




一、前言
經過超過半年的研發,螞蟻金服在今年完成了 Kubernetes 的全面落地,並使得核心鏈路100% 運行在 Kubernetes。到今年雙十一,螞蟻金服內部通過 Kubernetes 管理了數以萬計的機器以及數十萬的業務實例,超過90%的業務已經平穩運行在 Kubernetes 上。整個技術切換過程平穩透明,爲雲原生的資源基礎設施演進邁好了關鍵的一步。
本文主要介紹 Kubernetes 在螞蟻金服的使用情況,雙十一大促對 Kubernetes 帶來史無前例的挑戰以及我們的最佳實踐。希望通過分享這些我們在實踐過程中的思考,讓大家在應用 Kubernetes 時能夠更加輕鬆自如。
二、螞蟻金服的 Kubernetes 現狀
2.1 發展歷程與落地規模
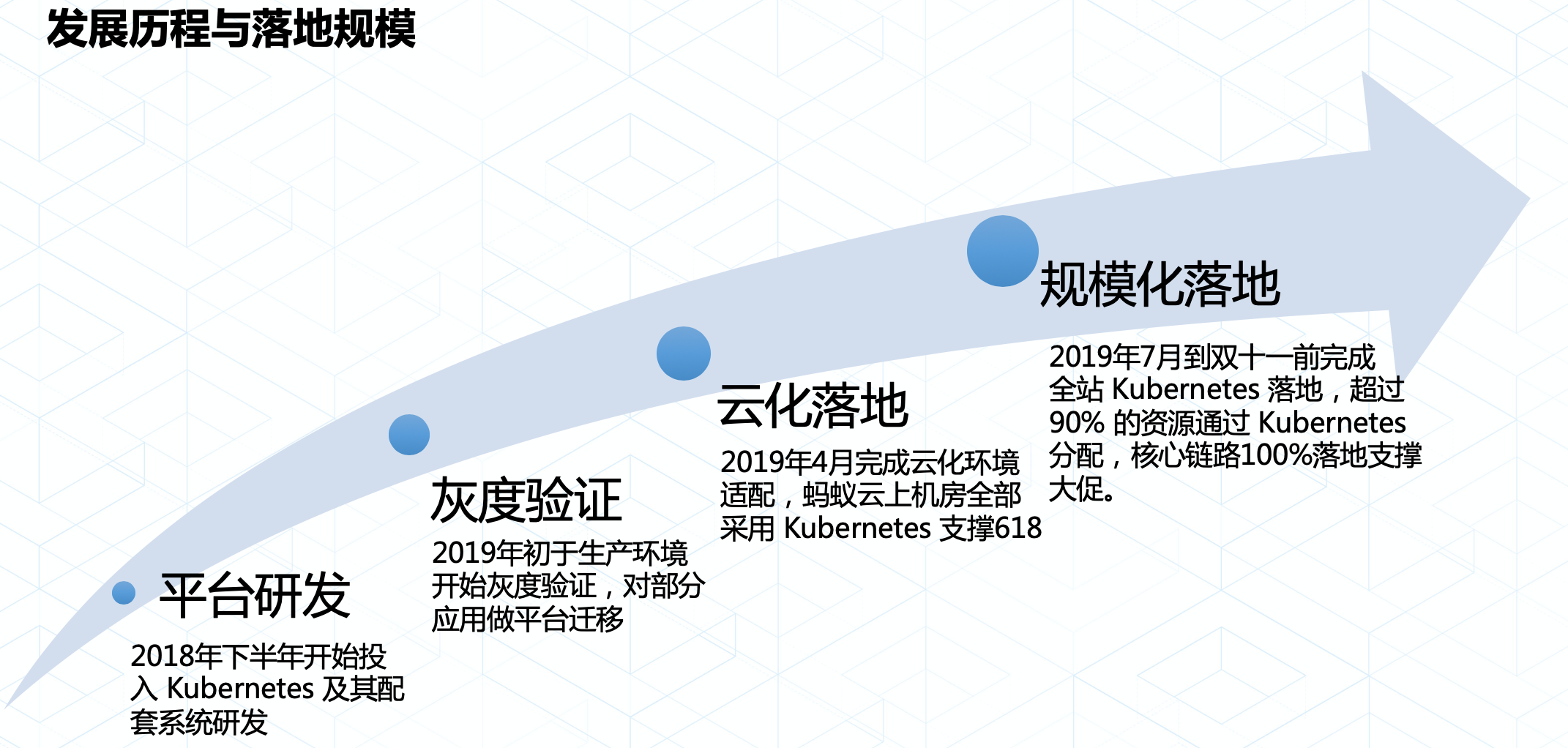 Kubernetes 在螞蟻金服落地主要經歷了四個階段:
Kubernetes 在螞蟻金服落地主要經歷了四個階段:
平臺研發階段:2018年下半年螞蟻金服和阿里集團共同投入 Kubernetes 技術生態的研發,力求通過 Kubernetes 替換內部自研平臺;
灰度驗證:2019年初 Kubernetes 在螞蟻金服灰度落地,通過對部分資源集羣進行架構升級以及灰度替換生產實例兩種方式,讓 Kubernetes 得以小規模的驗證;
雲化落地(螞蟻金服內部基礎設施雲原生化):2019年4月螞蟻金服內部完成 Kubernetes 適配雲化環境的目標,並於618之前完成雲化機房100% 使用 Kubernetes 的目標,這是 Kubernetes 第一次在螞蟻金服內部得到規模化的驗證;
規模化落地:2019年618之後,螞蟻金服內部開始全面推動 Kubernetes 落地,在大促之前完成核心鏈路100% 運行在 Kubernetes的目標,並完美支撐了雙十一大考。
2.2 統一資源調度平臺
Kubernetes 承載了螞蟻金服在雲原生時代對資源調度的技術目標:統一資源調度。通過統一資源調度,可以有效提升資源利用率,極大的節省資源成本。要做到統一調度,關鍵在於從資源層面將各個二層平臺的調度能力下沉,讓資源在 Kubernetes 統一分配。
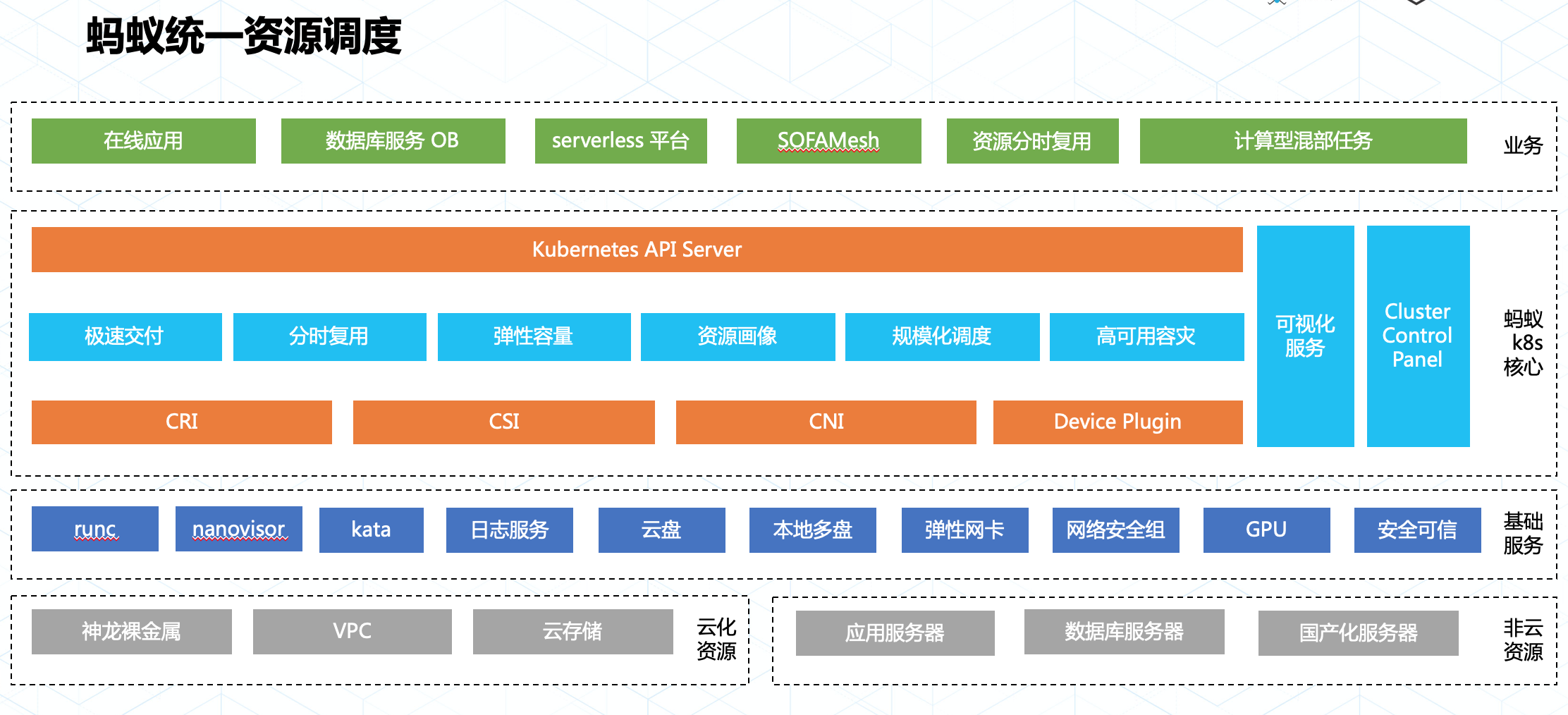
螞蟻金服在落地 Kubernetes 實現統一調度目標時遵循了標準化的擴展方式:
一切業務擴展均圍繞 Kubernetes APIServer,通過CRD + Operator方式完成業務功能的適配和擴展;
基礎服務通過 Node 層定義的資源接口完成個性化適配,有益於形成資源接入的最佳實踐。
得益於持續的標準化工作,我們在落地 Kubernetes 的大半年內應用了多項技術,包含安全容器,統一日誌,GPU 精細調度,網絡安全隔離及安全可信計算等,並通過 Kubernetes 統一使用和管理這些資源服務了大量在線業務以及計算任務型業務。
三、雙十一 Kubernetes 實踐
下面我們通過以下幾種場景介紹螞蟻金服內部是如何使用 Kubernetes,以及在此過程中我們面對的挑戰和實踐之路。
3.1 資源分時複用
在大促過程中,不同業務域的洪峯流量通常都是在不同時間段來臨,而應對這些不同時間到來的業務流量往往都需要大量的額外計算資源做保障。在以往的幾次活動中,我們嘗試了通過應用快速騰挪的方式來做到資源上的分時複用,但是服務實例上下線需要預熱,騰挪耗時不可控,大規模調度的穩定性等因素都影響了最終騰挪方案的實踐效果。
今年雙十一我們採用了資源共享調度加精細化切流的技術以達到資源分時利用的目標,爲了達到資源充分利用和極速切換的目標,我們在以下方面做了增強:
在內部的調度系統引入了聯合資源管理(Union-Resource Management),他可以將波峯波谷不重疊的業務實例擺放在相同的資源集合內,達到最大化的資源利用。
研發了一套融合資源更新,流量切換及風險控制的應用分時複用平臺,通過該平臺SRE可以快速穩定的完成資源切換以應對不同的業務洪峯。
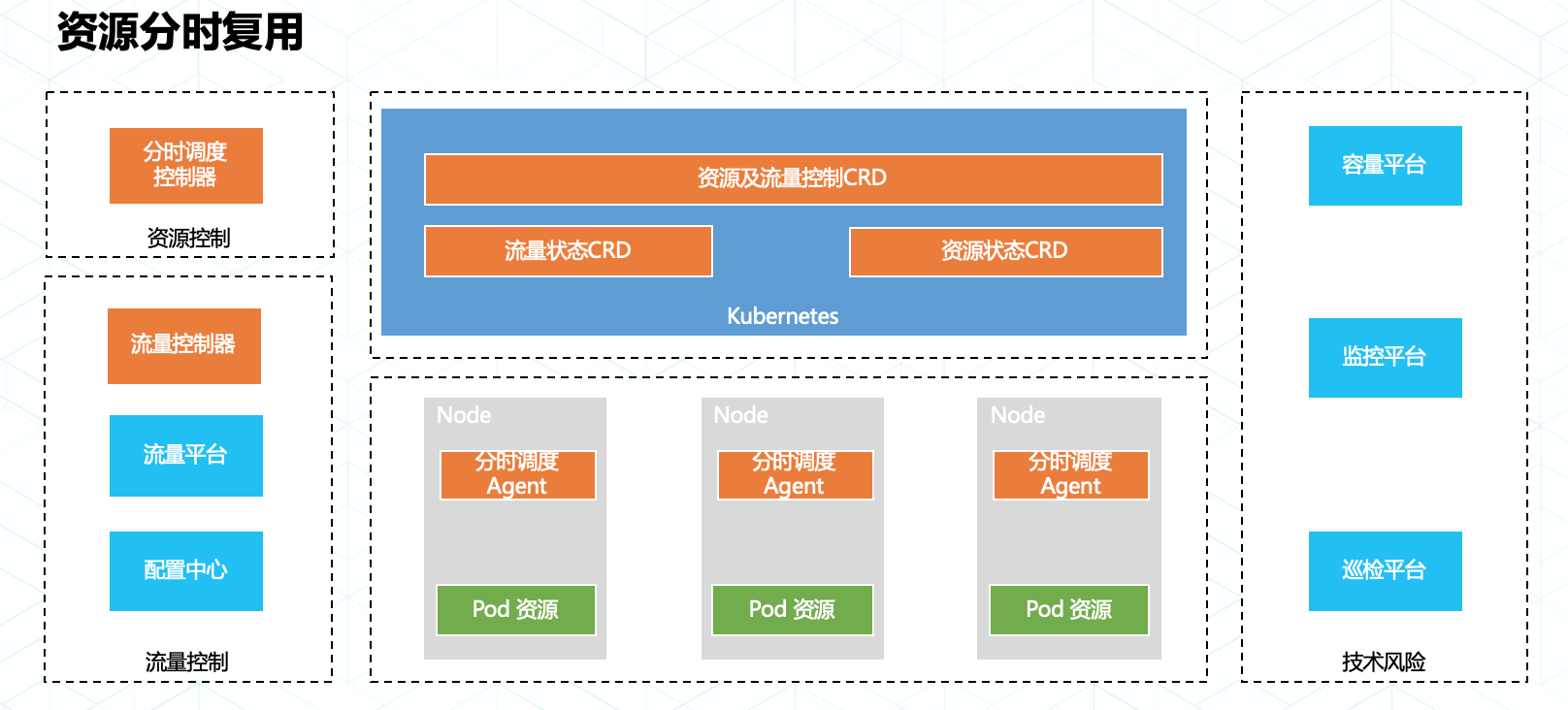
整套平臺和技術最終實現了令人激動的成果:螞蟻金服內部不同業務鏈路數以萬計的實例實現了最大程度的資源共享,這些共享資源的實例可分鐘級完成平滑切換。這種技術能力也突破了當下資源水平伸縮能力的效率限制,爲資源的分時複用打開了想象空間。
3.2 計算型任務混部
Kubernetes 社區的落地案例中,我們往往看到的都是各種各樣的在線業務,計算型業務往往通過“圈地”式的資源申請和獨立的二層調度跑在 Kuberentes 集羣中。但是在螞蟻內部我們從決定使用 Kubernetes 的第一天起,就將 Kubernetes 融合計算型業務實現資源的統一調度作爲我們的目標。
在螞蟻金服內部我們持續的使用 Kubernetes 支持各類計算業務,例如各類AI 訓練任務框架,批處理任務和流式計算等。他們都有一個共同的特點:資源按需申請,即用即走。
我們通過 Operator 模型適配計算型任務,讓任務在真正執行時纔會調用 Kubernetes API 申請 Pod 等資源,並在任務退出時刪除 Pod 釋放資源。同時我們在調度引擎中引入了動態資源調度能力和任務畫像系統,這爲在線和計算的不同等級業務提供了分級資源保障能力,使在線業務不受影響的情況下資源被最大化的利用。
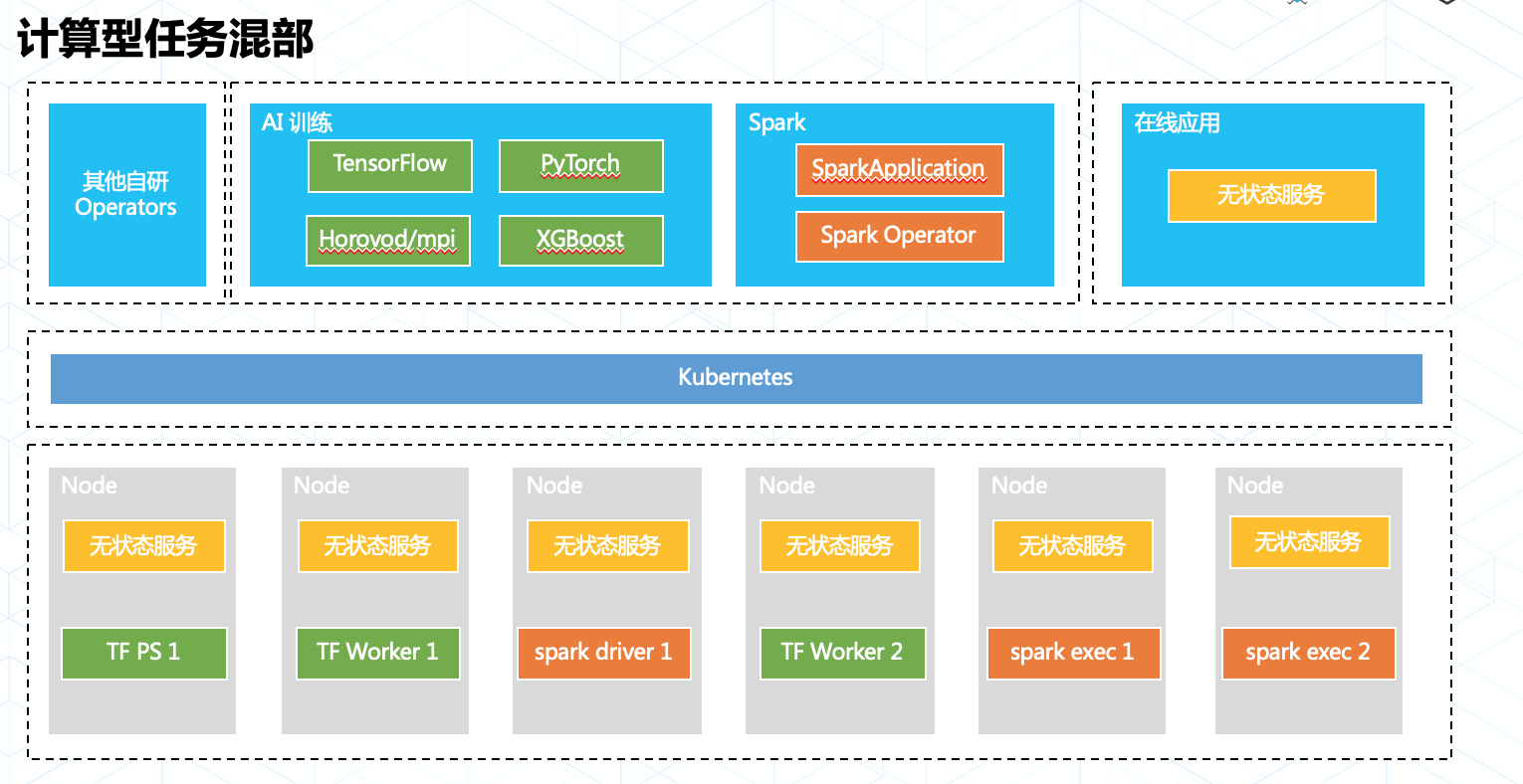
今年雙十一除了洪峯時間段(00:00~02:00),螞蟻金服 Kubernetes 上運行的任務均未做降級,每分鐘仍有數以百計的計算任務在 Kubernetes 上申請和釋放。未來螞蟻金服內部將會持續推動業務調度融合,將 Kubernetes 打造成爲資源調度的航空母艦。
3.3 規模化核心
螞蟻金服是目前少數運行了全球最大規模的 Kubernetes 集羣的公司之一,單集羣機器規模過萬,Pods 數量數十萬。隨着類似計算型任務混部和資源分時複用這類業務的落地,資源的動態使用以及業務自動化運維都對 Kubernetes 的穩定性和性能帶來的巨大的挑戰。
首先需要面對的挑戰是調度性能,社區的調度器在5k規模測試中調度性能只有1~2 pods/s,這顯然無法滿足螞蟻金服的調度性能需求。

針對同類業務的資源需求往往相同的特點,我們自研了批量調度功能,再加上例如局部的filters性能優化等工作,最終達到了百倍的調度性能提升!
在解決了調度性能問題後,我們發現規模化場景下 APIServer 逐漸成爲了影響 Kubernetes 可用性的關鍵組件,CRD+Operator 的靈活擴展能力更是對集羣造成巨大的壓力。業務方有100種方法可以玩垮生產集羣,讓人防不勝防。
造成這種現象一方面是由於社區今年以前在規模化上的投入較少 APIServer 能力較弱,另一方面也是由 Operator 模式的靈活性決定。開發者在收益於 Operator 高靈活度的同時,往往爲集羣管理者帶來業務不受控制的風險。即使對 Kubernetes 有一定熟悉程度的開發者,也很難保障自己寫出的 Operator 在生產中不會引爆大規模的集羣。

面對這種“核按鈕”不在集羣管理員手上的情況,螞蟻內部通過兩方面入手解決規模化帶來的問題:
我們通過持續總結迭代過程中的經驗,形成了內部的最佳實踐原則,以幫助業務更好的設計Operator
CRD 在定義時需要明確未來的最大數量,大量CR 業務最好採用 aggregate-apiserver 進行擴展;
CRD 必須 Namespaced scope,以控制影響範圍;
MutatingWebhook + 資源 Update 操作會給運行時環境帶來不可控破壞,儘量避免使用這種組合;
任何 controllers 都應該使用 informers,並且對寫操作配置合理限流;
DaemonSet 非常高階,儘量不要採用這類設計,如果必需請在 Kubernetes 專家的輔導下使用;
2.我們已經在 Kubernetes 實施了一系列的優化,包含多維度流量控制,WatchCache 處理全量 List 請求,controller 自動化解決更新衝突,以及 APIServer 加入自定義索引等。
通過規範和優化,我們從 client 到 server 對 API 負載做了整體鏈路的優化,讓資源交付能力在落地的大半年內提升了6倍,集羣每週可用率達到了3個9,讓 Kubernetes 平穩順滑的支撐了雙十一的大促。
3.4 彈性資源建站
近幾年大促螞蟻金服都會充分利用雲化資源,通過快速彈性建站的方式將全站業務做“臨時”擴容,並在大促後回收站點釋放資源。這樣的彈性建站方式爲螞蟻節省了大量的資源開支。
Kubernetes 提供了強大的編排能力,但集羣自身的管理能力還比較薄弱。螞蟻金服從 0 開始,基於 Kubernetes on Kubernetes 和麪向終態的設計思路,開發了一套管理系統來負責螞蟻幾十個生產集羣的管理,提供面向大促的快速彈性建站功能。
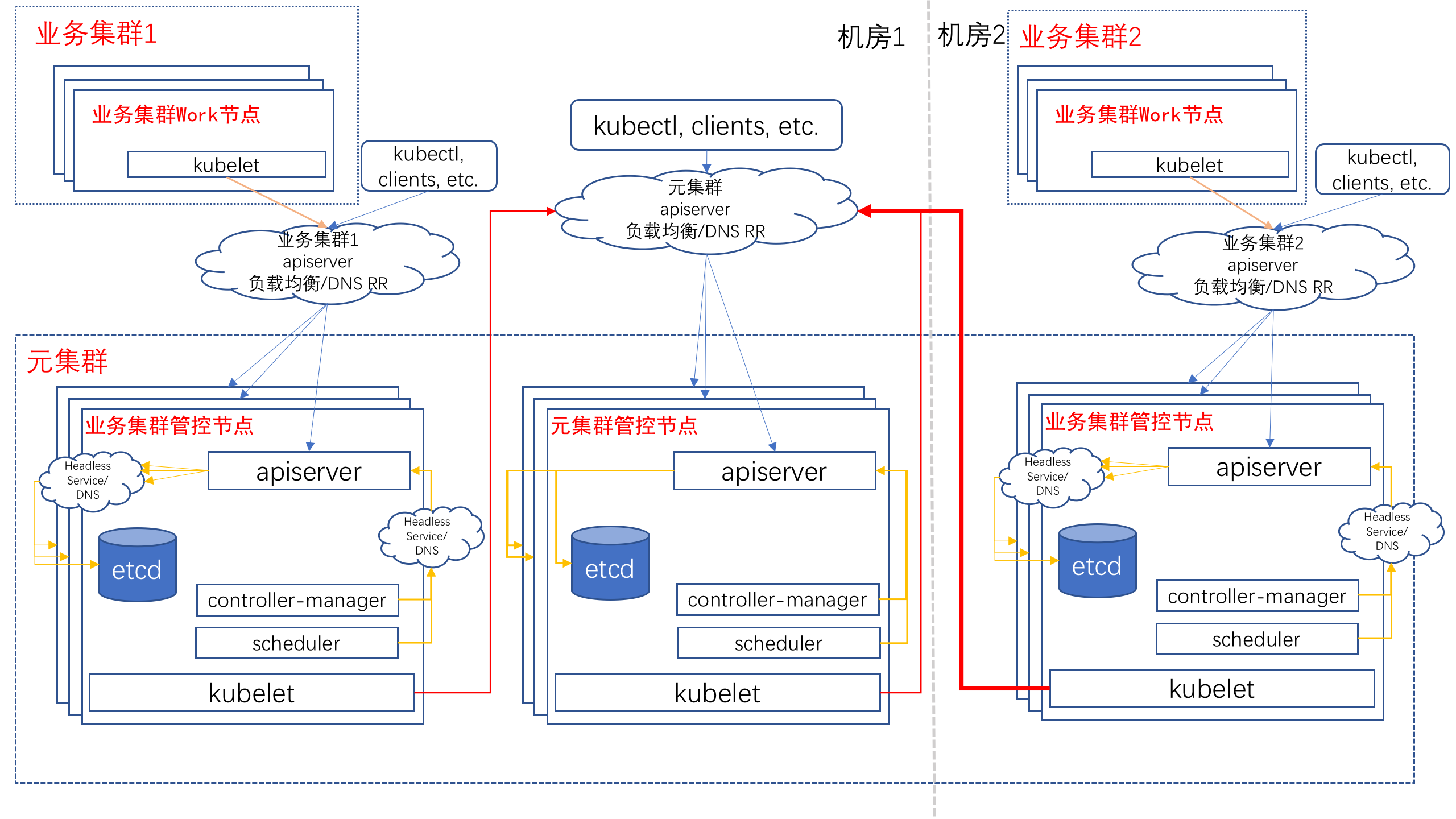
通過這種方式我們可以自動化的完成站點搭建,3小時內交付可立即使用的包含數千個 Nodes 的 Kubernetes 集羣。今年雙十一我們在一天內交付了全部彈性雲化集羣,隨着技術的不斷提升和磨練,我們期望未來能夠按天交付符合業務引流標準的集羣,讓螞蟻金服的站點隨時隨地可彈。
四、展望未來,迎接挑戰
雲原生時代已經到來,螞蟻金服內部已經通過 Kubernetes 邁出了雲原生基礎設施建設的第一步。雖然當前在實踐中仍然有許多挑戰在等着我們去應對,但相信隨着我們在技術上持續的投入,這些問題會一一得到解決。
4.1 平臺與租戶
當前我們面對的一大挑戰是多租戶帶來的不確定性。螞蟻金服內部不可能爲每個業務部門都維護一套Kubernetes集羣,而單個 Kubernetes 集羣的多租戶能力十分薄弱,這體現在以下兩個維度:
APIServer 和 etcd 缺少租戶級別的服務保障能力;
Namespace 並不能有效的隔離全部資源,並且由於Namespace 只提供了部分資源能力,對平臺型的接入方也很不友好。

未來我們會在覈心能力如 Priority and Fairness for API Server Requests 以及 Virtual Cluster 上持續的做技術投入和應用,有效保障租戶的服務能力保障和隔離。
4.2 自動化運維
除了資源調度,Kubernetes 下一階段的重要場景就是自動化運維。這涉及到應用資源全生命週期的面向終態自行維護,包含但不限於資源自動交付及故障自愈等場景。
隨着自動化程度的不斷提升,如何有效控制自動化帶來的風險,讓自動化運維能夠真正提升效率而不是任何時刻都需要承擔刪庫跑路的風險是接下來的一個重要難題。
螞蟻金服在落地 Kubernetes 的過程中經歷過類似的情況:從初期高度自動化帶來無限的興奮,到遭遇缺陷不受控制最終爆炸引發故障後的無比沮喪,這些都說明了在 Kubernetes 上做自動化運維仍有很長的路要走。
爲此我們接下來和阿里集團兄弟部門一起推動 Operator 的標準化工作。從接入標準,Operator 框架,灰度能力建設和控制治理上入手,讓 Kubernetes 上的自動化運維變的更加可視可控。
五、結束語
今年我們實現了 Kubernetes 由 0-1 的落地,經受了雙十一雙大促真實場景的考驗。但云原生的基礎設施建設仍是剛剛起步,接下來我們將在彈性資源交付,集羣規模化服務以及技術風險與自動化運維上持續發力,以技術支撐和推動業務服務完成雲原生的落地。
最後,也歡迎志同道合的夥伴加入我們,一起參與建設雲原生場景下的基礎設施!可點擊【金融級分佈式架構】公衆號【加入我們】-【超多崗位】 tab 獲取職位信息。
作者介紹
曹寅,螞蟻金服 Kubernetes 落地負責人,2015年加入螞蟻金服,主要從事容器技術及平臺研發相關工作,2018年開始負責螞蟻Kubernetes的研發落地。 曾在阿里雲彈性計算工作四年,對雲計算基礎設施領域有着深刻的理解。