




本人免費整理了Java高級資料,涵蓋了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo高併發分佈式等教程,一共30G,需要自己領取。
傳送門:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q
1. CopyOnWriteArrayList的簡介
Java學習者都清楚ArrayList並不是線程安全的,在讀線程在讀取ArrayList的時候如果有寫線程在寫數據的時候,基於fast-fail機制,會拋出ConcurrentModificationException異常,也就是說ArrayList並不是一個線程安全的容器,當然您可以用Vector,或者使用Collections的靜態方法將ArrayList包裝成一個線程安全的類,但是這些方式都是採用java關鍵字synchronzied對方法進行修飾,利用獨佔式鎖來保證線程安全的。但是,由於獨佔式鎖在同一時刻只有一個線程能夠獲取到對象監視器,很顯然這種方式效率並不是太高。
回到業務場景中,有很多業務往往是讀多寫少的,比如系統配置的信息,除了在初始進行系統配置的時候需要寫入數據,其他大部分時刻其他模塊之後對系統信息只需要進行讀取,又比如白名單,黑名單等配置,只需要讀取名單配置然後檢測當前用戶是否在該配置範圍以內。
類似的還有很多業務場景,它們都是屬於讀多寫少的場景。如果在這種情況用到上述的方法,使用Vector,Collections轉換的這些方式是不合理的,因爲儘管多個讀線程從同一個數據容器中讀取數據,但是讀線程對數據容器的數據並不會發生發生修改。很自然而然的我們會聯想到ReenTrantReadWriteLock,通過讀寫分離的思想,使得讀讀之間不會阻塞,無疑如果一個list能夠做到被多個讀線程讀取的話,性能會大大提升不少。
但是,如果僅僅是將list通過讀寫鎖(ReentrantReadWriteLock)進行再一次封裝的話,由於讀寫鎖的特性,當寫鎖被寫線程獲取後,讀寫線程都會被阻塞。
如果僅僅使用讀寫鎖對list進行封裝的話,這裏仍然存在讀線程在讀數據的時候被阻塞的情況,如果想list的讀效率更高的話,這裏就是我們的突破口,如果我們保證讀線程無論什麼時候都不被阻塞,效率豈不是會更高?
Doug Lea大師就爲我們提供CopyOnWriteArrayList容器可以保證線程安全,保證讀讀之間在任何時候都不會被阻塞,CopyOnWriteArrayList也被廣泛應用於很多業務場景之中,CopyOnWriteArrayList值得被我們好好認識一番。
2. COW的設計思想
回到上面所說的,如果簡單的使用讀寫鎖的話,在寫鎖被獲取之後,讀寫線程被阻塞,只有當寫鎖被釋放後讀線程纔有機會獲取到鎖從而讀到最新的數據,站在讀線程的角度來看,即讀線程任何時候都是獲取到最新的數據,滿足數據實時性。既然我們說到要進行優化,必然有trade-off,我們就可以犧牲數據實時性滿足數據的最終一致性即可。而CopyOnWriteArrayList就是通過Copy-On-Write(COW),即寫時複製的思想來通過延時更新的策略來實現數據的最終一致性,並且能夠保證讀線程間不阻塞。
COW通俗的理解是當我們往一個容器添加元素的時候,不直接往當前容器添加,而是先將當前容器進行Copy,複製出一個新的容器,然後新的容器裏添加元素,添加完元素之後,再將原容器的引用指向新的容器。對CopyOnWrite容器進行併發的讀的時候,不需要加鎖,因爲當前容器不會添加任何元素。所以CopyOnWrite容器也是一種讀寫分離的思想,延時更新的策略是通過在寫的時候針對的是不同的數據容器來實現的,放棄數據實時性達到數據的最終一致性。
3. CopyOnWriteArrayList的實現原理
現在我們來通過看源碼的方式來理解CopyOnWriteArrayList,實際上CopyOnWriteArrayList內部維護的就是一個數組
/** The array, accessed only via getArray/setArray. */ private transient volatile Object[] array;
並且該數組引用是被volatile修飾,注意這裏僅僅是修飾的是數組引用,其中另有玄機,稍後揭曉。關於volatile很重要的一條性質是它能夠夠保證可見性,關於volatile的詳細講解可以看。對list來說,我們自然而然最關心的就是讀寫的時候,分別爲get和add方法的實現。
3.1 get方法實現原理
get方法的源碼爲:
public E get(int index) {
return get(getArray(), index);
}
/**
* Gets the array. Non-private so as to also be accessible
* from CopyOnWriteArraySet class.
*/
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}可以看出來get方法實現非常簡單,幾乎就是一個“單線程”程序,沒有對多線程添加任何的線程安全控制,也沒有加鎖也沒有CAS操作等等,原因是,所有的讀線程只是會讀取數據容器中的數據,並不會進行修改。
3.2 add方法實現原理
再來看下如何進行添加數據的?add方法的源碼爲:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
//1\. 使用Lock,保證寫線程在同一時刻只有一個
lock.lock();
try {
//2\. 獲取舊數組引用
Object[] elements = getArray();
int len = elements.length;
//3\. 創建新的數組,並將舊數組的數據複製到新數組中
Object[] newElements = Arrays.copyOf(elements, len + 1);
//4\. 往新數組中添加新的數據
newElements[len] = e;
//5\. 將舊數組引用指向新的數組
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}add方法的邏輯也比較容易理解,請看上面的註釋。需要注意這麼幾點:
採用ReentrantLock,保證同一時刻只有一個寫線程正在進行數組的複製,否則的話內存中會有多份被複制的數據;
前面說過數組引用是volatile修飾的,因此將舊的數組引用指向新的數組,根據volatile的happens-before規則,寫線程對數組引用的修改對讀線程是可見的。
由於在寫數據的時候,是在新的數組中插入數據的,從而保證讀寫實在兩個不同的數據容器中進行操作。
4. 總結
我們知道COW和讀寫鎖都是通過讀寫分離的思想實現的,但兩者還是有些不同,可以進行比較:
COW vs 讀寫鎖
相同點:1. 兩者都是通過讀寫分離的思想實現;2.讀線程間是互不阻塞的
不同點:對讀線程而言,爲了實現數據實時性,在寫鎖被獲取後,讀線程會等待或者當讀鎖被獲取後,寫線程會等待,從而解決“髒讀”等問題。也就是說如果使用讀寫鎖依然會出現讀線程阻塞等待的情況。而COW則完全放開了犧牲數據實時性而保證數據最終一致性,即讀線程對數據的更新是延時感知的,因此讀線程不會存在等待的情況。
對這一點從文字上還是很難理解,我們來通過debug看一下,add方法核心代碼爲:
1.Object[] elements = getArray(); 2.int len = elements.length; 3.Object[] newElements = Arrays.copyOf(elements, len + 1); 4.newElements[len] = e; 5.setArray(newElements);
假設COW的變化如下圖所示:
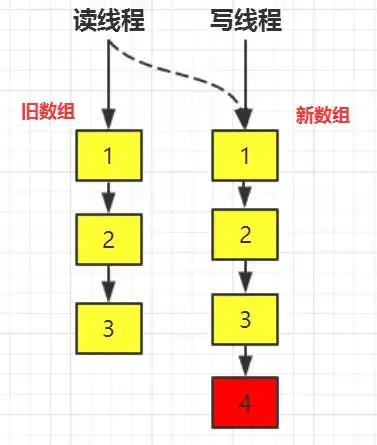
數組中已有數據1,2,3,現在寫線程想往數組中添加數據4,我們在第5行處打上斷點,讓寫線程暫停。讀線程依然會“不受影響”的能從數組中讀取數據,可是還是隻能讀到1,2,3。如果讀線程能夠立即讀到新添加的數據的話就叫做能保證數據實時性。當對第5行的斷點放開後,讀線程才能感知到數據變化,讀到完整的數據1,2,3,4,而保證數據最終一致性,儘管有可能中間間隔了好幾秒才感知到。
這裏還有這樣一個問題: 爲什麼需要複製呢? 如果將array 數組設定爲volitile的, 對volatile變量寫happens-before讀,讀線程不是能夠感知到volatile變量的變化。
原因是,這裏volatile的修飾的僅僅只是數組引用,數組中的元素的修改是不能保證可見性的。因此COW採用的是新舊兩個數據容器,通過第5行代碼將數組引用指向新的數組。
這也是爲什麼concurrentHashMap只具有弱一致性的原因,關於concurrentHashMap的弱一致性可以。
COW的缺點
CopyOnWrite容器有很多優點,但是同時也存在兩個問題,即內存佔用問題和數據一致性問題。所以在開發的時候需要注意一下。
內存佔用問題:因爲CopyOnWrite的寫時複製機制,所以在進行寫操作的時候,內存裏會同時駐紮兩個對 象的內存,舊的對象和新寫入的對象(注意:在複製的時候只是複製容器裏的引用,只是在寫的時候會創建新對 象添加到新容器裏,而舊容器的對象還在使用,所以有兩份對象內存)。如果這些對象佔用的內存比較大,比 如說200M左右,那麼再寫入100M數據進去,內存就會佔用300M,那麼這個時候很有可能造成頻繁的minor GC和major GC。
數據一致性問題:CopyOnWrite容器只能保證數據的最終一致性,不能保證數據的實時一致性。所以如果你希望寫入的的數據,馬上能讀到,請不要使用CopyOnWrite容器。