入
原地接入打破了僅在創建 Pod 時注入的原則,帶來了更高的複雜度。如原 Pod 擁有 4C8G 的資源,注入 SOFAMosn 後不能新增資源佔用,如果新增了資源佔用那麼這部分資源就不受容量管控系統管理,所以我們將 App Container 和 SOFAMosn Container 的資源做了共享,SOFAMosn 和 APP 公用 4C 的 CPU 額度,搶佔比相同。內存方面 SOFAMosn 可用內存 Limit 爲 App 的 1/4,對於 8G 內存來講,SOFAMosn 可見 2G,應用依然可見 8G,當應用使用內存超過 6G 時,由 OOM-Killer 優先 kill SOFAMosn 來保障應用可繼續申請到內存資源。
以上 CPU 搶佔比和 Mem limit 比例均爲實際壓測調整比例,最初我們嘗試過 SOFAMosn CPU 佔比爲應用的 1/4,Mem 爲應用的 1/16,這在小流量的應用下可正常工作,但是遇到核心應用,連接數上萬的場景下,內存和 CPU 都比較吃緊,特別是 CPU 爭搶能力弱於應用的場景下,會導致 RT 變長,間接影響應用。在實際運行的穩定性保障上通過各種參數調整和驗證,最後得出 SOFAMosn 與 APP 1:1 共享 CPU,Mem limit 限制爲應用 Mem 1/4 的比例。

圖10. 空中加油
通過原地注入的能力,我們實現了更加平滑的接入方式,極大加速了海量容器接入 SOFAMosn 的進程。
3. 如何處理幾十萬容器 SOFAMosn 的版本升級問題?
海量容器接入 SOFAMosn 之後,一個更大的挑戰是如何快速的升級 SOFAMosn 版本。我們一直強調 Service Mesh 帶來的核心價值是業務與基礎設施層的解耦,讓雙方可以更加快捷的向前走,但假如沒有快速升級的能力,那麼這個快速往前走便成了一句空話,而且任何軟件都可能引入 Bug,我們也需要一個快速的機制在 Bug 修復時可以更加快速的升級或回滾。SOFAMosn 的升級能力也從有感升級進階到無感升級。
3.1 有感升級

圖11. 有感升級
有感升級是一次 Pod 的 InPlace Update,這個升級過程中,會關閉此 Pod 的流量,然後做容器 Upgrade,容器 Upgrade 的時候,應用和 SOFAMosn 均會做更新、啓動,並在升級完成後打開流量。這個過程的耗時主要取決於應用啓動耗時,如一些龐大的應用啓動耗時可能達 2~5分鐘之久,所以升級週期也會被拉長,並且應用能感知到流量的開關。所以這種方式我們稱之爲有感升級,這種方式的優點是升級過程中無流量,穩定性更高。
3.2 無感升級
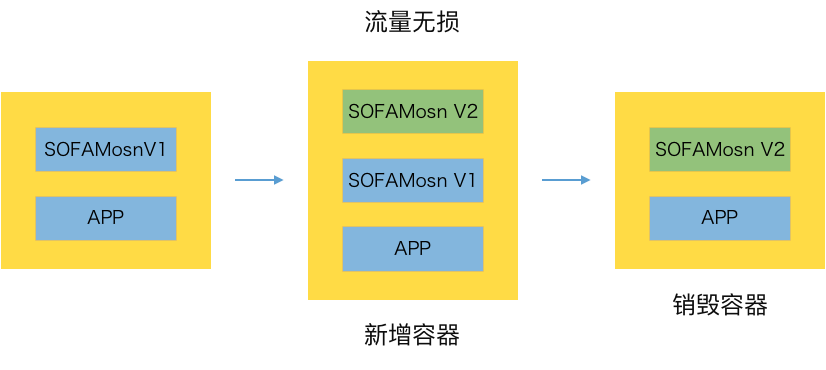
圖12. 無感升級
無感升級我們又稱之爲平滑升級,整個升級過程中不會暫停流量,SOFAMosn 的版本直接通過熱更新技術,動態接管舊版本的流量,並完成升級,整個過程中 APP Container 無感知,所以可以稱爲無感升級。這種升級方式減少了應用重啓的耗時,整個升級時長消耗主要在新舊 SOFAMosn 版本之間的連接遷移,關於無感升級的實現細節,可以參考我 2019 年上半年在 GIAC 上的分享:《螞蟻金服 Service Mesh 落地實踐與挑戰 | GIAC 實錄》
3.3 無人值守
有了快速升級的能力,還需要有在升級過程中的風險攔截,這樣才能放心大膽的做版本升級。基於無人值守的理念,我們在 SOFAMosn 的升級前後基於 Metrics 度量指標判斷升級前後的流量變化、成功率變化以及業務指標的變化等,實現及時的變更風險識別與阻斷,通過這種方式真正做到了放心大膽的快速升級。
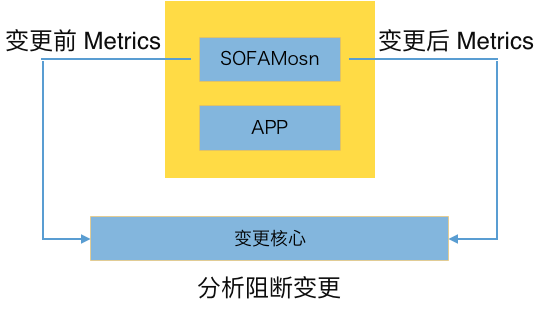
圖13. 無人值守
4. 如何保障 Service Mesh 的性能與穩定性達標?
SOFAMosn 在雙十一的表現穩定,峯值千萬級 QPS 經過 SOFAMosn,SOFAMosn 內部處理消耗平均 RT 低於 0.2ms。我們在性能和穩定性上經過多重優化改進才最終能達成以上成果,這其中離不開生產的持續壓測、打磨,以下是我們在性能和穩定性方面的一些改進點,僅供參考:
4.1 性能優化
CPU 優化
Golang writev 優化:多個包拼裝一次寫,降低 syscall 調用。我們在 go 1.9 的時候發現 writev 有內存泄露的bug,內部使用的目前是 patch 了 writev bugfix 的 go 1.12。writev bugfix 已經集成在 go 1.13 中。
詳情見我們當時給go 提交的PR: https://github.com/golang/go/pull/32138
內存優化
內存複用:報文直接解析可能會產生大量臨時對象,SOFAMosn 通過直接複用報文字節的方式,將必要的信息直接通過 unsafe.Pointer 指向報文的指定位置來避免臨時對象的產生。
延遲優化
協議升級:快速讀取 header:TR 協議請求頭和 Body 均爲 hessian 序列化,性能損耗較大。而 Bolt 協議中 Header 是一個扁平化map,解析性能損耗小。升級應用走 Bolt 協議來提升性能。
路由緩存:內部路由的複雜性(一筆請求經常需要走多種路由策略最終確定路由結果目標),通過對相同條件的路由結果做秒級緩存,我們成功將某核心鏈路的全鏈路 RT 降低 7%。
4.2 穩定性建設
Pod 級別 CPU Mem 限額配置,Sidecar 與 APP 共享 CPU Mem;
運維周邊建設:
原地注入;
平滑升級;
Sidecar 重啓;
監控建設:
系統指標:CPU、Mem、TCP、Disk IO;
Go 指標:Processor、Goroutines、Memstats、GC;
RPC 指標:QPS、RT、連接數;
旁路增強:
服務註冊中心性能提升;
回顧
如何讓 Service Mesh 發揮最大的業務價值?保證效率增加成本不變
如何達成幾十萬容器接入 SOFAMosn 的目標?降低接入成本
如何處理幾十萬容器 SOFAMosn 的版本升級問題?降低應用感知
如何保障 Service Mesh 的性能與穩定性達標?性能與穩定性層層優化
通過對以上問題的深入解讀,大家可以瞭解到螞蟻金服的 Service Mesh 爲何可以穩定支撐雙十一,也期望能爲大家落地 Service Mesh 帶來一些不一樣的思考。更多 Service Mesh 相關內容敬請關注我們的公衆號“金融級分佈式架構”來了解更多。